


Today’s tech companies are strapped for cash, and data and engineering teams must turn their focus to building revenue-generating data products. Simply to survive, data engineers are ruthlessly prioritizing tools, infrastructure, and resources to retain the things that power differentiating use cases and cull the rest.
Simultaneously, data engineers are dealing with lots of streaming data, and wondering how to build and maintain the infrastructure to handle that data in real-time. Many are turning to real-time data platforms to support real-time data pipeline development and empower their organizations to build revenue-generating user-facing applications and use cases.
Real-time data platforms exist to simplify development of real-time data pipelines that power revenue-generating use cases.
Real-time data platforms have the potential to massively differentiate products built by data and engineering teams who learn how to use them effectively. In this post, you’ll learn what a real-time data platform is, its various components, and how to integrate real-time data platforms into your existing data stack.
What is a Real-time Data Platform?
A real-time data platform combines several core components of real-time streaming data architectures into a single tool. It is a comprehensive software solution that enables data teams and the stakeholders they support to ingest, integrate, analyze, and visualize data in real time.
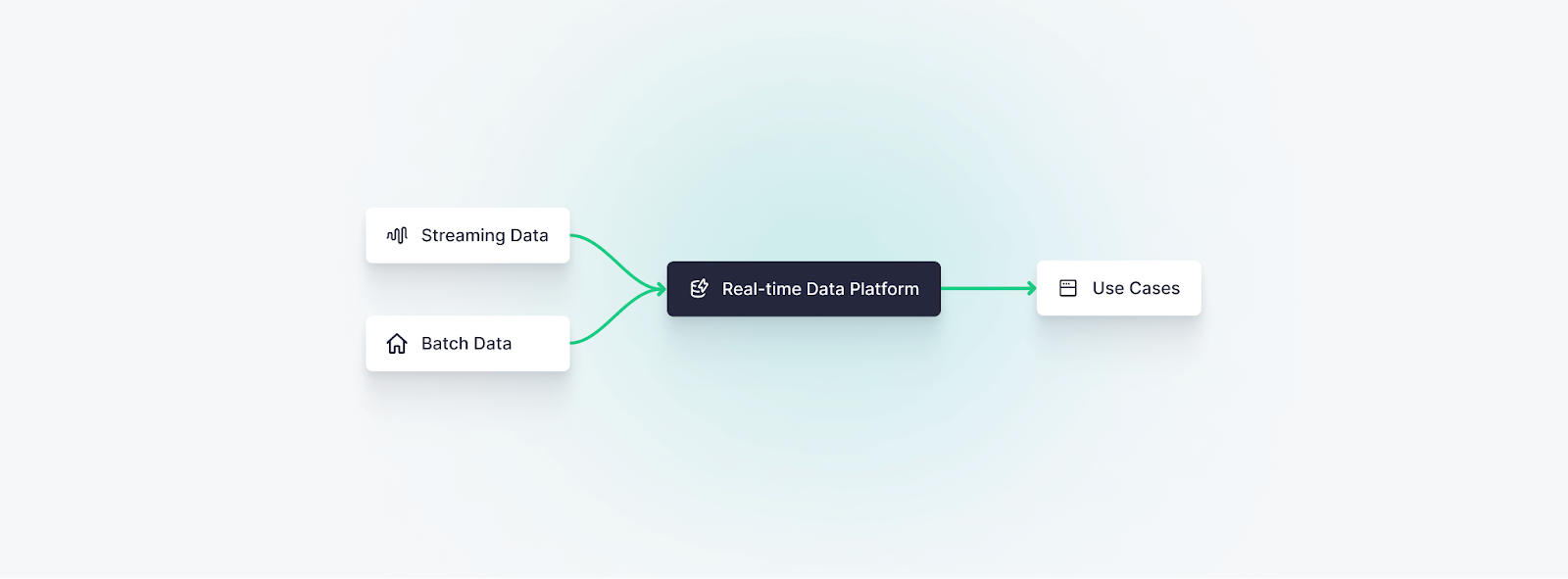
Real-time data platforms leverage modern technologies, such as streaming data platforms, real-time databases, real-time data analytics engines, machine learning, and low-latency API layers to process and publish data quickly for downstream consumers. They tightly couple these technologies to create a system that can be greater than the sum of its parts.
To better understand the real-time data platform, let’s break it down into its 3 core functions:
- Streaming data ingestion
- Real-time data pipeline development
- Real-time data access
Streaming data ingestion
Real-time data platforms are capable of real-time data ingestion, ingesting and storing streaming data at scale. Streaming data may come from a wide variety of sources, including sensors, social media feeds, websites, and transactional systems. In most cases, these event streams will be placed on a message queue or streaming data platform like Apache Kafka to be utilized by downstream consumers.
Real-time data platforms must be able to handle ingest frequency of millions of events per second from multiple concurrent data sources.
Most effective real-time data platforms offer native connectors for streaming platforms like Kafka, making it simple to subscribe to streaming data topics and persist streaming data into a real-time database.
The real-time database is optimized for high write throughput and low-latency read access. In cases where real-time analytics is desired for downstream use cases, the real-time database is optimized for OLAP workloads, utilizing a columnar storage system that supports high-speed queries that perform filters, aggregations, and joins on streaming and batch data sets.
Real-time data pipeline development
Unlike batch data pipelines, which transform and model data on a schedule, real-time data platforms are built to capture real-time data, transform it in flight, and publish real-time data products.
In contrast to traditional extract, transform, and load (ETL) batch processing workflows, real-time data platforms typically follow an extract, load, and transform (ELT) structure. In this approach, real-time data is captured from streaming data sources, loaded into a real-time database, and transformed using that database’s query engine. Real-time data platforms also allow for streaming data enrichment, enabling streams to be joined with other streams, dimensions, or fact tables, often using standard SQL JOIN semantics.
Real-time data platforms follow an "ELT" modality, enabling incremental materializations over data loaded into the real-time database.
Unlike batch ELT processing, however, real-time data platforms optimize for data freshness, low latency, and high concurrency.
In some cases, transformations may occur before the data is stored in the database using stream processing techniques, or within the database using incremental materialized views.
Real-time access layer
Fundamentally, real-time data platforms exist to support downstream applications that rely on streaming data and real-time analytics. As such, they almost always include a real-time API or access layer that exposes real-time data products to downstream data consumers.
The value of a real-time data platform lies in its ability to empower downstream consumers to build revenue-generating use cases without needing more glue code.
Unlike a standalone real-time database, which may require the use of an ORM or other “glue code” to build an API layer, a real-time data platform typically integrates the API layer directly within the platform, abstracting access to the database.
The Benefits of Real-time Data Platforms
Real-time data platforms are not the only way to build a real-time streaming data architecture, but they offer several benefits over alternative approaches. In particular, data and engineering teams turn to real-time data platforms for three main reasons:
- To simplify tooling decisions and deployment
- To focus on use-case development
- To reduce time to market
Real-time data platforms simplify tooling decisions
As described above, real-time data platforms integrate multiple components of a real-time data stack, namely streaming ingestion, real-time data modeling, and real-time API layers.
Using traditional approaches with open source or commercial tooling, data and engineering teams would need to construct real-time data architectures internally from piecemeal parts.
This causes problems in terms of both time to market - because tools must be deployed, integrated, and maintained individually - and data freshness and latency, since each integration involves an additional technical handoff that can introduce network latency (and potentially add egress costs).
Real-time data platforms shrink the tooling surface area, so engineers have to set up, integrate, and maintain fewer systems.
Real-time data platforms simplify the deployment of real-time data architectures by combining commonly used elements into a single platform and integrating with other common components of a real-time data stack, such as data warehouses and streaming data platforms, which makes it easier for teams to deploy, scale, and maintain their real-time data infrastructure.
Real-time data platforms free resources to focus on use cases
Stemming from the above benefit, real-time data platforms free up engineers to focus on use case development. An effective real-time data platform is a force multiplier, making it simple and fast to develop real-time data pipelines and share them with downstream applications and consumers.
When data and engineering teams attempt to build real-time data architectures without utilizing a real-time data platform, they generally spend more time deploying, integrating, and maintaining data stack components, rather than developing use cases.
Real-time data platforms abstract many complexities of real-time data pipeline development.
Real-time data platforms eliminate or reduce the need to hire dedicated DataOps, DevOps, or Data Platform Infrastructure resources to maintain new components of the data stack.
Real-time data platforms reduce the time to market
By simplifying tool decisions, abstracting integrations and glue code, and reducing resource consumption, real-time data platforms empower data and engineering teams to ship real-time data products and revenue-generating use cases to production, faster.
Ultimately, this is often the primary reason that engineers choose real-time data platforms over alternative tools and approaches. They can shed workloads that might otherwise take time away from developing differentiating customer experiences like predictive analytics, real-time fraud detection, real-time recommendation engines, real-time data visualizations, operational automation, and more.
As teams start moving from broad real-time concepts into the concrete components of a real-time data platform, one of the first challenges they face is consistently ingesting high volumes of events with low latency. For a deeper breakdown of the ingestion layer and how it shapes end-to-end real-time architectures, see this detailed guide on real-time data ingestion.
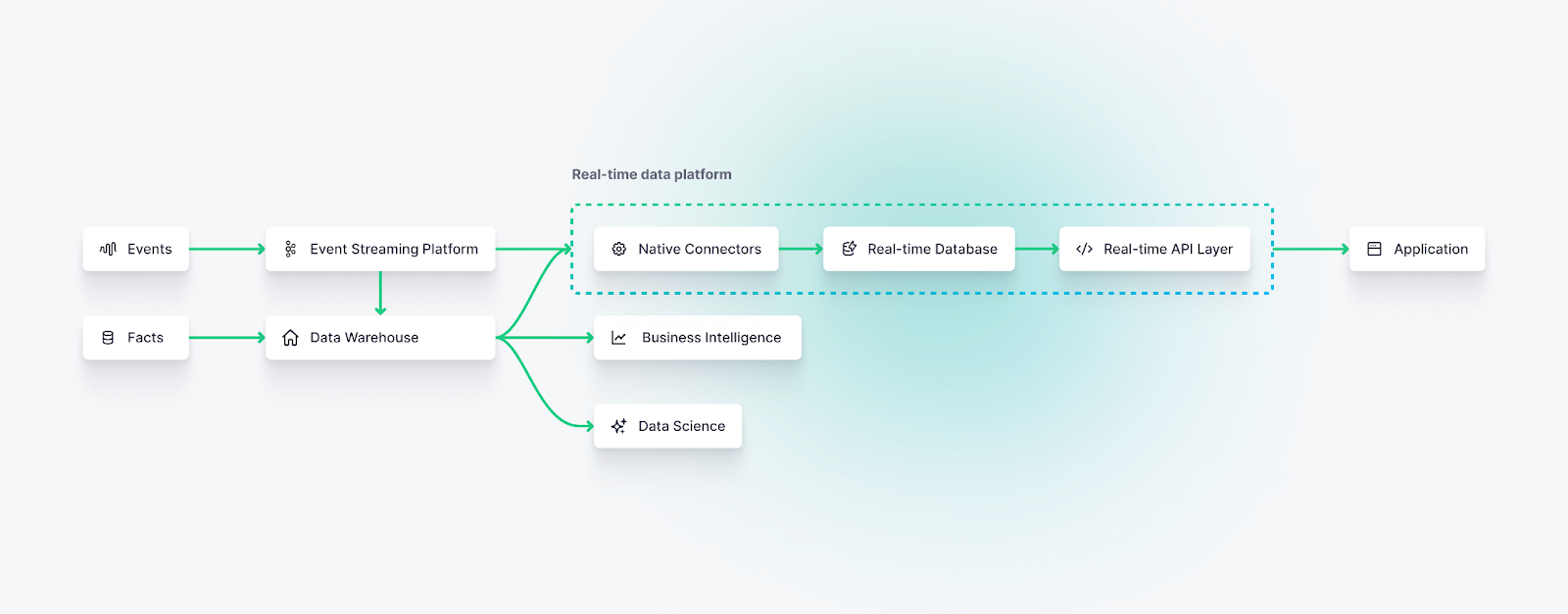
The Components of Real-time Data Platforms
As described above, real-time data platforms serve three functions: streaming ingest, real-time pipeline development, and real-time access. To accomplish this, they generally include the following integrated components:
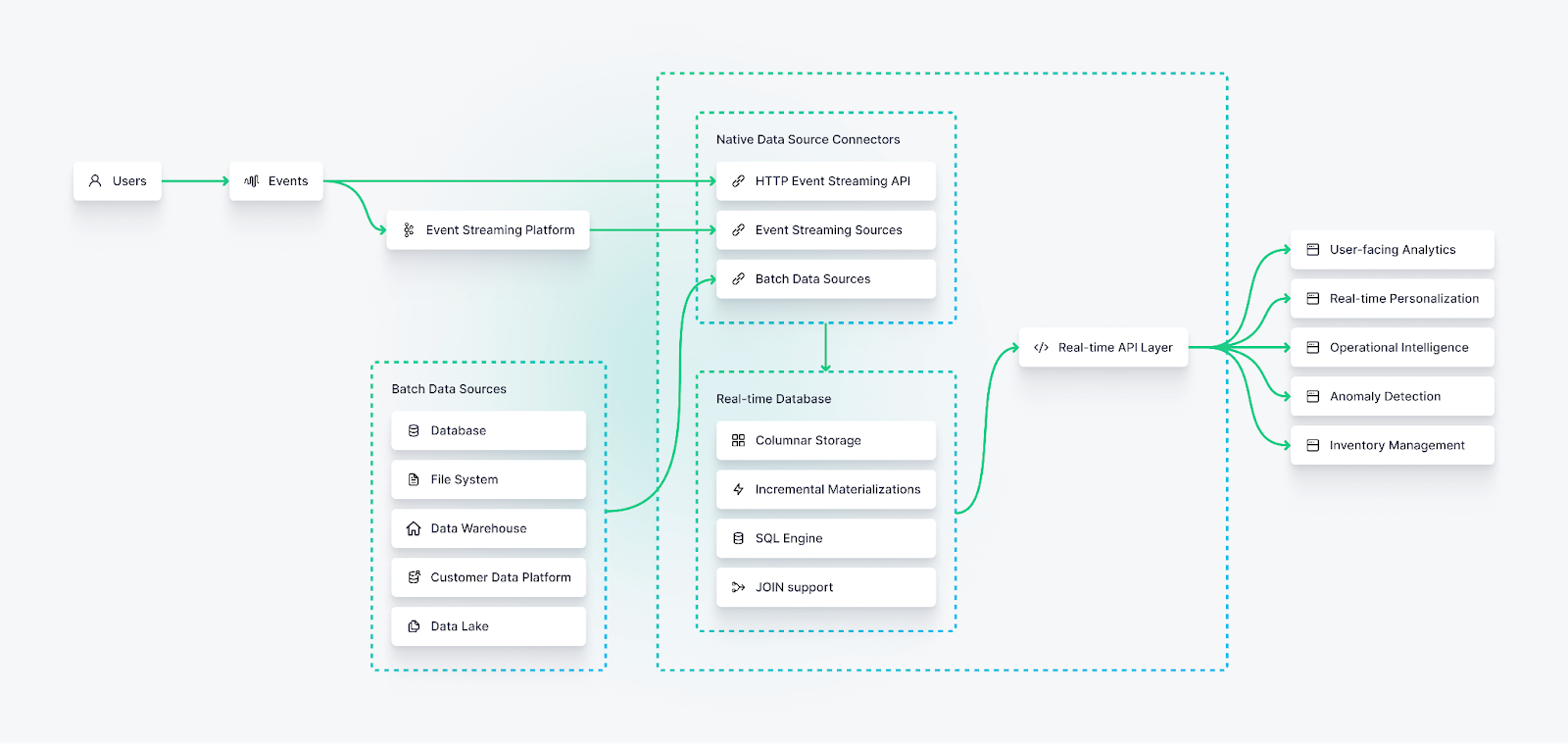
Native Data Connectors for Streaming and Batch Data
Real-time data platforms must be able to ingest and unify data from streaming sources, like IoT sensors, Kafka topics, or HTTP event streams, and batch sources, like data warehouses, data lakes, customer data platforms, application databases, and object storage systems.
As such, they often include native, first-party connectors that optimize write throughput and minimize latency when capturing data from various sources.
Real-time Database
To differentiate from simpler stream processing engines, a real-time data platform must include a storage layer optimized for both high-frequency ingestion and low-latency queries running complex analytical workloads.
This is why all real-time data platforms are built around a real-time database. Open source variants include ClickHouse®, Druid, and Pinot, while other commercial databases have emerged to fill the growing need for databases that can handle real-time data at scale.
High-Performance Data Processing
Often packaged as a part of the DBMS, an advanced data processing engine is a critical part of a real-time data platform. This component enables engineers to model metrics and transform data within real-time data pipelines.
The data processing layer can include stream processing, streaming analytics, materialized views, or real-time analytics engines that use SQL to enable filtering, aggregating, and joining streaming data sources with batch data sets.
Real-time data platforms may include a stream processing layer or may rely solely on the functionality of the database for real-time analytics.
Depending on the architecture and the desired tradeoff between cost and latency, the compute engine may be separated from the storage, or they may reside on the same machine. Because real-time data platforms often deal with “big data”, the storage and compute layers are often distributed to ensure scalability and fault tolerance.
As a part of a real-time data platform, data processing engines may be built on top of open source projects like Apache Spark or Apache Flink, or they may utilize the query engine of the real-time database.
Real-time API Layer
Real-time data platforms support open and scalable access to external applications and consumers through a low-latency API layer. By default, these APIs should be able to support millisecond response times over hundreds, thousands, or even millions of concurrent requests.
The API layer can power things like real-time, user-facing visualizations, automated decision-making systems, business intelligence dashboards, real-time recommendation engines, online machine learning algorithms, and more.
This layer can also enable real-time data integration with other downstream data tools, including data warehouses and data lakes.
How to integrate Real-time Data Platforms into your stack
Data and engineering teams have been given an imperative to maximize revenue generation and reduce costs, eschewing complex infrastructure projects and instead focusing on use cases. Real-time data platforms can be integral to a broader real-time data strategy that achieves these ends.
As with most modern tooling, data and engineering teams will face “build vs. buy” decisions when it comes to real-time data platforms. Large teams with vast resources may find cost efficiencies when building a real-time data platform from its various components.
If you're working with streaming data and need to enable downstream, revenue-generating use cases over that data, a real-time data platform will help.
The majority of engineering teams, however, will likely benefit from managed and/or serverless real-time data platform providers that abstract the data ingestion, data storage, data processing, and data access layers into a single, integrated tool.
Tinybird is a real-time data platform that allows data and engineering teams to unify streaming and batch data sources with a variety of native connectors, develop real-time data pipelines using an ergonomic SQL development environment, and empower their organizations to build revenue-generating use cases by exposing these pipelines as fully-documented, secure, and scalable APIs.
For data teams that want to take a big step forward in their real-time data strategy without investing time and resources in setting up and scaling infrastructure, Tinybird can be a force multiplier. If you’re interested in learning more about Tinybird, you can check out the documentation, sign up for a free-forever Build plan, or check out Tinybird’s pricing for Pro and Enterprise plans.