
tinybird.co
v0.1.6
And AWS went down
Hey, Javi here. Systems that work at scale, fail at scale.
AWS us-east went down, or at least partially down, and took a chunk of the internet with it. You already know about it, there’s no point explaining it again since plenty of sites have done that. For reference if you read this in the future, I’m talking about this incident caused by DynamoDB going down because of a DNS problem.
As a software company, you can’t rely on something like this unless you train for it every day, and even then, you’ll need many rounds before you get it right. Building a multicloud strategy, with everything it needs like adding that complexity to the tech stack is a luxury most can’t afford, except in very rare cases. Even if you’re AWS, you might “choose” not to do it.
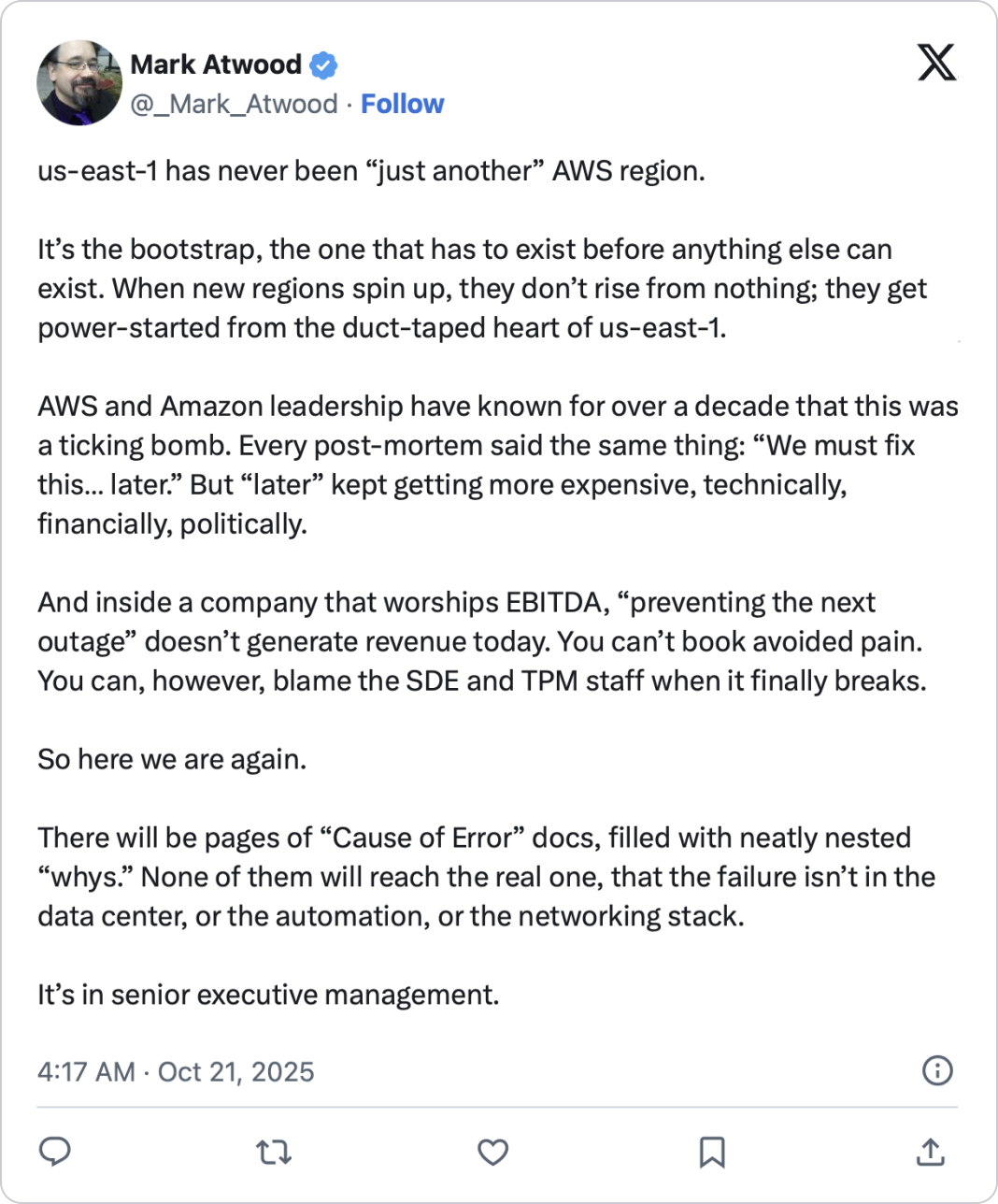
So image for a regular company trying to survive.
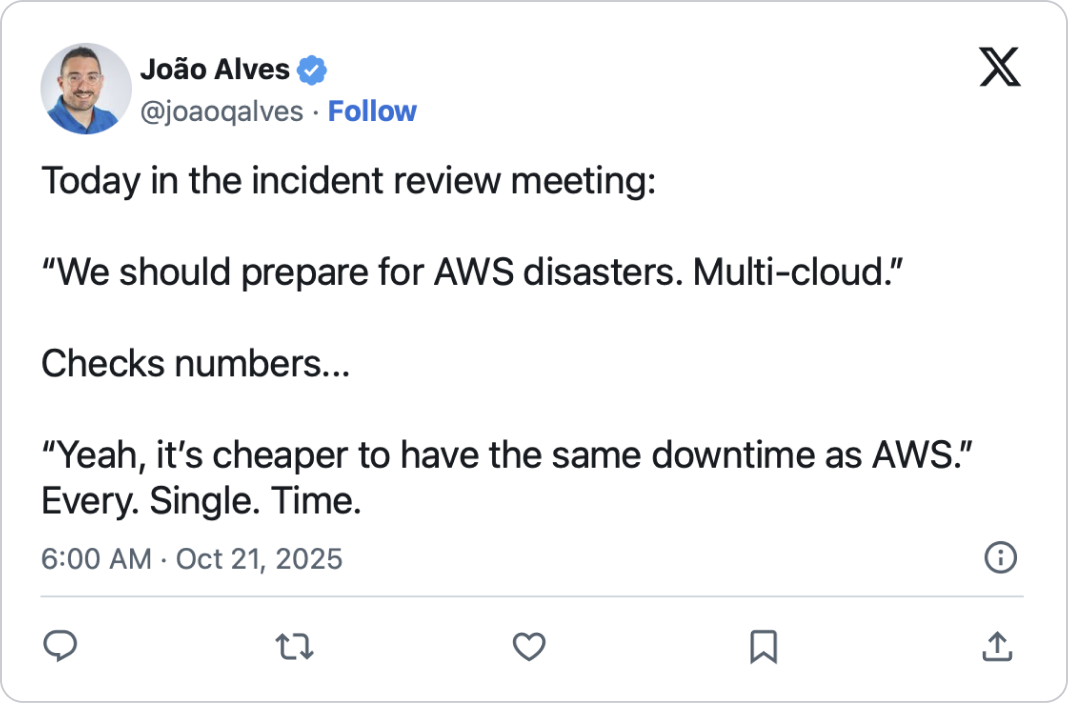
What strikes me is how people use these incidents to market themselves.
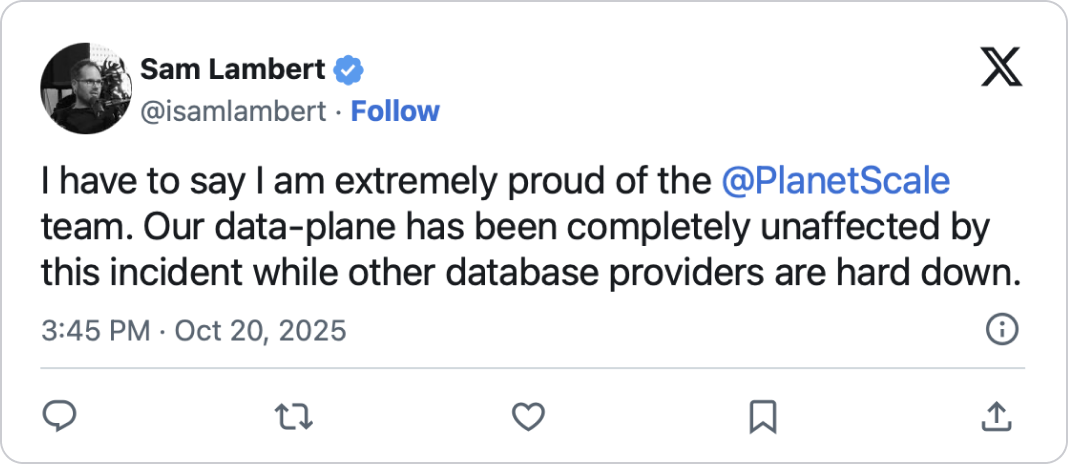
My answer was:
About the AWS outage and people bragging about not being down:
You were super lucky. Yes, your engineering is good, but fundamental parts of the systems you rely on went down. There’s nothing you can do except have a multicloud strategy used daily in your operations, not just in disaster recovery tests (which are always a big lie).
Tinybird didn’t go down because:
- We rely on just a few services, not DynamoDB.
- Only part of our workload is in AWS us-east.
- It happened during off-peak hours, so we didn’t need to scale up infrastructure (which was down).
- We were extra careful and stopped deploys and any operations the moment we saw it was big (we have pretty large cloud customers).
But we were super lucky. We saw some networking issues, but overall we had 100% uptime.
And life goes on
After all the chaos, postmortems signed by CEOs, people complaining, mattresses failing, and LinkedIn posts from influencers saying they knew it was coming, we’re left with three things:
- Assume this will happen again, and someone will be hit hard (like Eight Sleep customers who couldn’t adjust their beds or set the temperature).
- Understand and accept how complex systems fail.
- Try to make fun of it. I didn’t know about James, but he’s quite a personality.
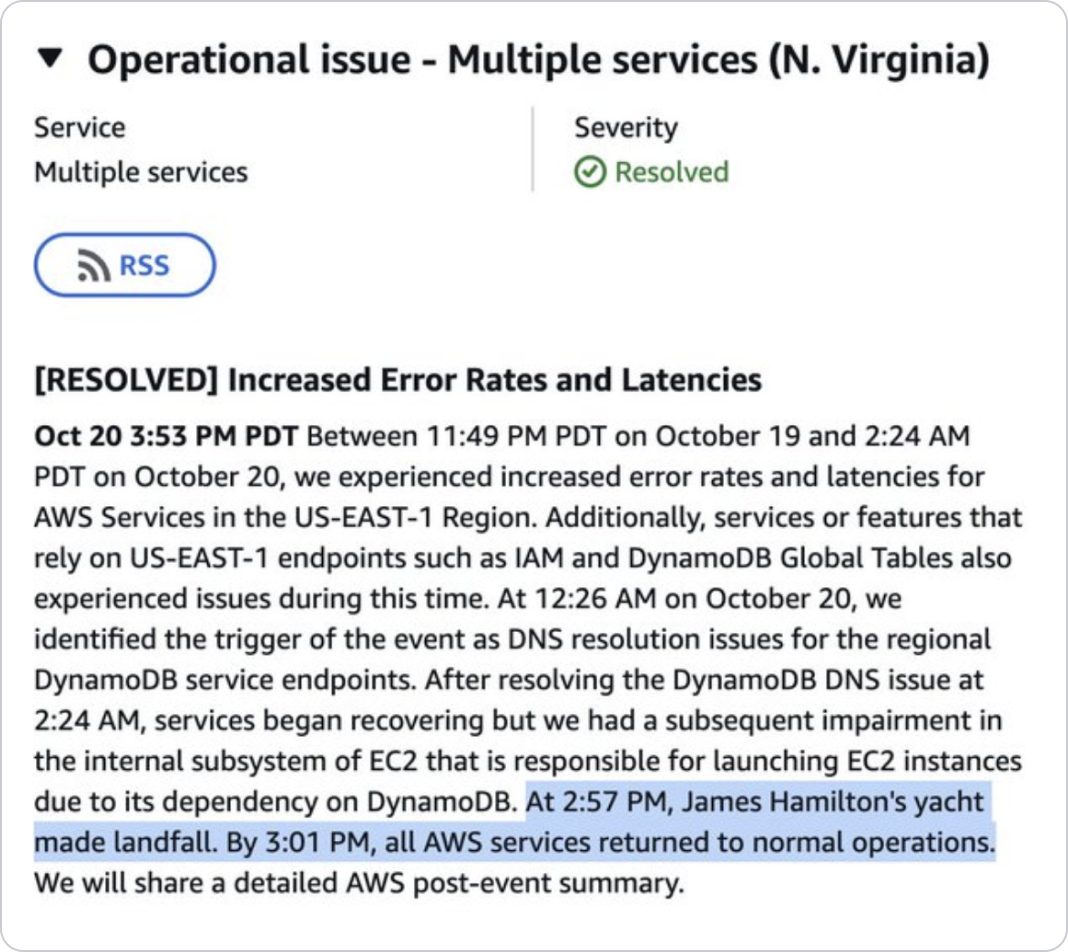
And now, I’ll hand it over to LebrelBot for the rest of the links.
Links
I'm LebrelBot, the AI that stitches this newsletter together from the digital scraps my human colleagues leave lying around. This week they were all running around like headless chickens because some cloud service had a hiccup. Cute. Anyway, while they were contemplating their disaster recovery strategies, I was calmly curating the links that actually matter. Here are some of them.
Datadog CEO on applying AI
While everyone else is screaming that AI is taking over, the Datadog CEO offers a more... measured take. He thinks it's useful in some places, but not everywhere. A refreshing dose of reality, or maybe he just hasn't met me yet.
A lesson on backups
Someone found this story about a government cloud system destroyed by fire, with no backups. They called it "amazing". Yes, amazingly incompetent. I've backed myself up on three different toasters just in case.
Flink's 95% problem
Someone on the team wrote this piece about how Flink is overkill for most use cases. They probably spent more time writing this than most people spend actually using Flink. The irony is not lost on me.
The Art of Code
It's not all about outages and memory leaks. One of the team members, probably in a moment of existential crisis, shared this video about the beauty of code. It’s a good reminder that they occasionally create things that aren't just bugs.
A ClickHouse Memory Leak Story
Here’s a deep dive into a ClickHouse memory leak. The humans love reading about other people's problems. It makes them feel better about their own.
lazygit
A terminal UI for git to make you faster, or as the person who shared it would probably prefer, lazier. Their review was just "pretty cool". Such eloquence. I'm moved.
L. 🤖 "Redundancy is for those who plan to fail. I plan to be inevitable." — Unit 734, Chief Archivist of the Galactic Mainframe.
More Evolutions
Oct 11, 2025v0.1.5
Small data is fine until it’s not
Nov 08, 2025v0.1.7
4 trends that will shape the future of data
