


Tinybird now ingests more user data in a single day than it did in an entire month in the weeks and months after we pushed the first production commit. We built Tinybird for data at scale from the beginning, with beta users ingesting millions of rows at a time, but these days we’re measuring some use cases in petabytes.
Ingesting data from an external origin at high volumes so that developers can build robust use cases is already a complex engineering task. But when you add to the mix the real-time nature of what Tinybird gives you, the challenge becomes quite massive.
Still, it’s worth solving. When developers get data into Tinybird at the scale for which we designed the platform, they very quickly accomplish some incredible things. Tinybird makes it so easy to take that data and publish low-latency APIs with nothing but SQL. You can transform, aggregate, join, and otherwise enrich data streams and dimensions to unlock some new insight or build a new real-time product. And the entire process happens in minutes.
Ingestion is addictive. Once you start using Tinybird, every new use case is just one SQL query away. Many users start with a narrow scope based on a readily available dataset. But because it is so fast and easy to build something meaningful in production with Tinybird, they quickly develop an appetite for more.
Ingestion in Tinybird is addictive. Every new use case is just one SQL query away.
Tinybird users want to ingest more data from more places and combine them all to build even more powerful applications. So they ask questions like…
- Can I enrich my Kafka streams with files from Amazon S3?
- Can I join data from Redpanda and MySQL for analytics?
- How do I run real-time analytics on data in Snowflake?
- Are there simpler alternatives to Kafka?
- Does Tinybird work with Rudderstack?
Building with Tinybird all starts with ingestion, so we’re focused on answering these questions. We want it to be easy to ingest from new sources. We want to feed that appetite.
Since we got started on Tinybird, we’ve always prioritized ingestion options based on our customers' expressed needs. The first thing we did was make it super easy to ingest a CSV file. Every database can export a CSV, so this was the logical first step.
Soon thereafter, we made it effortless to connect to Kafka, delivering on the promise of streaming analytics. We also added some other basic features like JSON uploads and Parquet file ingestion.
From there, we started providing some ad-hoc solutions to support other use cases. Users would need a new way to add data, and we’d respond.
For example, we had many users who used Kafka but wanted something simpler and easier to implement across a variety of client-side libraries. Or, they didn't use Kafka and didn't want to start.
So we built the Events API. It’s high-frequency streaming ingestion over an HTTP API, so you can use it anywhere. Our customers like the flexibility and performance it gives them, as evidenced by the surge in usage over the past few months.
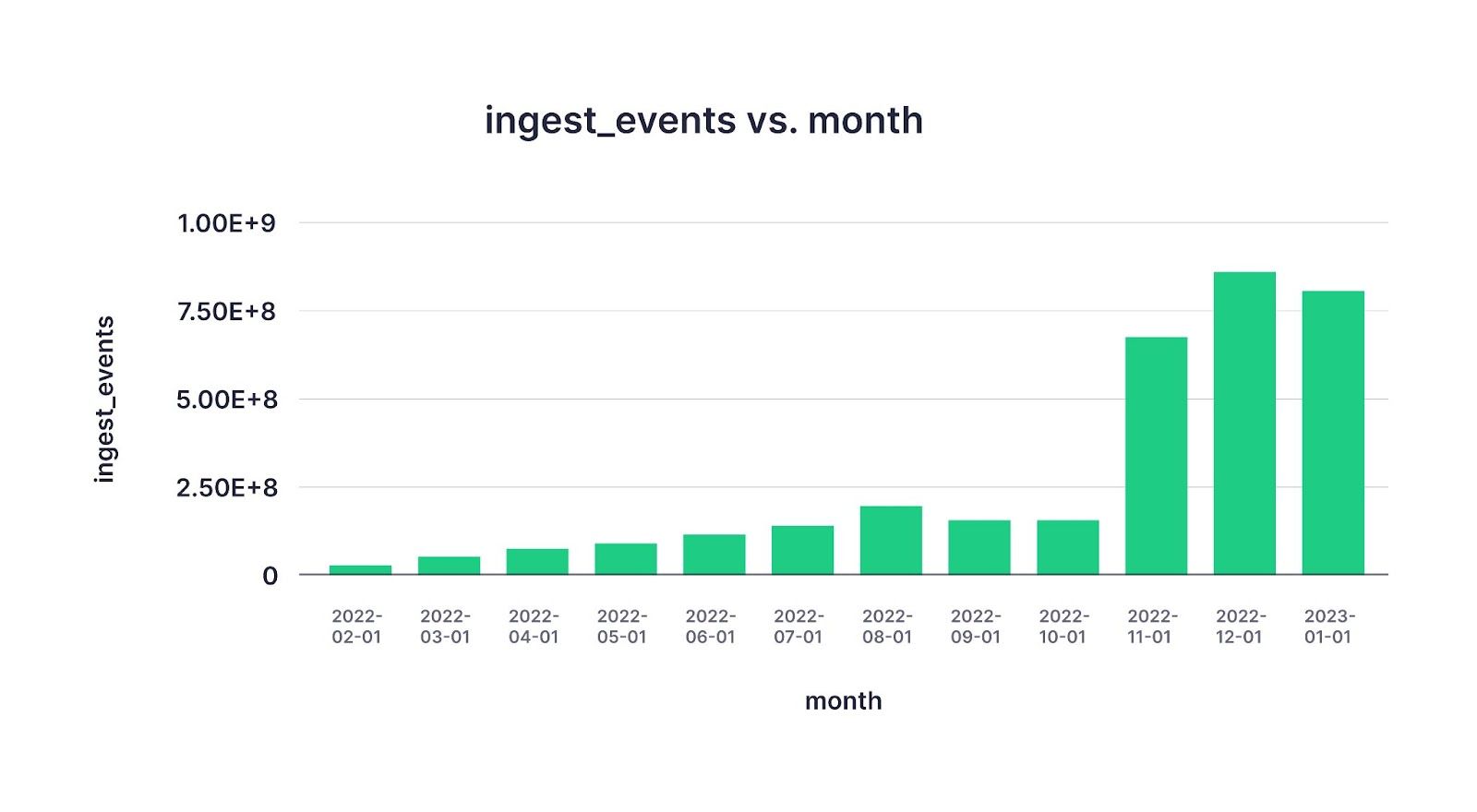
Of course, we haven’t built native connectors for everything (yet). So in the meantime, we’re helping users who need to ingest from sources we haven’t natively supported, publishing guides to document ingestion and data syncing from object storage like Amazon S3, warehouses like Snowflake, and messaging buffers like Google Pub/Sub.
But, why am I writing this and why are you reading it? Here’s the simple answer: we’re doubling down on ingestion, and we have big plans to add native support for many more external sources this year.
We’re doubling down on ingestion at Tinybird, and we have big plans to add native support for many more external sources this year.
Recently, we released a small but meaningful feature that not only capitalizes on the work we’ve already done to make ingestion more comfortable but also serves as a preview of what’s to come.
A new interface for a new paradigm
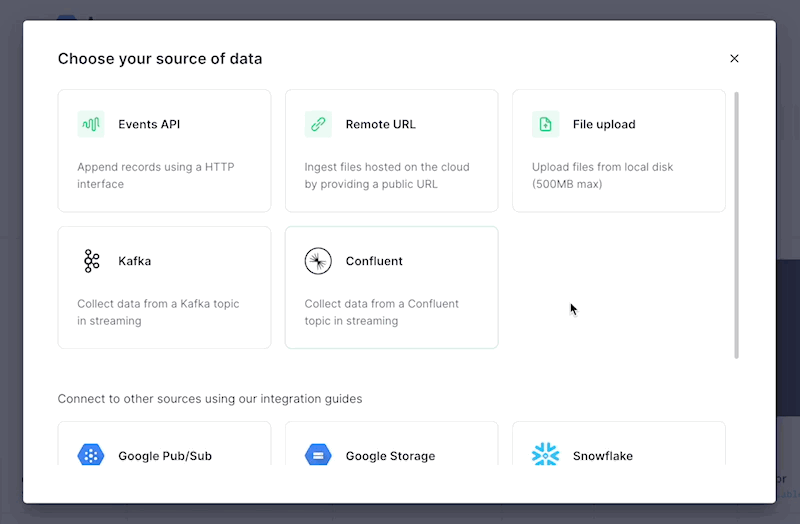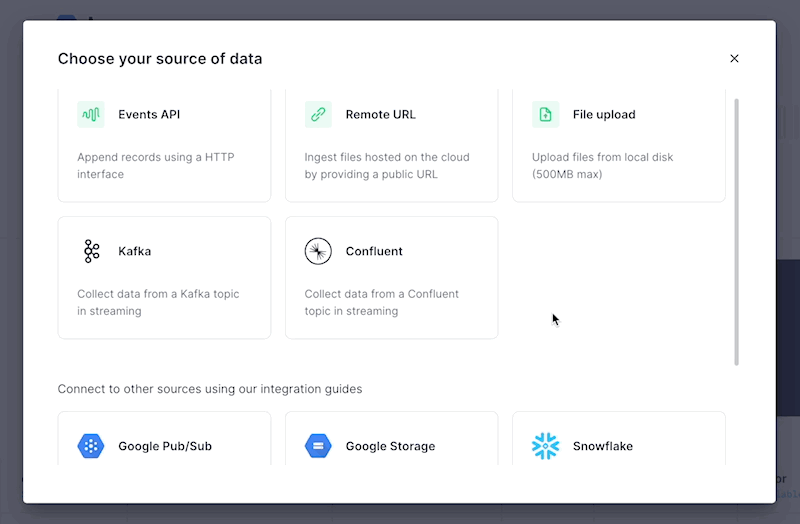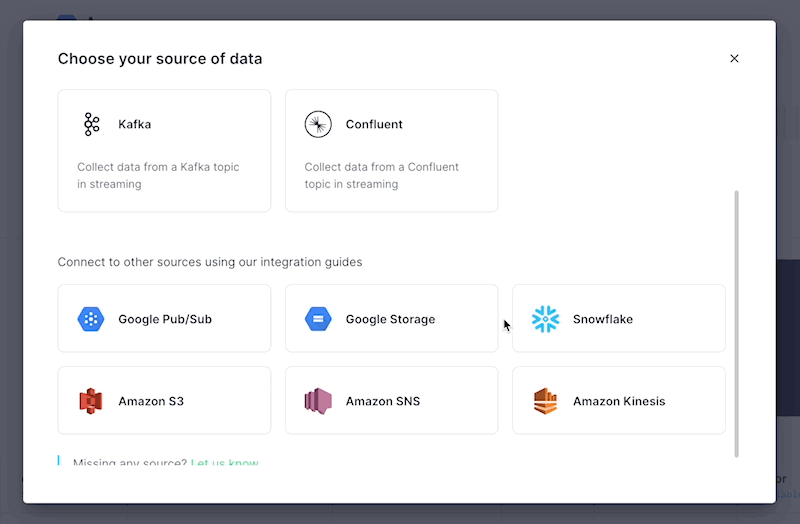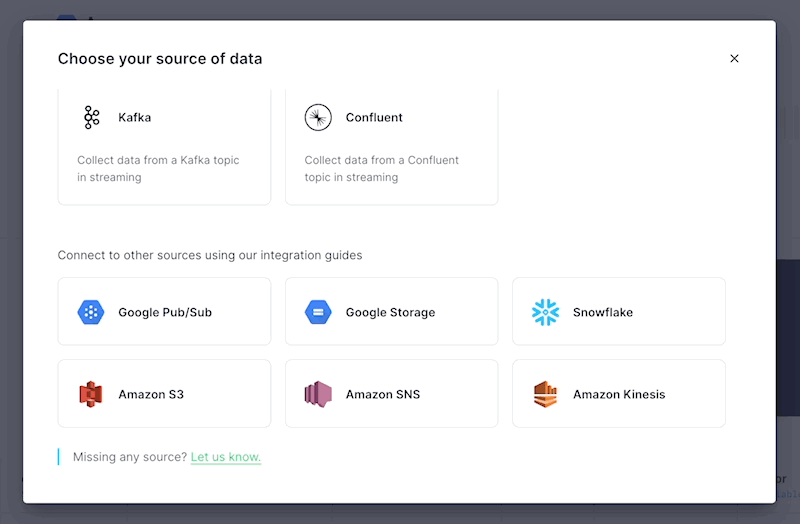
We’ve refreshed the Tinybird ingestion interface based on the new ingestion features and pathways we’ve developed in recent months.
This new ingestion UI is easier to navigate, and it includes ingestion sources that have always been available but were previously hidden in our documentation. Sources like:
- Snowflake
- Google Pub/Sub
- Google Storage
- Amazon S3
- Amazon SNS
- Amazon Kinesis
Our goal with this minor update is twofold:
- Make sure new and recurring users can quickly discover their ingestion options.
- Pave the way for the new ingestion pathways that we will release this year.
Over the coming months, we will release a series of native Connectors to the Data Sources that developers use most frequently. With just a handful of clicks or keystrokes, you can ingest your data at scale into Tinybird from even more places.
This year we plan to release a series of native Data Source connectors as well as a Connector SDK.
On top of that, we’ll release a Connector SDK so that our partners and data providers can even create integrations with Tinybird, unlocking the power of realtime for your data no matter where it’s stored.
We will never stop innovating on ingestion, and we will always provide quick and personalized support for the users that need more.
Read on for several examples of companies that have used Tinybird to combine multiple data sources to build amazing products and experiences for their customers.
Or, if you want to build you’re own fast real-time data applications, you can get started with Tinybird today. The free tier is generous, and we’re here to support you.

Kafka + Snowflake: personalized eCommerce sites
What if you could enrich eCommerce events data from Kafka with product dimensions stored in Snowflake to create real-time personalized webstore experiences for your customers?
That’s exactly what one of the largest fashion retailers in the world does with Tinybird.
Using the Tinybird native Kafka connector and the Snowflake connector, the data team at the eCommerce giant has built a real-time platform that enriches over 300 billion events sent via Kafka with data from tens of thousands of product dimensions stored in Snowflake - to serve personalized experiences to every website visitor.
These personalized experiences increase average order value (AOV) by nearly 30%, a big win for a company that generates millions of webstore sessions every day.

RedPanda + MySQL: personalized travel booking
When you book a hotel room, you want the best room at the best rate. The Hotels Network makes it possible for hoteliers to offer their website visitors just that. Using Tinybird, they’ve built services that optimize booking conversions through personalized offers for over 15,000 hotels. The Hotels Network processes 8 PB of data monthly - and growing - through Tinybird.
The Hotels Network uses Tinybird to join web events data streaming from Redpanda - ingested using the native Kafka connector - with dimensional traveler and hotel data in MySQL - sent using the Tinybird Data Sources API. They then publish low-latency APIs that power their personalization services.
On top of that, they use Retool as an internal BI tool to visualize Tinybird APIs and continually monitor the quality of their service.
Related: The Hotels Network builds real-time user personalization (video)
Rudderstack + Analytics: Matching students to tutors
Third Space Learning matches students to online tutors around the world. Demand for their services surged during COVID-19 as students were bound to kitchen tables, bedside desks, and makeshift “home classrooms”.
Before Tinybird, Third Space Learning business analysts used Looker to query their data lake and identify under-utilized tutors or unmatched students. The query latency in Looker often exceeded 20 minutes, leaving many students unmatched with tutors, and vice-versa.
Now, Third Space Learning ingests their platform events data into Tinybird using Rudderstack, and they use Tinybird to publish low-latency APIs, powering a service that automatically reassigns tutors and students when either fails to show up for an appointment.

The Tinybird Events API: a simple Kafka alternative
Vercel is one of the most-loved developer platforms. They make it delightful for frontend software engineers to develop, preview, and ship applications.
Vercel started using Tinybird to offer analytics to their users, initially using Kafka to ingest web event streams into Tinybird to publish APIs for their analytics service.
But Kafka was overkill for Vercel, so they turned to the Tinybird Events API. Every month, Tinybird processes 5+ PB of data and serves 80+ million API requests to Vercel platform users.
And thanks to the simplicity of Tinybird, Vercel has expanded its use of the Events API to build services for a web application firewall, usage-based billing, and log analytics.
Related: Vercel relies on Tinybird to help developers ship code faster
What data ingestion do you need?
Are we missing an ingestion source? Anything you’d like to add? Join the conversation in the #feedback channel in our community Slack, and let us know what you need.