


Data Warehouses as we know them came about for a pretty specific purpose: to let business people make business decisions based on business data. Bill Inmon described the Data Warehouse in 1992 as a “subject-oriented, non-volatile, integrated, time-variant collection of data in support of management’s decisions.”
The “father of Data Warehouses” himself understood that this new concept would open up data-driven approaches to strategic decision-making that our bosses’ bosses could use in the board room to rousing applause and victorious huzzahs.
Data Warehouses exist so that decision makers can make better decisions.
I think it’s safe to say that businesses now fully leverage the strategic insights that cloud Data Warehouses offer. We’re about a decade into the Cloud Data Warehouse "movement", and the results are as expected: Data Warehouses work well for business intelligence, and they’ve served up valuable analytical insight for business leaders from Texas to Tahiti.
In this blog post, I want to peel back the layers of the Data Warehouse onion, and explain why they exist, what they’re good for, and how they do it. This is a long post in its own right, but it’s actually a precursor to another one I plan to write explaining what Data Warehouses are not good for, and why. Stay tuned for that one.
Data Warehouses solve scalability problems by distributing storage and compute.
Before Data Warehouses were even a twinkle in Inmon’s eye, CEOs wanted to know how their business was doing. And way before data got “big”, the data we had on “how the business was doing” could pretty much fit on a floppy disk.
Of course, as we digitized, that data grew. So it became multiple files on a computer, and then at some point probably a dedicated database, still on a single computer.
Well I suppose the rest of the C Suite didn’t like their CEO sitting on the throne of the analytics monarchy, so to expand access to this data, we put that computer on a network. Now we could share the database and the riches within.
Then mid-management caught wind of the emerging oligarchy, and demanded democratic reform! “Give us data or give us death!” they shouted, and the “data-driven organization” was born from the ashes of the revolution*.
To meet the analytical needs of a growing number of users, we started creating multiple copies of the database running on different computers on the network. Data kept growing, and eventually this evolved into larger “servers” handling more shared sessions of users, but still with multiple distinct copies of the database.
You can see where this led to problems.
Ultimately, with many users trying to access a database on a single machine, we kept hitting the limits of the hardware. Plus, copying databases is slow, expensive, and hard to maintain. “Single source of truth” felt about as distant as the singularity back then.
By the late 20th century, what started as a pokéball of digital awareness had skipped past Charmander and evolved into a Charmeleon that we started to call “Analytics” or “BI”. Ultimately, with many users trying to access a database on a single machine, we kept hitting the limits of the hardware. Plus, copying databases is slow, expensive, and hard to maintain. “Single source of truth” felt about as distant as the singularity back then.
These problems led to the rise of distributed computing.
*my history is a bit fuzzy
Why do we need more than one machine?
It’s safe to say that, these days, data has reached full-on-holographic-Charizard level. The scale of analytical queries made on Data Warehouses today is immense. To handle that scale, Data Warehouses have to distribute the load. There’s only so much compute you can fit in a single machine, and at the scale demanded of these analytical use cases, a single machine just doesn’t cut it.

The average machine at one of the large cloud vendors falls somewhere below 64 CPU vCores and 256GB of memory. You’ll find the same thing if you buy your own hardware. A few machines offer more, but the cost of deploying them scales non-linearly. Go above this threshold and you’re dropping some serious cash to fill a rack.
But in the context of the Data Warehouse, 64 Cores & 256GB of memory is chump change. The largest Hadoop clusters, for example, reach 20,000 Cores and 64,000GB of memory (and test the limits of Hadoop in the process).
In today’s “data-driven” use cases, it’s not unheard of to have a single job that needs more than 256GB of memory. But the more common reality is that there are many, many smaller jobs that want concurrent access to those resources.
When you can’t vertically scale your machine at a reasonable cost, you’ve got one option: Buy more machines.
And when you can’t vertically scale your machine at a reasonable cost, you’ve got one option: Buy more machines.
But using more than one machine is hard.
As it turns out, distributing the load to multiple machines causes loads of problems. Not only is it harder to understand, but it’s also annoying to build and nightmarish to maintain.
Before we started distributing compute, we were used to writing sequential jobs: “Do X, then do Y, then do Z.” But in a distributed world, we’re asking many machines to do small parts of X, then use the pieces from X to start Y while finishing X, and on to Z…
This is when the MapReduce framework stepped in, formalizing how we built distributed loads, though it represented a new paradigm for those comfortable with working patterns. And like most paradigm shifts, it had a learning curve.
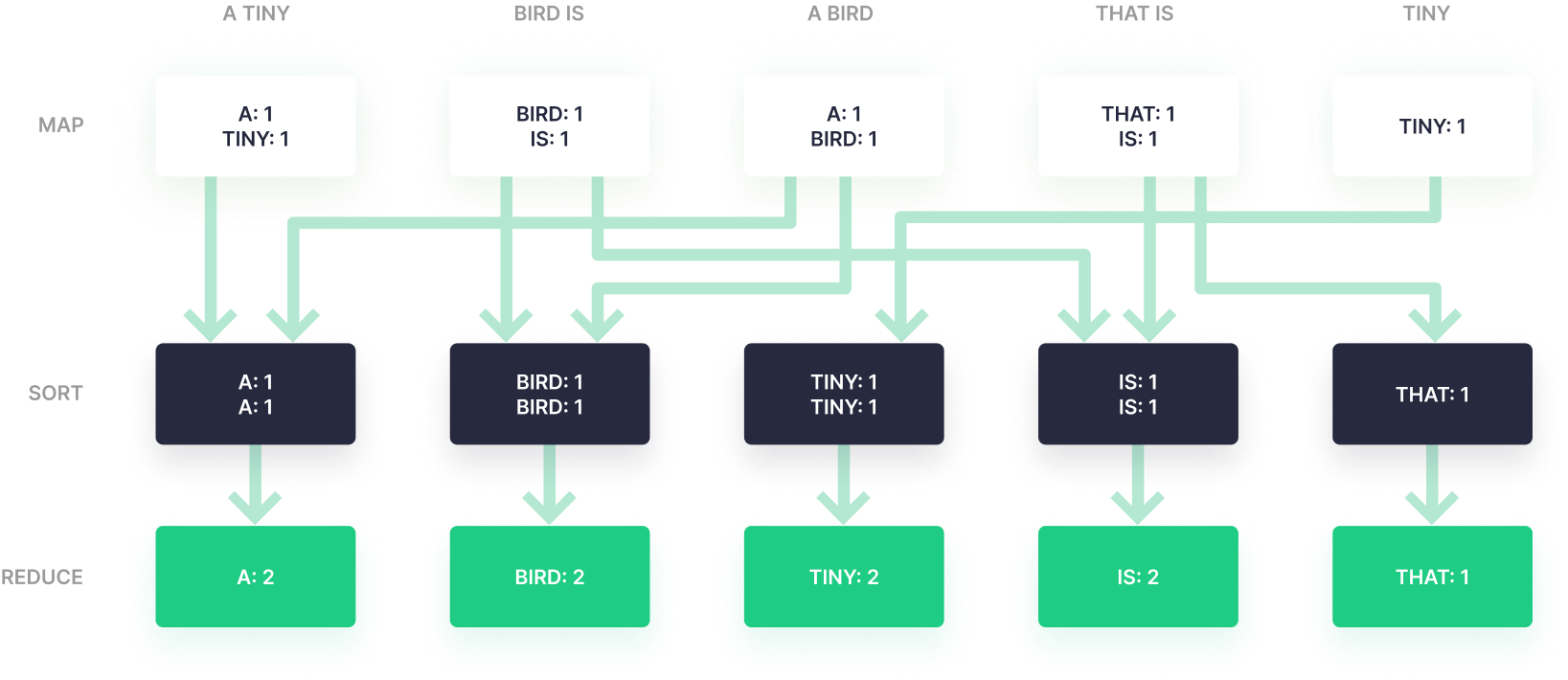
Spark started to make this framework more accessible by abstracting some of the low-level concepts, and Spark remains one of the most popular ways to write distributed compute jobs. But Spark still requires decent data engineers to be valuable.
Even then, it’s not just about the technical problem of processing jobs. While distributed databases make things easier on the business, they’re still a pain for the engineers who have to manage the hardware, understand specific software that can run on distributed systems, and maintain the configurations of that software across perhaps hundreds of different machines.
Debugging becomes a particularly dreaded nightmare because job logs get split across many machines. This means lots of time spent hunting down artifacts to get to the bottom of your problem.
How do many machines access the same data?
When you think of distributed file storage today, it’s likely that S3 springs to mind. But before S3, we had HDFS, the distributed file system behind Hadoop (hence the name: Hadoop Distributed File System). HDFS was the first solution that really enabled anyone to build a distributed file system; you didn’t need to go to a hardware vendor and buy their expensive, custom solution. You could just use any old hardware, stick HDFS on it and you had yourself a scalable, fault tolerant distributed file system.
These days, we talk about the “separation of storage and compute”, but this is still a relatively new development; in the days of HDFS, we had tightly coupled storage and compute. We’d build large servers (or ‘nodes’) with lots of CPU and memory, plus as much disk as would fit in the chassis. On these nodes, you’d run HDFS, which would create a distributed file system using all the disks on your machines, as well as your distributed compute engine of choice (e.g. MR, Spark, Hive, Impala, etc.).
Distributed file systems helped process query loads in parallel, but network throughput still limited performance. This gave importance to "Data Locality".
Now, although the file system was distributed across many machines, we still had a problem - networks were slow. It was significantly faster for Computer A to talk directly to its own disk than it was for Computer A to ask Computer B for data on its disk. This meant that a lot of effort was spent trying to ensure "data locality". Multiple replicas of data were kept on multiple machines, so when we created a job to process some data, we tried our best to place that job on one of the machines that had a replica of that data.
Data locality really helps with performance, but it's not always possible; if we had to process a lot of jobs at the same time, we couldn’t get picky about where they were processed, and we’d end up putting jobs on any machine that had spare capacity. This inevitably led to data being moved across the network, which naturally hurt the performance of jobs.
Trying to maintain high data locality (i.e. less network traffic) is hard, and it's not the only problem with this model of tightly coupled storage and compute.
Data Warehouses reduce costs by separating storage and compute
Data Warehouses have two eternal hurdles: more data & more users.
If we want to keep more data, we need to buy more storage. If we want to open the data up to more users, we need to add more compute resources. Sounds obvious, right? But in a tightly coupled model, we can’t do one without the other. If we just want to store more data, we don’t have a choice, we have to buy both. And if we just want to add more users, well, we still have to buy both.
Engineers are used to solving hard problems & battling with the consequences; but nothing ushers in a paradigm shift like depleted cost centers.
Engineers are used to solving hard problems & battling with the consequences; but nothing ushers in a paradigm shift like depleted cost centers.
Tightly coupled storage and compute promised performance benefits by minimizing network loads and their associated latency, but those promises were hard to keep in the real world, and the cost to scale this model became far too great. Thankfully, something else has changed: the cost & availability of high-speed, high-bandwidth networking. The recent and precipitous drop in network costs opened up the possibility of separating storage from compute, tackling them as distinct problems with different solutions and scaling them independently.
Pretty much all Warehouses have moved over to some kind of object storage. Amazon S3, Azure Blob Storage, and Google Cloud Storage are all Cloud-hosted object storage services, while MinIO, Ceph and Apache Ozone are options for those choosing to host their own tin. Like distributed file systems, object storage services store data across many machines, but they tend to do away with things like directories or file hierarchy, and present a much higher-level abstraction to the user.
Object storage services focus entirely on writing new data to disk and serving requests for data access. They are not concerned at all with processing data. Access to data is abstracted through APIs that make it easy to say which pieces of data you want, without ever needing to care exactly how or where it is stored. We don’t ever need to think about data locality, nor what our jobs are trying to actually do with the data. We can scale the amount of storage available based entirely on the amount of data we need to store, without caring about what kind of jobs our users are running.
And now, if our users start demanding more compute resources, or we add more users, we can just start adding more machines, focusing on higher core counts & stuffing in as much RAM as we can fit. We no longer need to think about placing jobs on specific machines to access local data, as all data access is via networked object storage.
Previously, we had quite complex resource management tools that would need to access metadata about where data was stored, so that it could accurately place processing jobs as close to the data as possible (ideally, on the same physical machine).
Separating storage & compute makes this unnecessary. We can place jobs anywhere. This flexibility has greatly simplified the task of resource management & job placement, and many frameworks have adopted containerization (e.g. Docker, Kubernetes, OpenShift, etc.) to take advantage of this flexibility. We can even create walled gardens of compute, and dedicate these resources to specific teams, while still being able to access the same data.
The basis of storage-compute separation is networking. We’re moving crazy amounts of data between our storage and processing layers. That's why Cloud is so attractive for data warehouses.
However, the basis of this model is networking. We’re moving crazy amounts of data between our storage and processing layers. Since data can’t traverse a network faster than the speed of light, we mortals will perpetually suffer under the laws of physics that impose latency upon our compute jobs.
Leveraging cloud networking for more throughput
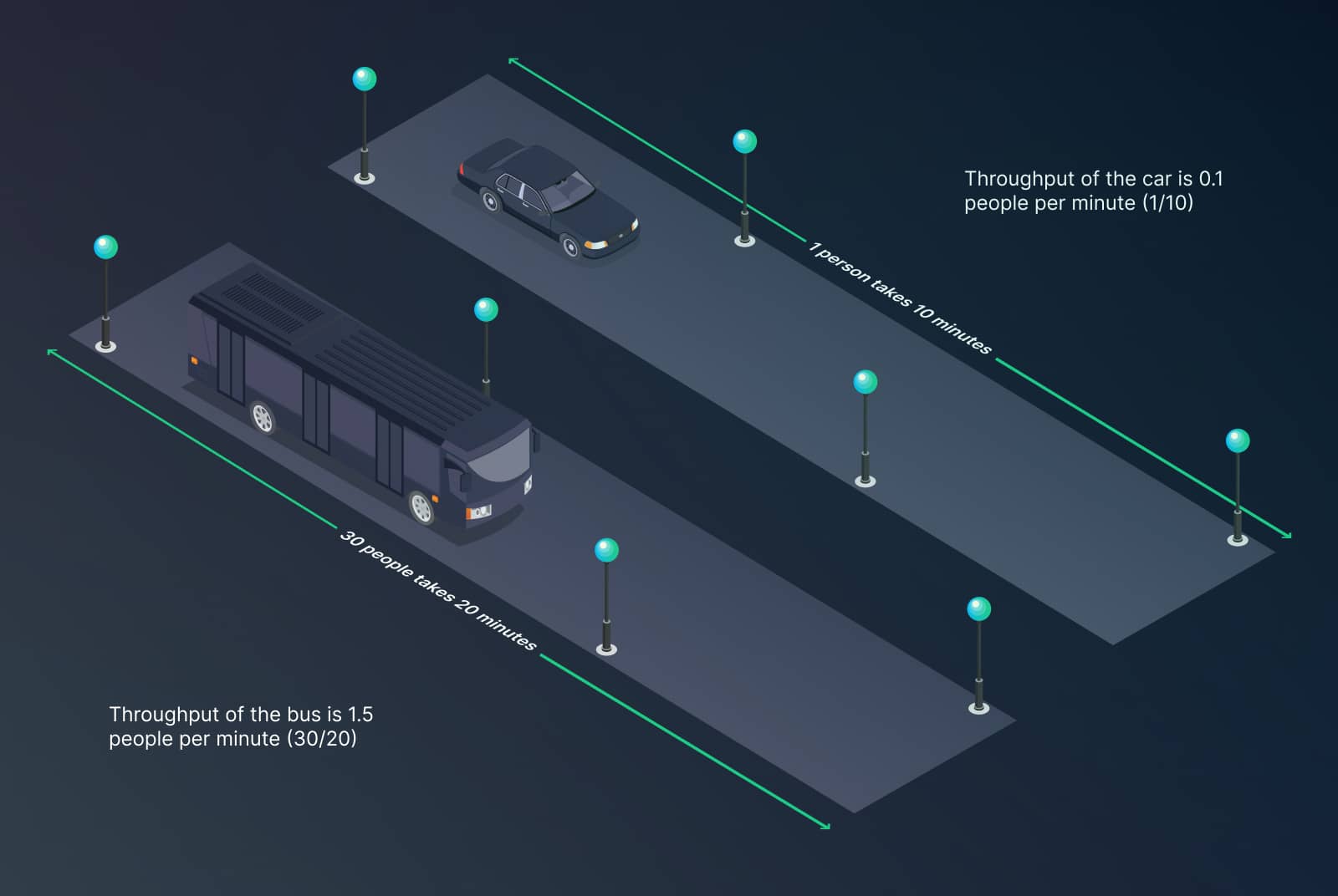
If you’re not sure about the difference between latency and throughput, consider this example:
A car carrying 1 person takes 10 minutes to get to the station, while a bus carrying 30 people takes 20 minutes. The car has a latency of 10 minutes. The bus, 20 minutes.
However, the bus has moved 30 people, while the car only moved 1. You could say that the throughput of the car is 0.1 people per minute (1/10) while the throughput of the bus is 1.5 people per minute (30/20).
Though latency will never break the light speed barrier, we can improve throughput by increasing the bandwidth of the network. A 1Gb network (that’s 1 Gigabit per second of bandwidth) is nearly top of the line for a home network, but it’s slow by data center standards. To maintain decent performance in this separated model, data centers now have multiple 40Gb or 100Gb network links to bridge between storage and compute services.
There’s many reasons why the Cloud is so attractive for Data Warehouses, but networking is one of the most important (and probably one of the most overlooked). Building fast & reliable networks is complex, with an astronomical upfront investment.
Data Warehouses make analytics accessible with SQL
Businesses are storing way more data than they did a decade ago, and the rate at which we generate data is still increasing exponentially. Those that struggled to store 200Gb of data in 2010 now store hundreds of terabytes in Cloud object storage without losing any sleep. The demand for ever more data storage is not going away anytime soon.
As data becomes more and more pervasive, we’re finding more and more creative things to do with that data. Beyond your typical BI, we now have AI/ML that is being trained with this data, or we’re surfacing this data back to our users to build better user experiences.
But, if we want to achieve more with all of this data, we need to enable more people to use it.
Data Warehouses adopted SQL to make data access and analytics more accessible across the organization.
Gone are the days that you needed to understand distributed computing paradigms & write crazy Java to exploit data. SQL may have fallen out of favor for a couple years in the middle, but it’s back stronger than ever today.
Most Data Warehouses have abstracted their complex, distributed nature behind a very familiar SQL interface. Anyone with SQL skills can come along and use the data, while the system handles translating that into the underlying distributed compute model.
What's next for Data Warehouses?
The cloud Data Warehouse has likely enabled the majority of meaningful, enterprise-level, data-driven business decision in the last few years. What it has allowed businesses to do is quite incredible, and we owe much to the vendors that have popularized and commercialized Data Warehouses for our use and benefit.
But, the only thing that never changes is change itself.
Already, the Data Warehouse concept is evolving. Even more recently we have the emergence of the Data Lake and the Lakehouse (though I much prefer a Mountain Chalet). These extend the Data Warehouse by taking the separation of storage and compute a step further.
The Data Warehouse physically separates the two; The Data Lake and its accompanying structures have begun to introduce their logical separation. Specifically, Data Lakes conceptually suggest that READ operations and WRITE operations should not be intermingled, and instead of processing write jobs through the Warehouse, send data directly to Object storage. The Warehouse only gets involved in the READ process.
The Data Lake is another technological advancement in how we handle data. But the more pressing issue is how this data is handled organizationally (or operationally).
Until very recently, it seemed that the primary need of the modern business was to know. We saw data as the fountain of knowledge, and Data Warehouses as the vessels that hold and dispense it.
Our needs are changing. It’s no longer enough to know. Now, we want to do. And we want to do fast. That means automation. That means injecting analytics back into the products themselves. It means building software on top of analytics. This is called real-time analytics.
Our needs are changing, and the current iteration of the Data Warehouse won't fully meet our most pressing upcoming needs.
And as I’ll explain in a soon-to-follow post, the current iteration of the Data Warehouse might not be up for the journey ahead.
As real-time demands continue to rise, many teams are also rethinking their analytical engines. If you're evaluating how traditional cloud warehouses compare to modern real-time OLAP databases, this breakdown of ClickHouse® vs BigQuery for real-time analytics offers a practical look at performance tradeoffs, architectural differences, and cost considerations when low-latency workloads matter.