


At organizations with Data Engineering practices, a data warehouse like Snowflake is the business-critical infrastructure that powers much of the company’s strategic decision-making.
If you’re part of said Data Engineering team, your job is to build, operate, and maintain your Snowflake instance, adding new data sources, optimizing queries, and empowering consumers within your organization to access and analyze the data.
Data engineers at Snowflake companies are tasked with building, operating, maintaining, and controlling access to the data warehouse.
And if you’re like most Data Engineers, your most significant constraints are resources (both people and infrastructure) and budget (i.e., you know that Snowflake can get expensive, very quickly).
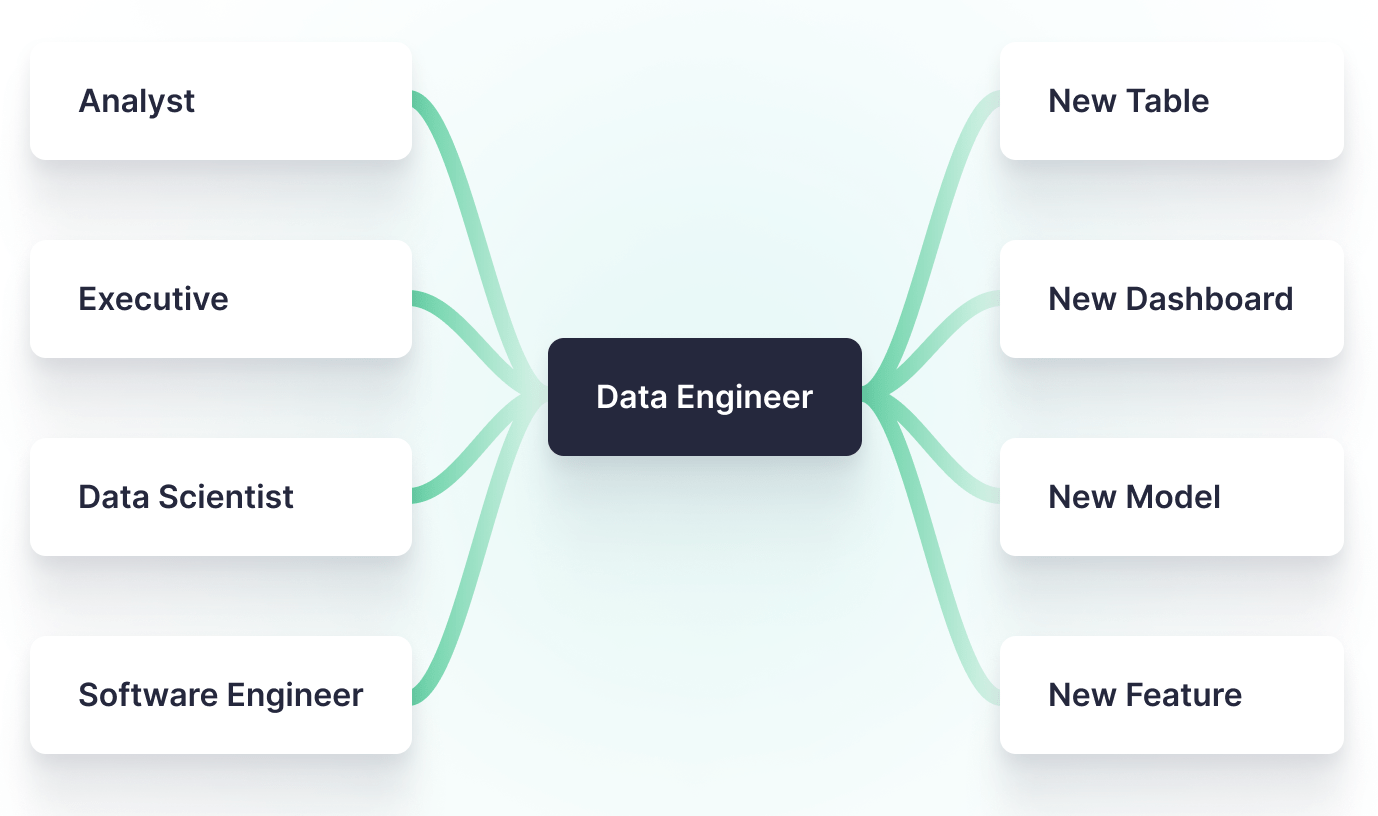
You might feel like it’s your job to “defend the keep,” quickly and cost-effectively portioning out access to a powerful and potentially expensive resource, handling requests from analysts, data scientists, executives, and software engineers.

That last group (software engineers) are often thought of primarily as data producers. But what happens when Product wants to start building features based on data in Snowflake? All of a sudden, Data Engineers have another mouth to feed.
Software engineers are often thought of as data producers, but when they become data consumers, it adds additional burden on already burdened Data Engineers.
And when Product gets involved with data, it poses some added uncertainties to your domain. Their user-facing requirements bring questions: How many concurrent users? What latency is required? How fresh does the data need to be? What do the queries look like and how frequently will they be run?
Even with definitive answers to these questions, you’ll have a hard time creating the data products that software engineers need without either neglecting other data consumers or risking cost overruns
In this blog post, we'll talk about 5 different struggles that Data Engineers experience when they’re trying to serve software engineers as data consumers. Then, we’ll share how Tinybird can help you surface your company’s Snowflake data quickly and inexpensively so you can satisfy all your data consumers without added trouble.
This blog post covers 5 common struggles that Data Engineers deal with when managing Snowflake, and how Tinybird can alleviate some of the stress when working with software engineers and product teams as data consumers.
The new Tinybird Snowflake Connector makes it easy to sync your Snowflake data to Tinybird and create low-latency APIs for your software team to consume at roughly 1/10th the cost of alternatives. For a comprehensive comparison of ClickHouse® alternatives including managed services and cloud data warehouses, see our honest comparison of the top ClickHouse® alternatives in 2025.
From there, you can query and shape your data using SQL and publish your queries as fast REST APIs. With Tinybird, your entire organization can build solutions based on your Snowflake data, without any red tape, with high performance, and in minutes instead of months or years.
Tinybird and Snowflake are, indeed, better together.
Background: Snowflake's pricing creates cost anxiety for data teams
For data teams that use it, Snowflake is one of the largest, if not the largest, cost centers to manage. Even when properly optimized, it can be expensive to maintain and operate. Data teams are responsible for controlling Snowflake costs and forecasting them. So before any stakeholder gets access, there's some up-front analysis of the use case to assess the technical needs and the cost implications. For teams considering alternatives, our ClickHouse® vs Snowflake comparison explores how ClickHouse® can deliver better price-performance for real-time analytics workloads.
While you’ll only pay for storage once for all the consumers of your data, you will pay for compute each time a consumer requires access to that data.
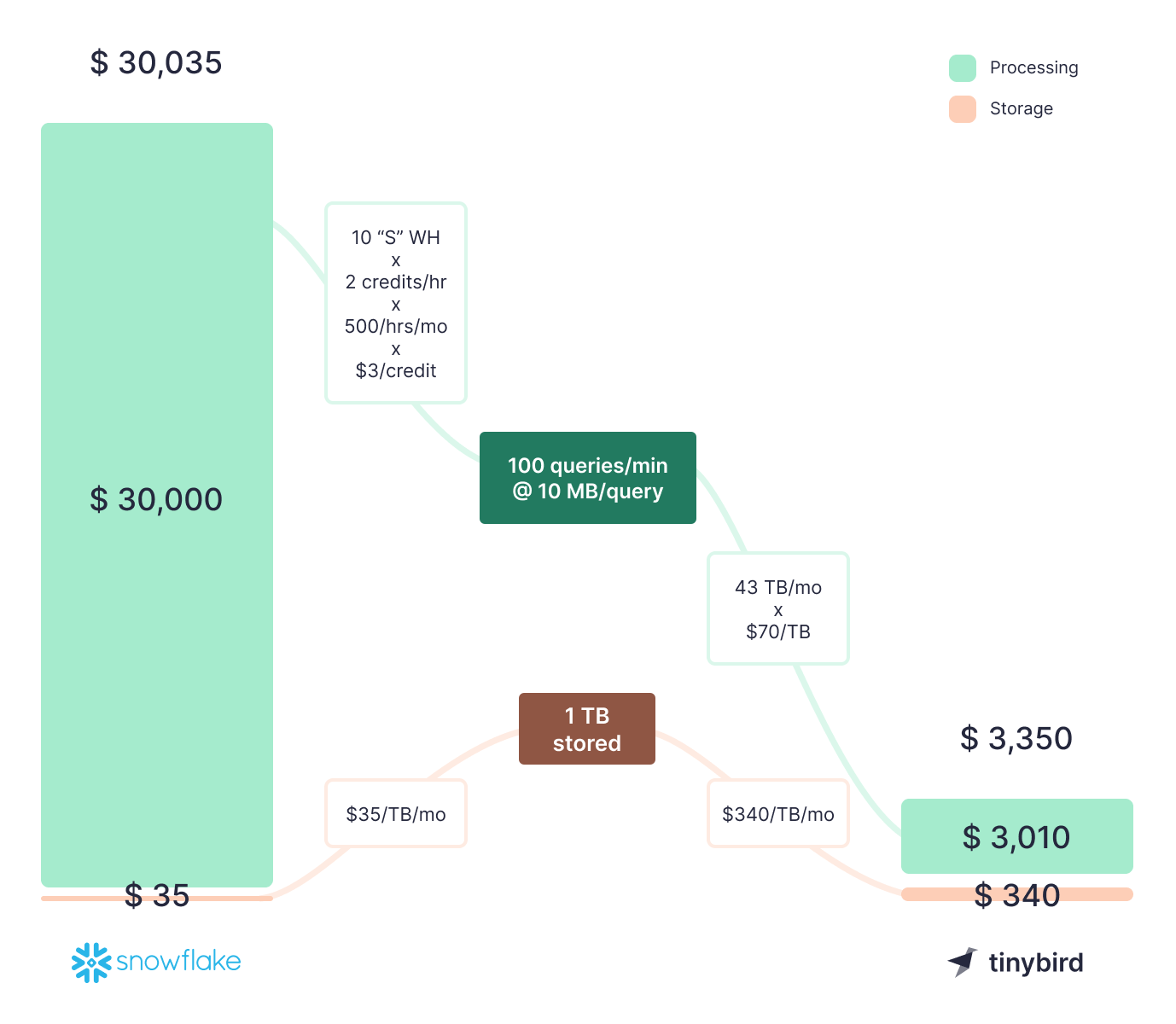
For most businesses, compute - and the credits it consumes - is the biggest line item on the Snowflake bill. Compute cost is directly correlated to the sophistication of your analytical dashboards, ETL processes, data pipelines, and more. A mid-sized organization can easily rack up a $30,000/month Snowflake bill operating just two X-Large warehouses running about 10 hours a day.
Snowflake can get very expensive, very fast, which is why data teams keep tight control over access to it.
Because Snowflake charges per second of compute, many data organizations try to keep the Snowflake data warehouse paused for as long as possible.
Whenever someone or something queries that data warehouse, it must be running. When those someones or somethings are analysts or data scientists, it’s usually simpler to keep those runtimes scheduled and bounded.
But when that someone is a bunch of external users, you have zero control. You’ll have almost no choice but to run the warehouse 24/7. And on top of that, you will most likely encounter concurrency issues on a single warehouse (even if it’s multi-cluster), and you’ll need to add more warehouses to support it.
As a result, data teams charged with maintaining Snowflake justifiably want tight control over who can access that data, how often they can access it, and how much freedom they have to manipulate in the warehouse (if any). In particular, they are especially concerned about external access through user-facing applications.
Access to Snowflake goes through Data Engineering, both in terms of technical development and cost forecasting and control.
As a consequence, while using Snowflake can often be of great benefit to an organization, it comes with a little pain for Data Engineers.
Specifically, Data Engineers often experience the following 5 struggles with Snowflake:
- Snowflake costs are hard to predict.
- Snowflake is not suited for high concurrency and low latency.
- Snowflake is a terrible application backend.
- Snowflake requires dedicated data engineering resources.
- Granting access to Snowflake tables often means a lot of red tape.
Let’s dive into these struggles in more detail and examine how Tinybird can help unblock data teams with each one.
Struggle #1: Snowflake costs are hard to predict.
Snowflake is a core data infrastructure for data-centric businesses, so its high cost can often be justified by its criticality. That said, Snowflake costs are a common concern for data leaders. Snowflake can quickly become expensive, especially when used inappropriately, like as a backend for production applications.
When you’re paying by the second to operate pre-sized warehouses with limited concurrency, you’ll rack up quite a bill to support user-facing applications with a high number of concurrent users making many API requests. That’s why Snowflake should never be used as an application backend. It’s costly enough as it is.
And even when used as it should be, there are so many factors that contribute to Snowflake compute costs: warehouse sizing, runtime groupings, serverless compute functions, cloud services, storage, transfer, etc. On top of all those factors, every query you run on a Snowflake warehouse will cost you, whether it’s in production or not. Feature development on Snowflake has its own costs that can be much harder to predict than stable production applications.
Tinybird eliminates the need for data consumers to access Snowflake directly, which means Snowflake costs will be much more predictable.
Tinybird eliminates the need for most data consumers to access Snowflake directly. By functioning as a publication layer, Tinybird surfaces integrated and preprocessed Snowflake data for operational applications at a fraction of the cost of doing the same with Snowflake. For a detailed breakdown of how Tinybird compares to ClickHouse® Cloud across multiple cost scenarios, see our comprehensive cost analysis.
Furthermore, Tinybird’s usage-based compute pricing maps much more directly to the value delivered by increased app usage. For Pro Plan users, Tinybird charges $0.07/GB processed only by published SQL. Unlike Snowflake, Tinybird won’t charge you for queries that aren’t exposed as APIs or Materialized Views, so development costs come way down.
Struggle #2: Snowflake is not suited for high concurrency and low latency.
Snowflake is not suited for low-latency, high-concurrency queries. Even if you do decide to just “throw money at it” and use Snowflake for user-facing features, you’ll quickly run into freshness, latency, and concurrency constraints.
Snowflake processes queries in a job pool. Even basic queries that consume basically zero resources (think SELECT 1) can take a second or two to respond.
Additionally, each warehouse is limited in its ability to support concurrent queries. If thousands of concurrent users make dozens of API requests per minute, prepare for an exorbitant bill or a slow user experience.
Developing directly on top of Snowflake might feel more comfortable for a Data Engineer, but if you choose this path in production you'll either pay to scale your warehouses or suffer high-latency query responses, neither of which are tenable solutions.
Building user-facing applications directly on top of Snowflake is either prohibitively expensive or unbearably slow. You choose.
Tinybird acts as a middle layer between Snowflake and your applications that supports high-concurrency requests with very low latency and at a much more reasonable cost. Tinybird ingests data from Snowflake, enables you to query and shape it using SQL, and then exposes those queries as high-concurrency, low-latency REST APIs that can be consumed from any application.
Furthermore, Tinybird can enrich streams from event platforms like Kafka with data in Snowflake. This is especially useful when product teams want to add differentiating real-time features such as real-time personalization or smart inventory management.
In summary, Tinybird can be immensely useful to help you scale your applications, maintain the freshness of your data, and control costs. You can develop and prototype queries over normalized tables in Tinybird without any additional costs, freeing your software teams to explore product ideas and implementation concepts without incurring added costs or placing added strain on data teams.
Struggle #3: Snowflake is a terrible application backend.
Even if Snowflake's cost and technical capabilities were acceptable for user-facing feature development, software engineering/DevOps teams would still need to build and host a backend for the application to expose the data.
A common path for software developers building over Snowflake data is to pre-aggregate metrics in Snowflake and then push them to Redis or Cloud SQL, upon which they’ll build a web service. These moving parts add complexity without solving the underlying concurrency problems of using Snowflake.
Tinybird is built to be a real-time backend. It abstracts and automates things like real-time data ingestion, API development, authentication, scalability, parameterization, and documentation so that both Data Engineers and Software Engineers can focus on data quality, performance, and feature development.
The idea behind Tinybird is simple: Take an up-to-date Snowflake table, query it with SQL, and publish your queries as APIs that scale to meet user needs. In this sense, Tinybird effectively becomes an application backend. It handles authentication, scalability, parameterization, and documentation for your APIs.
Tinybird frees you to focus resources on your most pressing problems instead of writing weeks’ worth of undifferentiated plumbing code.
Struggle #4: Snowflake requires dedicated data engineering resources.
Another pain associated with using Snowflake is the need for dedicated Data Engineers to manage and maintain the deployment. When it comes to Snowflake data, all paths must cross through the Data Team.
Snowflake is a complex system that requires expertise to maintain and optimize. As a result, organizations dedicate significant resources to managing their Snowflake deployment. Hiring more data engineers to support new feature development can be a non-starter when budgets are tight, and managers are simultaneously concerned about overworking their existing teams and risking burnout. It’s a catch-22 for modern data teams.
Tinybird can unburden data engineers and minimize resource needs by giving product-building teams more ownership over data pipelines while still protecting data quality in the source of truth (i.e., Snowflake).
Tinybird shifts energy from Data Engineering to Software Engineering. It gives software engineers more control over the data pipelines they use for feature development while maintaining Data Engineering's control over the single source of truth.
Smaller data teams can focus on managing just a few core Data Sources within Tinybird, and backend developers can query over them as needed to build and test their features. Using Tinybird APIs, CLI, or UI, software developers become much more self-sufficient in managing the data pipelines they need for their features. Instead of the back-and-forth to iterate with data engineering, software developers can write their own SQL, publish it as APIs, and call them from their applications.
Struggle #5: Granting access to Snowflake tables often means a lot of red tape.
Every query you run in Snowflake eats credits. And credits cost money ($2-4 per credit, to be more precise). Because of the risk of significant cost overruns due to unoptimized queries and wanton SELECT *s, organizations tightly control who can access the data stored in Snowflake, resulting in lengthy back-and-forth justification for resources.
Data Engineers hold the keys to Snowflake in most companies, and anything that might consume more credits must go through them. In large organizations, warehouses can be assigned to a team, passing the billing responsibility to them. In smaller organizations, Data Engineers control the company’s overall spend. Regardless, you’ll need to justify your use case to gain access to Snowflake.
Data Engineers hold the keys to Snowflake. They decide who gets access, and how much.
For example, if an executive needs a new chart on a dashboard, that may need Data Engineering approval. Analyst wants a new table or view? Approval required. And if a software developer has an idea for a new feature and needs Snowflake data to build it, that request likely goes through the already-overburdened data team, which takes time, slows the decision-making process, and can deter new feature development.
You can avoid this red tape by unfreezing data in Snowflake and moving it to a middle layer more readily, and less expensively, accessible by everyone in your organization. This is generally the process for business intelligence. The Data Team exposes certain tables and views to Looker or Tableau, and analysts construct queries over those tables.
For BI use cases, Data Engineers will expose tables or views to BI tools like Tableau or Looker so that analysts can construct queries and dashboards over those sanitized data products. But user-facing features aren't built with BI tools.
But user-facing applications and new product features aren’t built with Looker. They’re built with Python and TypeScript and C#. More importantly, they’re built over APIs that expose the data they need to run.
Fortunately, Tinybird is built to be an analytical backend for user-facing applications, and Data Teams have two options for how they manage it: Data engineers can set up scheduled syncs of Snowflake tables to Tinybird just once, build incrementally updating Materialized Views, and hand the keys to software developers who can write SQL in Tinybird Pipes and publish that SQL as dynamic, low-latency APIs to power their features.
Alternatively, Data Engineers can retain complete control over the data pipelines, and use Tinybird as a force multiplier to make it quite easy to publish data products as APIs that their software engineering consumers can use.
Either approach is valid, and the approach depends on resources, time, goals, and technical capacity of the various team members.
Tinybird maintains up-to-date copies of Snowflake tables in an environment designed for high-concurrency and low-latency querying, which is perfect for software engineers and the user-facing features they are building.
Regardless, this results in faster feature development without over-burdening the data team and using a tool that is cost-optimized for API development and maintenance.
Tinybird and Snowflake are better together.
Tinybird is a data processing platform and publication layer designed to help organizations surface their Snowflake data for application development both quickly and inexpensively.
With Tinybird, data engineers can easily sync Snowflake data to Tinybird and then expose it to consumers across the organization. Data teams retain control over Snowflake costs and data quality while reducing their workload and maintaining a single source of truth for the organization’s data.
With Tinybird, data teams retain control over Snowflake while reducing their workload and maintaining data quality in their organization's single source of truth. At the same time, product teams get access to the data they need with a backend built for publishing data-driven application features.
Simultaneously, product builders within the organization can consume Snowflake data and quickly build applications directly on top of Tinybird, significantly reducing the compute resources needed within Snowflake and massively improving product speed to market.

It’s a win-win for both sides. Data engineers defend the sanctity of the organization’s data without an added burden, and developers get structured, risk-free access to build new features on top of the data they need.
Get started with Tinybird today
If you’re new to Tinybird, you can sign up for free (no credit card needed) and start syncing data from Snowflake and many other sources today. You can also check out the documentation for more implementation details about using the Snowflake Connector. Also, feel free to join the Tinybird Community on Slack to ask any questions.