Best practices for SQL queries¶
When you're trying to process significant amounts of data, following best practices help you create faster and more robust queries.
Follow these principles when writing queries meant for Tinybird:
- The best data is the data you don't write.
- The second best data is the one you don't read. The less data you read, the better.
- Sequential reads are much faster.
- The less data you process after read, the better.
- Perform complex operations later in the processing pipeline.
The following sections analyze how performance improves after implementing each principle. To follow the examples, download the NYC Taxi Trip and import it using a Data Source. See Data Sources.
The best data is the one you don't write¶
Don't save data that you don't need, as it impacts memory usage, causing queries to take more time.
The second best data is the one you don't read¶
To avoid reading data that you don't need, apply filters as soon as possible.
For example, consider a list of the trips whose distance is greater than 10 miles and that took place between 2017-01-31 14:00:00 and 2017-01-31 15:00:00. Additionally, you want to retrieve the trips ordered by date.
The following examples show the difference between applying the filters at the end or at the beginning of the Pipe.
The first approach orders all the data by date:
SELECT *
FROM nyc_taxi
ORDER BY tpep_pickup_datetime ASC
After the data is sorted, you can filter. This approach takes around 30 to 60 ms after adding the time of both steps.
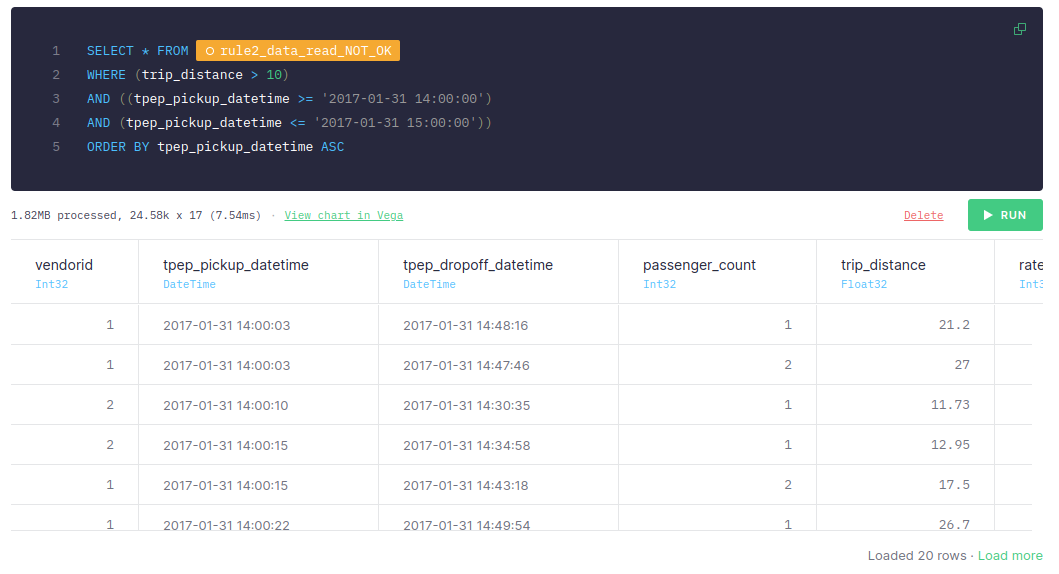
Compare the number of scanned rows (139.26k) and the size of data (10.31MB) to the number of scanned rows (24.58k) and the size of data (1.82MB): you only need to scan 24.58k rows.
Both values directly impact the query execution time and also affect other queries you might be running at the same time. Bandwidth is also a factor you need to keep in mind.
The following example shows what happens if the filter is applied before the sorting:
SELECT * FROM nyc_taxi
WHERE (trip_distance > 10)
AND ((tpep_pickup_datetime >= '2017-01-31 14:00:00')
AND (tpep_pickup_datetime <= '2017-01-31 15:00:00'))
ORDER BY tpep_pickup_datetime ASC
If the filter is applied before the sorting, it takes only 1 to 10 ms. The size of the data read is 1.82 MB, while the number of rows read is 24.58k: they're much smaller figures than the ones in the first example.
This significant difference happens because in the first approach you are sorting all the data available, even the data that you don't need for your query, while in the second approach you are sorting only the rows you need.
As filtering is the fastest operation, always filter first.
Sequential reads are much faster¶
To carry out sequential reads, define indexes correctly. Indexes should be defined based on the queries that are going to be run. The following example simulates a case by ordering the data based on the columns.
For example, if you want to query the data by date, compare what happens when the data is sorted by date to when it's sorted by any other column.
The first approach sorts the data by another column, passenger_count:
SELECT * FROM nyc_taxi
ORDER BY passenger_count ASC
After you've sorted the data by passenger_count, filter it by date:
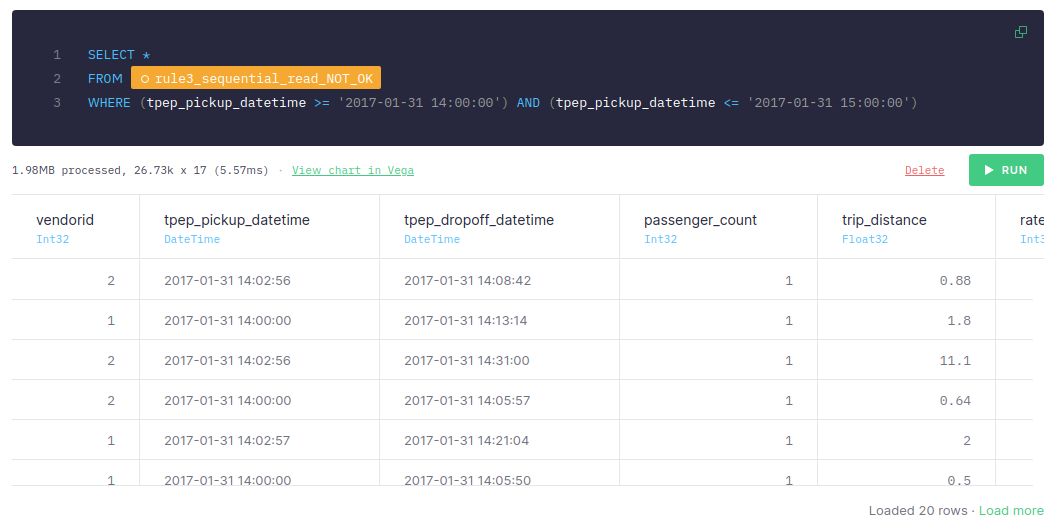
This approach takes around 5-10 ms, the number of scanned rows is 26.73k, and the size of data is 1.98 MB.
For the second approach, sort the data by date:
SELECT * FROM nyc_taxi
ORDER BY tpep_pickup_datetime ASC
After it's sorted by date, filter it:
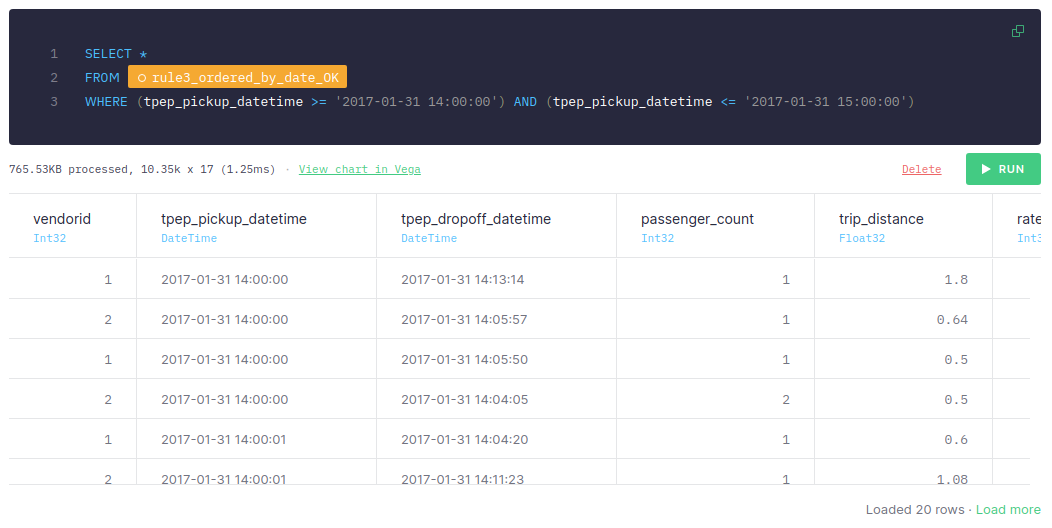
When the data is sorted by date and the query uses date for filtering, it takes 1-2 ms, the number of scanned rows is 10.35k and the size of data is 765.53KB. The more data you have, the greater the difference between both approaches. When dealing with significant amounts of data, sequential reads can be much faster.
Therefore, define the indexes taking into account the queries that you want to make.
The less data you process after read, the better¶
If you only need two columns, only retrieve those.
Consider a case where you only need the following: vendorid, tpep_pickup_datetime, and trip_distance.
When retrieving all the columns instead of the previous three, you need around 140-180 ms and the size of data is 718.55MB:
SELECT *
FROM
(
SELECT
*
FROM nyc_taxi
order by tpep_dropoff_datetime
)
When retrieving only the columns you need, it takes around 35-60 ms:
SELECT *
FROM
(
SELECT
vendorid,
tpep_pickup_datetime,
trip_distance
FROM nyc_taxi
order by tpep_dropoff_datetime
)
With analytical databases, not retrieving unnecessary columns make queries much more performant and efficient. Process only the data you need.
Perform complex operations later in the processing pipeline¶
Perform complex operations, such as joins or aggregations, as late as possible in the processing pipeline. As you filter all the data at the beginning, the number of rows at the end of the pipeline is lower and, therefore, the cost of executing complex operations is also lower.
Using the example dataset, aggregate the data:
SELECT
vendorid,
pulocationid,
count(*)
FROM nyc_taxi
GROUP BY
vendorid,
pulocationid
Apply the filter:
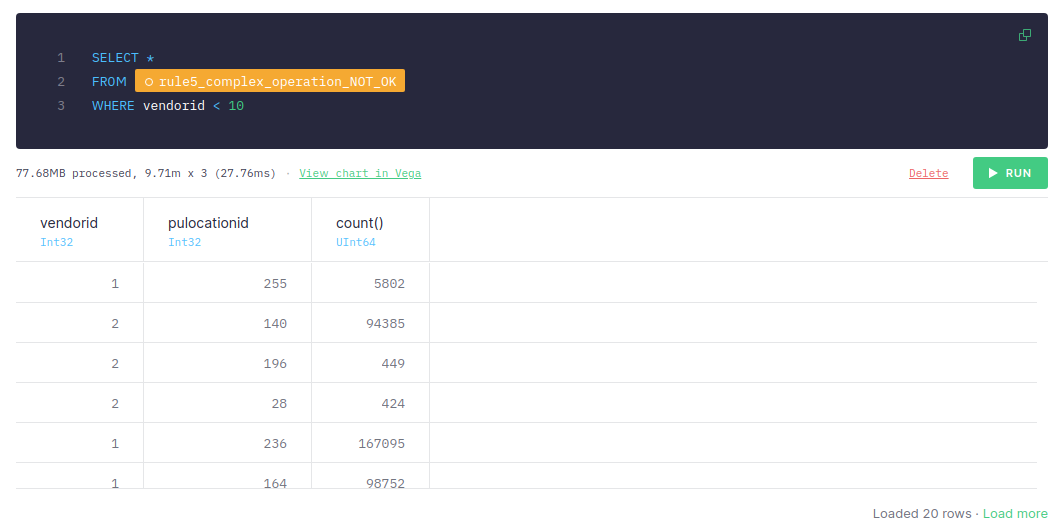
If you apply the filter after aggregating the data, it takes around 50-70 ms to retrieve the data, the number of scanned rows is 9.71m, and the size of data is 77.68 MB.
If you filter before aggregating the data:
SELECT
vendorid,
pulocationid,
count(*)
FROM nyc_taxi
WHERE vendorid < 10
GROUP BY
vendorid,
pulocationid
The query takes only 20-40 ms, although the number of scanned rows and the size of data is the same as in the previous approach.
Additional guidance¶
Follow these additional recommendations when creating SQL queries.
Avoid full scans¶
The less data you read in your queries, the faster they are. There are different strategies you can follow to avoid reading all the data in a Data Source, or doing a full scan, in your queries:
- Always filter first.
- Use indexes by setting a proper
ENGINE_SORTING_KEYin the Data Source. - The column names present in the
ENGINE_SORTING_KEYshould be the ones you use for filtering in theWHEREclause. You don't need to sort by all the columns you use for filtering, only the ones to filter first. - The order of the columns in the
ENGINE_SORTING_KEYis important: from left to right ordered by relevance. The columns that matter the most for filtering and have less cardinality should go first.
Consider the following Data Source, which is sorted by date by default:
SCHEMA >
`id` Int64,
`amount` Int64,
`date` DateTime
ENGINE "MergeTree"
ENGINE_SORTING_KEY "id, date"
The following query is slower because it filters data using a column other than the ones defined in the ENGINE_SORTING_KEY instruction:
SELECT *
FROM data_source_sorted_by_date
WHERE amount > 30
The following query is faster because it filters data using a column defined in the ENGINE_SORTING_KEY instruction:
SELECT *
FROM data_source_sorted_by_date
WHERE
id = 135246 AND
date > now() - INTERVAL 3 DAY AND
amount > 30
Avoid big joins¶
When doing a JOIN, the data in the Data Source on the right side loads in memory to perform the operation. JOINs over tables of more than 1 million rows might lead to MEMORY_LIMIT errors when used in Materialized Views, affecting ingestion.
Avoid joining big Data Sources by filtering the data in the Data Source on the right side. For example, the following pattern is less efficient because it's joining a Data Source with too many rows:
SELECT
left.id AS id,
left.date AS day,
right.response_id AS response_id
FROM left_data_source AS left
INNER JOIN big_right_data_source AS right ON left.id = right.id
The following query is faster and more efficient because if prefilters the Data Source before the JOIN:
SELECT
left.id AS id,
left.date AS day,
right.response_id AS response_id
FROM left_data_source AS left
INNER JOIN (
SELECT id, response_id
FROM big_right_data_source
WHERE id IN (SELECT id FROM left_data_source)
) AS right ON left.id = right.id
Memory issues¶
Sometimes, you might reach the memory limit when running a query. This is usually because of the following reasons:
- Lot of columns are used: try to reduce the amount of columns used in the query. As this isn't always possible, try to change data types or merge some columns.
- A cross
JOINor some operation that generates a lot of rows: it might happen if the crossJOINis done with two Data Sources with a large amount of rows. Try to rewrite the query to avoid the crossJOIN. - A massive
GROUP BY: try to filter out rows before executing theGROUP BY.
If you are getting a memory error while populating a Materialized View, the solutions are the same. Consider that the populate process runs in 1 million rows chunks, so if you hit memory limits, the cause might be one of the following:
- There is a
JOINand the right table is large. - There is an
ARRAY JOINwith a huge array that make the number of rows significantly increase.
To check if a populate process could break, create a Pipe with the same query as the Materialized View and replace the source table with a node that gets 1 million rows from the source table.
The following example shows an unoptimized Materialized View Pipe:
NODE materialized
SQL >
select date, count() c from source_table group by date
The following query shows the transformed Pipe:
NODE limited
SQL >
select * from source_table limit 1000000
NODE materialized
SQL >
select date, count() c from limited group by date
Nested aggregate functions¶
You can't nest aggregate functions or use an alias of an aggregate function that's used in another aggregate function.
For example, the following query causes an error due to a nested aggregate function:
SELECT max(avg(number)) as max_avg_number FROM my_datasource
The following query causes an error due to a nested aggregate with alias:
SELECT avg(number) avg_number, max(avg_number) max_avg_number FROM my_datasource
Instead of using nested aggregate functions, use a subquery. The following example shows how to use aggregate functions in a subquery:
SELECT
avg_number as number,
max_number
FROM (
SELECT
avg(number) as avg_number,
max(number) as max_number
FROM numbers(10)
)
The following example shows how to nest aggregate functions using a subquery:
SELECT
max(avg_number) as number
FROM (
SELECT
avg(number) as avg_number,
max(number) as max_number
FROM numbers(10)
)
Merge aggregate functions¶
Columns with AggregateFunction types such as count, avg, and others precalculate their aggregated values using intermediate states. When you query those columns you have to add the -Merge combinator to the aggregate function to get the final aggregated results.
Use -Merge aggregated states as late in the pipeline as possible. Intermediate states are stored in binary format, which explains why you might see special characters when selecting columns with the AggregateFunction type.
For example, consider the following query:
SELECT result FROM my_datasource
The result contains special characters:
AggregateFunction(count) | @33M@ | �o�@ |
|---|
When selecting columns with the AggregateFunction type use -Merge the intermediate states to get the aggregated result for that column. This operation might compute several rows, so use -Merge as late in the pipeline as possible.
Consider the following query:
-- Getting the 'result' column aggregated using countMerge. Values are UInt64
SELECT countMerge(result) as result FROM my_datasource
The result is the following:
UInt64 | 1646597 |
|---|