


Data engineers are grappling with surging data volumes while stakeholders increasingly demand real-time decision-making and user-facing features powered by data. This raises a fundamental question: How do you efficiently and quickly track and manage changes in your databases during periods of intense growth? One answer can be found in Change Data Capture (CDC), a technique that captures and routes changes made to a database in real time and sends them to a downstream system.
CDC has emerged as a powerful strategy that ensures all changes to data within a database are automatically captured and propagated to other systems. This automatic tracking reduces the strain on the databases themselves, minimizes latency, and ensures the data delivered is up to date.
This post explores Change Data Capture and its importance in real-time, event-driven architectures.
At Tinybird, we believe that data should be processed as soon as it happens. Period. And we believe that data and engineering teams should use tools uniquely suited to handling and processing that data without adding undue strain to other systems and resources. Change data capture upholds these beliefs, serving an important role within a larger event-driven architecture.
This post explores the concept of real-time change data capture, delving into its definition, architecture, and various techniques. You’ll learn why CDC is important in database and data warehousing environments, the advantages and potential drawbacks of CDC when compared with other real-time data handling methods, and its role in real-time data integration and real-time data analytics.
What is Change Data Capture (CDC)?
Change Data Capture (CDC) is a common method used by data engineers to track changes within a database. It is often used to replicate data from a relational database, like MySQL or PostgreSQL, to a downstream database system for analytical workloads, such as data warehouses like Snowflake, data lakes, or real-time data platforms like Tinybird.
With CDC, you subscribe to the changes in your source system, tracking operations like inserts, updates, and deletes. Each operation is captured and then sent to a downstream system. Where you send the captured data depends on your data pipeline and target workload, but most CDC solutions support a wide range of connectors for pushing data out to various data stores. It is particularly common for CDC solutions to push data out to a message queue, such as Apache Kafka, which makes it easier to handle high-volume changes and supports efficient [real-time data ingestion](https://www.tinybird.co/blog/real-time-data-ingestion) without worrying about the scalability of the data pipeline.
Change Data Capture tools subscribe to real-time updates from a source system (often a database) and write those changes to downstream systems (often a message queue or data warehouse).
The heart of CDC lies in the transaction log that most application databases produce. In databases like PostgreSQL, this log (known as the Write Ahead Log or WAL) is intrinsic to the database’s architecture. For others, like MySQL, the equivalent 'bin log' is an optional feature that can be activated. Regardless, the premise remains the same - the transaction log is a chronologically arranged, append-only file recording database changes and associated data.
CDC tools monitor this database transaction log file for new entries. Every operation is captured as an event and sent elsewhere. Often, these events are directed towards an append-only event streaming system such as Apache Kafka. The modification operations can then be dispatched into the preferred downstream system like a real-time database or data warehouse.
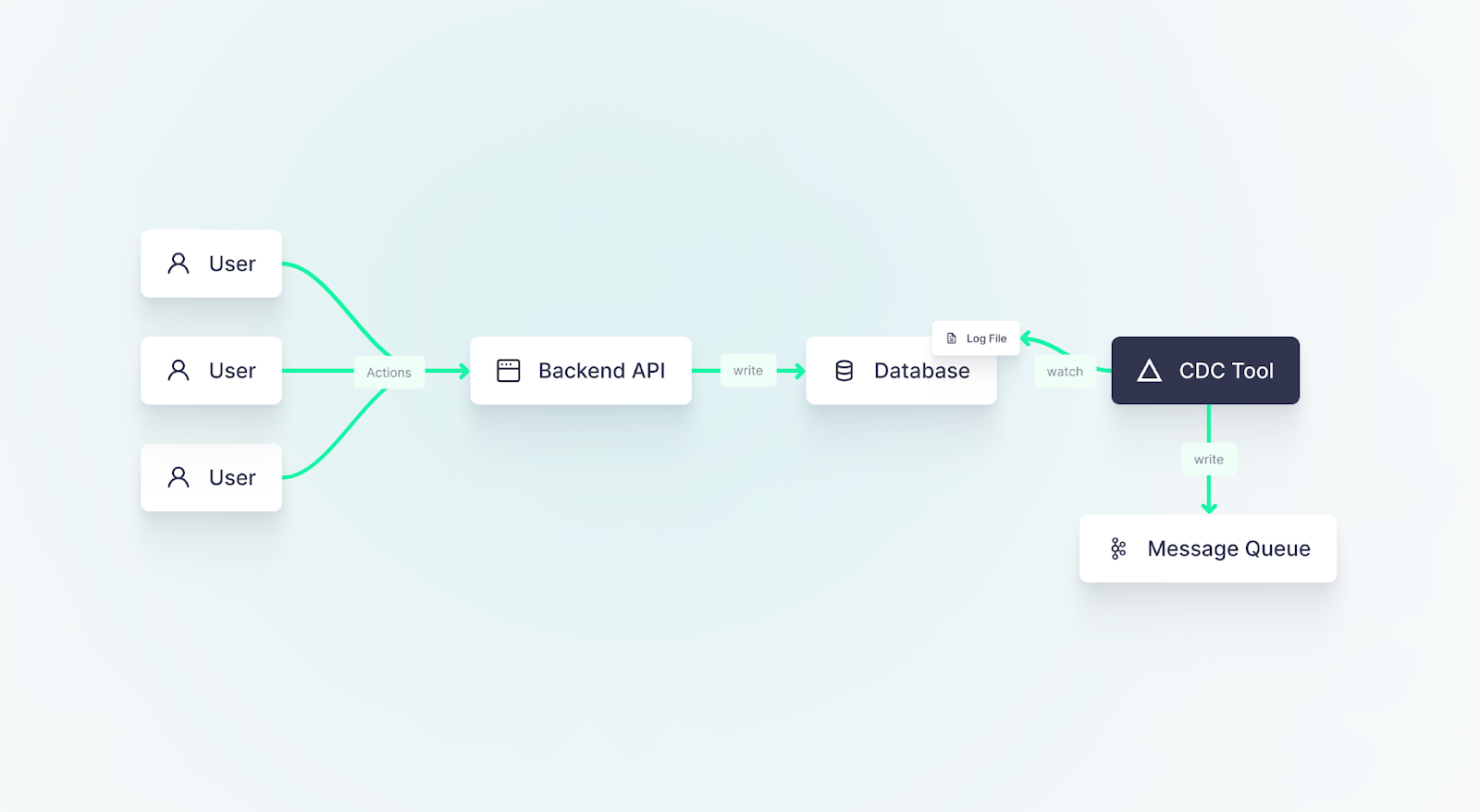
In event-driven architectures, CDC is a great option for capturing time-sensitive data in near real-time when it is not feasible to modify the application backend and API. Typical log-based CDC avoids placing too much additional load on the source system, which makes it preferable to other CDC methods that might execute queries on the database to read data from the source tables.
But, like anything, it's not without its drawbacks. CDC requires you to introduce new tooling to your stack and, while many CDC tools have been widely adopted, they can still be quite complex. Debezium is perhaps the most popular CDC tool today and has been implemented within other frameworks that abstract some of the complexity, such as Kafka Connect and Apache Flink.
Why is Change Data Capture important?
A major advantage of change data capture for data engineers is its role in enabling real-time data integration. With the accelerating pace of business and its increasing reliance on real-time data, data engineers are frequently tasked with ensuring data is consistently available in near real-time for user-facing applications, automation, and operational analytics. CDC supports this need by streaming changes from the source database to the target systems as they happen. This minimizes latency, keeps data fresh, and improves the accuracy and reliability of downstream systems, especially when paired with modern [real-time data platforms](https://www.tinybird.co/blog-posts/real-time-data-platforms).

Pros and Cons of Change Data Capture
Change Data Capture (CDC) often has an important role to play within streaming data architectures, but it also introduces challenges that need to be weighed carefully before implementation.
Strengths of Change Data Capture
Let's begin with the strengths:
- Real-time Data Updates: The crux of CDC lies in its ability to offer real-time or near-real-time data updates. This ability allows businesses to stay nimble, adapting to situations as they unfold. Immediate access to changes in source systems - and real-time analytics run on those changes - enables businesses to make more informed decisions promptly, thereby giving them a competitive edge in rapidly evolving market environments.
- Efficiency: CDC significantly reduces the load on source data systems by dealing solely with changed data. Batch ETL workflows initiated by downstream systems, such as data warehouses or orchestrators, place an undue load on the source system in the form of queries that often scan the full table, which can be both time-consuming and resource-intensive. Instead, by focusing only on new or updated data since the last checkpoint, CDC efficiently captures the required change data without touching the source database. This leads to improved overall performance and less strain on the system’s resources.
- Real-time Insights and Automation: With access to fresh data, organizations can make their analytics more precise and meaningful. As CDC offers near-real-time data, it ensures that the analysis and subsequent insights or automation are based on very fresh information. This can lead to more accurate forecasts, better user experiences, stronger strategic planning, and improved business outcomes.
Change Data Capture captures real-time changes at the database or source system without placing a significant load on that system.
Weaknesses of Change Data Capture
Despite its strengths, CDC does create some friction for data engineers who opt for it:
- Complexity: Reading a log file reading is a relatively lightweight operation in terms of CPU and memory, but it still adds an agent process on the server. This new dependency further complicates scaling the application database, as you need to account for how additional traffic will impact the resources required by this agent.
Moreover, it brings in a new technology with which your team might not be acquainted. While CDC tools are widely used, well-documented, and easy to start with, they can become complex to understand as you scale or deviate from the happy path. - Resource-intensive: Depending on the volume of data changes, CDC can become resource-intensive. While CDC reduces the load on source systems by capturing only changed data, if changes happen very frequently, it will begin to exert pressure on the system’s resources. So, while CDC generally minimizes resource use compared with most alternatives, it still demands care when planning and scaling infrastructure.
- Limited Scope: While many Change Data Capture tools and frameworks have a good variety of source and target connectors, they are still limited by their ability to integrate with other systems. In most cases, the source system is a database, and CDC tools must use a log file or some other mechanism to subscribe to changes. One alternative, event-driven approach to CDC that offers more flexibility is to modify the backend code and APIs to instead send events directly to an event streaming queue or real-time data platform.
Who benefits from Change Data Capture?
Change Data Capture (CDC) is a key data pipeline technology that, when properly implemented, can shoulder some of the load from various data-intensive roles:
- Database Administrators: CDC simplifies tasks by maintaining data accuracy and synchronization across systems.
- Data Analysts: CDC makes real-time data accessible faster, enhancing the accuracy and timeliness of the business intelligence and real-time analytics systems analysts are trying to build.
- Data Engineers: Without CDC tooling, data engineers would need to build and maintain batch data pipelines that extract data from source systems, analyze it for changes, and load it into downstream systems. With CDC, they have a purpose-built tool that simplifies real-time processing of changes made within a database.
Should you use CDC or ETL for data replication?
CDC and ETL (Extract, Transform, Load) are both data integration approaches used in data replication, but they serve different purposes and have distinct use cases.
ETL is a batch-oriented process that involves extracting bulk data from one or more source systems, transforming it to conform to a target schema, and then loading it into a destination system or data warehouse. ETL processes typically run on a scheduled basis (e.g., daily, hourly) rather than in real time. Due to the potential for higher latency, ETL is more common when the downstream use case doesn’t demand fresh data. This is common for business intelligence and reporting.
ETL is a batch process. It doesn't capture real-time data, and it often places a load on the source system. That said, it can be more flexible than CDC by offering the ability to transform data before propagating it to the downstream system.
Advantages of ETL vs CDC
- Data transformation: By design, change data capture doesn’t modify change operations, favoring precise replication that ensures upstream and downstream systems match. While this is often desirable, there are scenarios where an ETL process may be preferred, especially when downstream systems require a different data schema or format. ETL allows you to perform data cleansing, aggregation, and other data transformations during the process, ensuring the data is in the desired format for analysis or reporting.
- Independence from database logs: ETL doesn't rely on database logs, making it more portable and independent of specific database implementations. CDC tools must rely on source and sink connectors to move data between systems, whereas ETL workflows can often utilize SQL and orchestrators, making them more flexible.
Disadvantages of ETL vs CDC
- Not real-time: ETL processes are typically scheduled in batches, introducing a delay between data changes in the source system and their availability in the target system. When use cases supported by the downstream system demand real-time data, ETL might not be suitable for replication.
- Increased resource usage: Unlike CDC tools, ETL workloads aren’t optimized for capturing change data. What they gain in flexibility, they sacrifice in efficiency. ETL workflows often query source systems directly, processing and transferring larger volumes of data compared to CDC. This generally results in higher costs associated with compute and networking.
Most organizations will use a combination of both CDC and ETL to leverage the advantages of both approaches in different parts of their data integration and replication pipelines. A combination of CDC and ETL can be particularly beneficial to support full database migrations, where ETL can migrate historical data and CDC keeps the two systems in sync until the migration is complete.
Considerations for Real-Time Change Data Capture
Choosing the right Change Data Capture implementation requires an understanding of the use case, workload, and the systems involved. Here’s what you need to think about when adding CDC to your data pipeline.
What is the use case and workload?
CDC tends to be most appropriate for use cases where access to new data is time-sensitive, often because you are moving datasets from a database supporting an application or microservice to another operational or user-facing system.
For example, change data capture might power automated supply chain optimization systems, which need to work with fresh data to ensure that stock levels keep up with customer demand. Or consider a user-facing feature in gaming, where user actions can be analyzed in real time and then fed back into the user’s session, perhaps to show relevant prompts for user activation or to personalize the gaming experience.
For use cases that are not time-sensitive, a more simple batch ETL data replication strategy might be more appropriate.
What mechanism does the source system have to expose change data?
The database transaction log is the most common mechanism for capturing change data capture, but it’s not the only one. Timestamp, snapshot, and trigger-based CDC methods can also be used depending on the source system and its mechanism for exposing change data. Different databases, and different CDC solutions, may have different support for these different CDC methods. You must understand which source systems you will be working with, and research the CDC methods they support.
CDC frameworks like Debezium have wide support for a variety of source databases, including PostgreSQL, MySQL, Microsoft SQL Server, and Oracle database.
However, certain proprietary databases can be more challenging when they don’t play nicely with third-party CDC tools. For example, Oracle sells its own CDC solution for Oracle database (Golden Gate) and has been reluctant to open up its database to third-party solutions. Similarly, though Microsoft has been more supportive of open-source CDC solutions, it also offers custom CDC solutions for SQL Server. Third-party CDC solutions are typically forced to use less feature-rich and efficient methods to extract data, which can pose scalability challenges at high volumes.
Many application databases have built-in mechanisms that support third-party Change Data Capture tools, but some proprietary databases do not.
Does the target system support real-time CDC streams?
Next, consider whether the target system supports a real-time CDC stream natively. Most systems don't, though there are exceptions. Even if your target system does support CDC streams, you may still require an intermediary messaging queue like Kafka.
Kafka serves as a buffer to handle individual events, which can then be integrated into the target system. Kafka exposes a well-known protocol that has wide support in the data ecosystem, so it is more likely for this protocol to be supported by target systems.
Moreover, determine whether your target system supports the update/delete semantics of relational database management systems (RDBMS). Many analytical systems have limited or no support for updates and deletes, which can mean that the target system does not maintain a like-for-like representation of the source system. This can require additional configuration or transformations in the target system, such as deduplicating inserts to simulate updates, or applying a graveyard flag to deleted rows.
Wrap-up
As you navigate the challenges of big data and real-time analytics, Change Data Capture (CDC) can be your friend. As a purpose-built solution that’s ideal for capturing changes within application databases or other source systems and routing those to downstream workloads, it can effectively solve a common challenge that data engineers face when building real-time data pipelines.
Of course, CDC doesn’t come without its challenges. It’s a new tool to adopt, and it still adds resource constraints to application infrastructure, which can pose a risk for critical and user-facing applications.
If you're trying to build real-time use cases, or if you're evaluating tools to help you make the shift to event-driven architectures and real-time data processing, you should also consider giving Tinybird a try (it’s free with no time limit).
As a real-time data platform, Tinybird can offer combined benefits that neither CDC nor ETL can handle on their own. With a number of native source connectors, including popular event streaming platforms like Kafka or Confluent, Tinybird easily ingests change data in real time. You can then create real-time transformations using SQL and Materialized Views, and expose your real-time data pipelines to target systems as low-latency, high-concurrency APIs.
FAQs
1. What is Change Data Capture (CDC)?
Change Data Capture, or CDC, is a method of tracking and recording changes made to the data in a database. This information can be used in many contexts such as ETL (extract, transform, load) processes, event-driven architectures, and real-time analytics.
2. Why is CDC important?
CDC is crucial for maintaining efficient data ecosystems. It ensures immediate access to changes, making data integration more timely and improving the accuracy of analytics and insights.
3. How does Change Data Capture work?
CDC works by monitoring the database for changes. When a change occurs (like an update, delete, or insert operation), the CDC process captures that change and ensures it's reflected in other systems as required. CDC is well-supported for common databases like MongoDB, Postgres, and MySQL.
4. What are the benefits of using CDC?
CDC offers real-time data updates, reduces load on systems by only dealing with changed data, and provides fresh data for analytics, leading to more accurate insights.
5. What are the challenges of using CDC?
Implementing and managing CDC can be complex, requiring deep technical knowledge. Additionally, depending on the volume of data changes, CDC can be resource-intensive.
6. Who can benefit from CDC?
Various roles and industries can leverage CDC. Database administrators can streamline their tasks, data analysts can access up-to-date data for more accurate reports, and industries such as healthcare, finance, and retail can have real-time data updates for improved decision-making processes.
7. Can CDC be used in real-time analytics?
Yes, CDC is often used in real-time analytics or streaming data architectures to provide the most current data for analysis. Where ETL fails to deliver real-time data to analytics systems, CDC pairs nicely with real-time analytics architectures that demand up-to-date data.
8. Is CDC suitable for big data scenarios?
Yes, CDC is particularly beneficial in big data scenarios as it only processes changed data, reducing the resource load. It allows large databases to be updated more efficiently.
9. How do real-time data platforms like Tinybird support CDC?
Real-time data platforms like Tinybird simplify CDC implementation and management by providing a scalable storage and real-time analytics layer to capture change data. By pairing change data with a real-time data platform, data engineers can get the best of CDC and ETL in a well-integrated ecosystem designed for real-time use cases.
10. What is the role of CDC in event-driven architectures?
In event-driven architectures, CDC can provide real-time updates for events. When a change occurs in the data source, an event is generated, which triggers actions in other parts of the system. This way, the entire system can respond in real-time to changes.