Ingest from Amazon S3¶
Intermediate
In this guide you'll learn how to automatically synchronize all the CSV files in an Amazon S3 to a Tinybird Data Source.
Perform a once-off load¶
Often when you're building a new use-case with Tinybird, you'll want to load some historical data that comes from another system. You call this 'seeding' or 'backfilling'.
A very common pattern for exporting historical data is to create a dump of CSV files onto an Amazon S3 bucket. Once you have your CSV files, you need to ingest these into Tinybird.
You can append these files to a Data Source in Tinybird using the Data Sources API.
Let's assume we have a set of CSV files in our S3 bucket:
tinybird-assets/datasets/guides/events/events_0.csv tinybird-assets/datasets/guides/events/events_1.csv tinybird-assets/datasets/guides/events/events_10.csv tinybird-assets/datasets/guides/events/events_11.csv tinybird-assets/datasets/guides/events/events_12.csv tinybird-assets/datasets/guides/events/events_13.csv tinybird-assets/datasets/guides/events/events_14.csv tinybird-assets/datasets/guides/events/events_15.csv tinybird-assets/datasets/guides/events/events_16.csv tinybird-assets/datasets/guides/events/events_17.csv tinybird-assets/datasets/guides/events/events_18.csv tinybird-assets/datasets/guides/events/events_19.csv tinybird-assets/datasets/guides/events/events_2.csv tinybird-assets/datasets/guides/events/events_3.csv tinybird-assets/datasets/guides/events/events_4.csv tinybird-assets/datasets/guides/events/events_5.csv tinybird-assets/datasets/guides/events/events_6.csv tinybird-assets/datasets/guides/events/events_7.csv tinybird-assets/datasets/guides/events/events_8.csv tinybird-assets/datasets/guides/events/events_9.csv
To ingest a single file, you can generate a signed URL in AWS, and simply send the URL to the Data Sources API using the append mode flag.
For example:
curl -H "Authorization: Bearer <your_auth_token>" \ -X POST "api.tinybird.co/v0/datasources?name=<my_data_source_name>&mode=append" \ --data-urlencode "url=<my_s3_file_http_url>"
However, if you want to send many files, you probably don't want to manually write each cURL. So, we can use a simple script to iterate over our files in the bucket and generate the cURL commands automatically.
This script requires the AWS CLI and assumes you have already created your Tinybird Data Source.
You can use the AWS CLI to list the files in the bucket, extract the name of the CSV file and create a signed URL. Then, we can generate a cURL to send the signed URL to Tinybird.
To avoid hitting API rate limits you should delay 15 seconds between each request.
Here's an example script in bash:
#!/bin/bash
TB_HOST=<> # https://ui.us-east.tinybird.co OR https://ui.tinybird.co
TB_TOKEN=<token> # Token from the auth section
BUCKET=<> # S3 Bucket
DESTINATION_DATA_SOURCE=<> # Datesource where to append the data
WORKERS=1 # Concurrent imports
FORMAT=csv # Format of the files to append
check_status() {
job=$(curl -s -H "Authorization: Bearer $TB_TOKEN" "$TB_HOST/v0/jobs/$1")
echo $(echo $job | jq -r '.status')
}
append() {
job=$(curl -s -H "Authorization: Bearer $TB_TOKEN" \
-X POST "$TB_HOST/v0/datasources?name=$DESTINATION_DATA_SOURCE&mode=append&format=$FORMAT" \
--data-urlencode "url=$1")
job_status=$(echo $job | jq -r '.status')
job_id=$(echo $job | jq -r '.id')
while [[ "$job_status" != "done" && "$job_status" != "error" ]]
do
sleep 15
echo "Checking job at $TB_HOST/v0/jobs/$job_id"
job_status="$(check_status $job_id)"
echo "Job $job_id is $job_status"
done
}
i=0
pids="";
for file in $(aws s3 ls $BUCKET | awk '{print $4}' | grep $FORMAT)
do
url=$(echo -n "$BUCKET$file" | xargs | tr -d '\r')
echo $url
SIGNED=$(aws s3 presign "$url" --expires-in 3600)
append $SIGNED &
pid=$!
pids+=" $pid";
((i=i+1))
if (( $i%$WORKERS==0))
then
wait $pids
fi
done
trap "kill $pids" SIGINT
wait $pids
The script uses the following variables:
TB_HOSTas the corresponding URL for your region. We currently have: https://api.us-east.tinybird.co for the US region, and https://api.tinybird.co for the EU region.TB_TOKENas a Tinybird auth token withDATASOURCE:CREATEorDATASOURCE:APPENDscope. See the Tokens APIfor more information.BUCKETas the S3 URI of the bucket containing the events CSV files.DESTINATION_DATA_SOURCEas the name of the Data Source in Tinybird.
Automatically sync files with AWS Lambda¶
While the previously described scenario consisted of a one time dump of CSV files in a bucket to Tinybird, a different and more interesting scenario consists of appending to a Data Source each time a new CSV file is dropped into a bucket.
That way you can have your ETL process exporting some data from your Data Warehouse (such as Snowflake or BigQuery) or any other origin and you can forget about synchronizing those files to Tinybird.
This can be achieved using AWS Lambda.
Imagine you have an S3 bucket named s3://automatic-ingestion-poc/ and each time you put a CSV there you want to sync it automatically to an events Data Source in Tinybird.
This is how you do it:
- Clone this GitHub repository
- Install the AWS cli and run
aws configure. You need to provide theregionas well since it is required by the script. - Now run
cp .env_sample .envand set theTB_HOST,TB_TOKEN, andS3_BUCKET(in our caseS3_BUCKET=automatic-ingestion-poc) - Run the
./run.shscript. It'll deploy a Lambda function with nameTB_FUNCTION_NAMEto your AWS account, which will listen for new files in theS3_BUCKETand automatically append them to a Tinybird Data Source described by theFILE_REGEXPenvironment variable.
It creates a Lambda function in your AWS account:
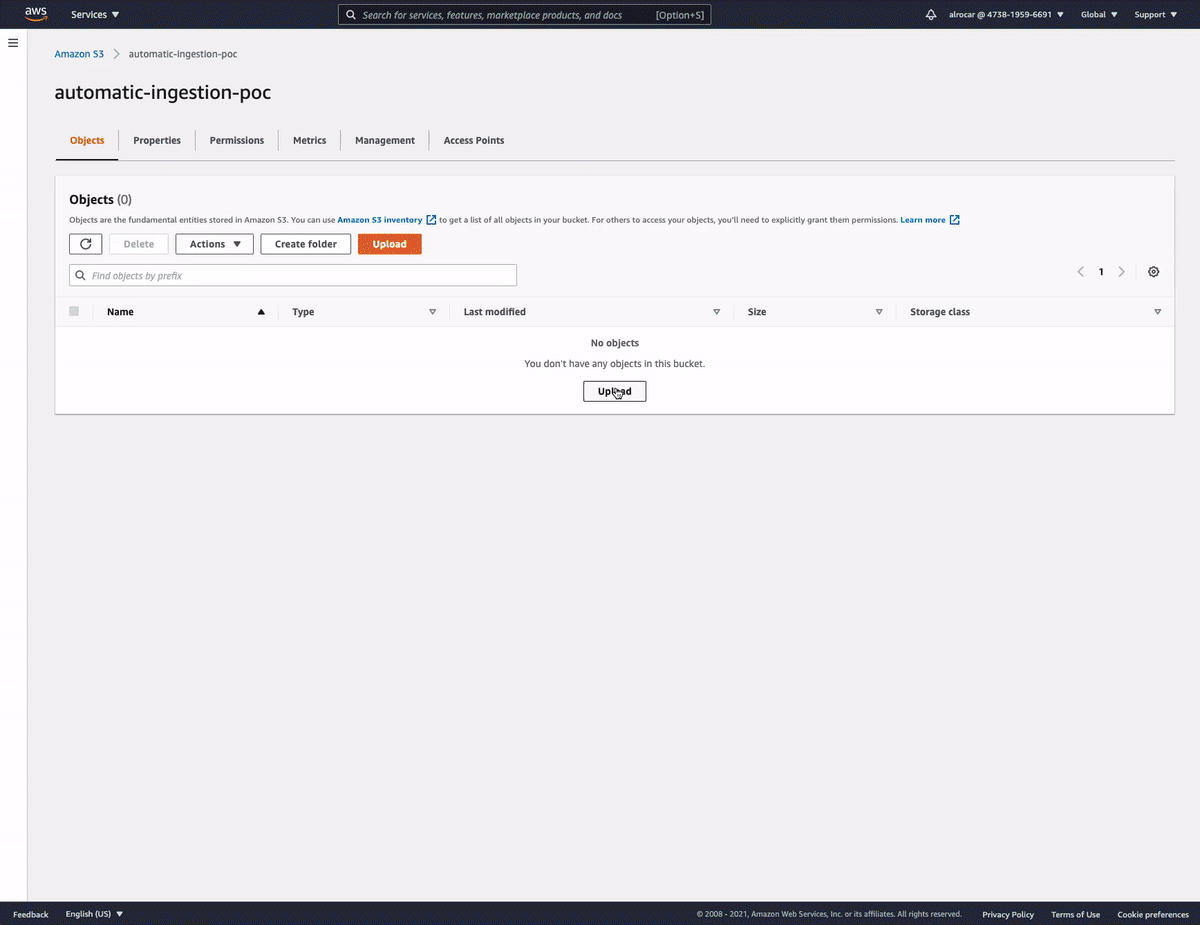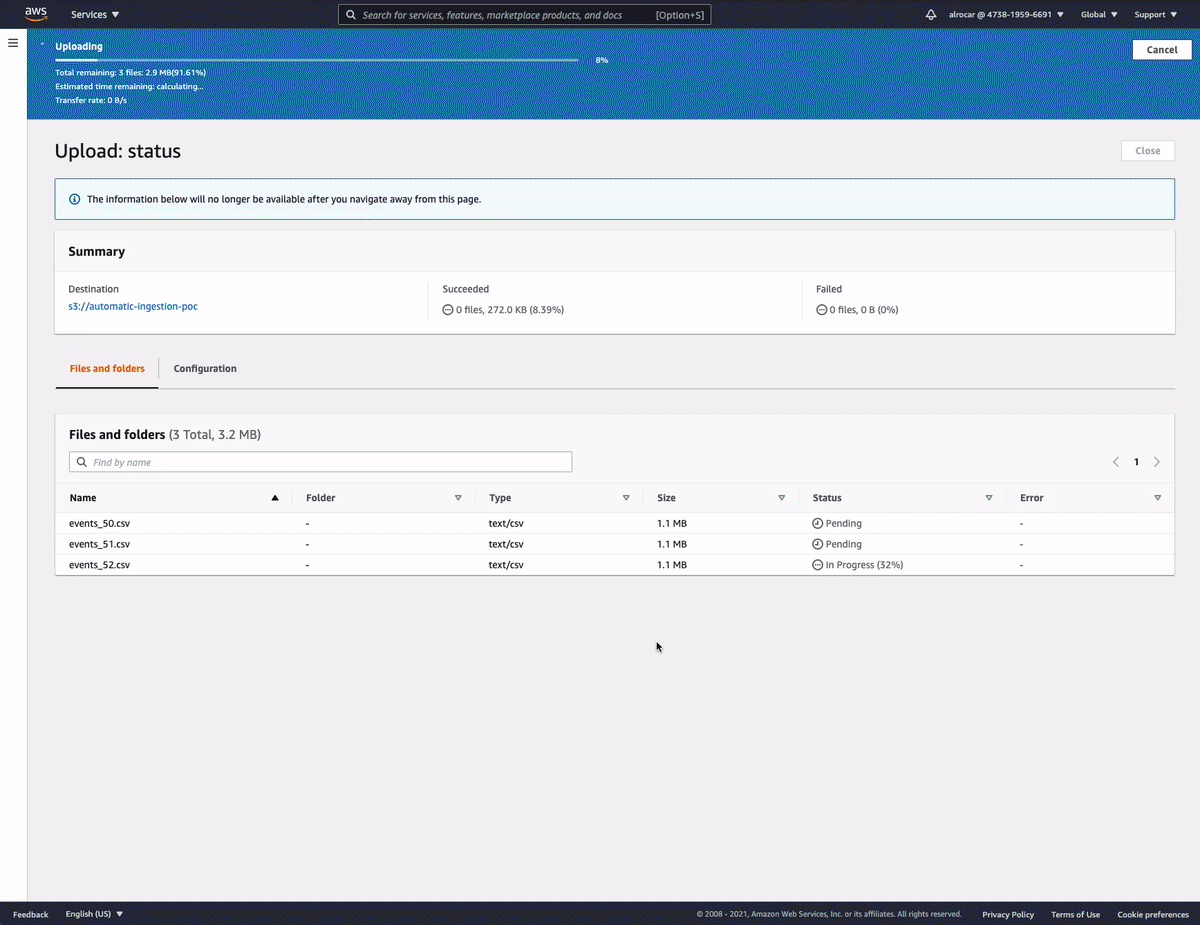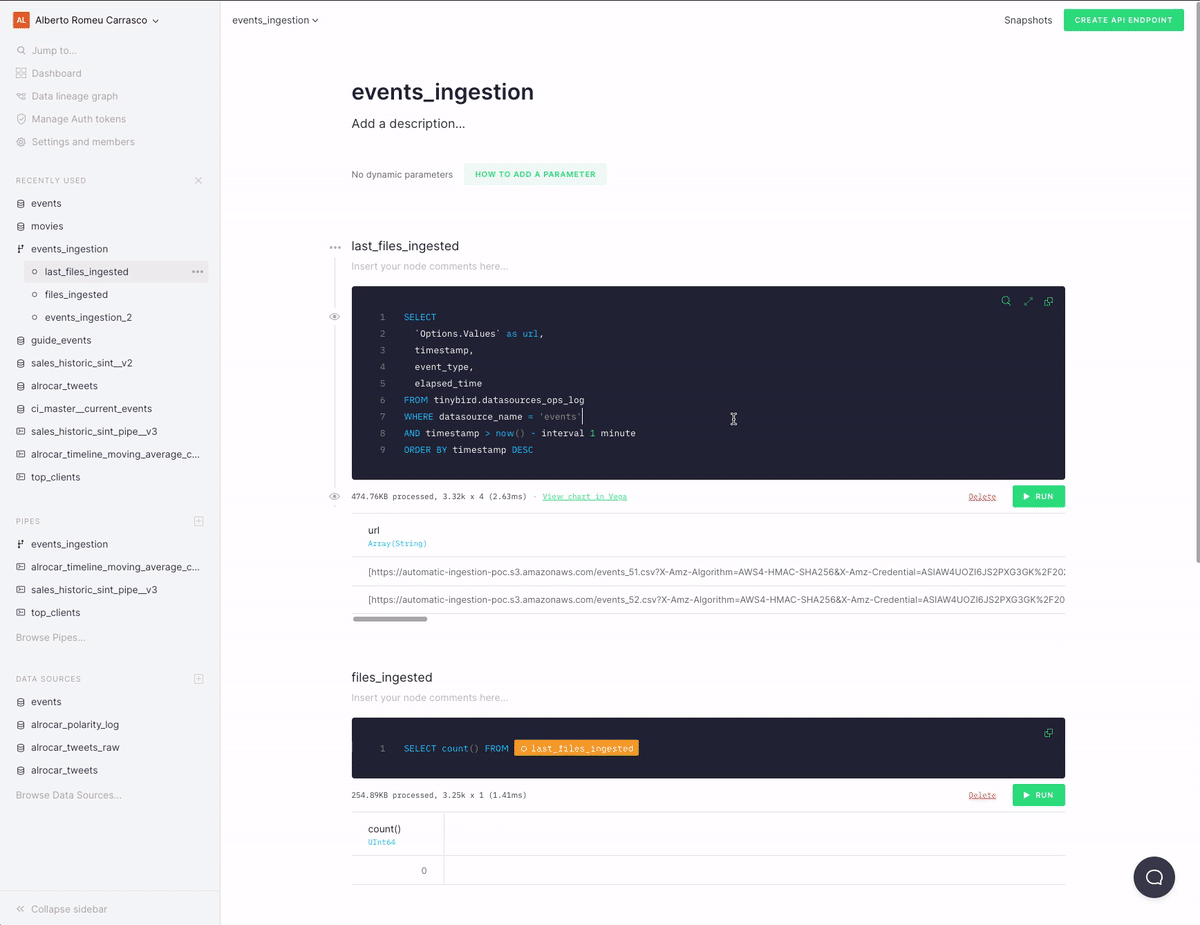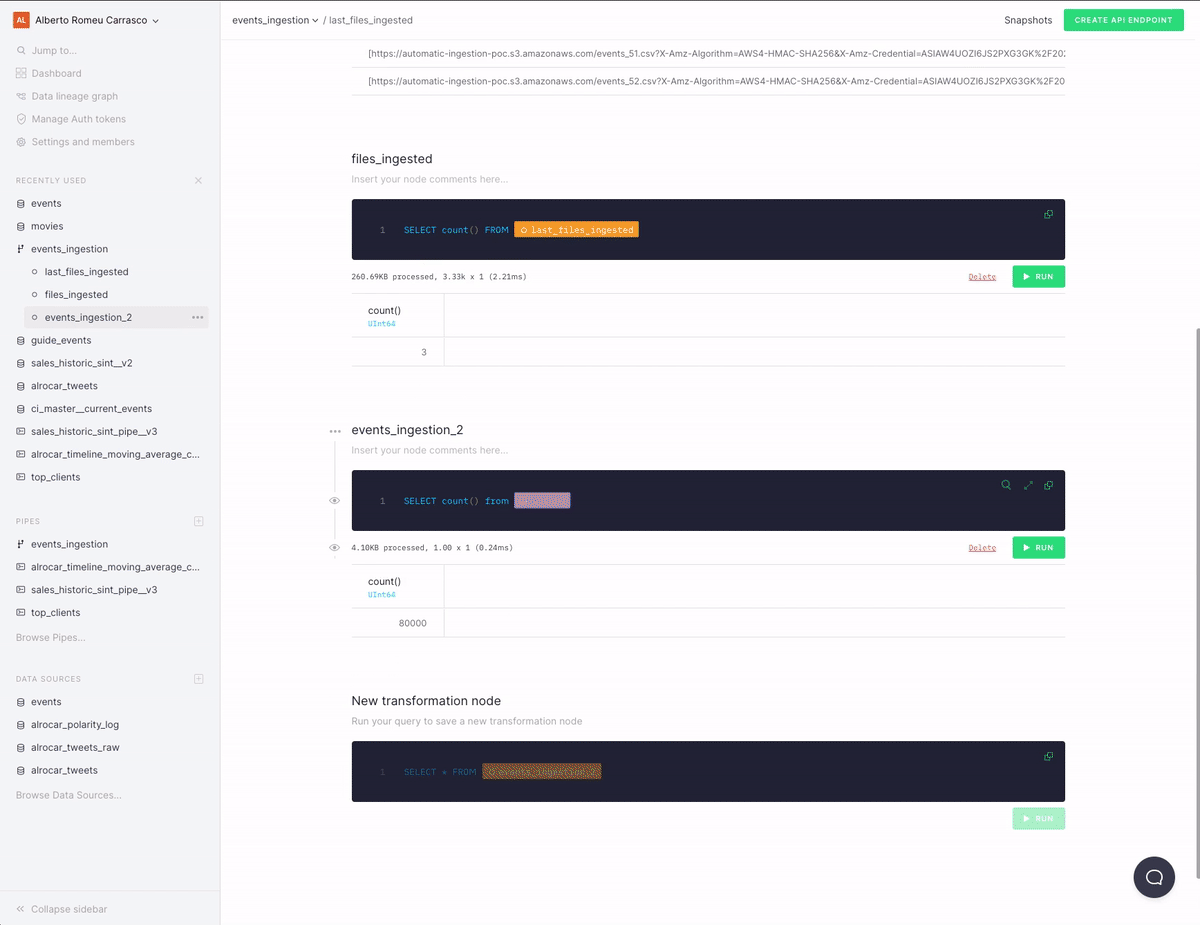
Each time you drop a new CSV file it is automatically ingested in the destination Data Source. In this case, the Lambda function is automatically configured to support this naming convention in the CSV files {DESTINATION_DATA_SOURCE}_**.csv. For instance, if you drop a file named events_0.csv it'll be appended to the events Data Source. You can modify this behaviour with the FILE_REGEXP environment variable or by modifying the code of the Lambda function.