


In 2020, humans created 2.5 exabytes of data every day.
By 2025, that number will hit over 450 exabytes, a 200x increase in data generation in a mere 5 years. Data creation is accelerating so rapidly that we might even run out of places to store all our data.
If you pair the "data hyperdrive" with the human bent towards understanding, problem-solving, and (depending on how cynical you're feeling today) profit, you'll realize pretty quickly that businesses, governments, and enterprising individuals are going to want to do something with all that data.
So, as a developer, you need ways to do more with all those exabytes while keeping costs and latency low.
And if you're frequently building applications on top of real-time data streams, then there's no time like the present to get up to speed on Materialized Views. Materialized views are particularly powerful when combined with ClickHouse®'s URL analysis functions like URLHierarchy for building efficient web analytics pipelines.
Tinybird is a real-time data platform that offers full support of Materialized Views. With Tinybird, you can unify data from batch and streaming data sets into indexed, columnar data stores, query and materialize filtered aggregations with nothing but SQL, and publish your metrics as low-latency APIs to consume in your real-time applications.
What is a Materialized View?
A Materialized View is the result of a query on a table in your database or data warehouse, stored in memory or disk so that you can easily access - and query over - its results in the future. A materialized view stores computed results, making it distinct from regular database views.
Developers can employ Materialized Views across a wide range of applications to improve query performance and simplify the development and maintenance of real-time data pipelines.
If you're in the process of or about to start building real-time analytics, you should become familiar with Materialized Views and when to use them.
How are view vs materialized view different?
The key difference between Views and Materialized Views is that Materialized Views are stored in memory, whereas Views are effectively virtual tables. When you create a regular View, you’re effectively creating a pointer to an underlying table. Materialized Views, in contrast, store the results of the materialization process on disk as a new table.
Do Materialized Views need to be refreshed?
It depends on the database management system. Some databases, like PostgreSQL, require the materialization process to be triggered manually. Other databases, like the real-time database powering Tinybird, run materializations incrementally during the real-time data ingestion processs.
In Postgres, you can use the REFRESH MATERIALIZED VIEW statement to replace the contents of a Materialized View.
In real-time data platforms like Tinybird, the aggregations in Materialized Views are calculated and stored in intermediate states using the -State combinator. Then, the intermediate states can be merged at query time using the -Merge combinator. This reduces query load while ensuring that real-time data is materialized on ingest.
Regardless, the need to refresh your Materialized View will depend on the database and use case.
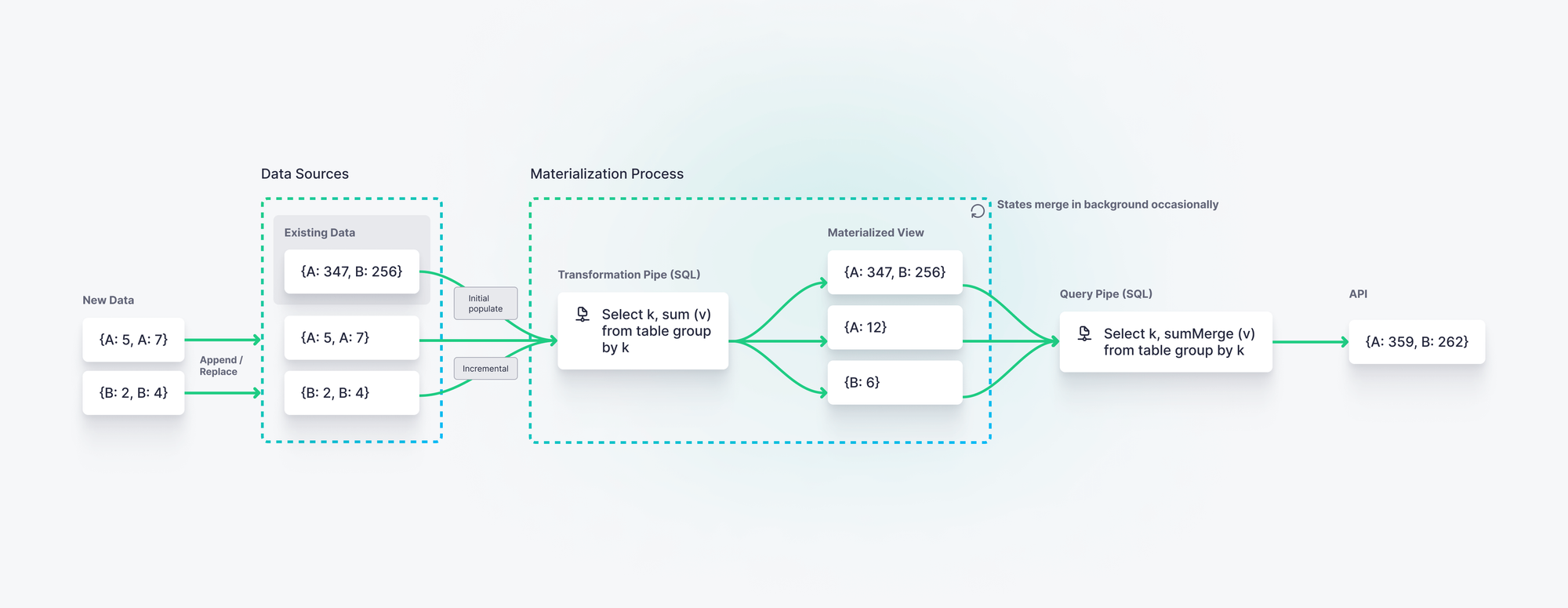
How to create a Materialized View
As with the above, this process will depend on your database. Below is a basic reference for the commands to create a simple Materialized View on common databases:
Create Materialized View in PostgreSQL
Use the following example command to create a Materialized View in Postgres:
For more information on Materialized Views in Postgres, check out the official docs.
Create Materialized View in Oracle Database
Similar to Postgres, the SQL statement to create a Materialized View in Oracle Database is:
For more information on Materialized Views in Oracle Database, check out the official docs.
Create Materialized Views in SQL Server
SQL Server doesn’t explicitly support Materialized Views, but rather Indexed Views, which are similar. To learn more about creating Indexed Views in SQL Server, check out the official docs.
Create Materialized View in MySQL
Materialized Views do not exist in MySQL. As an alternative, you can explore using tools like Flexviews.
Create Materialized View in ClickHouse®
Use the following syntax to create a Materialized View in ClickHouse®:
Note that you need to define the target table first. For more information on ClickHouse’s Materialized Views, check out the official docs.
Create Materialized View in Tinybird
Tinybird is real-time data platform that abstracts the complexities of ClickHouse®. You can create Materialized Views from any SQL query in the Tinybird UI, or create the following Pipe file:
You can define the schema for your target table in the corresponding Data Source file. Instead of using CREATE TABLE SQL syntax, you simply define a Data Source in a plaintext file. Note that if you use the Tinybird UI, the target table will be created automatically, and the -State combinator(s) for aggregate functions will be automatically appended to your queries.
For more info on using Materialized Views in Tinybird, check out the official docs or watch the tutorial below:
When to use Materialized Views
You should use Materialized Views to improve performance and reduce cost when querying over large amounts of raw data. They often provide a performance boost over regular database tables or views, especially when you start making more complex queries that involve filtered selections, aggregate functions like sum() and avg(), or projections, for instance as a part of real-time visualizations or dashboards. When customers come to Tinybird looking for help optimizing their queries, we often point them to Materialized Views as a common way to grab back performance by cutting down on the number of bytes or rows read when the endpoint is called.
Materialized Views are useful when you're building complex analytical queries over large amounts of raw data, but you typically only need filtered or aggregated results.
In particular, Materialized Views provide an advantage over regular tables in 3 specific categories:
- Speed,
- Simplicity, and
- Consistency.
Here’s what we mean by each of those…
Materialized Views are fast
At Tinybird, we’re all about speed. We believe that data should be analyzed when it happens. Period.
And when data is “happening” at sub-millisecond latency, we need queries that return results at millisecond (or faster) latency.
Database queries over raw tables, especially those that involve complex aggregations or filters, require most of the computation work to be done at query time. Expensive queries like this scan the same rows over and over, and they continually degrade as data grows.
Queries over raw data require computation at query time - which can increase latency and cost. Materialized Views move computation to ingestion time to reduce costs and improve speed.
Materialized Views speed up queries by shifting the computational work to write time instead of query time. When you need answers ASAP, Materialized Views give us a performant “cache” to query; the heavy lifting has been done during the materialization process, giving our product-facing queries the speed boost they need to serve relevant data.
In addition, Materialized View indexes can be different from the indexes of the raw table, which can support niche analytics use cases that will filter by a special subset or unique columns.
To get a sense of how much faster (and cheaper) Materialized Views can make your queries, take a look at this blog post about using Materialized Views to create data rollups on Ethereum blockchain transactions. There's even a nice little UI tool to demonstrate how Materialized Views can make queries 50x faster (and scan up to 50,000x fewer rows!).
Materialized Views are simple
Ever tried to optimize performance in one of your applications before realizing the performance bottleneck is behind a complex SQL query that gets executed over and over again?
Say, for example, that your application displays a ranking with top revenue-producing products by category for the last year in the United States? So you spin up a quick query that scans and aggregates all the rows from your transactional data, something like this:
Since that query is aggregating mostly past data that is not going to change, it is very likely you are processing way more data than you need when you run it. If you’ve made a million sales every year since the time you set up your database 10 years ago, every day you run this query you’ll be scanning 10 million+ rows even though only the most recent day’s worth of data (~2,700 rows) influences a change. Not to mention you’re doing a JOIN to a static dimensions table every time. It’s a total waste of resources.
Materialized Views can help you keep that aggregation always up-to-date and improve execution by speeding up not only compute time, but your time as well. By relying on Materialized Views for the intermediate results you use most frequently, you’ll save time and achieve more flexibility as you build new data products on top.
Materialized Views are consistent
We’ve already talked about how Materialized Views create speed, solving #1. And we’ve also shown how they simplify the scans you need to make on your database to get common aggregations. But Materialized Views also create consistency, especially when the results stored in Materialized Views involve heuristic filters determined at the time of development.
Using concepts from the same example as above, consider if we wanted to know how much revenue we generated yesterday by selling a certain product. If this is a global product, the definition of “yesterday” is going to depend on the timezone. For example, “yesterday” in London only overlaps “yesterday” in Los Angeles by 16 hours. Said differently, a sale made at 6 PM on one day in Los Angeles would show up as having been made at 2 AM in London the next day.
If we ask query writers to make the logical determination of what “yesterday” means, each one might choose differently. For example, a data analyst building a dashboard for the CRO might choose a common timezone (GMT) regardless of where the sale originated, but a developer building real-time personalization on the e-commerce site might instead choose the timezone of the sale.
Neither determination is inherently wrong, but the discrepancy can cause problems down the line as the different business users and user-facing applications rely on insights gathered using different sets of logic.
By creating a Materialized View with a descriptive name, like sales_yesterday_gmt_by_poduct_mv, you cement within your data structures the business logic that you consistently reuse, avoiding application-level irregularities that cause process breakdowns later on.
What are the limitations of Materialized Views?
Materialized Views aren’t always a silver bullet, and the implementation details vary depending on the database you are using (more on that below). There are always trade offs. In particular, Materialized Views have a few drawbacks to consider:
- They take up additional storage space. Data storage costs money. Materialized Views will often contain orders of magnitude less rows than the original data tables, but this is still something to keep in mind. In Tinybird, both the original data and Materialized Views can be created with a TTL definition, to only retain data as needed.
- Not all SQL queries can be materialized. Depending on the database you use, you may find problems materializing queries with
UNIONorJOIN, for example, and you’ll need to avoid clauses likeLIMITorORDER BY. Materialized Views in Tinybird, however, do support JOINs and GROUP BY clauses, plus a few other clauses that some databases don’t allow. - They are not (necessarily) kept up to date automatically. Again, depending on your database, you may need to explicitly refresh data in your Materialized View as new data is ingested into your base tables. This isn’t the case in Tinybird (more below), but if the results of the query that you’re materializing change often, Materialized Views might hold stale data.
A special note about real-time analytics use cases
The database you use and the way it approaches Materialized Views will have a pretty significant impact on when it’s practical to use them. At Tinybird, we focus heavily on real-time analytics use cases, where we’re streaming large volumes of data, transforming that data in real-time using SQL, then publishing the results via low-latency API endpoints.
So for our applications, #3 above just won’t fly. If we use a traditional relational database like Postgres, for example, Materialized Views have to be forcefully refreshed when new data is ingested. If we’re streaming gigabytes of new data every second, like in many of our customers’ use cases, we wouldn’t keep up. Simply put, databases like Postgres (and other OLTP databases) aren’t meant for real-time data, because they require batch processes to keep the Materialized View current.
But with Tinybird, that’s a different story. As real-time data is ingested into Tinybird using one of its native source connectors, transformations, aggregations, and subsequent materializations happen on the fly, so Tinybird API endpoints always serve fresh data. For a little more on how that process works, you can check out our guide to mastering Materialized Views in Tinybird.
Wrapping up
Materialized Views are a tried and true way to grab performance benefits when query logic is frequently being applied and recycled at the application level, or when you need your endpoints to scan fewer rows. Use Materialized Views in most cases where you want to reduce application response time, simplify your codebase, and ensure consistent business logic across multiple data-consuming applications. And remember, if you’re going realtime, choose a database that can keep up.
If you're new to Tinybird, you can sign up for free today. The Build Plan is free forever, with no credit card required, no time restrictions, and generous tier limits.
Want to learn how Materialized Views are created in Tinybird? Check out our guide: Create Materialized Views with Transformation Pipes