


This is a story about how a single integration test took 1 second when it should have taken 1 millisecond. The code worked, and one second is nothing, but the frustration was overpowering. It had to be fixed.
And it’s a good thing we did fix it. In the end, this seemingly trivial inefficiency motivated the pull request that would cut our global memory usage in half, slash threads and processes by 70%, and virtually eliminate I/O traffic.
Read on to learn how.
The integration test that should have been 1000x faster
The antagonist in this story, and the impetus for our work, was a single, measly integration test. The specific test isn’t important; we have dozens just like it. It sent a very simple bit of SQL to Tinybird’s Query API:
Here, daily is a node previously saved in the platform and defined as
The Data Source stock is relatively small, with around a million rows.
Tinybird transforms the initial HTTP request to a final SQL query to ClickHouse®, the real-time database that underpins our platform:
This is a simple aggregating query over a small table that filters over the primary key on one of the world’s fastest analytical databases; it’s a recipe for speed.
So you can imagine our frustration when we saw test times lag to over a second. We were expecting sub-millisecond responses, instead, this request was letting an entire tick of the second hand pass by. Unacceptable.
This simple query should have returned a response in a millisecond. Instead it took 1000x longer.
Maybe you think that's dramatic. Most people wouldn’t care about a wasted second here or there. But we knew it should be faster, and we couldn’t let it go. So we decided to investigate further down the stack.
The first check was the statistics header that Tinybird returns as part of the HTTP response:
Sure enough, the db (database) operation only took 1.8 ms, about as fast as we originally expected.
So, either the HTTP server was to blame, or the time spent preparing the process for transforming the request into a final SQL query to the database. After a bit of print() debugging, we narrowed it down to the latter: setting up the environment for running the request was taking too long.
This step, which does the transformation described above, changes the API request into the final SQL query that’s sent to the database. In addition to replacing nodes by their definition, it also applies templates and parameters and does some validation to ensure everything is in order.
We handle billions of requests like this every day at Tinybird, so this process has to be very, very fast. And as we all know, the most common way to make something fast in Python is to… not use Python 🧌. We adhere to this axiom at Tinybird, shifting our most CPU-intensive services to C++ extensions that we call from standard Python code.
The best way to make something fast in Python is to not use Python. For CPU-intensive tasks, we shift the workload to C++ extensions to maintain speed.
We know Python’s limitations, and we account for them. So why was this test so insufferably slow?
Enter the ProcessPoolExecutor, the true villain of this story.
Some background on Python threading and the GIL
Python is slow. Good Python developers understand this, especially those who work with real-time data at scale. What it gives in flexibility and readability, it takes away in speed and performance.
Most modern services need to be able to use several cores at the same time. Designing and building such a service in Python carries a problem: its threading model.
In Python, multi-threaded applications are not concurrent. It implements a “Global Interpreter Lock” (GIL), whereby each thread gets access to the interpreter for a bit before it is evicted by another thread. The GIL gets used by one thread, and only one thread, at a time. This makes parallel programs simpler to reason about, but it also means that multithreaded applications can still only use a single CPU core. Again, Python is slow!
In Python, multi-threaded applications are not concurrent, since the interpreter can only be accessed by one thread at a time.
To work around this limitation, Python developers use threading processes for CPU-intensive operations. Each process has its own Python interpreter and GIL, so you can use several cores at once while sharing information between processes. To do this, you use the ProcessPoolExecutor, which is in charge of spawning the processes and sharing data between them.
Of course, if you don’t need multiple cores, you can use the simpler ThreadPoolExecutor, which distributes tasks amongst threads. It’s limited by the single GIL, but it’s generally easier to work with.
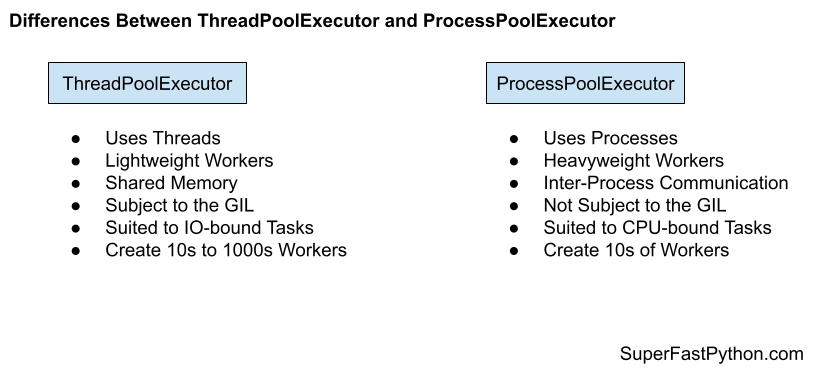
Keenly aware of the limitations of threading in Python, we knew that if we tried to use threads or async code, long or complex queries constructed by our query builder process would inevitably block or slow down parallel requests. So, we opted for the ProcessPoolExecutor to distribute work across multiple cores.
To utilize multiple cores, we used processes instead of threads, which move CPU-intensive tasks to individual processes with their own Python interpreters, sharing the data between them.
Did we really need the ProcessPoolExecutor?
It’s important to validate old assumptions every once in a while. Requirements are fuzzy and ever-changing. So we wondered, did we really need process concurrency? In this case, the answer was an obvious and unfortunate “Yes”. We ran a small benchmark test that confirmed it; processing 100 requests across 10 parallel workers was almost 10 times faster with the ProcessPoolExecutor than with the ThreadPoolExecutor.
Tinybird processes billions of queries a day. We absolutely must have high concurrency to avoid blocking user queries.
But the drawbacks of the ProcessPoolExecutor were beginning to mount:
- It is much slower to initialize when first created. In our production apps, we warm up the processes before allowing requests, but for short-lived CI tests, we didn’t. When running a single test, you pay the cost of starting the pool. That’s why my test was taking one whole, agonizing second.
- In general, processes share a lot of memory with the original creator. As we needed more processes to scale and do more requests concurrently, we also needed to add more and more memory to the servers. There are ways to shrink the combined memory footprint, but it isn’t straightforward and we have plenty of other things to do.
- The communication between processes carries overhead. Python makes the process feel seamless so you may not notice it, but the overhead is still there, and it has a cost in both memory and performance.
- We had a history of issues related to the use of processes. For example, the shutdown process is more complex, and we suffered from both zombie processes and 502 errors in production because of it.
- The default behavior is different between operating systems (Linux vs OSX), which made it harder to test and develop within a team with various OS preferences.
So, thanks to our angst about a trivial little second, we decided it was a good time to rethink concurrency. If processes weren’t a great (and fast) solution, we had to find a better one.
Releasing the GIL with the ThreadPool class
Moving away from the ProcessPool implementation and its latency overhead meant using the ThreadPool class instead, which required that we revisit how we managed the GIL. Could we have finer control for unlocking and locking GIL threading to get the speed and concurrency we needed without the overhead?
This is where experienced developers stop and think. Ninety-nine times out of 100, you aren’t the only person ever to have suffered from a certain problem. There are thousands of native extensions and companies doing similar work, so somebody will have tried different approaches that might benefit you. Just open your browser and start searching.
Before you try to fix a problem, you always check if somebody else has already fixed it.
Sure enough, we confirmed there was precedent for more precisely controlling the GIL so that several threads can be active at the same time. And as you might have guessed, it involves not using Python.
Remember that the GIL exists to control the Python interpreter. If you aren’t using Python code or objects, you don’t need it. You can call a C function from a Python thread and release the GIL until it needs it again. The C function can copy any Python object it needs and unlock the GIL, allowing the next Python thread to work concurrently. While that Python thread acquires the GIL, the C function can happily work in the background. As long as it doesn’t need to do anything with Python, it leaves the GIL alone. When it does need Python, it requests the GIL back and goes back to work normally.
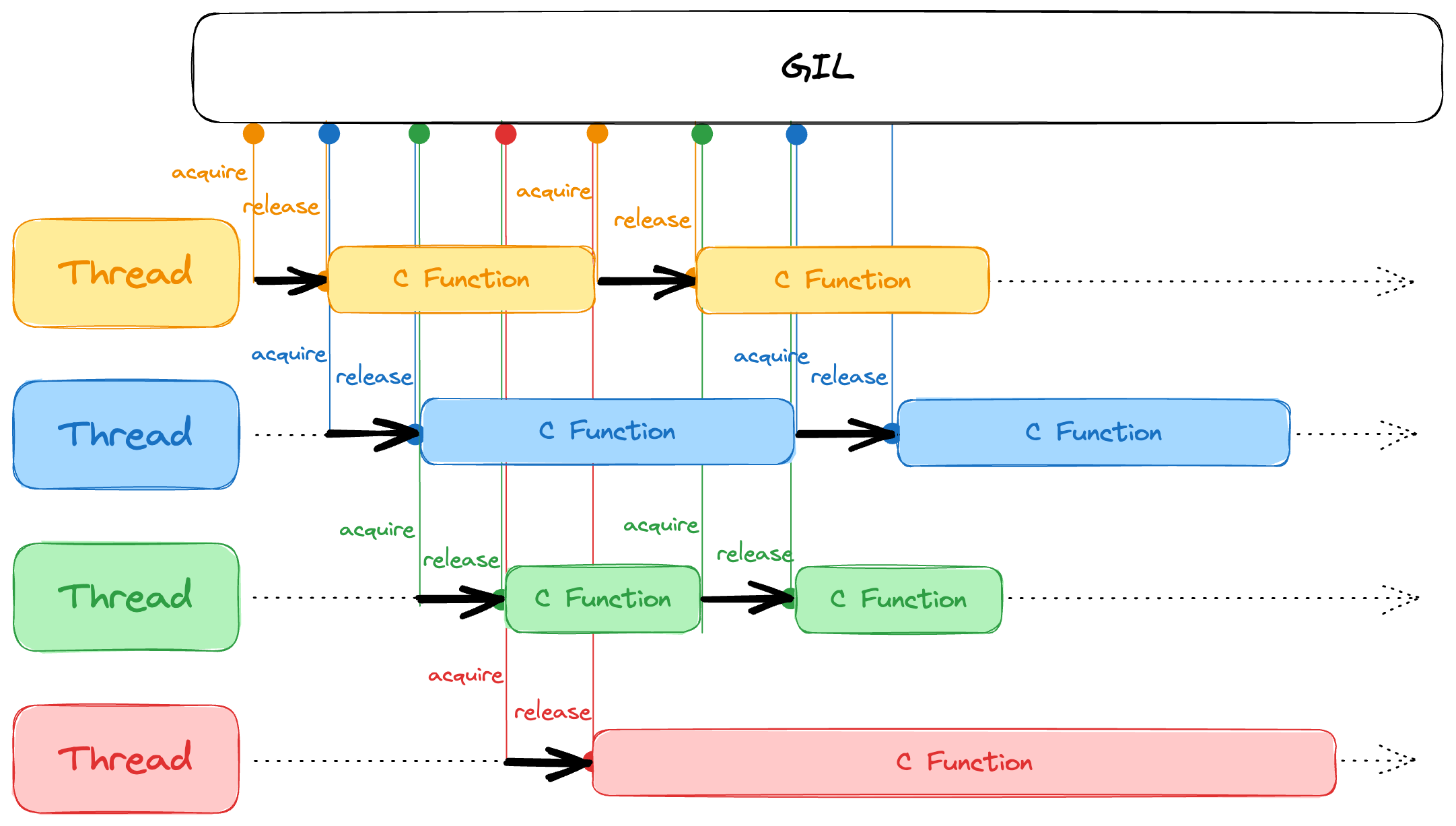
With this approach, you can use the ThreadPoolExecutor to run a CPU-intensive native code concurrently on a pool of threads without acquiring the GIL.
Our research ultimately landed us on the official Python docs for Initialization, Finalization, and Threads. Specifically, we learned that to accomplish our aims in a C/C++ extension, we needed to use the Py_BEGIN_ALLOW_THREADS and Py_END_ALLOW_THREADS switches as necessary. You use Py_BEGIN_ALLOW_THREADS to unlock the GIL precisely where you call your C-based code, let the C code do its thing, and use Py_END_ALLOW_THREADS when the C code returns to re-engage the GIL and continue with your Python code.
We changed our code so that each thread would release the GIL after it initiated a C function, then reacquire it when the function returned. This way, multiple threads could initiate CPU-intensive tasks concurrently.
After making these changes to our C++ functions, we again ran a benchmark with 100 parallel requests using both the ProcessPoolExecutor and the ThreadPoolExecutor.
This simple change to our codebase, about 100 lines of code including the benchmark test, had an incredible effect. Threads were no longer 10x slower than processes. Now, they were faster, since they could run the C functions in parallel and had the added benefit of not needing to share messages between processes.
But, concurrency is always a tricky subject. So, even though my benchmark test showed promise and everything was working correctly in CI and staging environments, we decided to roll out the change only partially so we could analyze the impact in production.
We ran a test in production to see how this code change would impact customer queries and our production servers. The results were very promising.
We introduced a flag to select the Executor and enable threads in certain servers for a brief period so we could verify if customer requests were affected. During the test, we assessed how the code changes affected the servers themselves in terms of memory, I/O, or CPU.
We ran the test for about 30 minutes until we noticed some new errors in the logs and decided to revert those servers to using the processes while we analyzed the results.
What we saw vindicated our choice to obsess over a single second.
The Results
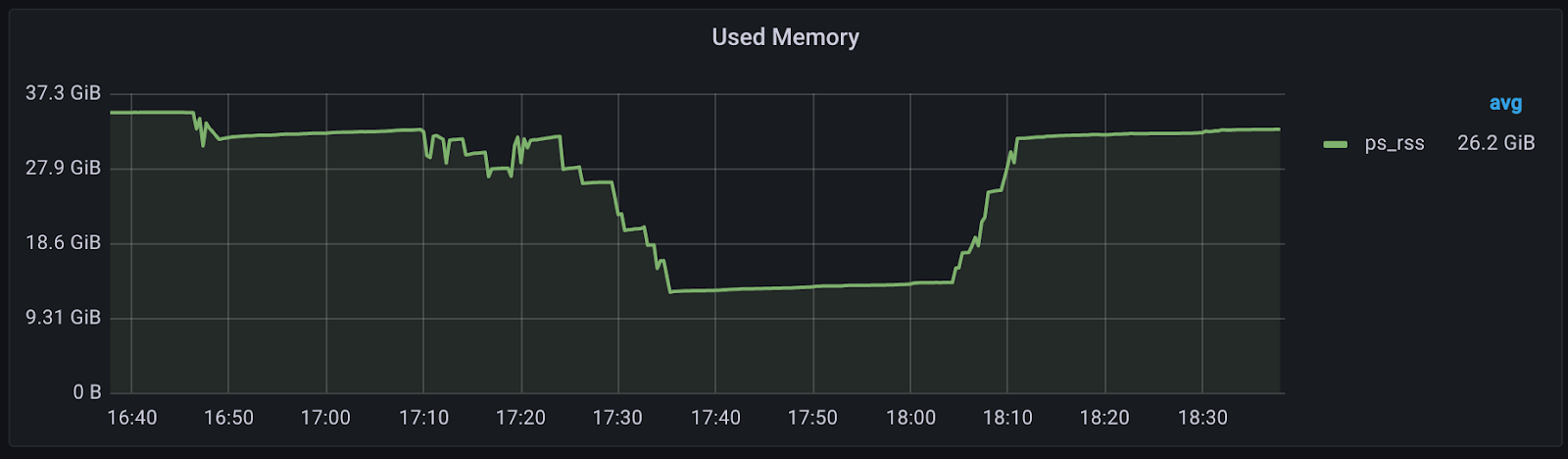
We first noticed a significant drop in memory usage. Below you can see the memory consumption of a single server during the test, which ran from about 17:35 to about 18:05. The new threading design reduced memory from 32GB to 12 GB.
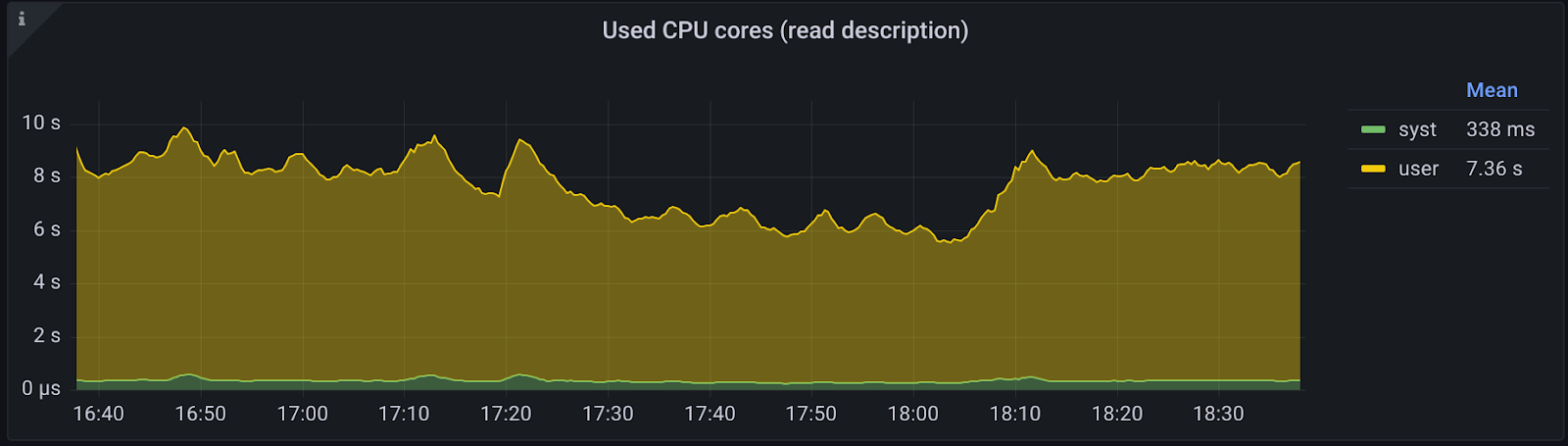
But memory usage wasn’t the only gain. We additionally cut processes and threads used by about 60-70% each, as you can see in the chart below

We also witnessed a noticeable drop in CPU usage by about 10-20%.
And as expected, I/O traffic dropped to effectively zero. With processes, the main process would need to send the query to a worker and then receive the result. With threads, that happens directly in memory, so there isn’t any external communication.

Of course, it wasn’t all good. The downside was that GIL lag bloated by around 15%, adding around 75 milliseconds of additional latency.
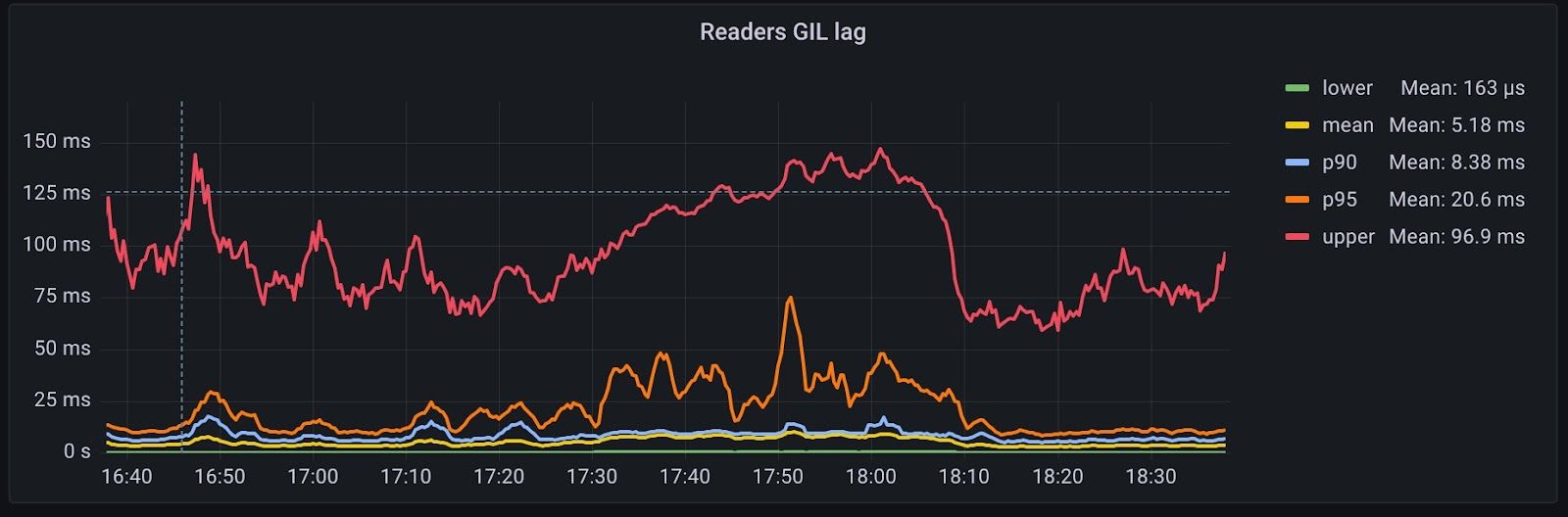
We were buoyed by these results, so we investigated both the odd logs that caused us to end our test and the extra GIL lag, and we found a bug in a completely unrelated part of the code. We hadn’t noticed it before because each process had its own cache (no concurrency problems if you don’t share!). Once we fixed it, we not only addressed the errors and lag but also made the cache more effective.
The final results:
- Global memory usage went down by over 50%
- CPU usage was slightly lower (10-20%)
- The number of running threads and processes decreased by 60-70%
- I/O traffic was virtually eliminated
Using threading, C++ extensions, and finer-tuned GIL control, we were able to reduce memory usage by >50%, CPU usage by ~20%, threads and processes by ~70%, and I/O traffic by 100%.
We had landed on a safer, simpler, and faster alternative to the ProcessPool threading model. Thanks to our ThreadPool implementation that pushed CPU-intensive tasks to C functions and released the GIL to the next Python thread, we gained significant performance with very little new code. All thanks to one second that we just couldn’t suffer.
Takeaways
For our Python-coding readers
- Remember, Python is slow. This is why so many Python extensions are not written in Python. When you need to run CPU-intensive operations, look for better approaches.
- Learn about the GIL. Even if it ends up being optional in the future. Once you understand its role, advantages, and disadvantages, you will understand why many things are the way they are in the Python ecosystem.
General Lessons
- Allow annoying code to motivate you to dig deeper. When you have the access and opportunity to go further down the stack, good things can happen. In this case, we ended up with a better application that used fewer resources and is easier to manage. Also, running a single test was fast.
- Learn the internals of the technology you use. Doing so makes it easier to search for and find better solutions. In our case, understanding the GIL and language interoperability was key to determining a new approach using extensions. Honing your craft can also provide more insights for testing and monitoring.
- Don’t assume that something that has been working for years is the best solution. Revisit your assumptions often. Hardware improves, languages and patterns evolve, and software requirements change quickly with increased product usage.
- You are not special. Research what other people are doing in similar situations. In many cases, a better solution is hiding in plain sight.
- Working code trumps theories and opinions. Yes, we found an opportunity here to optimize working code, and we did it. It’s easy to theorize about areas for improvement or redesign, but as your stack and platform become more complex and your user base grows, changes get riskier. Sometimes, some simple testing code, or additional debug statements, can help you gather the data needed for debating design decisions, gaining consensus, and deploying improved software.