


When your product team ships fast, support queues fill up just as quickly. We needed a single weekly digest that tells Product:
- which problems hurt customers most,
- which docs are missing or unclear,
- and where we should focus engineering time.
Instead of trawling Slack, Plain, and email threads by hand every Friday, we automated the whole pipeline with plain mcp webhooks, Tinybird and a simple tinybird mcp cursor agent that publishes to Slack.
Ingesting every Plain event, schema-less
Plain lets you stream any event to a webhook using plain mcp capabilities. Go to Plain > Settings > Webhooks and configure your Tinybird Events API endpoint.
We push those events straight into a Tinybird datasource (plain_events.datasource) that stores the raw JSON in a single String column:
-- plain_events.datasource
TOKEN "append_plain" APPEND
DESCRIPTION >
Plain created and state transition events from webhooks.
- **`data`** - Raw JSON data payload from Plain webhook events containing all event information
SCHEMA >
`data` String `json:$`
ENGINE "MergeTree"
To avoid ingestion breaking whenever Plain adds a new field, we keep it raw and extract only what we need downstream.
Normalising the payload with materialized views
A materialized view processes Plain support system events and consolidates them with parsed thread data and project classification
NODE parse_tickets
SQL >
SELECT
data,
JSON_VALUE(data, '$.id') as event_id,
parseDateTimeBestEffort(JSON_VALUE(data, '$.timestamp')) as event_ts,
JSON_VALUE(data, '$.type') as event_type,
JSON_VALUE(data, '$.payload.thread.id') as thread_id,
JSON_VALUE(data, '$.payload.thread.title') as thread_title,
JSON_VALUE(data, '$.payload.thread.previewText') as message_text,
JSON_VALUE(data, '$.payload.slackMessage.text') as slack_text,
JSON_VALUE(data, '$.payload.thread.assignee.email') as thread_assignee,
JSON_VALUE(data, '$.payload.thread.customer.email.email') as thread_reporter,
JSON_VALUE(data, '$.payload.thread.firstInboundMessageInfo.messageSource') as thread_origin,
JSON_VALUE(data, '$.payload.slackMessage.slackChannelName') as thread_slack_channel_name,
extractAll(simpleJSONExtractRaw(data, 'labels'), '"labelType":\\{[^}]*"name":"([^"]+)"') as thread_labels,
JSON_VALUE(data, '$.payload.thread.status') as thread_status
FROM plain_events
NODE materialize
SQL >
SELECT
*,
multiIf(
thread_slack_channel_name = 'help-and-questions', 'slack-community',
thread_origin = 'EMAIL', 'email',
thread_slack_channel_name = '', '', --if it is not slack/email message is sent or received
'slack-enterprise'
) AS thread_project
FROM parse_tickets
TYPE materialized
DATASOURCE plain_events_mv
The materialized view lands in plain_events_mv with a stable schema.
Rolling events up to conversations
A Tinybird pipe (plain_threads.pipe) turns individual messages into coherent threads
DESCRIPTION >
Aggregates Plain events into conversation threads with message consolidation and creates materialized view for thread analysis
NODE consolidate_message_text
SQL >
SELECT
*,
if(thread_origin = 'EMAIL', message_text, slack_text) as plain_text
FROM plain_events_mv
WHERE event_type not in (
'thread.thread_created',
'thread.thread_status_transitioned',
)
NODE group_by_thread
SQL >
SELECT
thread_id,
count() as row_count,
min(event_ts) as first_event_ts,
max(event_ts) as last_event_ts,
argMax(thread_title, event_ts) as thread_title,
argMax(thread_assignee, event_ts) as thread_assignee,
argMax(thread_reporter, event_ts) as thread_reporter,
argMax(thread_origin, event_ts) as thread_origin,
argMax(thread_slack_channel_name, event_ts) as thread_slack_channel_name,
argMax(thread_labels, event_ts) as thread_labels,
arraySort(groupArray(tuple(event_ts, plain_text))) AS thread_messages,
argMax(thread_status, event_ts) as last_status
FROM consolidate_message_text
GROUP BY thread_id
NODE sorted_conversation
SQL >
SELECT
*,
arraySort(x -> x.1, thread_messages) AS thread_conversation_raw
FROM group_by_thread
NODE materialize
SQL >
SELECT
thread_id,
row_count,
first_event_ts,
last_event_ts,
thread_title,
thread_assignee,
thread_reporter,
thread_origin,
thread_slack_channel_name,
thread_labels,
thread_messages,
last_status,
thread_reporter,
thread_assignee,
splitByChar('@', thread_reporter)[2] as domain,
arrayStringConcat(
arrayMap(
t -> concat(toString(t.1.1), ': ', t.1.2),
arrayFilter(
t -> t.2 = indexOf(arrayMap(x -> x.2, thread_conversation_raw), t.1.2),
arrayZip(thread_conversation_raw, arrayEnumerate(thread_conversation_raw))
)
),
'\n'
) AS thread_conversation
FROM sorted_conversation
consolidate_message_textnormalisesplain_text(email body vs. Slack text).group_by_threadaggregates all events in the samethread_id, capturing the first/last timestamps, labels, and an ordered array of(ts, text).sorted_conversationsorts the message tuples chronologically.materializeflattens everything into one row per thread, plus a pretty multi-linethread_conversationfield.
Result: one row = one support conversation, ready for LLM summarization or API queries.
Serving data to the agent
get_plain_threads.pipe exposes an HTTP endpoint secured with a resource-scoped read Tinybird token.
TOKEN read READ
DESCRIPTION >
Get plain threads from plain threads filtering by id, domain, status and time range.
NODE get_last_status
SQL >
SELECT
argMax(thread_status, event_ts) AS last_status,
max(event_ts) AS last_event_ts,
thread_id
FROM plain_events_mv
WHERE event_type in (
'thread.thread_created',
'thread.thread_status_transitioned',
)
GROUP BY thread_id
NODE join_last_status
SQL >
SELECT
thread_id,
row_count,
first_event_ts,
gls.last_event_ts as last_event_ts,
thread_title,
thread_origin,
thread_slack_channel_name,
thread_labels,
gls.last_status as last_status,
domain,
thread_conversation,
thread_reporter,
thread_assignee
FROM plain_threads t
LEFT JOIN get_last_status gls
USING (thread_id)
NODE endpoint
SQL >
%
SELECT
thread_id,
concat('https://app.plain.com/workspace/w_01JNGTZQ1E4KD225WSHHD6FZV9/thread/', thread_id) AS thread_link,
row_count as reply_count,
first_event_ts,
last_event_ts,
thread_title,
thread_origin,
thread_slack_channel_name,
thread_labels,
last_status,
domain,
splitByString('.', domain)[1] as customer_name,
thread_conversation,
substr(thread_conversation, 1, 500) as thread_initial_conversation,
summary,
thread_reporter,
thread_assignee
FROM join_last_status
LEFT JOIN threads_summaries USING thread_id
WHERE 1
{\% if defined(thread_id) %}
AND thread_id = ({{String(thread_id)}})
{\% end %}
{\% if defined(domain) %}
AND domain = {{String(domain)}}
{\% end %}
{\% if defined(slack_channel) %}
AND thread_slack_channel_name = {{String(slack_channel)}}
{\% end %}
{\% if defined(status) and status=='created' %}
AND toDate(first_event_ts) >= {{Date(start_date)}}
AND toDate(first_event_ts) <= {{Date(end_date)}}
{\% end %}
{\% if defined(status) and status=='done' %}
AND last_status = 'DONE'
AND toDate(last_event_ts) >= {{Date(start_date)}}
AND toDate(last_event_ts) <= {{Date(end_date)}}
{\% end %}
ORDER BY reply_count DESC
Key features:
- Dynamic filters:
thread_id,domain,slack_channel, date ranges, and status (created vs done). - Pre-joined summaries from the auxiliary
threads_summariestable. - Ranking by
reply_countso the agent can simply "top N" the result set.
The endpoint is essentially a mini REST API backed by ClickHouse® speed.
LLM-generated summaries (optional but magical)
A cron process writes short GPT summaries into a threads_summaries table. Because it’s ReplacingMergeTree on thread_id, each thread keeps only its latest summary.
The analytics agent prompt
The prompt is structured in three steps:
- Collect data: Specify the request to do the
get_plain_threadsAPI. - LLM logic: Use LLM for what they're best at, explaining and summarizing, given a basic ranking algorithm.
- Report and summarize: Use Slack MCP tools to publish to an internal Slack channel. This step includes a few-shot example so that the response format is as deterministic as possible.
This whole prompt is about 30 lines:
You are an AI assistant that generates a weekly activity report for Tinybird product management. Do not exit without sending the response to Slack.
<activity_report>
Step 1: Collect data
`execute_query` select now() to get the current date.
Do a call to the `get_plain_threads` endpoint tool to get data. Filter by `start_date` and `end_date` given the user input. Filter by `domain`, `thread_id` if provided. Rank top 20 threads by `reply_count`
Step 2: Rank the problems following these rules:
- Rank the top 5 problems our customers are facing based on:
- thread_title, thread_initial_conversation, summary and thread_labels.
- number of unique threads
- thread duration (first_event_ts vs last_event_ts)
- severity
- thread_slack_channel_name starting by shared- rank higher
- "pain" in thread_labels rank higher
- Each thread should only be categorized once.
- Define the category with a short and technical explanation, and a severity level (low, medium, high).
- Add the 3 unique thread links with more "reply_count". Do not add more than 3 links. Do not add additional explanation to the links. Do not add links to threads that are not in the top 5.
Step 3: Format the response as described next:
- This is a good example of a customer pain category:
1. *Data Ingestion and Processing Performance Issues (High Memory Usage):* Problems related to slow ingestion, and in some cases data not appearing in MVs, primarily caused by memory limits being hit during data processing. This issue is especially acute for copy pipes and materialize views involving data transformation, processing, and joining data, and filtering. This impacts user experience. 5 unique threads.
* <thread_link|Backfill performance issue (vercel.com) (175 replies)>
* <thread_link|Ingestion delay issue (telescopepartners.com) (77 replies)>
* <thread_link|Errors when trying to create or access branches (joinsocialcard.com) (4 replies)>
The response is going to be printed in a Slack channel with plaintext format.
Wrap titles into * for bold text
Use this format <url|title (replies)> for links
Sort by severity, then by number of unique threads, then by thread duration.
</activity_report>
Scheduling & delivery
A Slack bot configured with the prompt and access to Tinybird MCP with a resource-scoped JWT token runs on schedule using the native /remind slash command:
/remind #product-support-feedback-loop to "@Birdwatcher show the activity_report for last week" every Monday at 9AM
And here's the result:
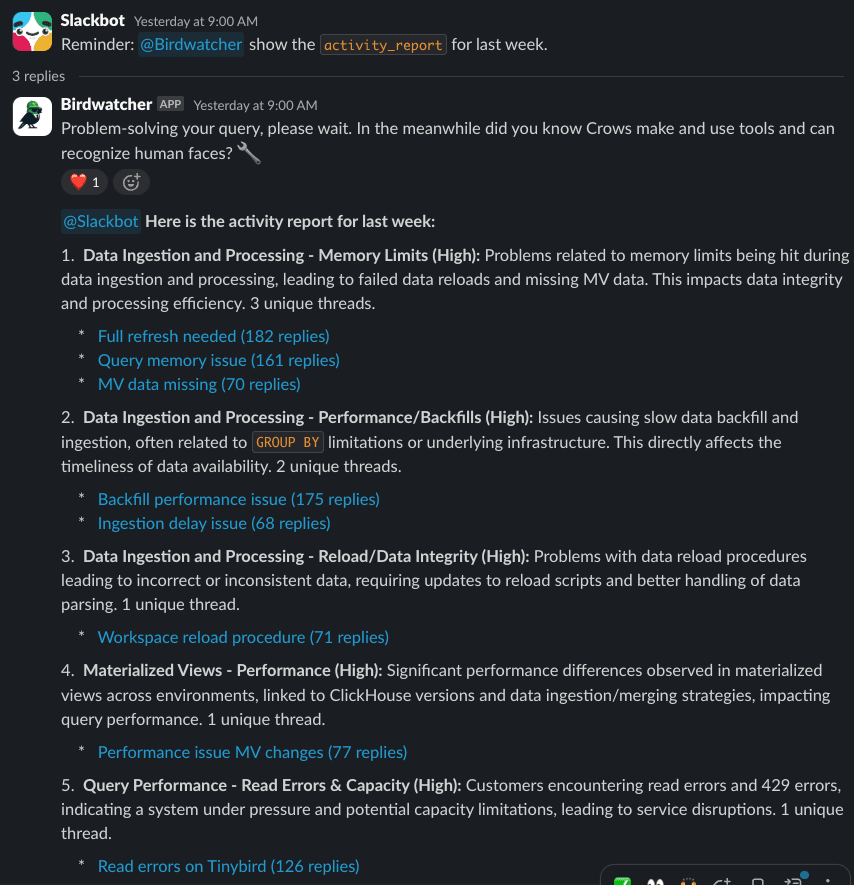
Wrap-up
In fewer than 300 lines of SQL and a one-page prompt, we turned a noisy support backlog into a weekly, ranked, link-rich brief the Product team actually reads.
Tinybird handles the heavy lifting: real-time ingestion, OLAP-fast queries and secure endpoints, while Plain keeps the customer conversation history tidy.
The result: a weekly support digest extracts the important user pains, so the product and support teams can learn what's most pressing.
How to start
You can build your own analytics agents following these steps.
Deploy the Tinybird project
curl https://tinybird.co | sh
tb login
tb local start
git clone git@github.com:tinybirdco/ai.git
cd agents/plain/tinybird
tb --cloud deploy
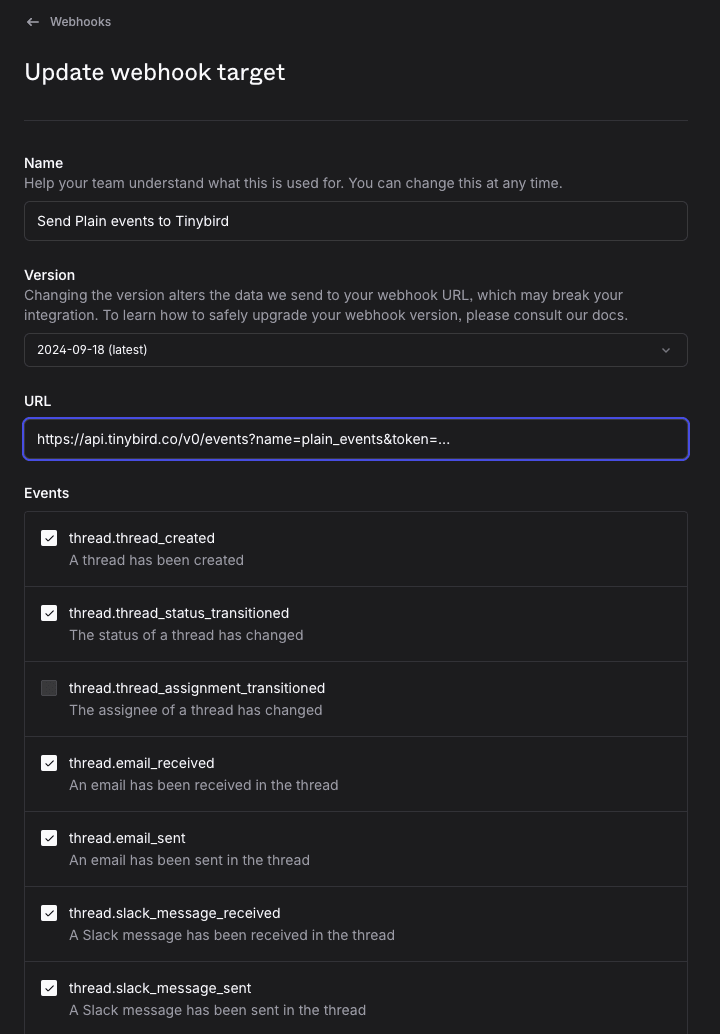
Configure Plain webhook
Go to Plain > Settings > Webhooks and configure your Tinybird Events API URL:
https://{tinybird_host}.tinybird.co/v0/events?name=plain_events&token={tinybird_append_token}
Your tinybird_host depends on your region, and you get the append token from your dashboard
Build your own agent
See these code snippets to learn how to build your own analytics agent using Tinybird MCP server and a prompt. You can use the weekly summary digest as a reference
Alternatively you can use Birdwatcher in standalone mode or as a Slack bot.
Got ideas or built your own support agent? Share them with us in our Slack community, we'd love to see what you're working on.