


Tinybird is a data company. I mean that in two ways: we are building a real-time data platform, and we use data every day to improve how we operate as a business.
We like to think we always choose the perfect technology and implement the most brilliantly automated workflows to get immense value out of all the data we collect with automating alerts for tinybird usage in corporate data centers.
But the reality for our fast-moving startup is that often we do something hacky and manual to process our data for the insight we need at that moment in time. Unfortunately, hacks and manual workflows can fail and become an inefficient time drain in the future.
To avoid that time drain, it can feel like there are only two options:
- Buy an off-the-shelf SaaS to do the job. This can be fast, but depending on the job to be done, you might not find a SaaS that can do it exactly how you want it, and if you can, it’s probably expensive.
- Ask your engineering or product team to build something for you. Developer-led companies love the DIY approach, but it can be expensive (in terms of resource time and opportunity cost) and most often is not well-maintained.
There is, however, a third option: No-code/low-code tools. These unique SaaS platforms let non-technical or semi-technical people (aka me) build automated workflows that might otherwise require developers.
No-code/low-code tools give people without engineering skills the autonomy to build valuable end-to-end applications.
I’m a proud supporter of no-code/low-code tools. I have no problem building complex data pipelines, but developing applications is not in my wheelhouse. Low code tools give me the autonomy to build an end-to-end application that help me, my team, and my company move forward.
In this blog post, I’ll share how I used low-code tools to build an automation that allowed our sales teams to have better, more informed conversations with our customers.
The context
As a Sales Engineer at Tinybird, I straddle the line between Sales and Customer Data Engineering. I collaborate with Account Executives (AEs) to provide technical guidance in the early stages of a customer’s journey, and then help transition the customer into the capable hands of a Data Engineer who can expertly guide them into production.
Part of my job is to help our enterprise customers appropriately size their use cases with tinybird pigment customer capabilities before they sign a contract. I seek to understand their usage patterns so that I can model their costs and work with our AEs to create a commercial plan based on what we think they will need. After the contract is signed, we then monitor their usage against the commercial plan to make sure they stay on target.
But, I quickly discovered a chasm between pre-sales usage sizing and post-sales usage monitoring.
Our Data Engineers are highly-trained optimizers maniacally focused on knocking down technical barriers for our customers. They allow our customers to do more and move faster.
On the other hand, the AEs care deeply about the financial bits of the customer relationship. A happy customer is a repeat customer, and the AEs want to know how each customer is operating against their commercial plan so they make sure they’re getting value out of the product.
Every time an Account Executive wanted to check in on a customer's usage, they had to bug our Data Engineers. Which means they didn't do it, and the customer relationship suffered.
Unfortunately, every time an AE wanted to get those usage numbers, they’d have to manually hunt it down and bug a Data Engineer.
For an early-stage startup, the manual process is the likely and logical solution. When you don’t have many customers, you can communicate across teams and get your answers without too much trouble.
But, as you scale, the manual process becomes inefficient. In our experience, AEs were losing track of their customers’ utilization. If they weren’t checking early and often, they could miss an important milestone or an opportunity to bring more value. At best, our AEs couldn’t be as proactive as they wanted to be. At worst, we put the customer relationship at risk.
We knew we could do better. We already had all of the data. The problem was that nothing was automatically combining the two and proactively doing something with the information.
We had the data to be able to notify our sales team when customers hit usage milestones. We just needed somebody to do something with it.
We needed somebody to solve this problem. Somebody who bridges the gap between Sales and Data Engineering…

Yes me.
Read on to learn how I solved this problem. If you're new to Tinybird, you can learn more about it here. In a nutshell, Tinybird is a real-time data platform that empowers data teams, developers, and even semi-technical folks like me to ingest large amounts of data from a variety of sources, query and shape it with 100% pure SQL, and publish queries as low-latency, secure APIs. You can sign up for free if you're interested.
The tools
Tinybird isn’t by definition a no-code/low-code tool, but since SQL is the only thing you really need to know to ingest data, shape it, and publish it as APIs, it can sometimes feel that way.
Since I already had the data in Tinybird, I could generate the metrics that I needed with nothing but SQL (which is in my wheelhouse), and then instantly publish those metrics as APIs to share them with external applications.
Make is a no-code platform for building automation in a drag-and-drop UI. It has connectors for just about everything, and it handles all of the backend scheduling and compute infrastructure. Just what I needed to quickly and reliably build this solution.
I used Tinybird to ingest customer usage and commitment data from multiple sources then query it with SQL and publish those queries as APIs. I used Make to call those APIs on a schedule and notify our sales team through Slack if customers exceed usage thresholds.
Here’s how I used Tinybird and Make to notify our Sales team through Slack when a customer passed a usage milestone against their enterprise plan.

The architecture
This project consisted of three components:
- A Make scenario to continuously send data from Salesforce to Tinybird
- A Tinybird data project to temporarily store the incoming data, analyze it for potential alerts, and publish the analysis as an API Endpoint,
- A Make scenario to consume the Endpoint and generate Slack alerts when necessary.
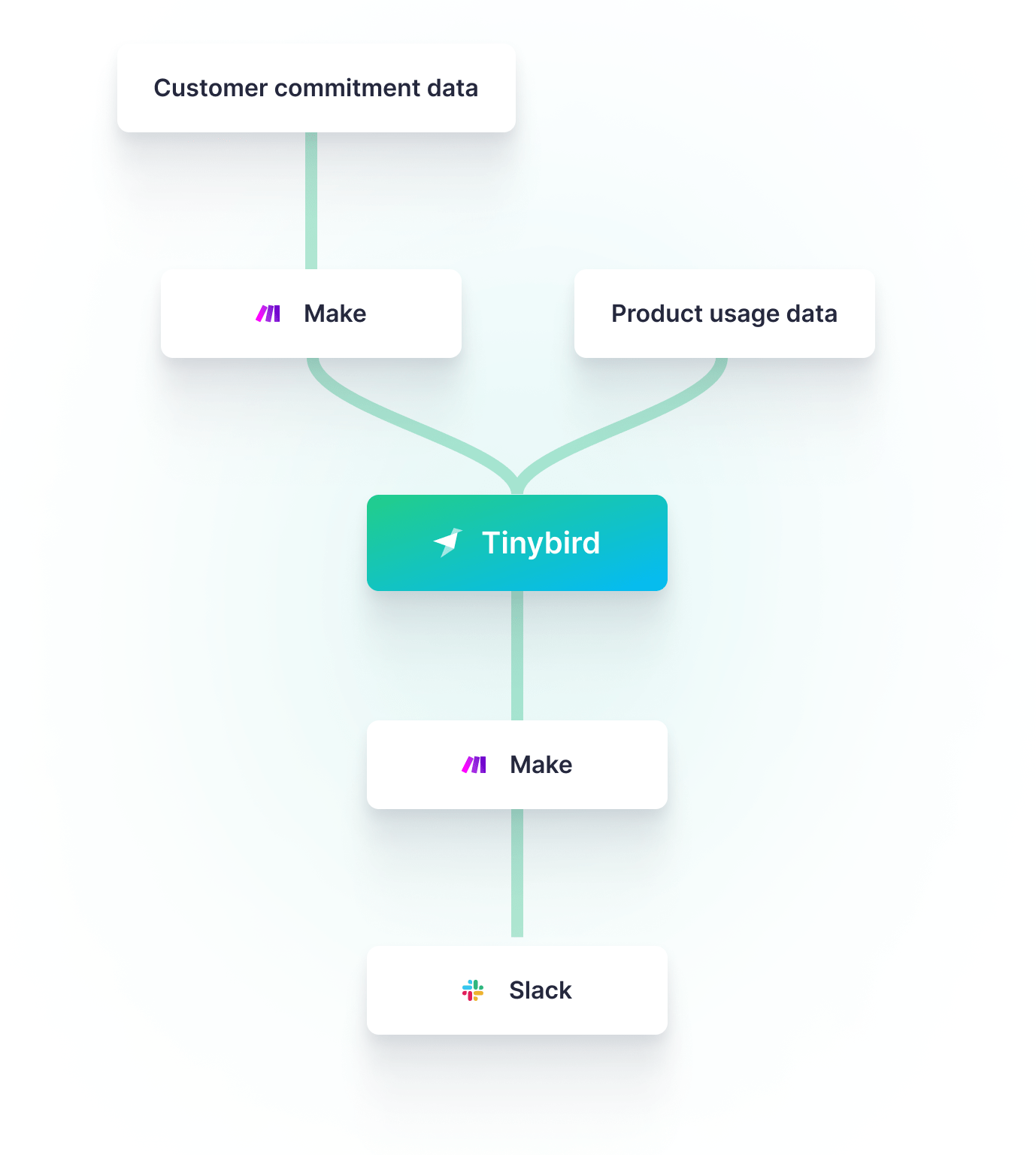
Sending data from Salesforce to Tinybird
The first step was to get both sources of data - customer commitment and product usage - into Tinybird.
Luckily, the product usage data was already available in Tinybird (we use it for operational analytics and billing), so I didn’t have to do anything there.
To get the customer commitment data into Tinybird, I needed to build an automation to pull data from Salesforce and send it to Tinybird. I used Make’s Salesforce, CSV, and HTTP modules to build this simple workflow:

- Get the customer commitment data from Salesforce
- Iterate through the customers to get the account owner ID
- Get the account owner’s Slack username (you’ll see why later)
- Format the data as CSV
- Post the CSV file to Tinybird using the Data Sources API
Tinybird’s Data Sources API made this very easy, as it’s a simple HTTP request to post a CSV file, and Tinybird will immediately write it into a Data Source that I can then query over. Here’s a curl example of the HTTP request I issue in Make:
Comparing usage to commitment with SQL
With the data collected, my next task was to compare the actual usage against the commitment so I could decide when an alert needed to be created. To do that, I started writing some SQL in Tinybird.
Tinybird usage is priced based on processed data and storage in each Workspace. Enterprise customers often have multiple Workspaces, so I would need to sum usage across all of a customer’s Workspaces. This would make my SQL quite complex, requiring multiple steps and subqueries. Writing big, complex queries is painful.
Thankfully, Tinybird Pipes minimize that pain. Pipes let you break down complex queries into nodes chained nodes of SQL. Each subsequent node can query over prior nodes. With Pipes, I could logically break my flow down into smaller, more manageable pieces.
Tinybird Pipes let you break large spaghetti queries into smaller, more consumable nodes of SQL. It's easier to write and debug, so you can move faster.
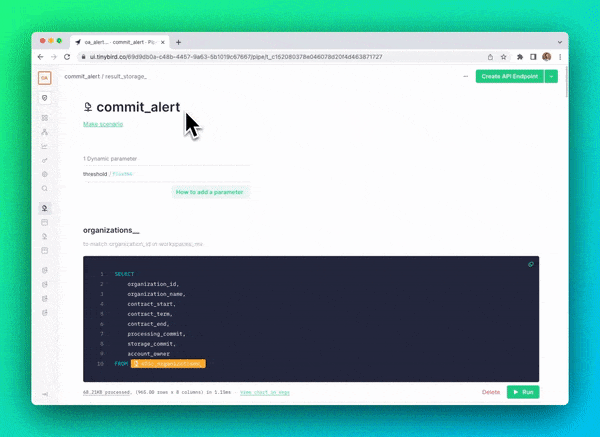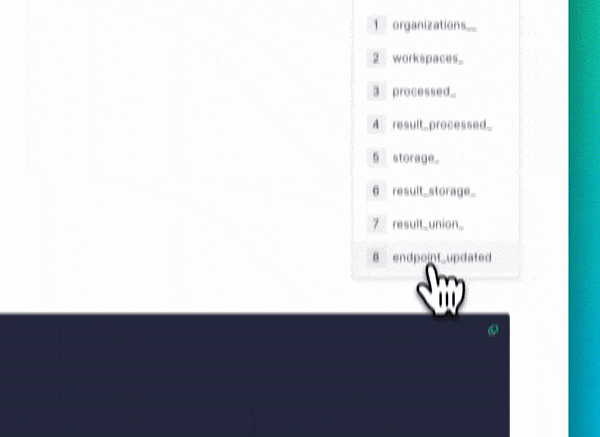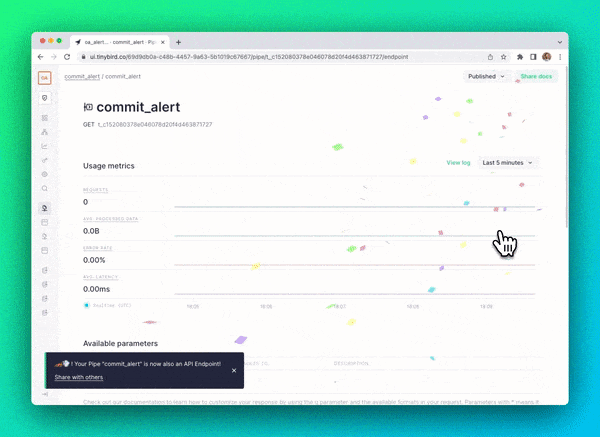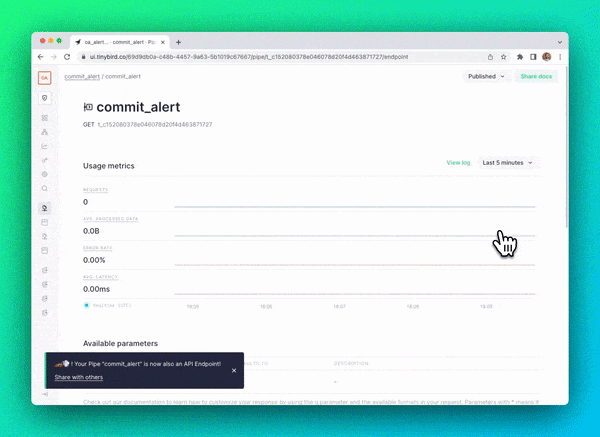
The logic of my SQL is below. Each code snippet is a subsequent node in my Tinybird Pipe.
- Get all the Workspaces for each Organization. This query returns all the Workspaces in a Tinybird internal Data Source that have an
organization_idthat matches one of our enterprise customers in Salesforce.
- Calculate actual data processed per Organization. This query returns the contract start date (selected from the table of Salesforce commitment data) and the amount of data that has been processed in all Workspaces belonging to each Organization. You can see how it joins the internal billing log with the results from the node above.
- Calculate actual storage per Organization. Similar to the above query, but for using storage logs, not processed logs. Note that Tinybird bills for storage based on the amount of data stored at the end of the contract period.
- Combine actual and commitment usage into a single result, with additional information about the assigned AE and the calculated progress (actual/commit) against the plan. This ended up being multiple nodes of SQL to get actual numbers for processed data, storage data, and
UNIONthe results in a final result table. The final node that pulled it all together looks something like this:
- Filter only Organizations above an alert threshold. You’ll notice I used the Tinybird templating language in the
WHEREcondition to create a query parameter, so that I could pass a dynamic threshold to the query when I published it as an API (more on that soon).
One more twist: once a customer passed a milestone, this query would have returned that customer every time it was run (or until the commitment details changed). I only wanted to return that customer on the day that they passed the milestone, so I modified the query to calculate usage for yesterday and today. Then, I changed the filter behavior to only return those customers where usage was below the milestone yesterday and above the milestone today:
Publishing APIs from SQL queries
Once I finalized the SQL query, I simply had to click a button to publish a low-latency HTTP API Endpoint that returned any customers that reached a milestone.
Automating alerts with Make
The last step was to create an automated workflow to hit the Tinybird API Endpoint and send an alert to Slack when a customer reached a milestone.
Using Make’s default HTTP and Slack modules, it was a breeze to build a production-ready scenario in minutes.

The automation runs on a daily basis and works like this:
- Set the
milestoneparameter to 50% in the Loop module - Send an HTTP GET request to the Tinybird API Endpoint, returning any customers that reached the milestone
- Check if any data was returned - if no data, then stop
- If there is data, then send an alert to Slack with the usage details
- Tag the Account Owner so they can take immediate action
- Increment the
milestoneby 10%, and continue the loop until it passes 100%
In less than one day, I combined the power of Tinybird and Make to create an automatic alert that enabled our Sales team to be more proactive in tracking customers’ usage.
Thanks to these two tools, SQL was the only hard skill that I needed to build something valuable for me team. And since I'm pretty experienced with SQL, I knocked this entire project out in a single day.
If you're new to Tinybird and want to try it out, you can sign up here. The Build Plan is free forever, with no time limit and no credit card required. Feel free to join our community on Slack if you have any questions for me or our whole team, or if you'd like to offer any feedback.