


This is a story about one of the largest eCommerce retailers in the world, and how they built an alternative to Google Analytics. This particular retailer is based in the US but operates in hundreds of markets worldwide, with thousands of physical stores and an eCommerce website that garners more than 10 million daily sessions. Their website produces more than a terabyte of web events data every single day, driving annual revenues in the tens of billions of dollars.
But don’t let their size fool you. They had problems with analytical scalability just like everyone else. They leaned very heavily on Google Analytics to give them insight into how their online business performed, and, put simply, it was letting them down in some of the areas they cared about most.
A few years ago, they decided to do something about it. Here’s how they built a new, lightweight real-time architecture to take web analytics into their own hands.
Related: A privacy-first approach to building your own Google Analytics
Problems with privacy, completeness, freshness
Like many companies across the globe, the legal team at this retailer was worried about emerging e-privacy legislation and whether it would force their analytics teams to stop using Google Analytics altogether. But beyond the legal concerns, the analysts and data engineers continued to be frustrated by some of the blatant hindrances posed by Google Analytics. At this company’s size, even with Google’s premium Analytics 360 product, the analysts faced the following specific problems:
- Data wasn’t fresh. Google Analytics can make you wait 36 hours or more for web events data collected by its tracker to consolidate in BigQuery for analysis. For a company that often runs single-day sales, that’s particularly limiting.
- Data wasn’t complete. Ad-blockers and non-consent of cookies significantly reduce the amount of traffic that Google Analytics users can legally process. Additionally, Google Analytics’ data sampling policies can hinder larger analytical queries. Both these things make analysts question the veracity of the insights they’re served.
- Data was out of their control. Google Analytics places constraints not only on data flow and attribution models but also on how and where data is stored. Seeing as several European countries have outlawed Google Analytics (and others will likely follow), this was a prescient concern.
As their analysts and engineers saw it, the retail giant had three choices:
1. Keep using Google Analytics
They could simply live with the sampling and latency issues and just kick the legality can down the road. But based on how the legislation and subsequent rulings are shaping up, the probability of fines seemed like a real threat.
2. Use another third-party product
There are some more privacy-oriented products on the market such as Fathom and Plausible that might have helped them overcome the legal concerns. But these alternatives didn’t provide the metrics that they needed, weren’t designed to scale to their size, and weren’t particularly extensible to the use cases they anticipated.
3. Build a first-party tracker and analytics platform
The most flexible alternative was to just build a GDPR-compliant first-party tracker to feed web events into their own data infra. While this seemed the most burdensome option upfront, the first-party option offered some distinct advantages:
- They could use first-party cookies to identify randomized, anonymous sessions without asking for consent, so they could capture 100% of traffic while ensuring visitor privacy.
- They would have full control over what they tracked, processed, and stored to further ensure data privacy.
- It would be easier to extend to current and future use cases.
- With the right architecture, they could solve massive use cases requiring real-time analytics.
They decided to go with Option 3. Here’s how they did it:
How the retail giant built a Google Analytics alternative
When the company set out to overcome the issues with its current setup by building its own platform, its engineers approached the problem with compliance and scalability top of mind, keeping it as lightweight and anonymous as possible.
They decided to track just 3 events:
- Page Views
- Items Added to Cart
- Transaction
These were all they needed to achieve their initial use cases, and they figured they could always extend the tracking code in the future if needed.
Here’s the basic architecture they ended up building:
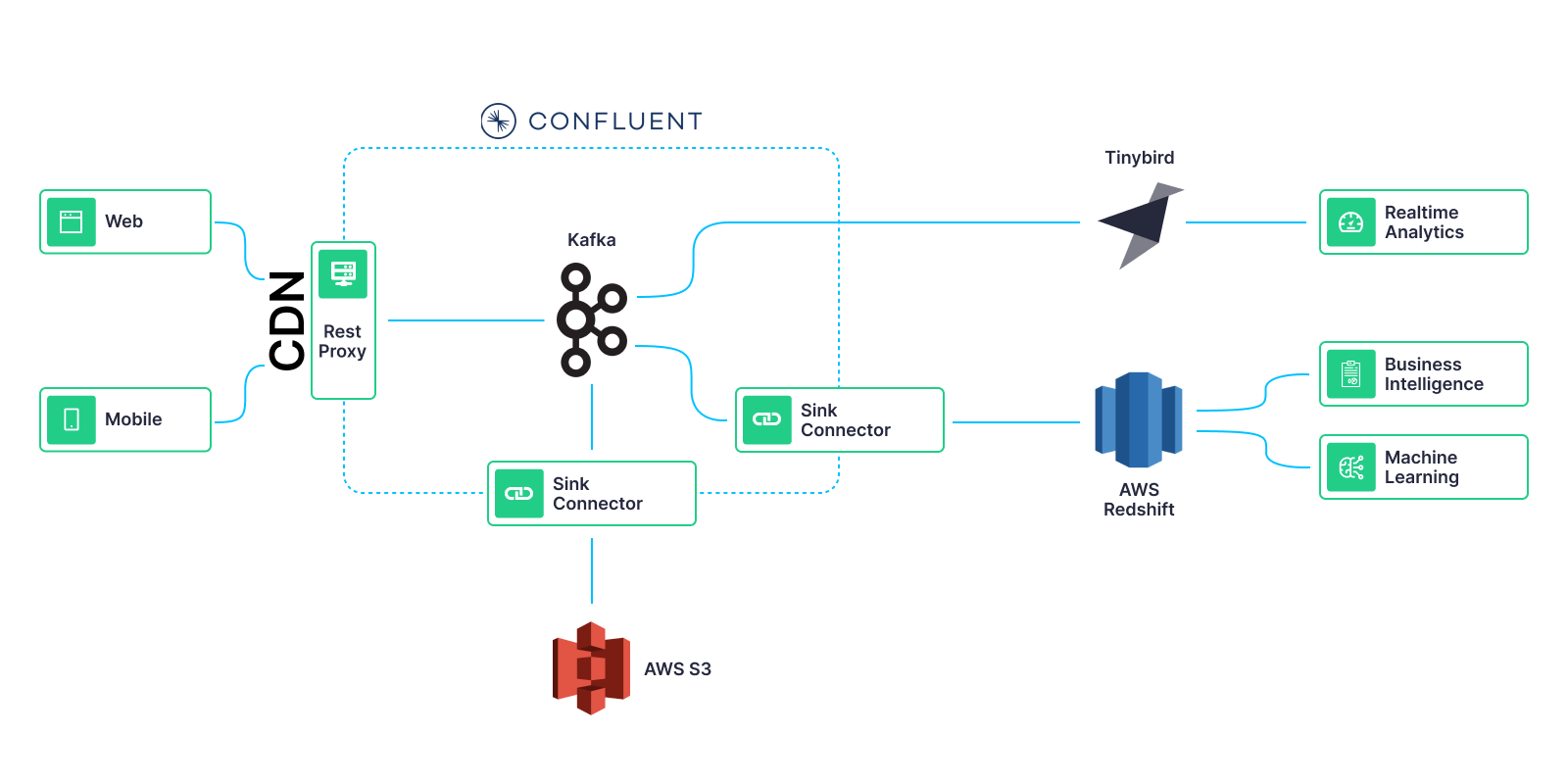
A few constraints helped guide their approach:
- They needed all session metrics to be captured using only first-party session cookies set on their domain. This was critical for GDPR compliance without cookie consent.
- They wanted to be able to forward session metrics to different applications based on the use cases they needed to solve.
Kafka for event streaming
To solve constraint #2, they decided to go with Kafka. The pub/sub streaming architecture served their need to send events on to multiple sinks, and they liked the abstraction, scalability, and reliability offered by Kafka.
They used Confluent Cloud to host their Kafka cluster, and provisioned it with the proper dimensions to support their immense traffic load.
But, the engineers recognized that it wouldn’t work to have the clients generate Kafka messages directly to the broker. Not only would it introduce more dependencies and add overhead, but it also wouldn’t allow them to set cookies on their own domain, violating constraint #1.
CDN and a REST Proxy
So, rather than sending Kafka messages directly from the browser and mobile apps, they sent them as HTTP POST requests to their CDN, where the cookie logic was implemented. Then, on the CDN, they configured redirects to send the requests along to a REST proxy, this open-source solution provided by Confluent, that would transform the requests into Kafka messages.
Note that Kafka is a great message broker, but it’s not built for analytical workloads. It doesn’t provide enough to extract all the value from the data.
Fortunately, Confluent Cloud allowed them to quickly set up several sink connectors to send data to other platforms that would allow them to do the analysis they needed.
In particular, they set up the following:
- AWS S3 as a cheap backup that saved compressed CSVs with the raw information.
- Redshift for large analytical queries and ad-hoc analysis where they didn’t have tight real-time constraints, such as ML workflows and BI tools.
- Tinybird for real-time use cases.
Extra measures for GDPR compliance
To follow the guidance on best practices for complying with GDPR when using first-party cookies, the retailer also chose to do the following:
- Never track user IDs, order IDs, or anything that could be considered PII or could allow us to trace activity back to a single individual.
- Keep everything anonymous and use randomized session IDs generated on the CDN to avoid any kind of fingerprinting.
- Implement only the use cases they could justify as “observability to guarantee the platform works as intended.”
- Always aggregate metrics. Never process or expose data at the user, item, or order level with associated IDs.
- Provide an opt-out option for the visitor.
- Keep the raw data for the shortest time possible, up to a few months.
- Use a first-party session cookie set by their domain.
- Never let third-party services see or analyze the data.
The engineers working on the project forced themselves to keep it minimal so that they could be confident in the privacy and legality of what they built. They weren’t trying to build all the functions of Google Analytics, only the ones they needed to support the use cases that Google Analytics could not fulfill without third-party cookies, in real time, and with 100% of the data.
Identifying sessions in a privacy-first manner
To identify sessions, the retailer’s eCommerce clients use a first-party cookie with a random session ID. These are categorized as functionality cookies - which means explicit consent is not required since the cookie was indeed needed to keep a visitor’s session on the site with legitimate interests (and for server affinity when balancing).
The engineers configured the cookie directly on the CDN, so every single request to the website would have a Set-Cookie header. As soon as a visitor landed on the site, they’d have a randomized, anonymous session ID assigned.
In their cookie logic, the engineers set a TTL of 30 minutes on the session, renewed after every request, so the session would expire after 30 minutes of inactivity. This is the same definition that Google Analytics uses for a session, so that gave them some continuity in their analytics as they transitioned to this new setup.
Handling real-time use cases with Tinybird
One of the driving influencers for the retailer taking on this project was Google Analytics’ inability to handle the real-time use cases that emerged as absolutely critical for them. For example, on the biggest retail day of the year (Black Friday), Google Analytics might just stop working as it grappled with the company’s immense scale, and they’d have absolutely no insight into how the website performed during its most indispensable moments.
Tinybird readily solves this problem with an architecture that serves low-latency results on analytical queries over billions or trillions of rows.
With events data going into Tinybird via Tinybird’s native Kafka connector, the engineers were able to build some pretty mind-blowing products, including a frontend application that internal analysts now use to track active sessions, active carts, and active orders in real-time with sub-second latency across their entire global eCommerce ecosystem.
Remember, the backend was processing tens of millions of events every day (peaking on Black Friday), and the data engineers were able to bring additional data into Tinybird and enrich it with joins for up-to-the-minute insights into revenue performance filtered across specific geographies, product categories, and individual product. All of this without tracking a single piece of PII. This is impressive.
What this means for the future of eCommerce
Tinybird’s founders originally united in the shared belief that data-driven real-time applications have the potential to change entire industries. Not only did the data engineers, analysts, and developers at this retail giant experience that firsthand: The dashboard they built is now the first page that anyone on the eCommerce side of the business looks at every single day.
What Tinybird made possible opened up new use cases that they didn’t dream were achievable only a few years prior. Certainly, they couldn’t have been accomplished with Google Analytics.
And with the simple solution above, they achieved quite a bit:
- No sampling in their analytics. Near 100% accuracy on data collection and processing.
- Data freshness under 1 minute, with sub-second application latency, across their entire multinational business.
- Complete control of the data flow, so they only tracked the data they needed and could be more confident in their privacy compliance.
- Completely flexible attribution modeling based on individual events that can further be calculated retrospectively (solving another big shortcoming of Google Analytics).
For now, the company still relies on Google Analytics to serve many of its less pressing analytical needs, especially those where they can stand to rely on cookie consent from visitors.
But now that they’ve created a new, privacy-first pathway to solve some of their most challenging business problems, they’ve discovered even more operational use cases than anticipated.
And thus, this massive retail company has shifted from reactive to proactive, getting ahead of customer demand in real time by analyzing what's happening right now, not the day before. They’re well-prepared for what’s next, confident that they’ve implemented a privacy-first alternative to Google Analytics that can serve their real-time analytical needs now and in the future.