


The problem
There are times when you have a query that involves clickhouse union all statements and you'd like to materialize it. If you try to do it on ClickHouse®, the union clickhouse operation will fail. The solution is to create two materialized views that write to the same table. In this post we'll explain how to do it on ClickHouse® and on Tinybird.
We’ll also use SimpleAggregateFunction(function, type). It is a data type that stores the value of the given aggregate function without storing the full state as AggregateFunction does. According to the documentation, “it can be applied to functions for which the following property holds: the result of applying a function f to a row set S1 UNION ALL S2 can be obtained by applying f to parts of the row set separately, and then again applying f to the results: f(S1 UNION ALL S2) = f(f(S1) UNION ALL f(S2))”. What does this mean?
Imagine that function is sum, one set is [1, 3, 7] and another set is [2, 4, 6]. Doing sum(sum(1, 3, 7), sum(2, 4, 6)) will yield the same result as doing sum(1, 3, 7, 2, 4, 6). So if we want to use sum in a materialize view, we can store the result in a SimpleAggregationFunction(sum, type) data type. Other functions where this happen are any, anyLast, min, max, and more.
Therefore, SimpleAggregateFunctions data types will be useful, for instance, when using a data source to store the results of two materialized views in order to perform the same output as doing a "clickhouse union" of two tables, but faster.
A practical example
Let’s see first an example of what we would like to achieve. In this example, we’ll be using Unsplash open data.
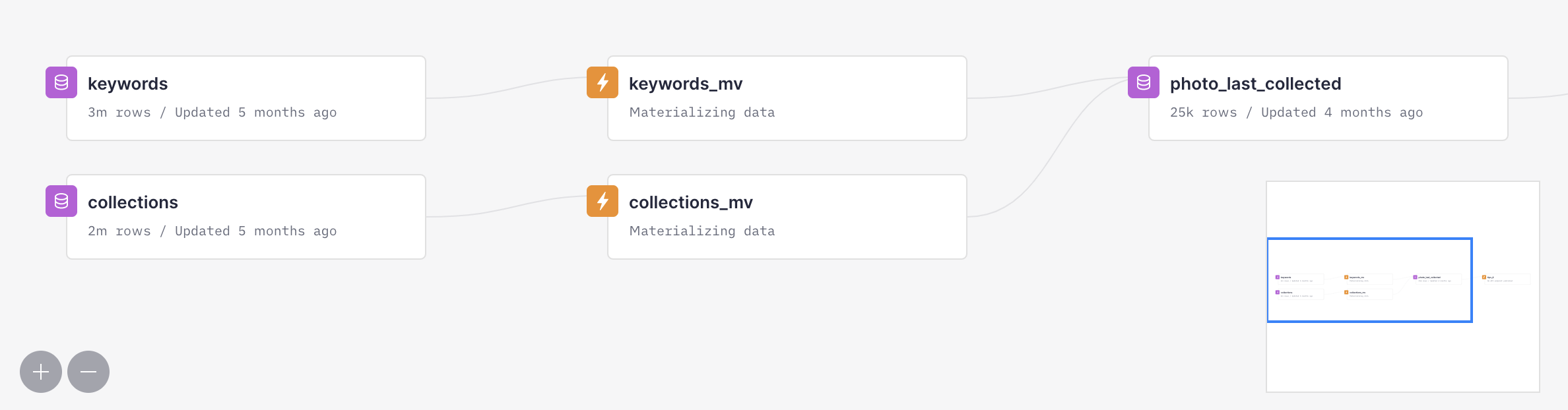
We have will be using two source tables: collections and keywords. The first one contains information about every time a photo has been added to a collection, and the second one about the keywords used to describe each photo.
Our purpose is to create an enpoint to get the last time a photo was added into a collection and some information about this collection along with the complete list of keywords for this photo. In order to explore the data and get an idea of what we want to accomplish, we will be doing something similar to the following aggregation over the result of an UNION ALL:
How can we achieve the same result but using materialized views? We can not materialize the result of an UNION ALL, but we can make use of the AggregatingMergeTree engine.
First of all, let’s create the destination table, photo_last_collected:
What should we take into account here:
- Every
SimpleAggregateFunctionusinggroupArrayArraymust have Array type, and can’t beNullable. ThegroupArrayfunction can’t contain null values. - We could also use
groupUniqArrayArrayin order to avoid duplicated keywords
Now, let’s create two materialized views, one per table. This view materializes the photo id and the keywords that belong to each photo to the photo_last_collected Data Source:
And the following view materializes the photo id, the last time it was added to a collection, the collection id and the collection title that belong to each photo to the photo_last_collected Data Source:
Key points:
- As a rule of thumb, column names must have the same name and must be inserted in the same order into the destination Data Source
- The
keywords_listcan not simply be an empty array, we must cast it correctly toArray(String), because that’s the data type of the destination column last_time_collected_at,collection_idandcollection_titlecan’t either beNull, we have to cast them to the exact type of the column in the landing Data Source they’re being saved in
If you create the Tinybird Data Sources and Pipe files under a project with this structure (the folder structure is already created when you do tb init with our CLI):
You’d just have to run tb push --push-deps --populate --wait to create the Data Source on Tinybird, the materialized views, and populate the Data Source.
Then, you’d only have to get the data already joined from the photo_last_collected destination table.
As you can see, the result is the same as from the first query, and it’s about 6x faster.
A similar result would have been obtained if we had used AggregateFunction when defining the photo_last_collected Data Source. Using SimpleAggregateFunction has several advantages:
- As SimpleAggregateFunction just saves the value instead of the full state of its aggregate function (like AggregateFunction does), it’s more performant.
- It lets us write the cleaner and simpler queries, as we don’t have to use the
-Statesuffixes for the Materialized Views and we can just query the landing datasource doingSELECT * FROM photo_last_collected. Otherwise we’d have to use the-Mergesuffix to merge the intermediate states of the aggregated columns.