Change Data Capture (CDC) is a design pattern that allows you to track and capture change streams from a source data system so that downstream systems can efficiently process these changes. In contrast to Extract, Transform, and Load (ETL) workflows, it can be used to update data in real-time or near real-time between databases, data warehouses, and other systems. The changes include inserts, updates, and deletes, and are captured and delivered to the target systems without requiring the source database to be queried directly.
In this post, you'll learn how to implement a real-time change data capture pipeline on change data in MongoDB.
In this blog post, I'll describe how to implement a real-time change data capture (CDC) pipeline on changes in MongoDB, using both Confluent and Tinybird.
In this tutorial, I'll be using Confluent to capture change streams from MongoDB, and Tinybird to analyze MongoDB change streams using it's native Kafka Connector. Why Tinybird? For real-time analytics on change data, Tinybird serves as an ideal data sink. While MongoDB excels at operational workloads, ClickHouse® significantly outperforms MongoDB for analytical queries, making CDC pipelines an effective way to combine the strengths of both databases.
This is an alternative approach to using Debezium and Debezium’s MongoDB Connector, a popular open source framework for change data capture. It is a perfectly viable solution thanks to its MongoDB CDC connector, but this guide provides an alternative for real-time analytics use cases.
Tinybird is the perfect data sink when you want to run real-time analytics over change data in MongoDB.
With Tinybird, you can transform, aggregate, and filter MongoDB changes as they happen and expose them via high-concurrency, low-latency APIs. Using Tinybird with your CDC data offers several benefits:
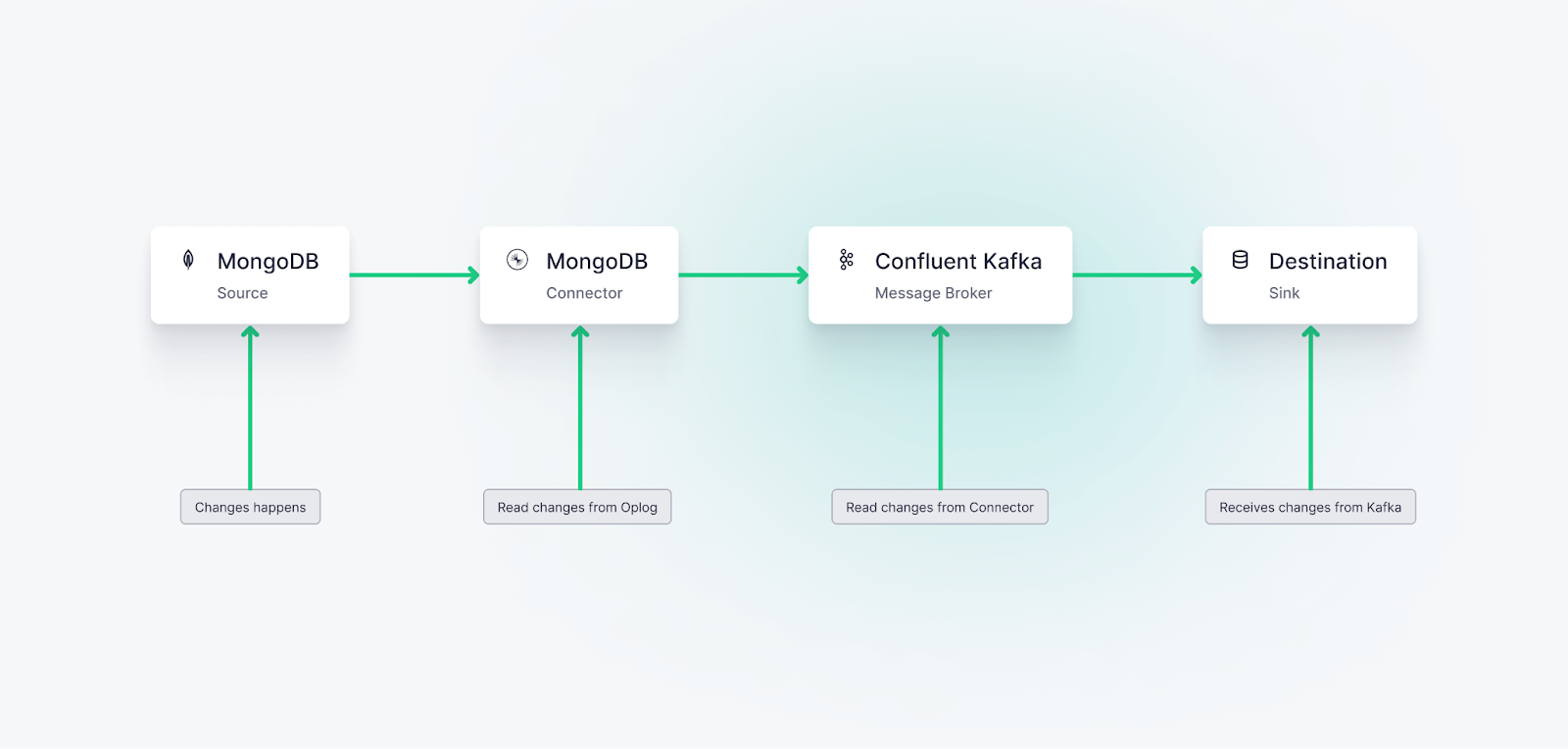
CDC with MongoDB works primarily through the oplog, a special capped collection in MongoDB that logs all operations modifying the data stored in your databases.
When a change event such as an insert, update, or delete occurs in your MongoDB instance, the change is recorded in the oplog. This log is part of MongoDB's built-in replication mechanism and it maintains a rolling record of all data-manipulating operations.
Changes in MongoDB are recorded in its oplog, a built-in replication mechanism offered by MongoDB.
CDC processes monitor this oplog, capturing the changes as they occur. These changes can then be propagated to other systems or databases, ensuring they have near real-time updates of the data.
In the context of MongoDB Atlas and a service like Confluent Kafka, MongoDB Atlas runs as a replica set and is configured to generate an oplog. A connector (like the MongoDB Source Connector) is then used to pull the changes from MongoDB's oplog and stream these changes to Kafka topics. From there, these changes can be further processed or streamed to other downstream systems as per your application requirements.
Let's create a CDC pipeline using MongoDB Atlas and Confluent Cloud.
For more details on this, check out the Confluent Docs.
Replace the placeholders with your actual values:
$ENV_ID: Your Confluent Cloud environment ID$CLUSTER_ID: Your Kafka cluster ID$API_KEY: Your Confluent Cloud API key$API_SECRET: Your Confluent Cloud API secret$SR_ARN: Your Schema Registry ARN (if using dedicated schema registry)$BOOTSTRAP_SERVER: The bootstrap server address from your Confluent Cloud cluster settings$CONNECTION_URI: Your MongoDB Atlas connection string$DB_NAME: Your MongoDB database name$COLLECTION: Your MongoDB collection name$TOPIC_PREFIX: Prefix for the Kafka topic nameBefore connecting Confluent to Tinybird, you need to install the Tinybird CLI and authenticate with your account. This guide uses the CLI for a hands-on technical workflow.
First, install the Tinybird CLI on your machine:
```bash curl -L tinybird.co | sh ```This installs the Tinybird CLI tool and sets up Tinybird Local for local development. For more installation options, see the Tinybird installation guide.
Next, authenticate with your Tinybird account:
```bash tb login ```This command opens a browser window where you can sign in to Tinybird Cloud. If you don't have an account yet, you can create one during this process. After signing in, create a new workspace or select an existing one.
For a complete quick start guide, see Get started with Tinybird.
With CDC events being published to a Kafka stream in Confluent, your next step is connecting Confluent and Tinybird. This is quite simple using the Tinybird Kafka Connector, which will securely enable Tinybird to consume messages from your Confluent topic stream and write them into a Data Source.
The Kafka Connector is fully managed and requires no additional tooling. Simply connect Tinybird to your Confluent Cloud cluster, choose a topic, and Tinybird will automatically begin consuming messages from Confluent Cloud. As part of the ingestion process, Tinybird will extract JSON event objects with attributes that are parsed and stored in its underlying real-time database.
First, create a connection to your Confluent Cloud Kafka cluster using the Tinybird CLI. You'll need the bootstrap server, API key, and secret that you saved from Step 2.
Run the following command to start the interactive wizard:
```bash tb connection create kafka ```The wizard will prompt you to enter:
kafka_connection)pkc-xxxxx.us-east-1.aws.confluent.cloud:9092)If your Confluent Cloud cluster uses a CA certificate, the wizard will also prompt you for the certificate path.
Now, create a Data Source that will consume messages from your Kafka topic. You can use the guided CLI process or create the files manually.
Option 1: Use the guided CLI process (recommended)
Run the following command to start the guided process:
```bash tb datasource create --kafka ```The CLI will prompt you to:
kafka_connection)mongodb_cdc_consumer)earliest to read from the beginning, or latest to read only new messages)Option 2: Manually create the Data Source files
Alternatively, you can manually create a .datasource file. First, create the connection file if you haven't already. Create a file named connections/kafka_connection.connection:
Then, create a Data Source file (e.g., datasources/mongodb_cdc.datasource) that references this connection. Here's an example that defines a Tinybird Data Source to hold the change events from your MongoDB collection. In your case, the SCHEMA should match the data in your Kafka topic, which includes the fields from your MongoDB documents. Use JSONPath expressions to extract specific fields from the MongoDB CDC events into separate columns:
Replace mongodb_cdc.users with the actual topic name from Step 3 (with the prefix you configured). Adjust the schema fields to match the structure of your MongoDB documents. The __timestamp column is automatically added by Tinybird and represents when the event was ingested.
After creating your connection and Data Source files, deploy them to Tinybird Cloud:
```bash tb --cloud deploy ```You can also validate the setup before deploying by running:
```bash tb --cloud deploy --check ```This will verify that Tinybird can connect to your Kafka broker with the provided credentials.
Once deployed, Tinybird will automatically begin consuming messages from your Confluent topic, and you'll start seeing MongoDB change events stream into your Data Source as changes are made to the source data system.
When implementing CDC at scale, deduplication is essential. MongoDB change streams can produce duplicate events due to network retries, connector restarts, or Kafka consumer rebalancing. Without proper deduplication, you'll have inconsistent analytics and incorrect aggregations.
There are several strategies for handling deduplication in Tinybird:
ReplacingMergeTree engine to automatically deduplicate rows based on a primary key. This is ideal when you have a unique identifier (like a document ID) and a timestamp or version field that indicates the latest state.argMax to deduplicate at query time. This approach is flexible but can impact query performance on large datasets.For detailed guidance on implementing these strategies, see:
Now your CDC data pipeline should be up and running, capturing changes from your MongoDB Atlas database, streaming them into Kafka on Confluent Cloud, and then sinking them into a real-time, analytical datastore on Tinybird’s real-time data platform.
You can now query, shape, join, and enrich your MongoDB CDC data with SQL Pipes and instantly publish your transformations as high-concurrency, low-latency APIs to power your next use case.
For example, create a Pipe file (e.g., pipes/get_mongodb_changes.pipe) to query your MongoDB CDC data:
Deploy your Pipe to Tinybird Cloud:
```bash tb --cloud deploy ```After deployment, Tinybird automatically creates API endpoints for your Pipes. You can access your endpoint using the token you created. Here's an example of how to call the endpoint:
```bash curl "https://api.tinybird.co/v0/pipes/get_mongodb_changes.json?token=YOUR_TOKEN" ```The endpoint returns data in JSON format by default. You can also request other formats:
.csv for CSV format.ndjson for newline-delimited JSON.parquet for Parquet formatExample response:
```json { "data": [ { "_id": "507f1f77bcf86cd799439011", "name": "John Doe", "email": "john.doe@example.com", "age": 30, "city": "San Francisco", "created_at": "2023-08-15 10:30:00", "updated_at": "2023-08-15 10:30:00" } ], "rows": 1, "statistics": { "elapsed": 0.001, "rows_read": 1, "bytes_read": 256 } } ```Change Data Capture (CDC) is a powerful pattern that captures data changes and propagate them in real-time or near real-time between various systems. Using MongoDB as the source, changes are captured through its operations log (oplog) and propagated to systems like Confluent Kafka and Tinybird using a connector.
This setup enhances real-time data processing, reduces load on the source system, and maintains data consistency across platforms, making it vital for modern data-driven applications. The post walked through the steps of setting up a CDC pipeline using MongoDB Atlas, Confluent Cloud, and Tinybird, providing a scalable solution for handling data changes and powering real-time analytics.