


We’ve got a problem. The data integration landscape is dominated by poll-based ETL pipelines that run on a schedule and initiate communication with source data systems. This model is pervasive; companies of all sizes in all industries use it.
Why is this a problem? Actually, it’s two:
- Added load on the source data system: In many cases, the source system is an application database, and the ETL tool queries that database to get changes in the data.
It’s common to use a “delta” approach to only select the data that has changed since your last poll, and you would think that this approach would minimize the amount of data these queries scan. In many cases, however, you’d be wrong.
In reality, these queries often scan the whole table. This is because the index of the source system often doesn’t match the key that the ETL tool uses to filter the data, so the query often does a full scan of the database searching for new rows even though it’s only returning a small subset.
So, while your network and storage load might be smaller with a delta approach thanks to a smaller result set from the query, your application database is still supporting a full table scan. You can end up putting a significant load on your database, which will, at best, degrade the experience of the application it underpins. Worse, you’ll be looking at a sky-high compute bill.
You'd think that a delta approach to extracting changes from a database would be efficient, but in many cases those queries still scan the whole table.
- Change data isn’t fresh. By definition, poll-based ETLs run on a schedule and thus are immediately out of date as soon as the job finishes. In the best-case scenario, these jobs are running every hour. More commonly, they’re running every 12 to 24 hours.
You can minimize the time between polling jobs to make things fresher, but now you’re running into problem #1, and you can’t risk bringing down the application to support whatever downstream data needs you might have.
Because of this, you simply can not support use cases that depend on live, real-time data, such as user-facing analytics, usage-based billing, real-time personalization engines, real-time fraud detection, and more. It’s just impossible with poll-based ETLs.
Poll-based, batch ETLs place undue strain on source data systems and result in out-of-date data being loaded into downstream systems. In this blog post, I highlight several event-driven architecture patterns as alternatives to poll-based workflows.
At Tinybird, we believe that data should be processed as soon as it happens. Period. And we believe that data and engineering teams should use tools uniquely suited to handling and processing that data without adding undue strain to other systems and resources.
In this blog post, I’ll highlight several different event-driven architectural patterns that can be implemented across different source data systems, and discuss the pros and cons of these implementations.
Switching to an event-driven architecture
Event streaming, message queuing, and serverless functions are on the rise, and some enlightened individuals are shifting away from a polling mindset and towards a new paradigm: event-driven architecture.

The concept of event-driven architecture is quite simple. Data is almost always generated in response to some kind of event: a user clicks a button, a transaction gets processed, a file is uploaded. Why not use these events to trigger a real-time data ingestion process?
The idea behind event-driven architecture is simple: Use events to trigger data ingestion processes.
Event-driven architecture solves your two problems above, and it’s already gaining traction as a preferred method for data capture and integration that bypasses (or rather, parallels) the source data system.
Example use case for event-driven architecture
Consider a scenario that’s true for nearly every B2C business and most B2B businesses: You have a user-facing application that is built on top of backend APIs that talk to an application database like Postgres or MySQL.
When a user takes an action within your application, it calls an API and some data gets generated, which is then pushed to the database. As your company gains traction and the application adds more users and more features, you start scaling the database, desperately trying to keep up with an increasing frequency of single-row inserts coming from the API.
And then some bozo from marketing wants to run analytics on that data. So you run a batch export at night when most of your users are asleep and your application database server has some extra cycles, and you copy that new data over to your data warehouse. This is common. Most companies do this.
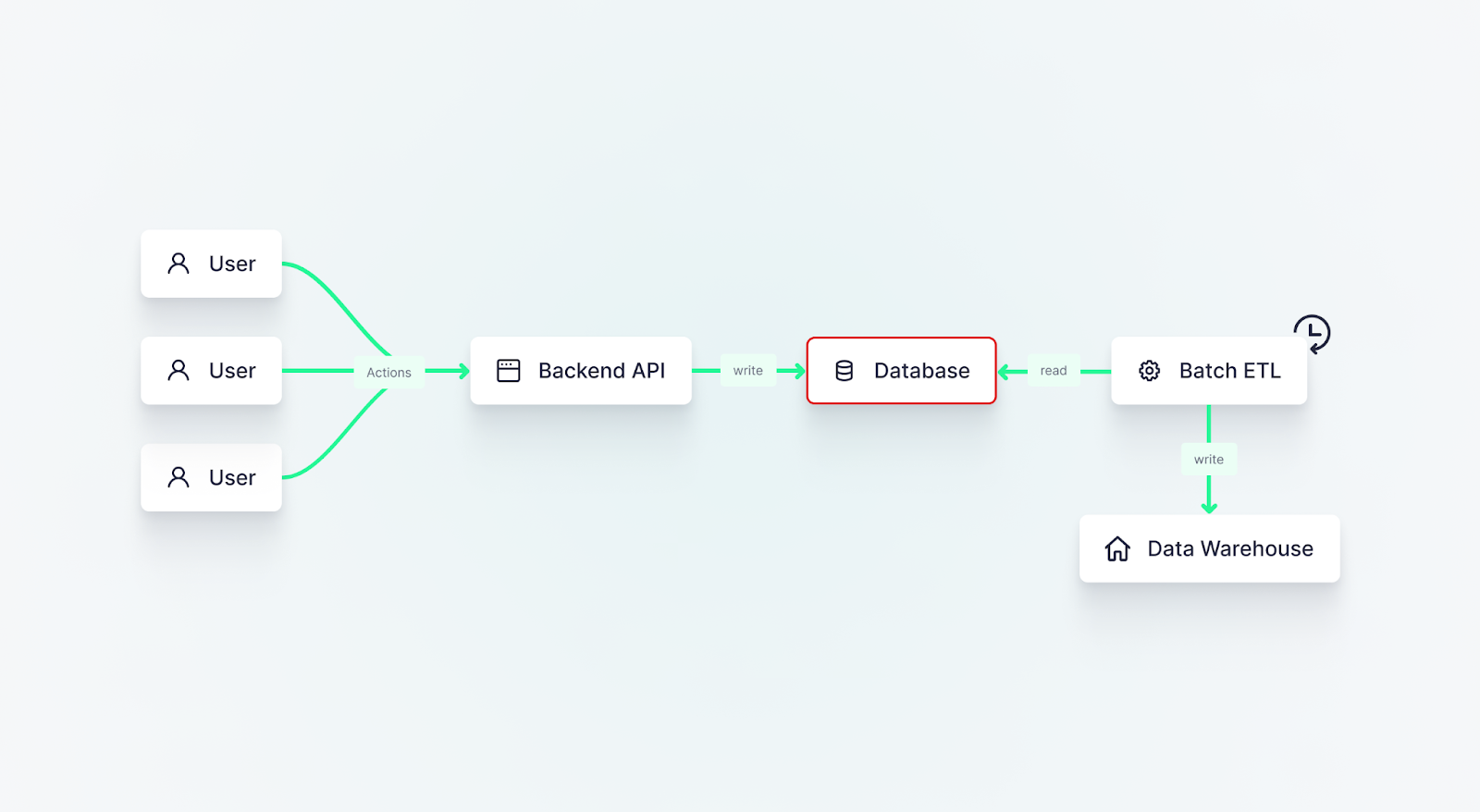
This is where you run into those two problems. The batch job puts an extra load on the database and ends up with stale data anyway. If you try to run the job more frequently to compensate, you increase the burden. It’s a catch-22 that can’t be solved by batch ETL.
The batch job puts an extra load on the database and ends up with stale data anyway. If you try to run the job more frequently to compensate, you increase the burden. It’s a catch-22 that can’t be solved by batch ETL.
So how could you avoid these two problems and still make the marketing bozos happy?
The key is in getting the data to the warehouse before (or at the same time) it hits the application database. In this scenario, you already have an event: the API call. You can use that to your advantage by pushing the event and its data onto a message queue at the same time that your backend inserts it into the application database.
With this event-driven approach, you completely avoid the need to extract this data from the application database later on; it’s already on the message queue.
They key to an event-driven approach is getting the data to the warehouse before (or at the same time) that it hits the application database.
This is a very efficient pattern, as the data has already been generated and is in memory on the backend. You’re simply sending it to one more endpoint.
But, as with all patterns, there is a downside: you must make code changes to your application’s backend. This work is often pushed down to the software engineers responsible for the backend, rather than to the team who manages the data(base).
This may or may not present a challenge in your organization. If the software team is backlogged with issues, this might not be a priority. It all depends on how quickly they can move, and how long you can wait.
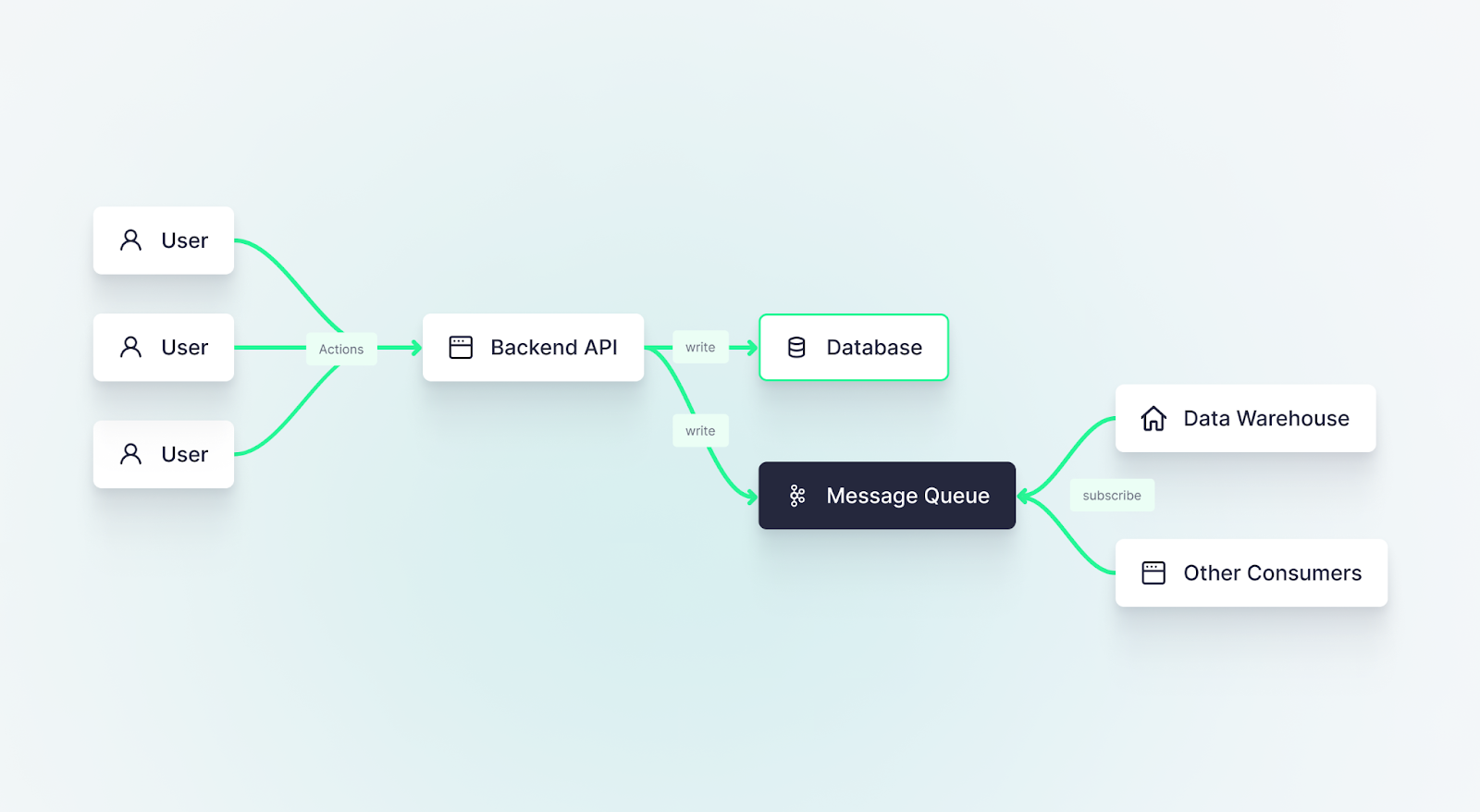
What about Change Data Capture?
Change data capture (CDC) is a proven implementation within event-driven architectures that you can use to avoid loading your database without touching your backend, and it comes with its pros and cons.
With CDC, you subscribe to a log of changes made in your database, like inserts, updates, and deletes, and push those changes somewhere else. If making code changes to your API is not an option for you, CDC is a great way to build event-driven pipelines after and apart from your application database.
Most application databases create a log of operations performed on the database. For some databases, this log is a core piece of the database’s architecture, such as Postgres’ Write Ahead Log (WAL). For others, it's a separate feature that needs to be enabled, like MySQL’s bin log.
In either case, it’s largely the same idea. The log is an append-only file of database changes (e.g. inserts, updates, deletes) and their data. Every operation is appended as a new line in time order, meaning you can use the log to reconstruct the state of the database at an exact moment in time by simply starting at the top and replaying each event one by one.
CDC tools watch this log file for new lines, capturing each change operation as an event, and pushing those events somewhere else. It’s particularly common for those events to be pushed onto an append-only event streaming system like Apache Kafka. Change operations can then be pushed into the desired downstream system, such as an analytical (OLAP) database.
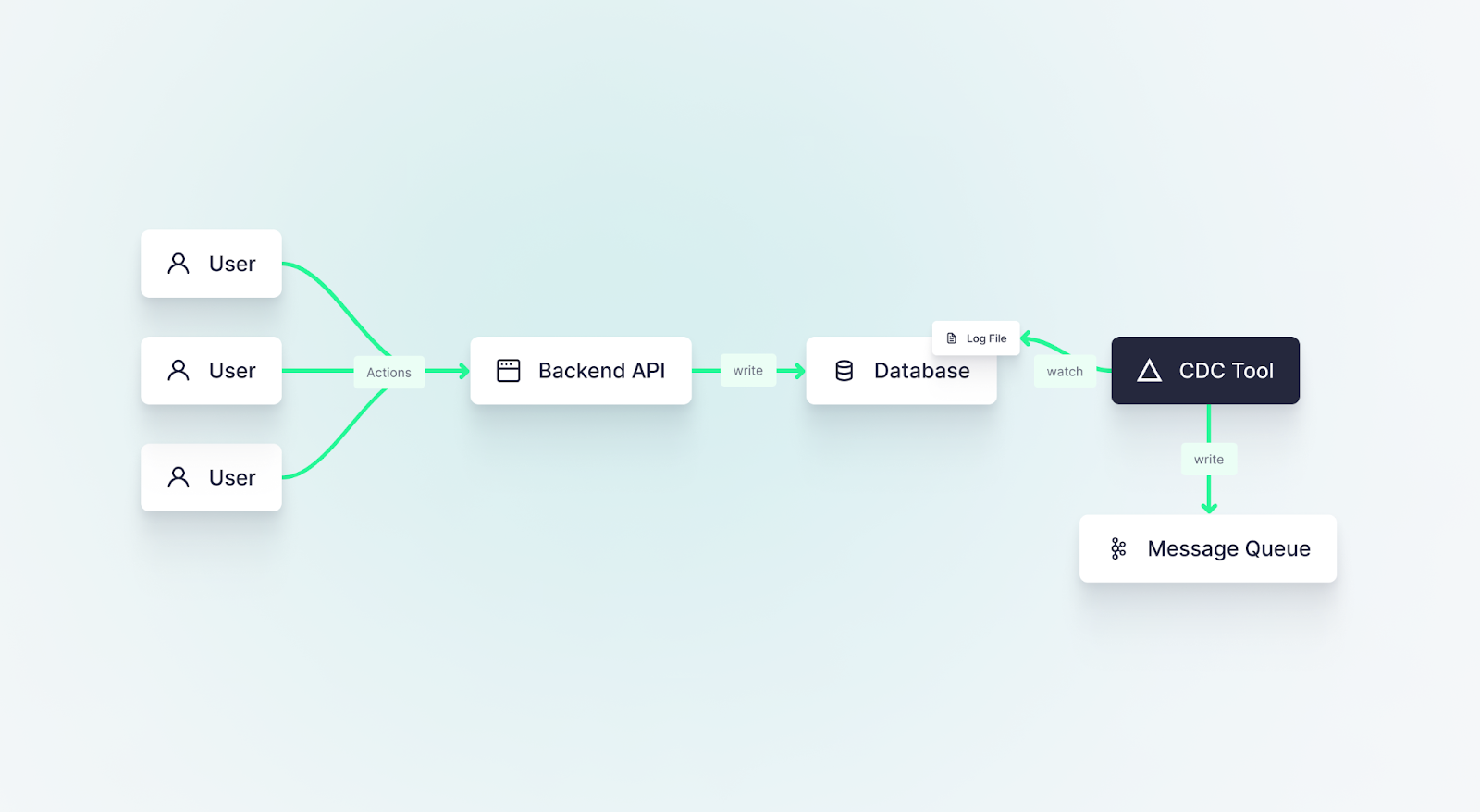
Change Data Capture is an attractive strategy if you can’t or don’t want to update your existing API code. The team that owns the database will typically own CDC implementations, and there are free, open-source frameworks like Debezium that make it relatively simple to get up and running.
As this strategy involves just watching a log file, it is much lighter weight than running delta queries against the database. New lines are appended to the log files immediately, so they are accessible in near real-time, keeping the latency to a minimum.
Change data capture systems are a good alternative to event-driven architectures when your backend engineering team can't or doesn't want to update backend APIs to send events to downstream consumers in parallel to database writes.
However, it’s not all sunshine and daisies. While reading the log file is lightweight, it still requires an additional agent process on the server which does increase the load. It adds yet another layer of consideration when scaling the application database, as you must consider how increased traffic will affect the resources needed by this agent.
It also introduces a net-new technology that your team may not be familiar with. While these tools are well-adopted and simple to start with, they can become complex to understand as you scale or if you stray outside of the beaten path.
Neither of these two strategies is wrong, and the end result is largely the same: a stream of real-time changes from your application stack. It’s up to you to determine the best approach.
Event-driven architectures aren’t just for databases
Of course, not every data ingestion scenario involves an application database. Maybe not even the majority. In this case, you might not have that 1:1 relationship between rows in a database and events generated. In many situations, you might actually receive data as files, either pushed from an internal service or even collected from an external data vendor.
Event-driven architectures can be applied to file systems just as with databases.
In days gone by (actually, it’s still pretty common today), a data producer or broker would set up a large File Transfer Protocol (FTP) server and dump files onto a big storage server. They’d give their clients FTP credentials, which the client would use in bash scripts that run daily to look for new files and copy them into internal shared storage. It’s a quaint little workflow that has served its purpose for years.
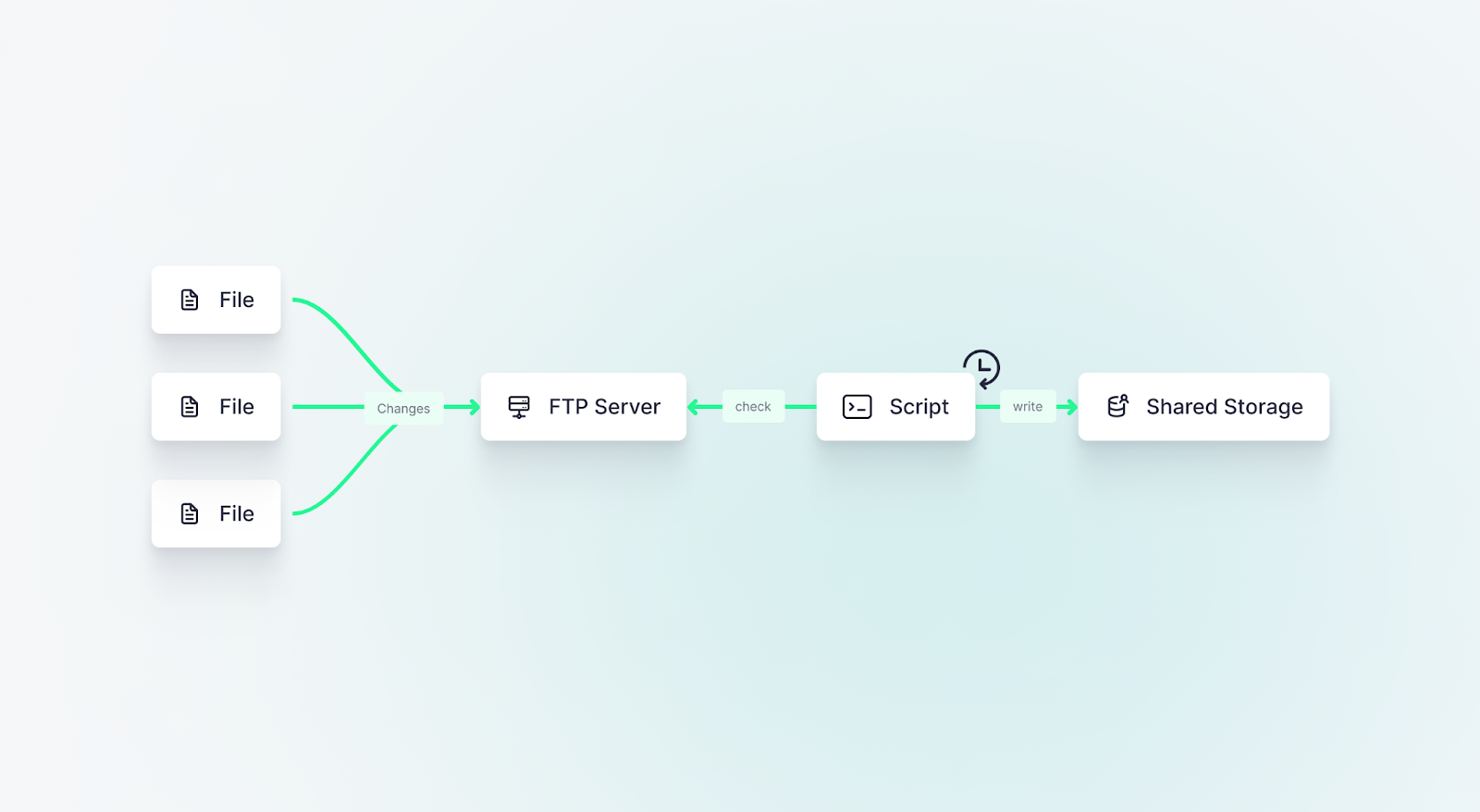
But, in addition to being outdated, it presents some problems:
- Somebody has to maintain a huge storage service. Any data producer or broker will need to build and maintain their own internal file storage system. This is expensive and painful.
- FTP is not flexible or scalable. FTP is not a particularly flexible protocol, especially if you’re downloading large files where a network failure could kill the transfer and you’d have to start from the beginning. It’s also hard to scale, so it is often slow. With many clients connecting and trying to download files simultaneously, it quickly slows to a crawl.
FTP is outdated and inflexible, yet it's still widely used today.
The nice thing about event-driven data pipelines is that they are flexible, and they can be adapted to many use cases, many source data systems, and the many different requirements of downstream data consumers. And they can be used with files just as with databases, albeit with a different set of tools.
Modern cloud vendors make event-driven file ingestion simple
Times have changed, and now we have fault-tolerant, scalable, and cost-effective file storage services like Amazon S3 and Google Cloud Storage.
Not only are these services just much more enjoyable to use than FTP, but they also make it possible to use an event-driven architecture for distributing and consuming files. Rather than constantly polling the storage service to say “Have new files arrived?” or waiting a full day and then saying “Give me all the files that arrived yesterday”, the storage service itself can create notifications about new files and push them out to a message queue, just as in event-driven architectures with databases.
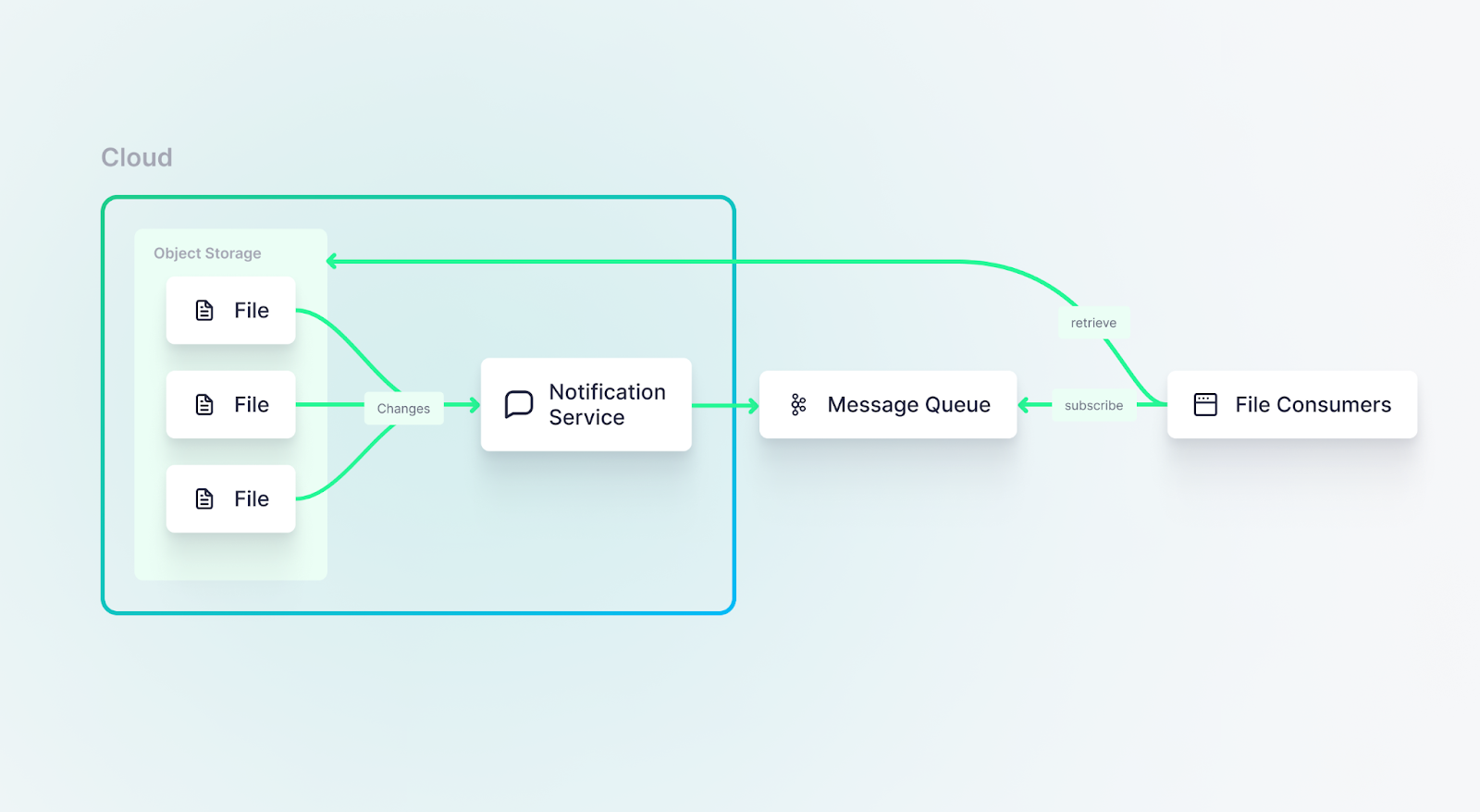
Downstream consumers, then, can simply subscribe to the message queue, and go fetch the file when they’re notified.
Files hosted in object storage on cloud vendors can leverage cloud-native notification services to notify downstream consumers of new or modified files.
This pattern is great for a couple of reasons:
- It’s way more robust than FTP. You don’t have to worry about maintaining an FTP server or your own file storage system. You don’t have to worry about network failures or slow client connections. You don’t have to worry about how to handle late files or files that have been re-uploaded to fix an error in the data. The storage service and message queue make most of these pains magically disappear.
- It increases data freshness. Of course, if you’re working with files, you’re never going to have the most fresh data, because it’s all been batched into a file already… but you can at least get the file as soon as it's ready, rather than hours or days later.
You can see how this mirrors the scenario with application databases. The source data system is different, but the implementation and benefits are very similar.
And because these modern cloud storage services have event notifications built into them that can be enabled with a single click, setting up event-driven file ingestion is quite easy. There’s very little extra work for the data creator, and the data consumer can utilize serverless services that make it trivial to adopt this new pattern.
Amazon, for example, has SQS and SNS which can be used to queue these events, and then you can attach any number of tools to respond to the event and handle the file. For example, you could use Apache NiFi to handle S3 Event Notifications that are queued in SQS.
Message queues: Flexible, durable, and efficient
So, whether you’re working with databases or files as a source data system, you can adopt these new patterns for an event-driven architecture. Instead of polling your database or file store for changes, you can emit events instead.
But what should you do with those events?
You have two options, really:
- Put events on a message queue or event-streaming platform, or
- Have events trigger processes directly
In the event-driven patterns described above, I referred specifically to option #1. This is the preferred pattern, and the one chosen by most.
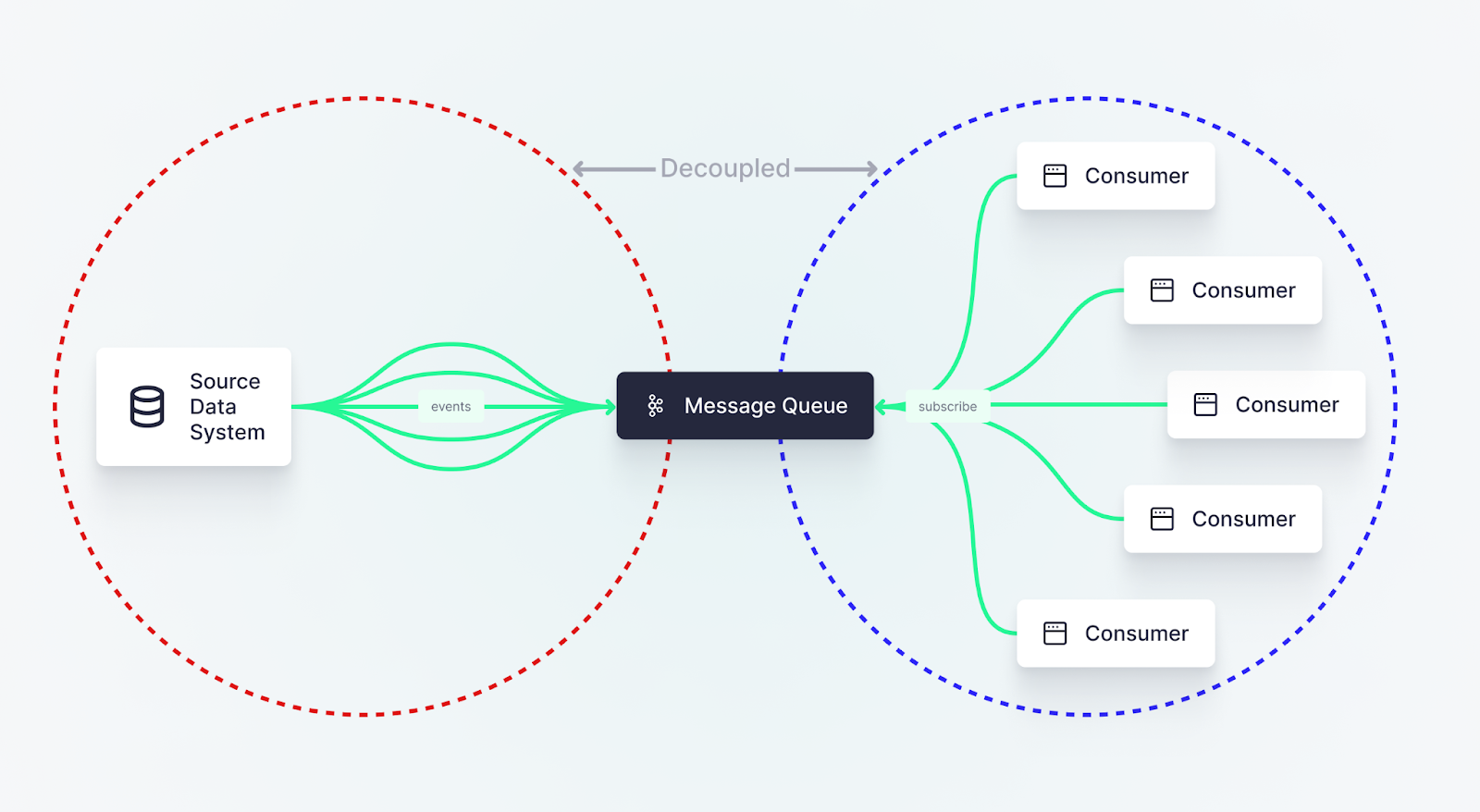
Why? The message queue is a durable, flexible, and efficient way to access data as it arrives. The beauty of the message queue is two-fold:
First, you solve the two problems that we started with by…
- Decoupling downstream use cases from the source data system, and
- Delivering data to consumers as soon as it's generated.
Second, most message queues allow for any number of downstream consumers to connect and subscribe to new messages. So if 4 different teams building 8 different things want access to the data in 16 different ways they can each do their thing without disrupting each other.
Message queues aren't the only way to handle event-driven real-time data ingestion, but they are by far the most popular because they decouple source data from consumers and are flexible enough to handle many different consumers at once.
If a team just wants to get changes every day, they can consume yesterday's messages as a batch. But, if another team wants to consume messages in real time, they can watch for new messages and automatically trigger their process as the data arrives.
This model fits perfectly with both databases and files, but it does require an additional intermediary service. And as your event-driven architectures and implementations grow, you’ll likely invest a lot of resources in maintaining and scaling your message queue or event-streaming platform. This can be a worthwhile tradeoff considering all the real-time use cases that event-driven architectures make possible.
So, could you skip the queue?
Yes, you could skip the queue
In some cases, you can have events trigger a process directly. For example, you can configure Amazon S3 to trigger an AWS Lambda function directly, allowing you to process the individual event immediately. You could replicate this model with other processing frameworks, like Apache NiFi or Apache Flink.
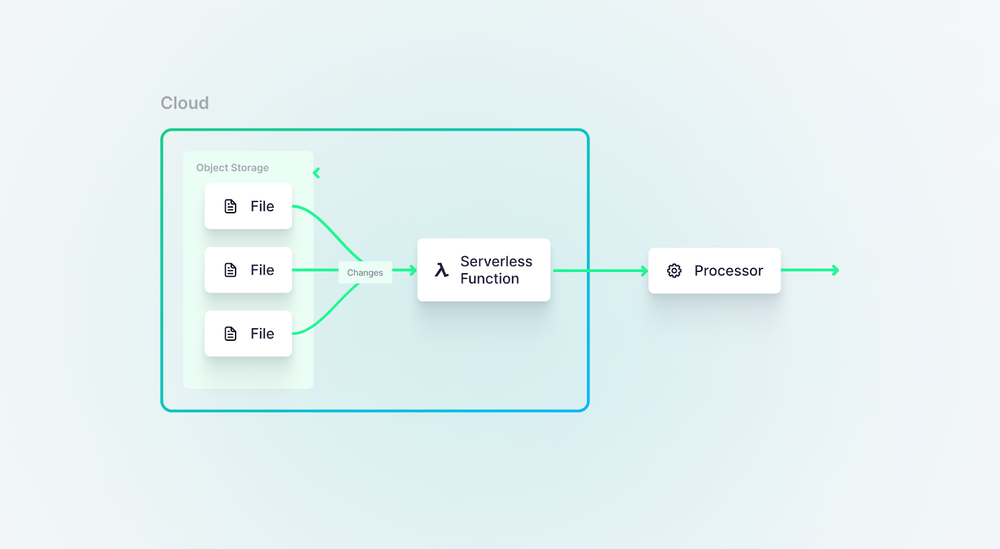
Now, there are pros and cons to this approach. The biggest pro is that you cut out yet another intermediate service, so it can be both cheaper and simpler. You also minimize latency and preserve data freshness, as you’re invoking the processing function immediately.
For more simple use cases, you could skip the message queue and use a serverless function to immediately trigger a process based on updates in source file systems.
However, there are also downsides. Message queues offer a level of durability that you might not get within your processing framework, which could make it more difficult to handle failures.
You also lose some flexibility. Since you’re eschewing the “pub/sub” model, you’re likely sending events directly to a single processor, rather than publishing them to a queue where multiple processors can subscribe as they choose.
If you send events into SQS, for example, you can connect a bunch of different tools, e.g. Apache NiFi, Apache Flink, Striim, StreamSets, or your own code that lives on a small, cheap EC2 server, to process the event. If you instead send events directly to a Lambda, you don’t have this flexibility.
It’s also harder to apply this pattern to databases. For files, you tend to have fewer events, as each event represents a big chunk of data (the file) and it’s easy to define a process that says “When I get a file, do this, then end”.
This is more difficult when you have a stream of changes from an application database. There is an overhead to starting and stopping a process, and if you’re receiving a constant stream of changes, you don’t want to spin up unique processes for each event. You’d normally want a long-running process that consumes events and handles them as a continuous stream.
Ultimately, either of these approaches can work for event-driven file ingestion, but you’re better off using a queue for database changes.
Conclusion
I’ve presented here some different patterns for event-driven data capture and integration from both databases and files. For databases, you can modify your backend code to emit events with your API calls before the database or choose Change Data Capture tools that watch database log files and emit events on changes after the database. For files, you can use cloud-native messaging services to emit events to a message queue or trigger processes directly with serverless functions.
Ultimately, any of these approaches will help you minimize the load on source data systems and increase the freshness of your data when it hits data-consuming processes.
Of course, not every use case requires fresh data. Business Intelligence (BI) reports, for example, can typically get by on daily batches. But operational and user-facing features like real-time operational analytics, in-product analytics, real-time personalization, fraud & anomaly detection, smart inventory management, sports betting & gaming, and more do need fresh data. If you’re using a poll-based methodology for capturing data from source systems, you simply have no way to access fresh data, and you cannot do these use cases. They are just impossible.
If you're trying to build any of these real-time use cases, or if you're evaluating tools to help you make the shift to event-driven architectures and real-time data processing, you should also consider giving Tinybird a try. Tinybird lets you unify streaming and batch data sources, join and transform them with SQL, and quickly share your real-time data products with internal stakeholders as high-concurrency, low-latency APIs. The Tinybird Build plan is free with no time limit, and there are even mock data streaming workflows in case you don't want to BYO data just to learn the tool.