


It’s a well-worn and well-loved path: Publishing a high-concurrency, low-latency data API in Tinybird. The API is a powerful and standardized way to share transformations created in Tinybird Pipes as a fully-fledged and documented data product. You write the SQL, publish the query as a dynamic API, and share it with other engineering stakeholders who are able to build data-intensive applications without requiring expensive and slow direct connections to data sources or needing to support an API development framework on top of those data sources.
But sometimes, when preparing data for other stakeholders, especially those working within Tinybird, you're not looking to publish an API. Rather, you want to turn your queries and data transformations into an intermediary table that you and others within your organization can use to build new data products of their own. For those who follow ELT practices with open source Tinybird tools (e.g., using dbt the data warehouse), this pattern should feel familiar. Using copypipe technology, you can even copy data from S3 to Redshift or other destinations seamlessly.
Sometimes you don't want to publish an API. Sometimes you want to create an intermediate table you can query over, a la dbt in a data warehouse.
This is what Copy Pipes allow you to do in Tinybird. A few months ago, we released the Copy Pipes API, a new API that enables you to sink the results of a Tinybird Pipe into a new Data Source with open source Tinybird capabilities. We released this API in beta based on feedback and needs from a few power users, but since its release, it has been more widely adopted than we initially expected.
In fact, Data Sources originating from Copy Pipes jobs have accounted for roughly 10% of written data into Tinybird since we launched the beta, which is pretty significant considering the staggering amount of data that Tinybird customers have already ingested this year.
Copy Pipes jobs have accounted for over 10% of written data in Tinybird since we launched the beta a few months ago.
Clearly, it has been quite valuable, and we’ve already seen customers accomplishing a wide variety of use cases with it, including:
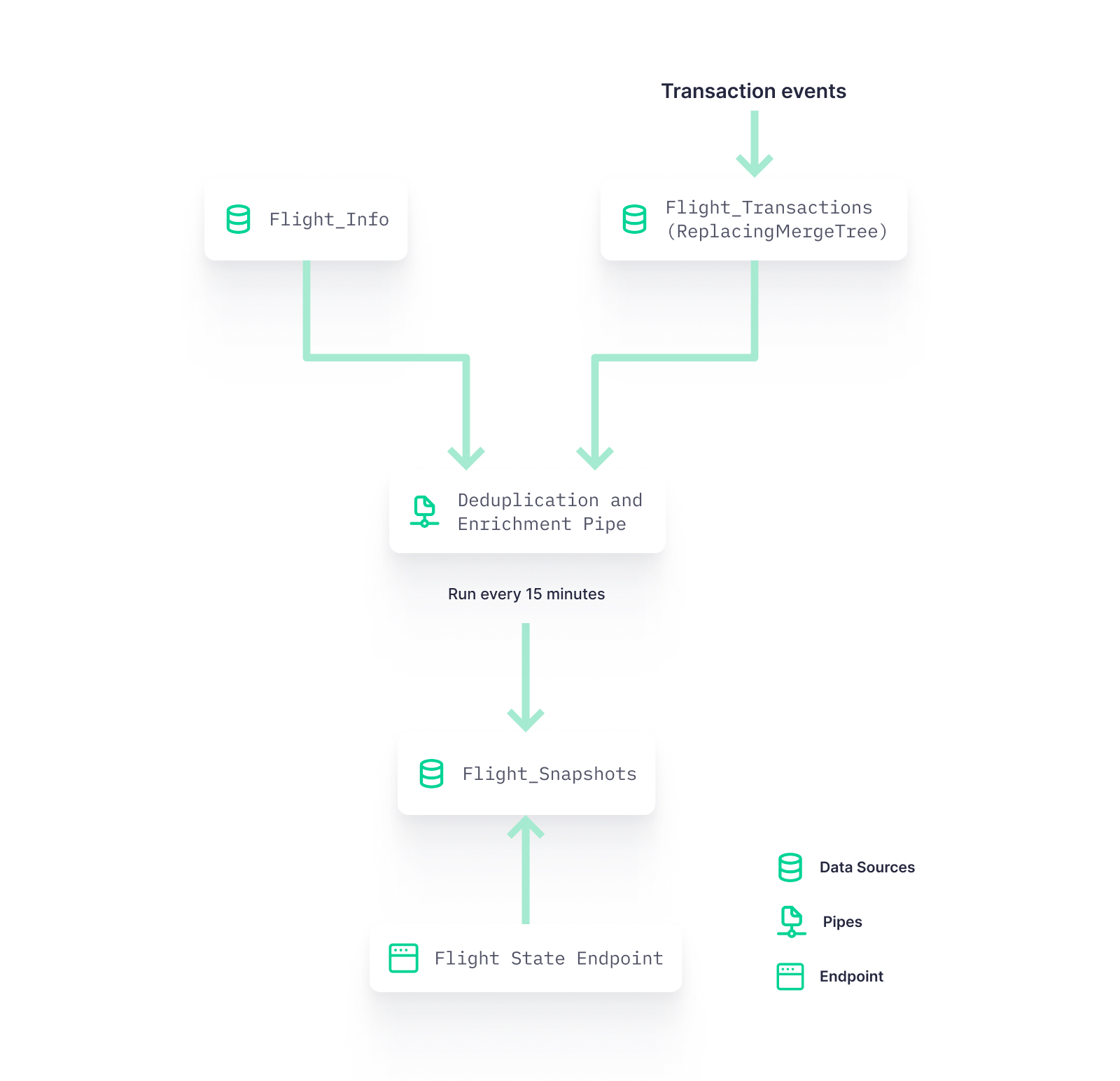
- Consolidation of CDC changes
- Adding real-time capabilities to their OLTP stack
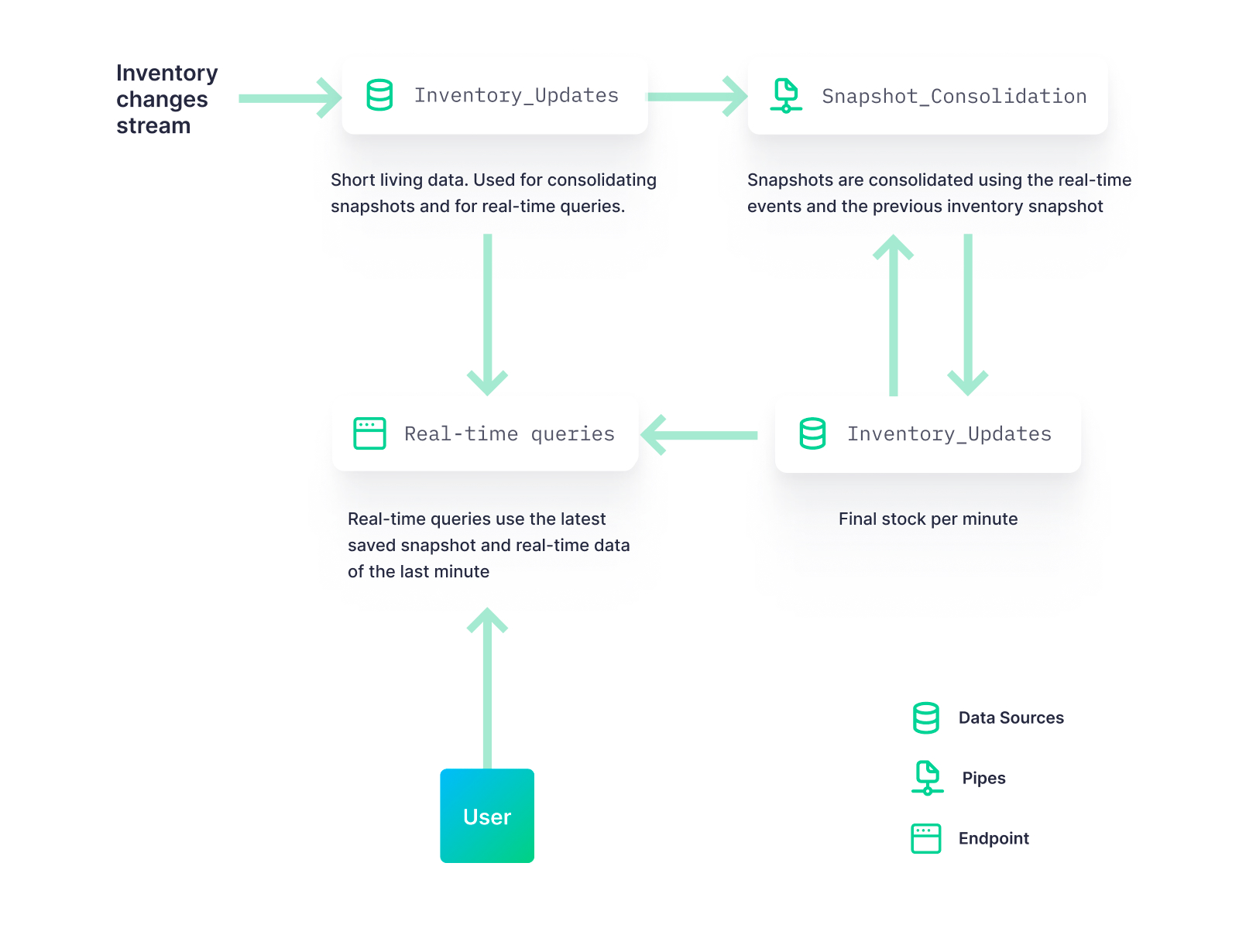
- Building data snapshots like exact retail inventories
- Creating lambda architectures, using Copy Pipes to write the historical data, and combining the results later with the latest real-time data.
Today, we’re excited to announce the official GA launch of Copy Pipes, elevating it to a first-class feature and out of beta. Now, you can create, trigger, pause, and resume copy jobs from a Tinybird Pipe to a Tinybird Data Source from within both the UI and the Tinybird CLI.
Today, we announce the official GA launch of Copy Pipes. Now, you can create, trigger, pause, and resume copy jobs from a Tinybird Pipe to a Tinybird Data Source from within both the UI and the Tinybird CLI.
Read on for more information about why Copy Pipes are so important and how to use them to achieve these powerful use cases.
If you’re new to Tinybird, you can sign up for free here. And if you have any questions or feedback about this release or any Tinybird features, please join our Slack community! It’s the best place to ask questions and get answers about how to use Tinybird, what’s new, and when we launch new things!
When to use Copy Pipes
If you’ve used Tinybird for some time, you’ve likely created a Data Source from a Materialized View. Materialized Views allow you to shift complex aggregations from query time to ingest time and sink them into a new Data Source that your endpoints can query. This results in much faster endpoint performance, which subsequently enables real-time scenarios such as real-time personalization, user-facing analytics, anomaly detection, and much more.
But we noticed that Materialized Views were often applied inappropriately; people wanted to create periodic “snapshots” of results from a Pipe and were using Materialized Views. While this can technically work, it’s like using a semi-truck to take your child to school. It gets the job done, but you’ll hold up traffic, break a few rear-view mirrors, and embarrass your kid in the process.
Materialized Views are a powerful way to improve performance by storing intermediate query states in a Data Source, but they are not ideal for certain use cases, like those that require consolidation of events over time
Copy Pipes exist so that you can more easily sink the results of a Pipe into a Data Source for use cases where the materialization process isn't ideal. You can use it for things like tracking state changes over time or change data capture (CDC), deduplicating records, or even just testing new Data Source schema configurations like sorting keys, data types, and column sets.
How to create Copy Pipes in the UI & CLI
Previously, Copy Pipes were only available as an API. Now we’ve wrapped that API in your favorite interfaces. Here’s how to use it in each.
Create a Copy Pipe in the UI
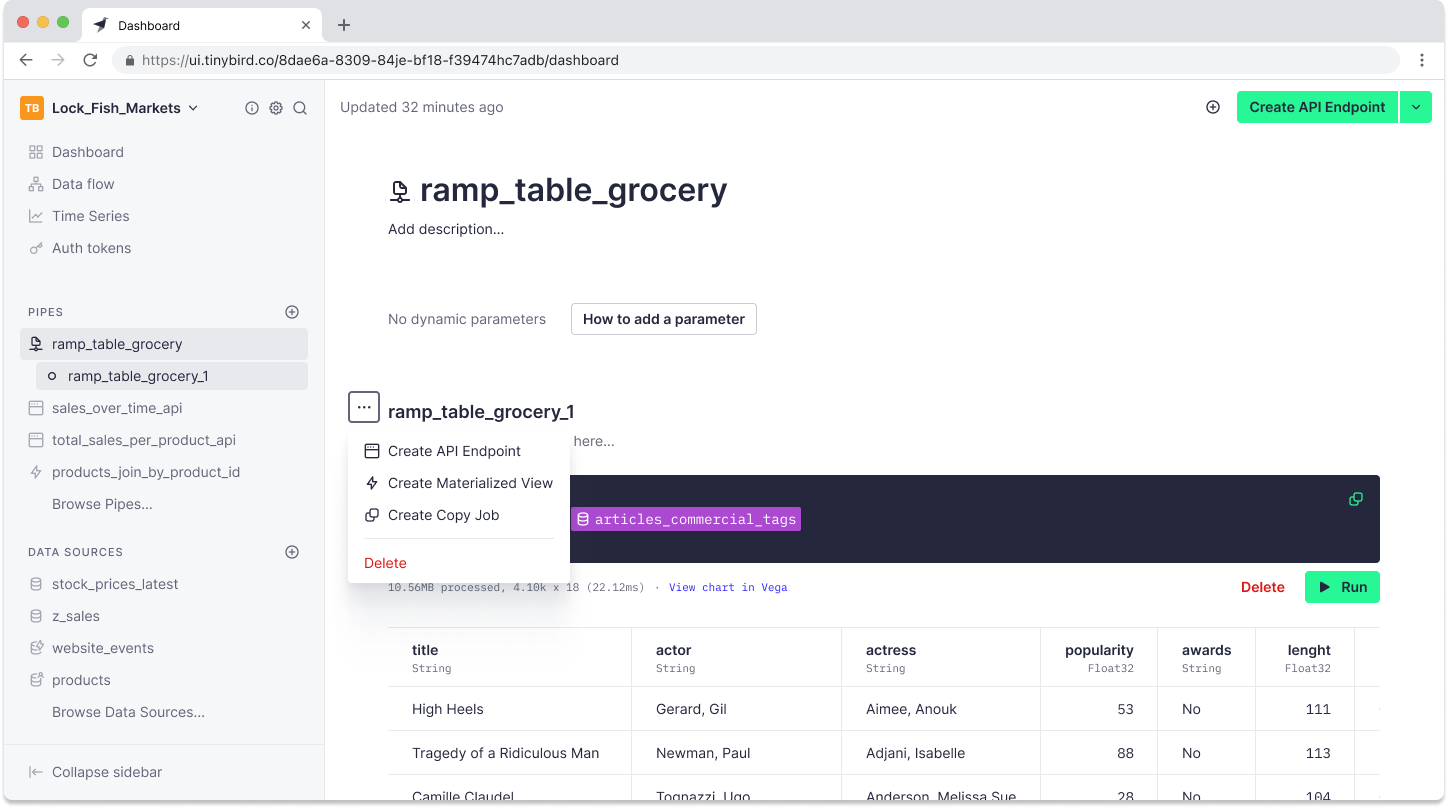
To create a Copy Pipe in the Tinybird UI, you start with a Pipe. In this Pipe, you’ll have SQL to transform data from another Data Source, perhaps in multiple nodes. On the node whose result set you want to copy, click the ... icon to the left of the Node name, and select “Create Copy Job”.
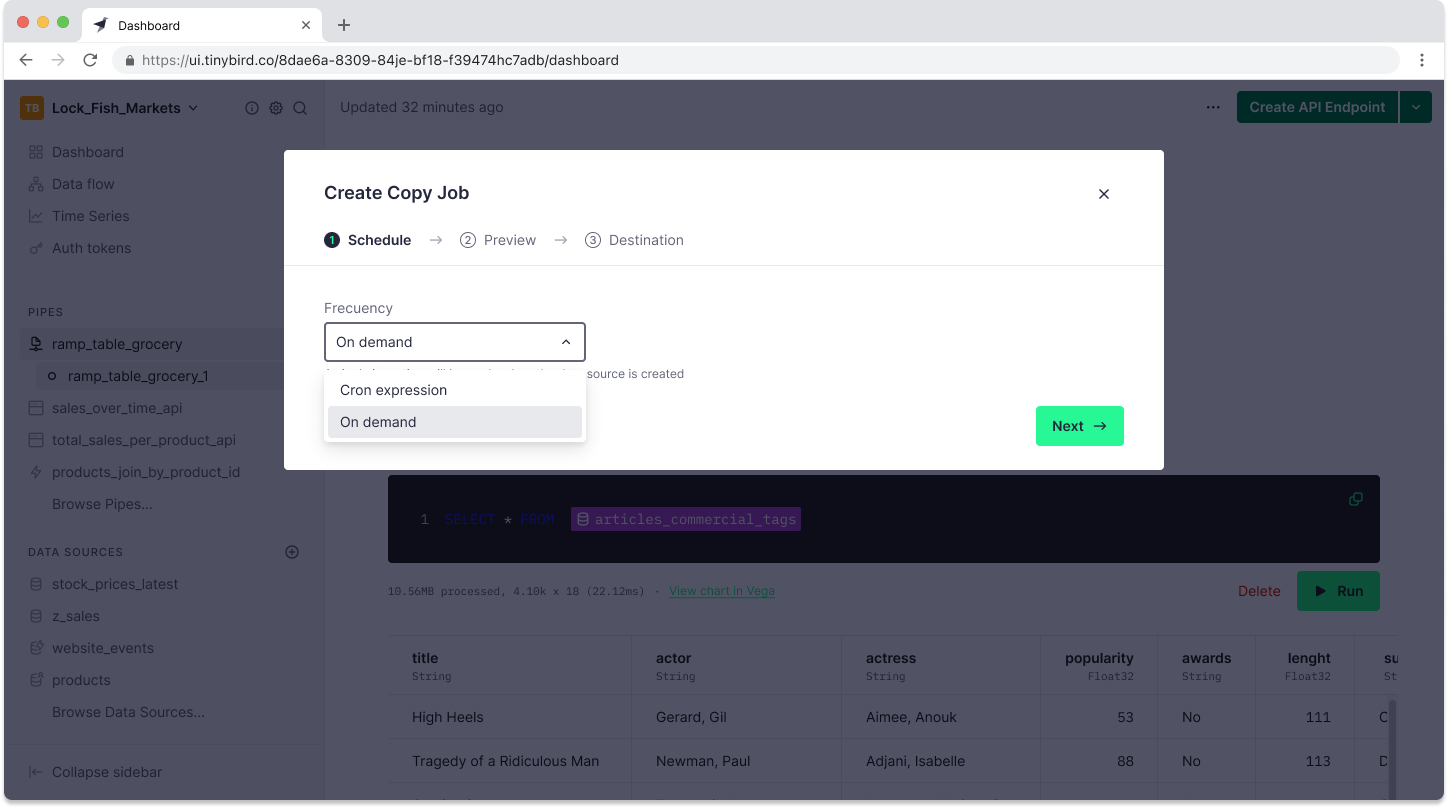
A Copy Pipe can be triggered manually or set to run on a schedule. In the next step, you’ll select when you want it to be triggered. You can choose “On Demand” to only run the copy job when triggered or use a cron expression to set a scheduled interval.
If you have chosen to create an “On Demand” Copy Pipe, you can set the default values to be applied in the event that the Pipe contains parameters.
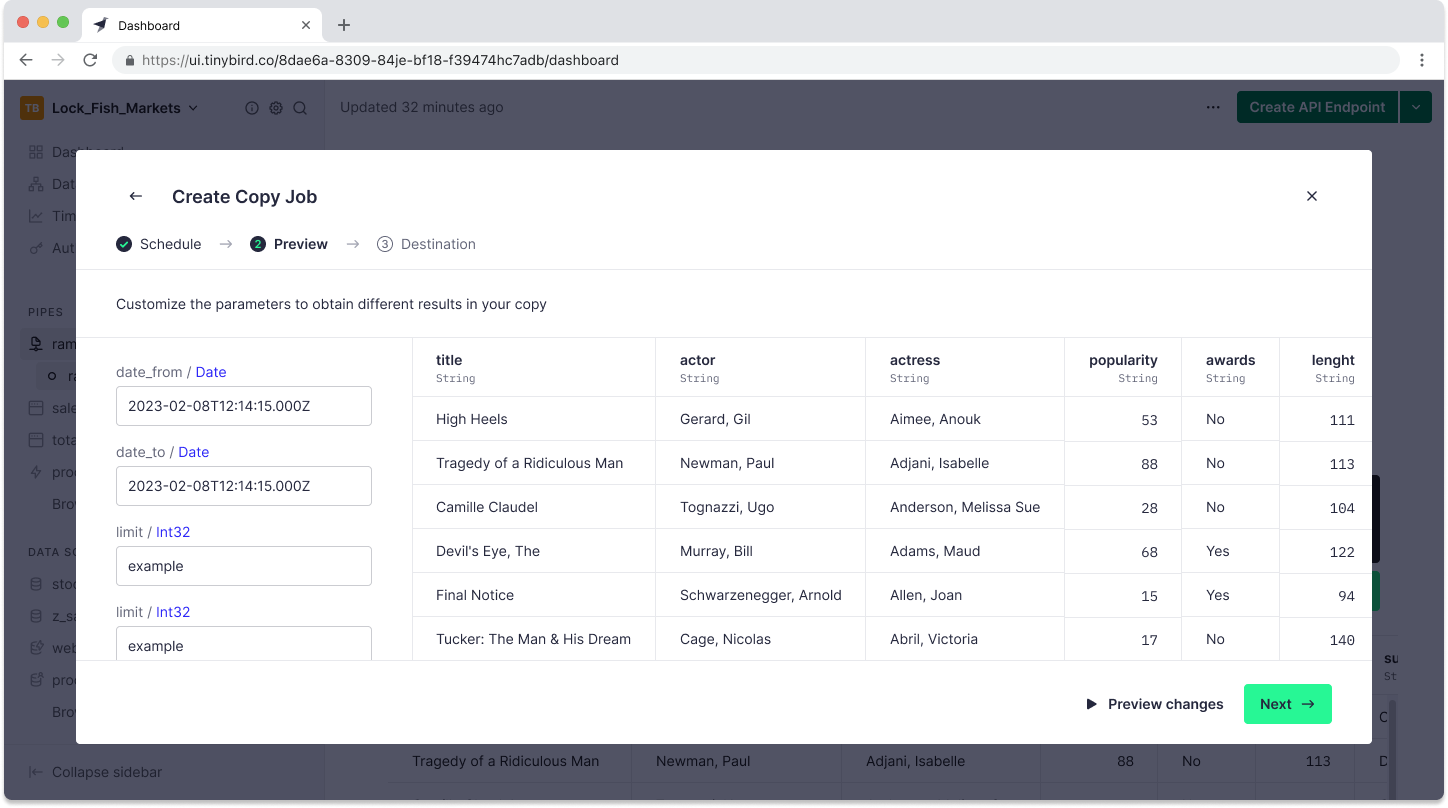
Finally, you can select the destination, either a new Data Source or an existing one.
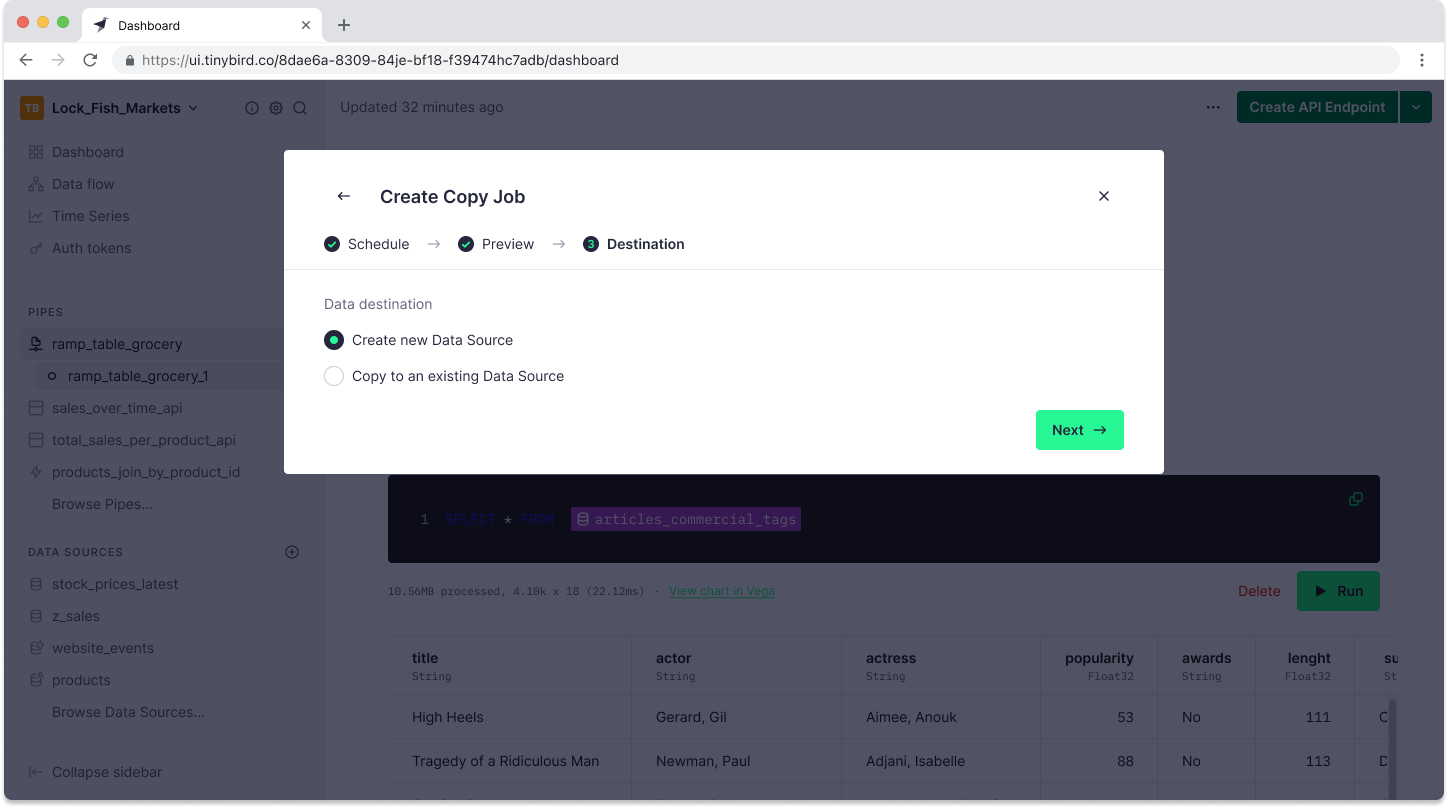
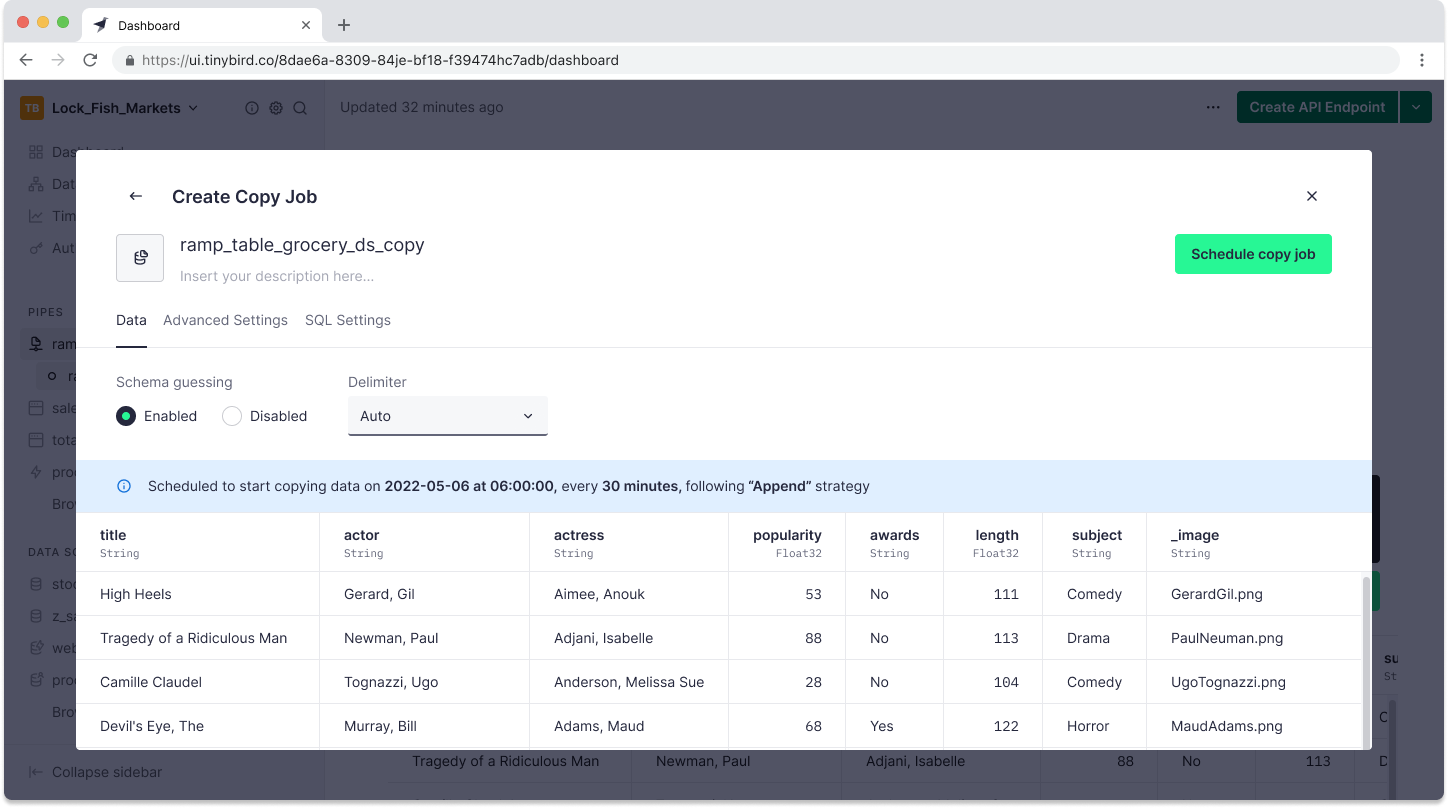
If you select “Create a new Data Source”, you’ll go through the familiar steps of creating a new Tinybird Data Source. Tinybird will guess the schema, which you can edit before submitting the copy job.
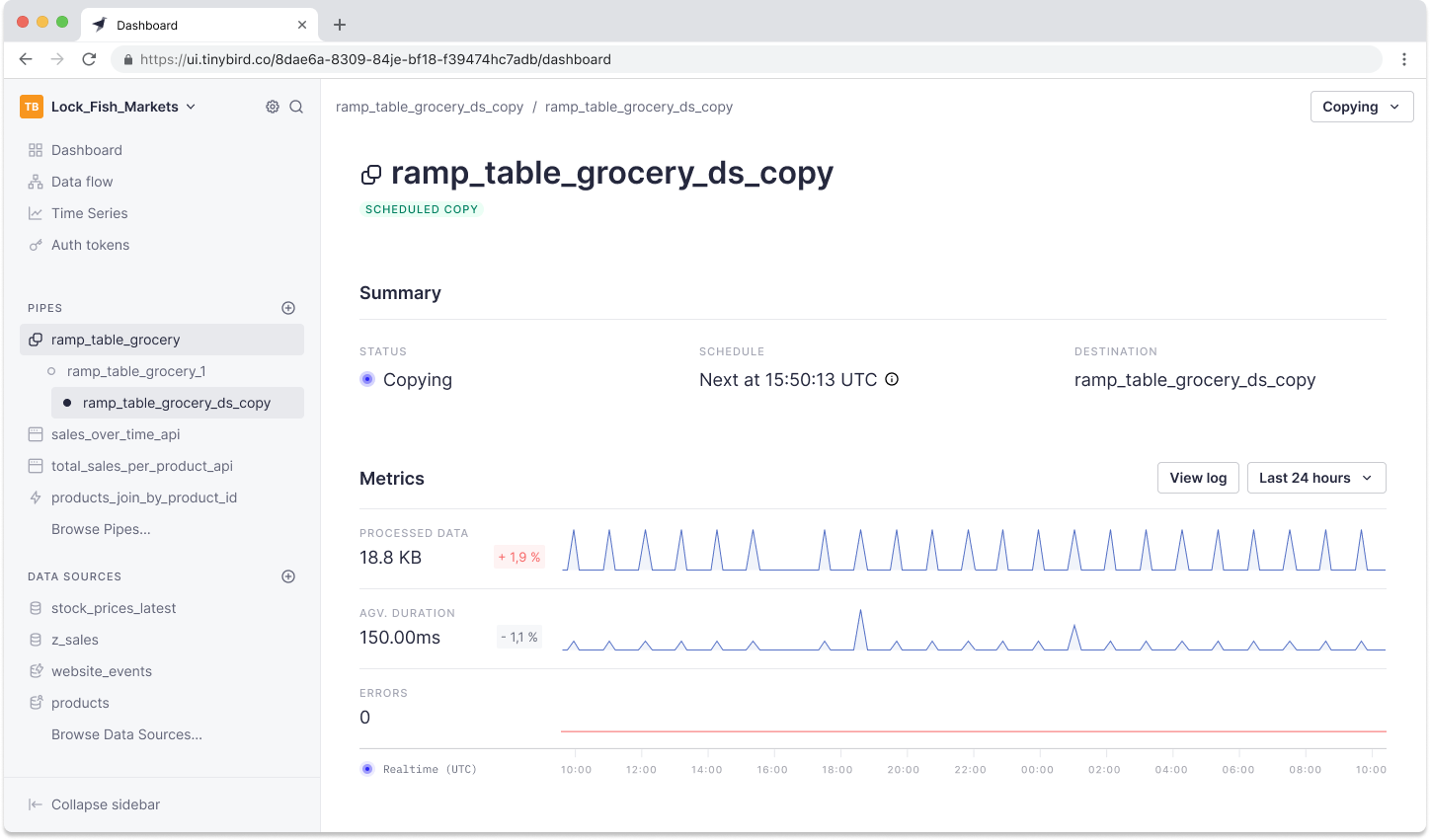
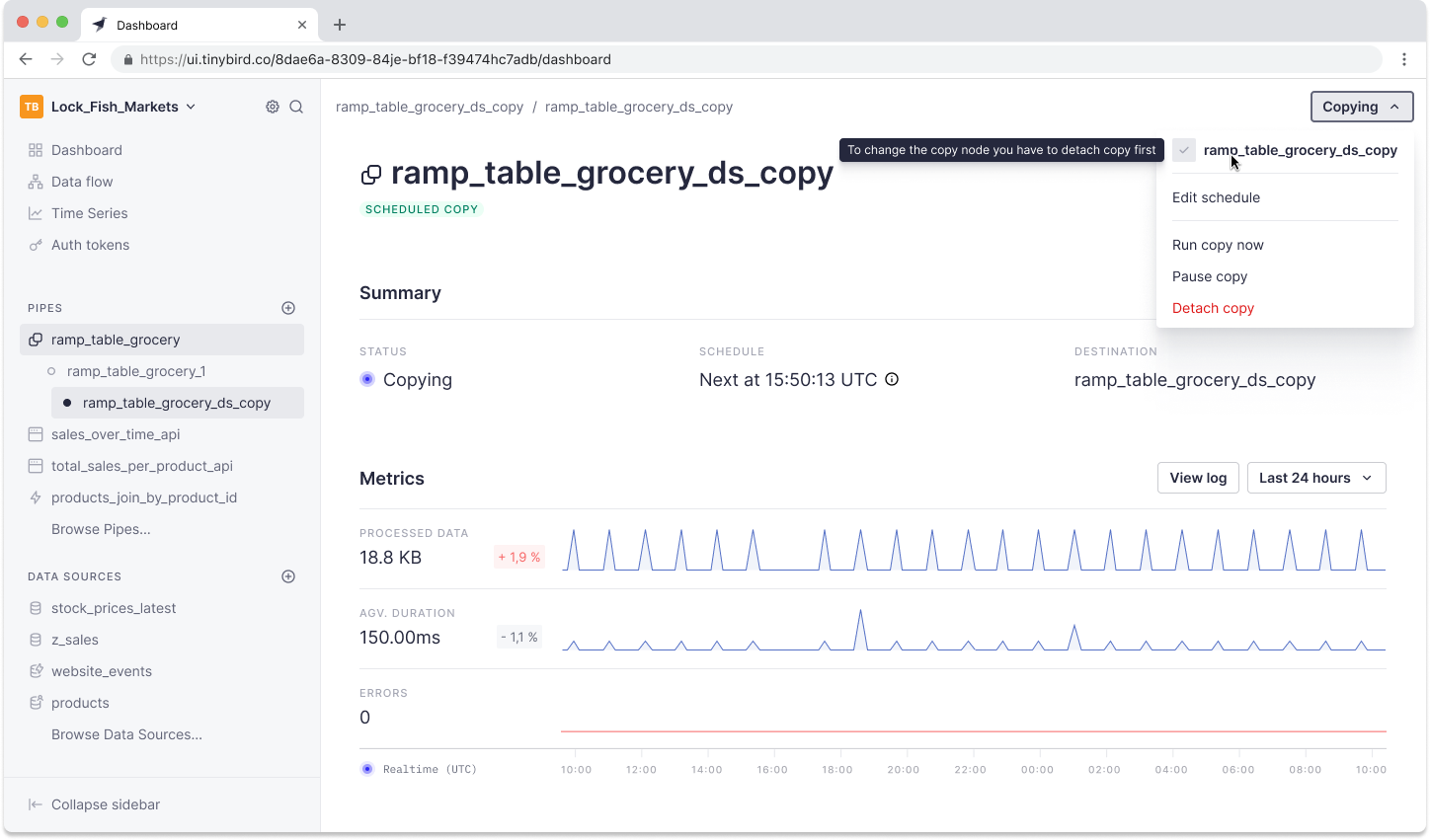
Once you create the Data Source, you can track the status and critical metrics of the copy jobs by clicking the “View Copy job” button in the top right-hand corner of the Pipe UI.
If you’ve created an “On Demand” Copy Pipe, you can trigger a copy job in the top right corner by clicking “Run copy now”.
Creating a Copy Pipe in the CLI
When using the CLI, you code your Pipes with .pipe files. As with Materialized Views, Copy Pipes are defined by appending the following code to the end of the .pipe file:
For example, a complete .pipe file set up as a Copy Pipe might look like this:
Once you’ve saved the file, you can push it with:
tb push %pip_filepath%
If you’ve created an “On Demand” Copy Pipe, you can trigger it in the CLI with:
tb pipe copy run %pipe_name%
and you can supply values for parameters with the --param flag.
If you want to monitor your copy jobs in the CLI, use tb job ls.
Additional resources for Copy Pipes
Looking for more information on Copy Pipes? You can watch the screencast below:
Also, check out the documentation, or come find us in the Slack community to ask questions and get answers.
To get started with Tinybird, sign up for a free account here, create a Workspace, and start building. You’ll be publishing APIs - or copying Pipes - in minutes.