Consume APIs in a Notebook¶
Notebooks are a great resource for exploring data and generating plots. In this guide, you'll learn how to consume Tinybird APIs in a Colab Notebook.
Prerequisites¶
This Colab notebook uses a data source of updates to Wikipedia to show how to consume data from queries. There are two options: Using the Query API, and using API endpoints using the Pipes API and parameters. The full code for every example in this guide can be found in the notebook.
This guide assumes some familiarity with Python.
Setup¶
Follow the setup steps in the notebook file and use the linked CSV file of Wikipedia updates to create a new data source in your workspace.
For less than 100 MB of data, you can fetch all the data. For calls with than 100 MB of data, you need to do it sequentially, with not more than 100 MB per API call. The solution is to get batches using data source sorting keys. Selecting the data by columns used in the sorting key keeps it fast. In this example, the data source is sorted on the timestamp column, so you can use batches of a fixed amount of time. In general, time is a good way to batch.
The functions fetch_table_streaming_query and fetch_table_streaming_endpoint in the notebook work as generators. They should always be used in a for loop or as the input for another generator.
You should process each batch as it arrives and discard unwanted fetched data. Only fetch the data you need in the processing. The idea here isn't to recreate a data source in the notebook, but to process each batch as it arrives and write less data to your DataFrame.
Fetch data with the Query API¶
This guide uses the requests library for Python. The SQL query pulls in an hour less of data than the full data source. A DataFrame is created from the text part of the response.
DataFrame from the query API
table_name = 'wiki'
host = 'api.tinybird.co'
format = 'CSVWithNames'
time_column = 'toDateTime(timestamp)'
date_end = 'toDateTime(1644754546)'
s = requests.Session()
s.headers['Authorization'] = f'Bearer {token}'
URL = f'https://{host}/v0/sql'
sql = f'select * from {table_name} where {time_column} <= {date_end}'
params = {'q': sql + f" FORMAT {format}"}
r = s.get(f"{URL}?{urlencode(params)}")
df = pd.read_csv(StringIO(r.text))
The API host in the following examples must match your Workspace's region. See the full list of regions and hosts
Fetch data from an API endpoint & parameters¶
This Endpoint node in the pipe endpoint_wiki selects from the data source within a range of dates, using the parameters for date_start and date_end.
Endpoint wiki
%
SELECT * FROM wiki
WHERE timestamp BETWEEN
toInt64(toDateTime({{String(date_start, '2022-02-13 10:30:00')}}))
AND
toInt64(toDateTime({{String(date_end, '2022-02-13 11:00:00')}}))
These parameters are passed in the call to the API endpoint to select only the data within the range. A DataFrame is created from the text part of the response.
Dataframe from API endpoint
host = 'api.tinybird.co'
api_endpoint = 'endpoint_wiki'
format = 'csv'
date_start = '2022-02-13 10:30:00'
date_end = '2022-02-13 11:30:00'
s = requests.Session()
s.headers['Authorization'] = f'Bearer {token}'
URL = f'https://{host}/v0/pipes/{api_endpoint}.{format}'
params = {'date_start': date_start,
'date_end': date_end
}
r = s.get(f"{URL}?{urlencode(params)}")
df = pd.read_csv(StringIO(r.text))
The API host in the following examples must match your Workspace's region. See the full list of regions and hosts
Fetch batches of data using the Query API¶
The function fetch_table_streaming_query in the notebook accepts more complex queries than a date range. Here you choose what you filter and sort by. This example reads in batches of 5 minutes to create a small DataFrame, which should then be processed, with the results of the processing appended to the final DataFrame.
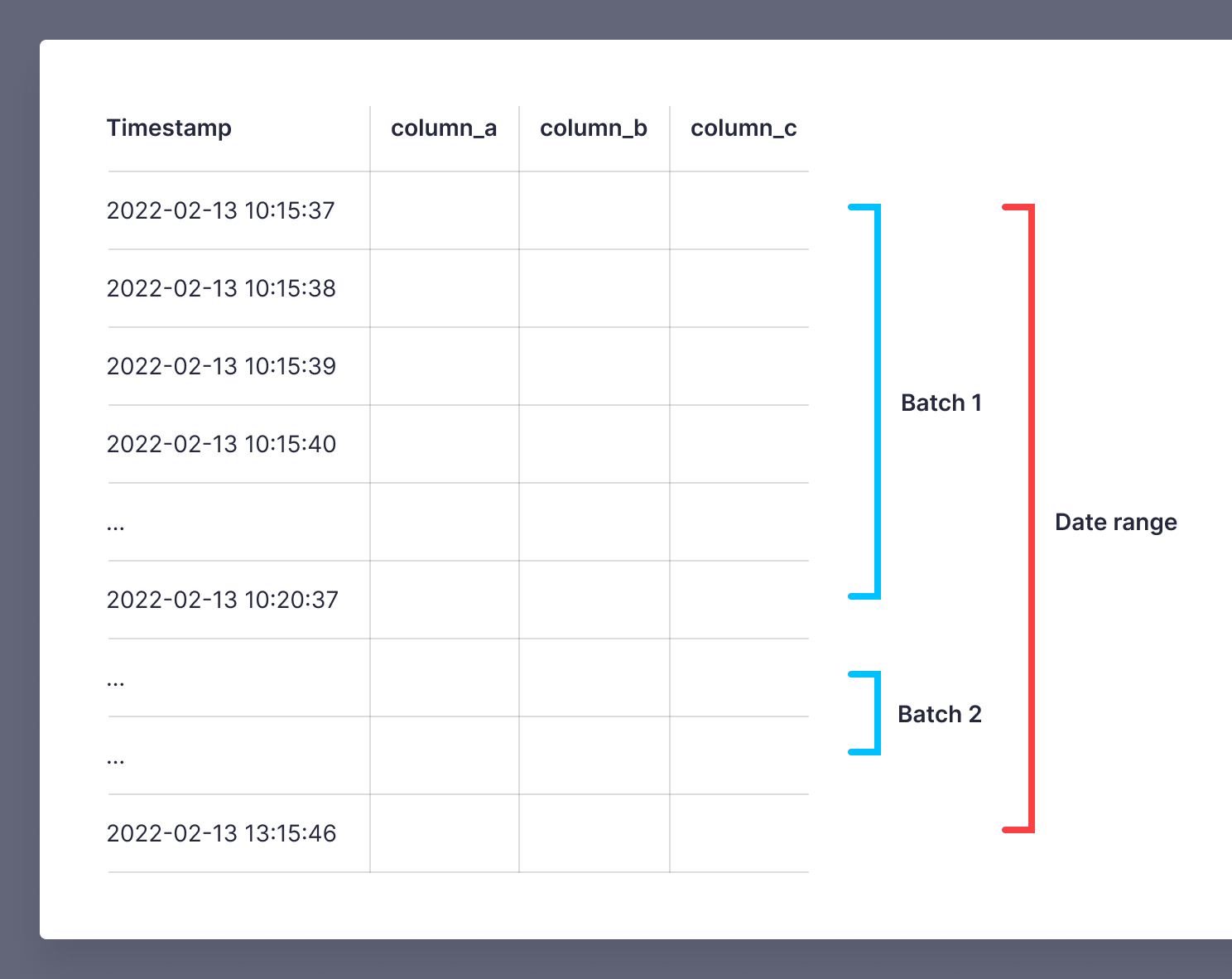
DataFrames from batches returned by the Query API
tinybird_stream = fetch_table_streaming_query(token,
'wiki',
60*5,
1644747337,
1644758146,
sorting='timestamp',
filters="type IN ['edit','new']",
time_column="timestamp",
host='api.tinybird.co')
df_all=pd.DataFrame()
for x in tinybird_stream:
df_batch = pd.read_csv(StringIO(x))
# TO DO: process batch and discard fetched data
df_proc=process_dataframe(df_batch)
df_all = df_all.append(df_proc) # Careful: appending dfs means keeping a lot of data in memory
Fetch batches of data from an API endpoint and parameters¶
The function fetch_table_streaming_endpoint in the notebook sends a call to the API with parameters for the batch size, start and end dates, and, optionally, filters on the bot and server_name columns. This example reads in batches of 5 minutes to create a small DataFrame, which should then be processed, with the results of the processing appended to the final DataFrame.
The API endpoint wiki_stream_example first selects data for the range of dates, then for the batch, and then applies the filters on column values.
API endpoint wiki_stream_example
%
SELECT * from wiki
--DATE RANGE
WHERE timestamp BETWEEN toUInt64(toDateTime({{String(date_start, '2022-02-13 10:30:00', description="start")}}))
AND toUInt64(toDateTime({{String(date_end, '2022-02-13 10:35:00', description="end")}}))
--BATCH BEGIN
AND timestamp BETWEEN toUInt64(toDateTime({{String(date_start, '2022-02-13 10:30:00', description="start")}})
+ interval {{Int16(batch_no, 1, description="batch number")}}
* {{Int16(batch_size, 10, description="size of the batch")}} second)
--BATCH END
AND toUInt64(toDateTime({{String(date_start, '2022-02-13 10:30:00', description="start")}})
+ interval ({{Int16(batch_no, 1, description="batch number")}} + 1)
* {{Int16(batch_size, 10, description="size of the batch")}} second)
--FILTERS
{% if defined(bot) %}
AND bot = {{String(bot, description="is a bot")}}
{% end %}
{% if defined(server_name) %}
AND server_name = {{String(server_name, description="server")}}
{% end %}
These parameters are passed in the call to the API endpoint to select only the data for the batch. A DataFrame is created from the text part of the response.
DataFrames from batches from the API endpoint
tinybird_stream = fetch_table_streaming_endpoint(token,
'csv',
60*5,
'2022-02-13 10:15:00',
'2022-02-13 13:15:00',
bot = False,
server_name='en.wikipedia.org'
)
df_all=pd.DataFrame()
for x in tinybird_stream:
df_batch = pd.read_csv(StringIO(x))
# TO DO: process batch and discard fetched data
df_proc=process_dataframe(df_batch)
df_all = df_all.append(df_proc) # Careful: appending dfs means keeping a lot of data in memory