Stream from AWS Kinesis¶
In this guide, you'll learn how to send data from AWS Kinesis to Tinybird.
If you have a Kinesis Data Stream that you want to send to Tinybird, it should be pretty quick thanks to Kinesis Firehose. This page explains how to integrate Kinesis with Tinybird using Firehose.
1. Push messages From Kinesis To Tinybird¶
Create a token with the right scope¶
In your workspace, create a Token with the Create new data sources or append data to existing ones scope.
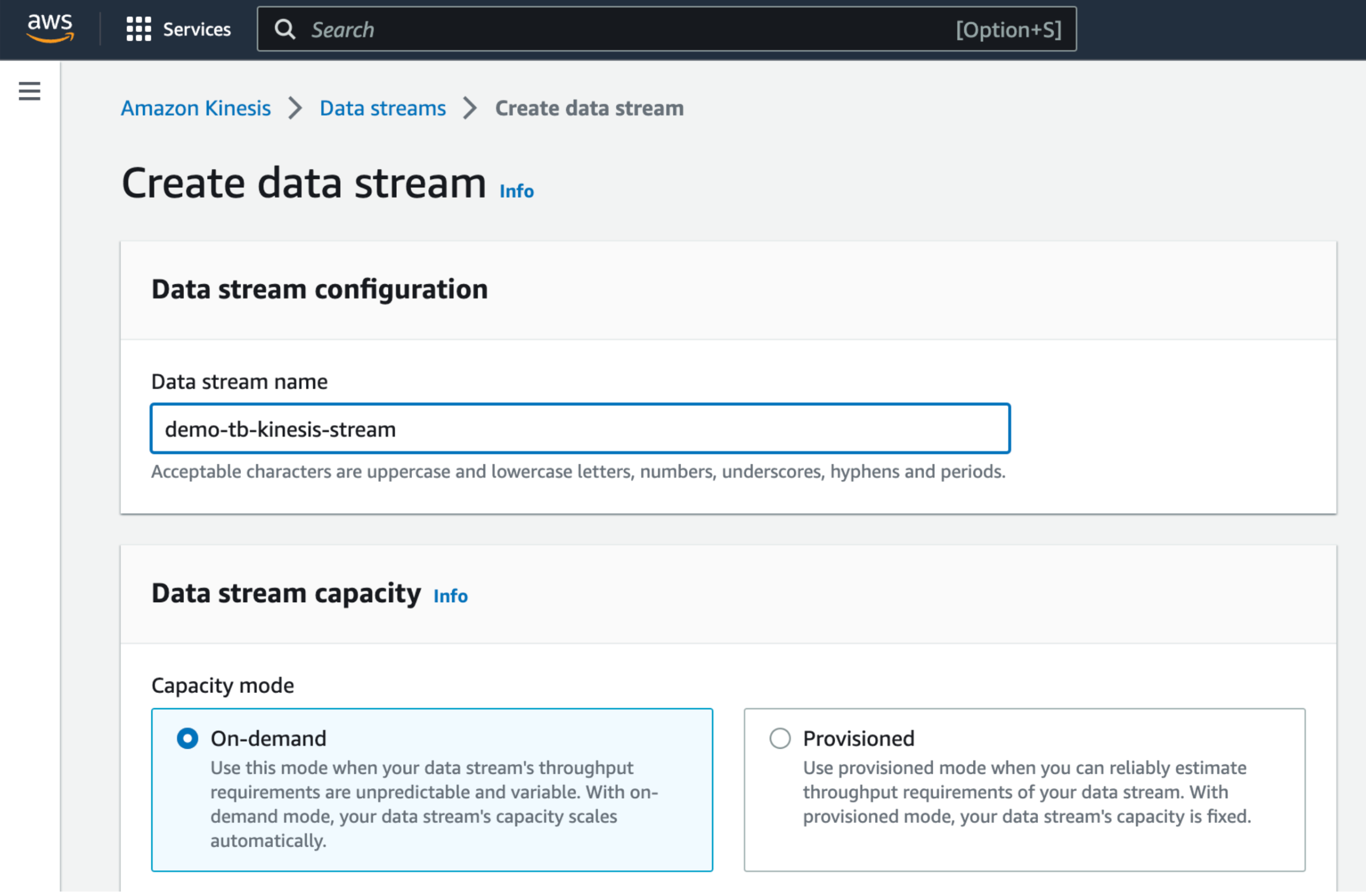
Create a new data stream¶
Start by creating a new data stream in AWS Kinesis. See the AWS documentation for more information.
Create a Firehose delivery stream¶
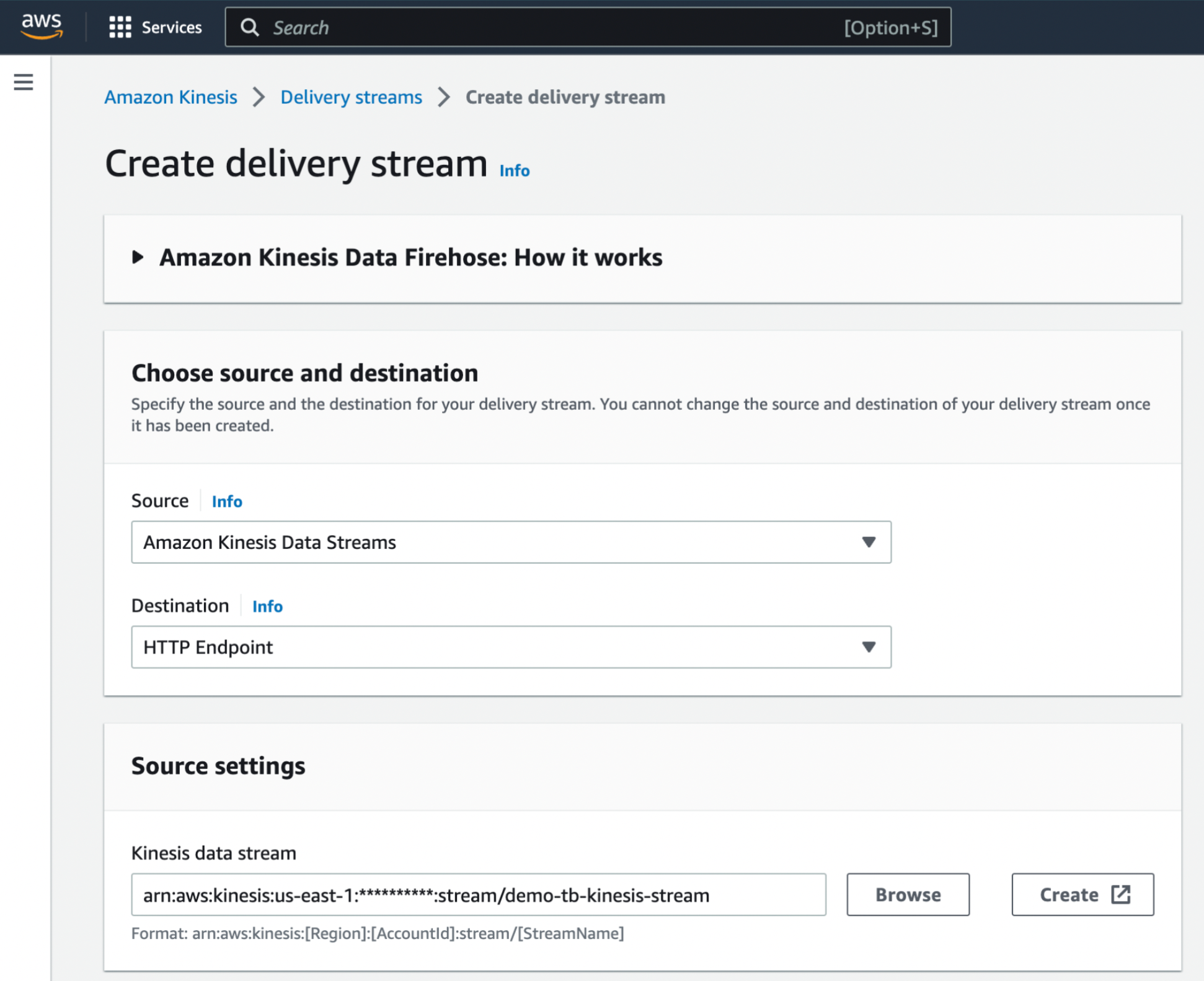
Next, create a Kinesis Data Firehose delivery stream.
Set the Source to Amazon Kinesis Data Streams and the Destination to HTTP Endpoint.
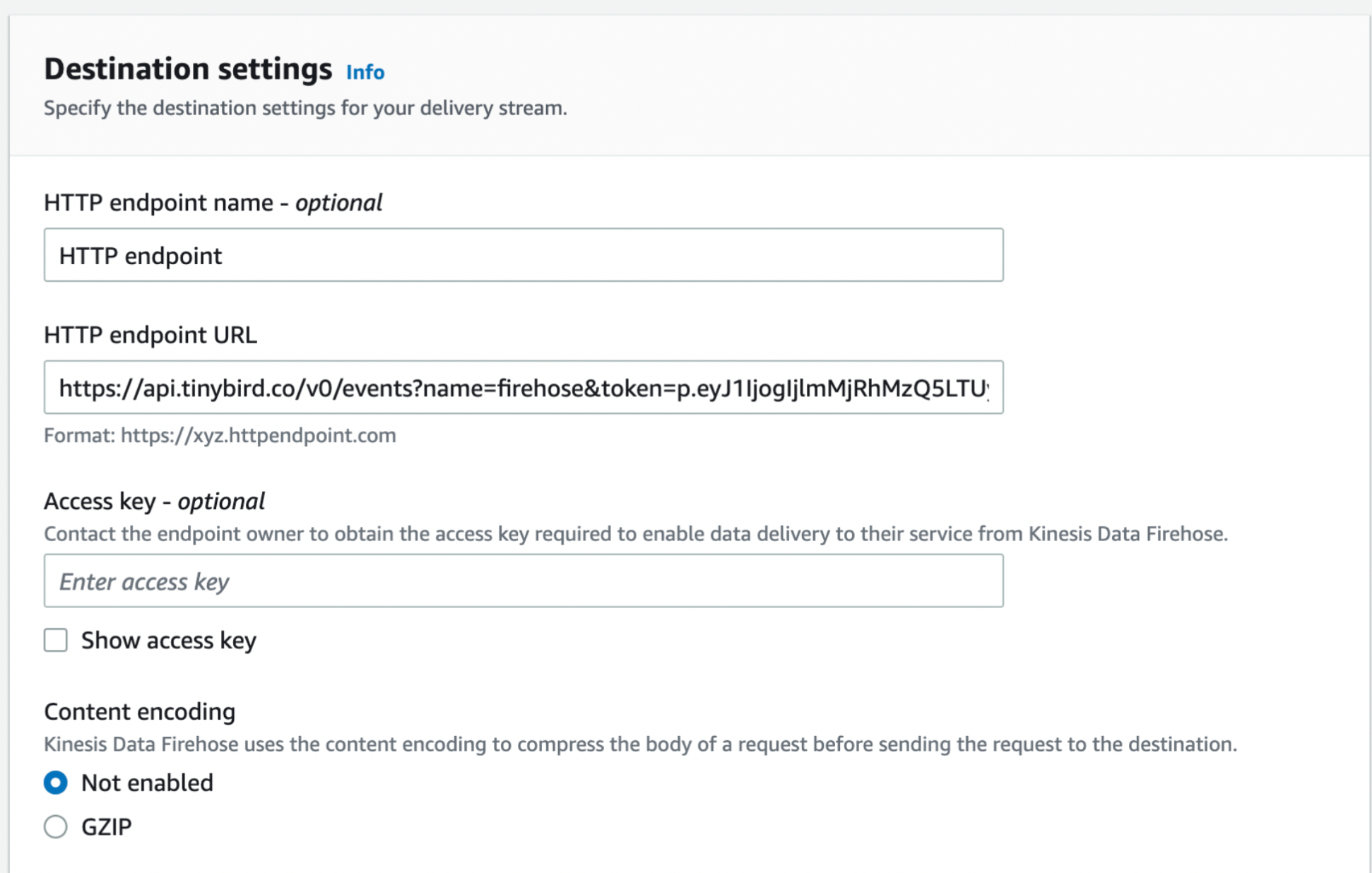
In the Destination Settings, set HTTP Endpoint URL to point to the Tinybird Events API.
https://<your_host>/v0/events?name=<your_datasource_name>&wait=true&token=<your_token_with_DS_rights>
This example is for workspaces in the GCP --> europe-west3 region. If necessary, replace with the correct region for your workspace. Additionally, note the wait=true parameter. Learn more about it in the Events API docs.
You don't need to create the data source in advance; it will automatically be created for you.
Send sample messages and check that they arrive to Tinybird¶
If you don't have an active data stream, follow this python script to generate dummy data.
Back in Tinybird, you should see 3 columns filled with data in your data source. timestamp and requestId are self explanatory, and your messages are in records\_\data:
2. Decode message data¶
Decode message data¶
The records\_\data column contains an array of encoded messages.
In order to get one row per each element of the array, use the ARRAY JOIN Clause. You'll also need to decode the messages with the base64Decode() function.
Now that the raw JSON is in a column, you can use JSONExtract functions to extract the desired fields:
Decoding messages
NODE decode_messages
SQL >
SELECT
base64Decode(encoded_m) message,
fromUnixTimestamp64Milli(timestamp) kinesis_ts
FROM firehose
ARRAY JOIN records__data as encoded_m
NODE extract_message_fields
SQL >
SELECT
kinesis_ts,
toDateTime64(JSONExtractString(message, 'datetime'), 3) datetime,
JSONExtractString(message, 'event') event,
JSONExtractString(message, 'product') product
FROM decode_messages
Recommended settings¶
When configuring AWS Kinesis as a data source, use the following settings:
- Set
wait=truewhen calling the Events API. See the Events API docs for more information. - Set the buffer size lower than 10 Mb in Kinesis.
- Set 128 shards as the maximum in Kinesis.
Performance optimizations¶
Persist the decoded and unrolled result in a different data source. You can do it with a materialized view: A combination of a pipe and a data source that leaves the transformed data into the destination data source as soon as new data arrives to the Firehose data source.
Don't store what you don't need. In this example, some of the extra columns could be skipped. Add a TTL to the Firehose data source to prevent keeping more data than you need.
Another alternative is to create the Firehose data source with a Null Engine. This way, data ingested there can be transformed and fill the destination data source without being persisted in the data source with the Null Engine.