Ingest from Google Cloud Storage¶
In this guide, you'll learn how to automatically synchronize all the CSV files in a Google GCS bucket to a Tinybird data source.
Prerequisites¶
This guide assumes you have familiarity with Google GCS buckets and the basics of ingesting data into Tinybird.
Perform a one-off load¶
When building on Tinybird, people often want to load historical data that comes from another system (called 'seeding' or 'backfilling'). A very common pattern is exporting historical data by creating a dump of CSV files into a Google GCS bucket, then ingesting these CSV files into Tinybird.
You can append these files to a data source in Tinybird using the data sources API.
Let's assume you have a set of CSV files in your GCS bucket:
List of events files
tinybird-assets/datasets/guides/events/events_0.csv tinybird-assets/datasets/guides/events/events_1.csv tinybird-assets/datasets/guides/events/events_10.csv tinybird-assets/datasets/guides/events/events_11.csv tinybird-assets/datasets/guides/events/events_12.csv tinybird-assets/datasets/guides/events/events_13.csv tinybird-assets/datasets/guides/events/events_14.csv tinybird-assets/datasets/guides/events/events_15.csv tinybird-assets/datasets/guides/events/events_16.csv tinybird-assets/datasets/guides/events/events_17.csv tinybird-assets/datasets/guides/events/events_18.csv tinybird-assets/datasets/guides/events/events_19.csv tinybird-assets/datasets/guides/events/events_2.csv tinybird-assets/datasets/guides/events/events_20.csv tinybird-assets/datasets/guides/events/events_21.csv tinybird-assets/datasets/guides/events/events_22.csv tinybird-assets/datasets/guides/events/events_23.csv tinybird-assets/datasets/guides/events/events_24.csv tinybird-assets/datasets/guides/events/events_25.csv tinybird-assets/datasets/guides/events/events_26.csv tinybird-assets/datasets/guides/events/events_27.csv tinybird-assets/datasets/guides/events/events_28.csv tinybird-assets/datasets/guides/events/events_29.csv tinybird-assets/datasets/guides/events/events_3.csv tinybird-assets/datasets/guides/events/events_30.csv tinybird-assets/datasets/guides/events/events_31.csv tinybird-assets/datasets/guides/events/events_32.csv tinybird-assets/datasets/guides/events/events_33.csv tinybird-assets/datasets/guides/events/events_34.csv tinybird-assets/datasets/guides/events/events_35.csv tinybird-assets/datasets/guides/events/events_36.csv tinybird-assets/datasets/guides/events/events_37.csv tinybird-assets/datasets/guides/events/events_38.csv tinybird-assets/datasets/guides/events/events_39.csv tinybird-assets/datasets/guides/events/events_4.csv tinybird-assets/datasets/guides/events/events_40.csv tinybird-assets/datasets/guides/events/events_41.csv tinybird-assets/datasets/guides/events/events_42.csv tinybird-assets/datasets/guides/events/events_43.csv tinybird-assets/datasets/guides/events/events_44.csv tinybird-assets/datasets/guides/events/events_45.csv tinybird-assets/datasets/guides/events/events_46.csv tinybird-assets/datasets/guides/events/events_47.csv tinybird-assets/datasets/guides/events/events_48.csv tinybird-assets/datasets/guides/events/events_49.csv tinybird-assets/datasets/guides/events/events_5.csv tinybird-assets/datasets/guides/events/events_6.csv tinybird-assets/datasets/guides/events/events_7.csv tinybird-assets/datasets/guides/events/events_8.csv tinybird-assets/datasets/guides/events/events_9.csv
Ingest a single file¶
To ingest a single file, generate a signed URL in GCP, and send the URL to the data sources API using the append mode flag:
Example POST request with append mode flag
curl -H "Authorization: Bearer <your_auth_token>" \ -X POST "https://api.tinybird.co/v0/datasources?name=<my_data_source_name>&mode=append" \ --data-urlencode "url=<my_gcs_file_http_url>"
Ingest multiple files¶
If you want to ingest multiple files, you probably don't want to manually write each cURL. Instead, create a script to iterate over the files in the bucket and generate the cURL commands automatically.
The following script example requires the gsutil tool and assumes you have already created your Tinybird data source.
You can use the gsutil tool to list the files in the bucket, extract the name of the CSV file, and create a signed URL. Then, generate a cURL to send the signed URL to Tinybird.
To avoid hitting API rate limits you should delay 15 seconds between each request.
Here's an example script in bash:
Ingest CSV files from a Google Cloud Storage Bucket to Tinybird
TB_HOST=<region>
TB_TOKEN=<token>
BUCKET=gs://<name_of_bucket>
DESTINATION_DATA_SOURCE=<name_of_datasource>
GOOGLE_APPLICATION_CREDENTIALS=
REGION=<region>
for url in $(gsutil ls $BUCKET | grep csv)
do
echo $url
SIGNED=`gsutil signurl -r $REGION $GOOGLE_APPLICATION_CREDENTIALS $url | tail -n 1 | python3 -c "import sys; print(sys.stdin.read().split('\t')[-1])"`
curl -H "Authorization: Bearer $TB_TOKEN" \
-X POST "$TB_HOST/v0/datasources?name=$DESTINATION_DATA_SOURCE&mode=append" \
--data-urlencode "url=$SIGNED"
echo
sleep 15
done
The script uses the following variables:
TB_HOSTas the corresponding URL for your region.TB_TOKENas a Tinybird Token withDATASOURCE:CREATEorDATASOURCE:APPENDscope. See the Tokens API for more information.BUCKETas the GCS URI of the bucket containing the events CSV files.DESTINATION_DATA_SOURCEas the name of the data source in Tinybird, in this caseevents.GOOGLE_APPLICATION_CREDENTIALSas the local path of a Google Cloud service account JSON file.REGIONas the Google Cloud region name.
Automatically sync files with Google Cloud Functions¶
The previous scenario covered a one-off dump of CSV files in a bucket to Tinybird. A slightly more complex scenario is appending to a Tinybird data source each time a new CSV file is dropped into a GCS bucket, which can be done using Google Cloud Functions.
That way you can have your ETL process exporting data from your Data Warehouse (such as Snowflake or BigQuery) or any other origin and you don't have to think about manually synchronizing those files to Tinybird.
Imagine you have a GCS bucket named gs://automatic-ingestion-poc/ and each time you put a CSV there you want to sync it automatically to an events data source previously created in Tinybird:
- Clone this GitHub repository (
gcs-cloud-function). - Install and configure the
gcloudcommand line tool. - Run
cp .env.yaml.sample .env.yamland set theTB_HOST, andTB_TOKENvariable - Run:
Syncing from GCS to Tinybird with Google Cloud Functions
# set some environment variables before deploying PROJECT_NAME=<the_GCP_project_name> SERVICE_ACCOUNT_NAME=<service_account_name@project_name.iam.gserviceaccount.com> BUCKET_NAME=<bucket_name> REGION=<region> TB_FUNCTION_NAME=<name_of_the_function> # grant permissions to deploy the cloud function and read from storage to the service account gcloud projects add-iam-policy-binding $PROJECT_NAME --member serviceAccount:$SERVICE_ACCOUNT_NAME --role roles/storage.admin gcloud projects add-iam-policy-binding $PROJECT_NAME --member serviceAccount:$SERVICE_ACCOUNT_NAME --role roles/iam.serviceAccountTokenCreator gcloud projects add-iam-policy-binding $PROJECT_NAME --member serviceAccount:$SERVICE_ACCOUNT_NAME --role roles/editor # deploy the cloud function gcloud functions deploy $TB_FUNCTION_NAME \ --runtime python38 \ --trigger-resource $BUCKET_NAME \ --trigger-event google.storage.object.finalize \ --region $REGION \ --env-vars-file .env.yaml \ --service-account $SERVICE_ACCOUNT_NAME
It deploys a Google Cloud Function with name TB_FUNCTION_NAME to your Google Cloud account, which listens for new files in the BUCKET_NAME provided (in this case automatic-ingestion-poc), and automatically appends them to the Tinybird data source described by the FILE_REGEXP environment variable.
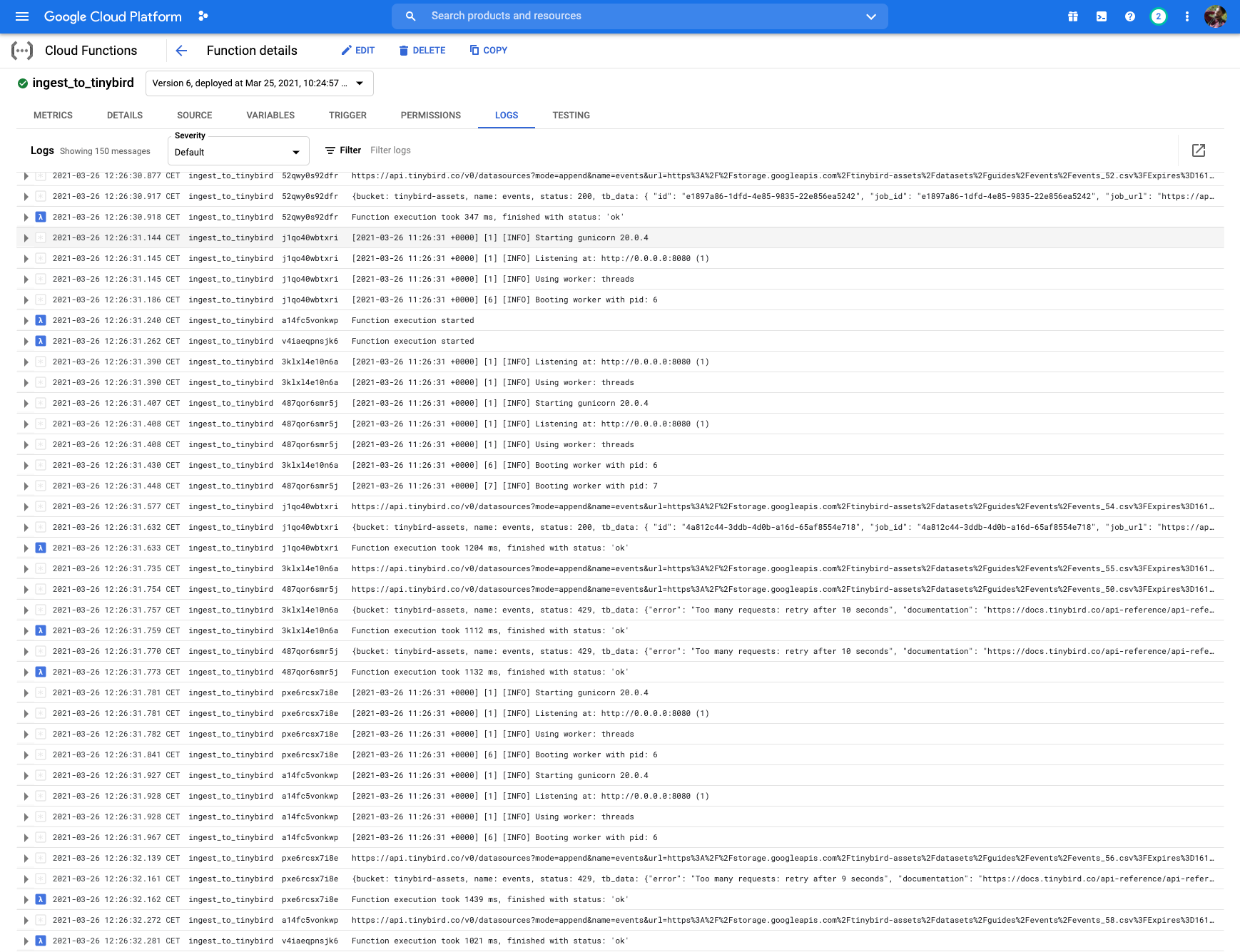
Now you can drop CSV files into the configured bucket:
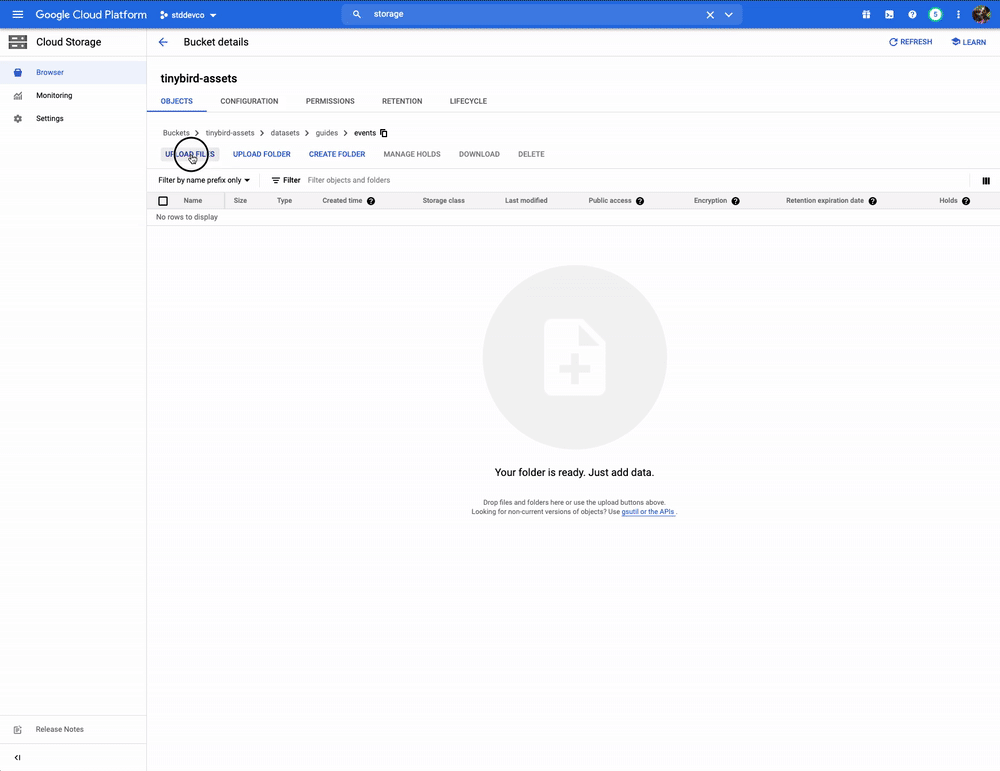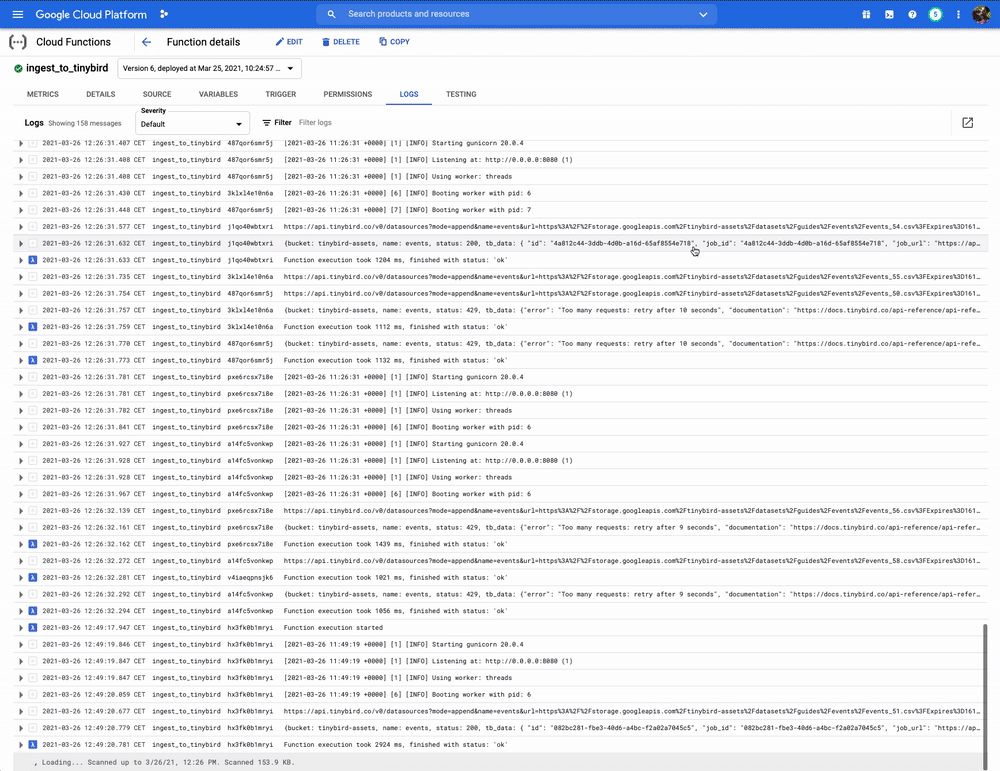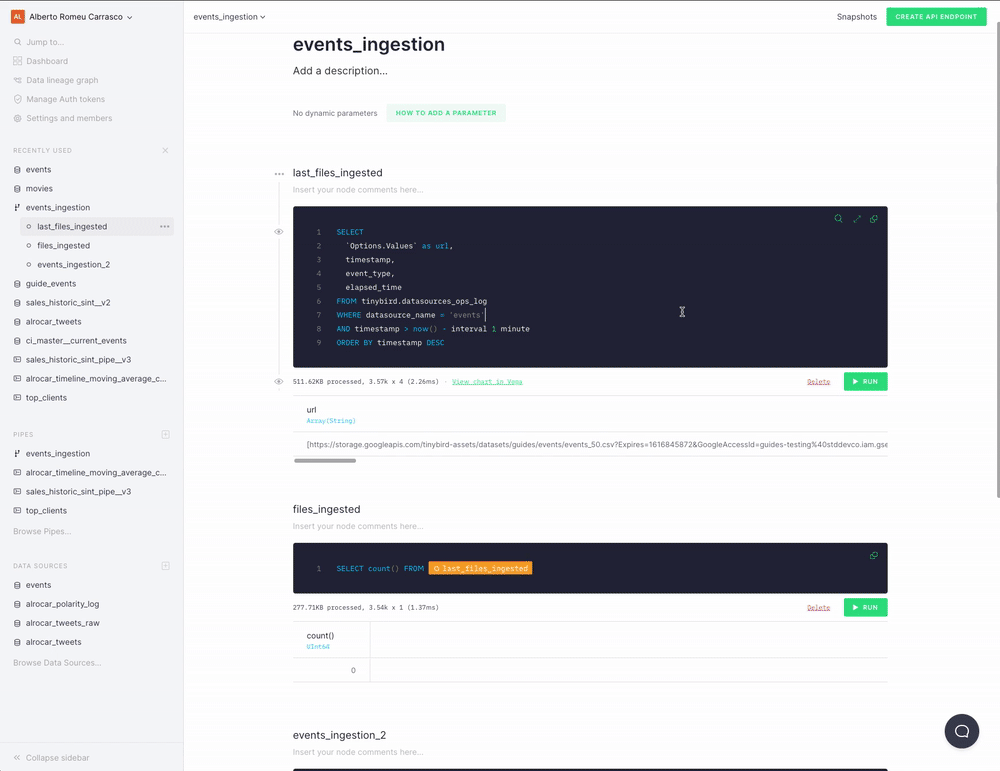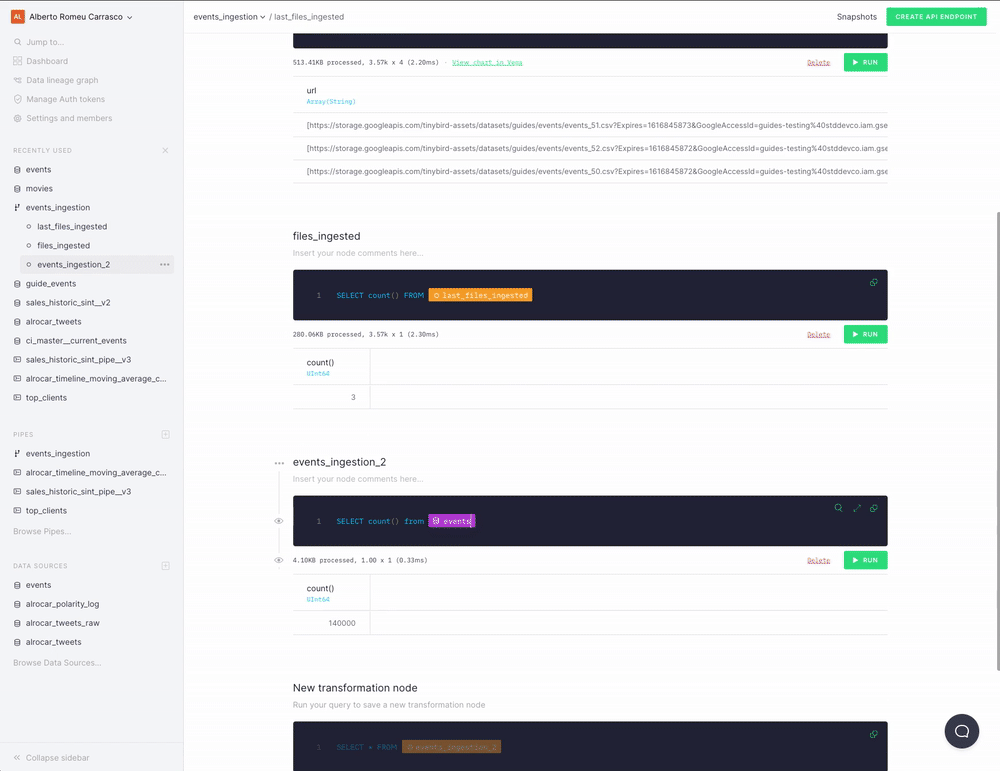
A recommended pattern is naming the CSV files in the format datasourcename_YYYYMMDDHHMMSS.csv so they are automatically appended to datasourcename in Tinybird. For instance, events_20210125000000.csv will be appended to the events data source.