


DataMarket, a spinoff of WhiteBox, is the largest privately operated data marketplace platform in Spain. We save our customers thousands in data acquisition and engineering costs by providing them clean, ready-to-use, and GDPR-compliant datasets. Every dataset we offer, covering topics like real estate, mobility, retail, weather, and public administration; helps our customers enrich their internal databases, improve their AI models, and make decisions real-time.
Some of our datasets have years of uninterrupted history of daily updates and are used, among other things, to monitor inflation in real time.
The challenges we faced with old infrastructure
We initially created DataMarket in early 2021 as a spin-off of our Data Science / AI Consulting company, WhiteBox. As a fully bootstrapped project, it ran entirely on our existing on-premise infrastructure, a data center located in our Madrid office. The core components of the project included:
- Postgres: as the relational database our crawling engines use as a backend.
- ClickHouse®: as the analytical database we used to store and process our datasets.
- FastAPI and Google Drive: to share the data with our clients.
By definition, a data marketplace is a space where clients pay for datasets on a subscription or per-use basis. It’s particularly challenging to create new and large datasets in real time, and simultaneously control user access while maintaining a positive user experience. These challenges are what drove us to consider upgrading our legacy infrastructure, and they are explained in more detail below.
We weren’t prepared to scale to billions of rows per week
A vital piece of DataMarket is our web crawling core, which crawls hundreds of websites, extracts valuable information, and stores it for future processing. This component continually generates rich datasets, often with years of historical data.
At the beginning of the project, our on-premise server was more than enough to store our data, but as time passed and the number of crawled pages grew, we were forced to pay for bigger storage devices and move some historical data to cloud-based storage.
We don’t expect the amount of data we create to slow down. Quite the opposite, as we’re constantly adding new data sources to our service. While some of them only create thousands of rows per day, others add millions of new rows every few hours.
At the same time, because we’re monetizing these datasets, we have rigorous standards for data quality. We always prioritize things like avoiding duplicates, checking data types, null values, and many more nuances.
Controlling data access was a nightmare
When customers pay for access to our data, the dataset they receive is highly customized based on both their needs and their budget.
For example, we have a real estate dataset that includes all properties in Spain, with metadata about those properties (latitude, longitude, type of building, floor area, etc.). Some of our customers pay a reduced fee only for properties located in Madrid, while others need the full dataset.
Likewise, depending on when they subscribed and what they need, some customers get access only to data added from the time they subscribed, while others might pay more for all the historical data.
Put simply, every customer should get only the data they paid for. No more, no less. Accounting for these precise access controls on a client-by-client basis, especially as new data is constantly being added, becomes a huge nightmare.
Every customer needs something different
One of the biggest hurdles for us to overcome is that, although our customers might find our datasets both interesting and valuable, they just don’t have the technical expertise to properly process it. As depressing as this may sound, many companies still use Excel spreadsheets to handle data transformation. They simply don’t have the knowledge necessary to do a proper ETL.
To help our customers out, we usually offer an initial consulting service to get the data in the format they need. This typically means doing some specific data reshaping for them, so that by the time they get the data, it’s ready-to-use, and they can start to get value from the very first moment they buy a subscription.
In addition, our clients need different formats when accessing the data, for example via an API, a JSON file, a CSV file, etc. One size does not fit all.
As you probably can imagine, implementing a specific ETL for each client and designing a custom output becomes a big pain from an operational point of view, especially as we grow.
Having various support engineers creating custom ETLs for our customers in different systems and tools - like SQL queries, pandas, or Spark in a Jupyter Notebook - costs us a lot of time and money. Having a single methodology and tool to do that kind of support task was core to making the process more efficient and maintaining our margins.
Tinybird specifically addresses each pain
I started using Tinybird when they announced the open beta. At WhiteBox, we are always looking for new tools to integrate with our development stack. Everyone in the data sector was talking about Tinybird back then, and I already knew the product because I am a long-time ClickHouse® user (if you use ClickHouse®, Tinybird documentation and blog posts are sometimes more helpful than the official stuff). So I started implementing some PoCs, and I found the product really easy to use. After some testing and learning all the functionalities, I realized that Tinybird was a perfect fit for DataMarket. It could replace many tools, reduce complexity, centralize our operations, and make us much more efficient.
So after more than a year of operating DataMarket, and experiencing solid growth, we decided to start the migration of huge parts of our infrastructure to Tinybird. We needed a scalable tool that could store the raw datasets, transform them on the fly, and let us easily share them with our clients.
Tinybird makes this all possible. We can send Tinybird high-frequency data using a simple HTTP endpoint, easily transform the data with SQL, and automatically publish the results as an API endpoint in a single click. We’ve eliminated 4 tools from our legacy infrastructure and moved almost everything to Tinybird, just because of how easy it is to use and maintain. Below is a bit more on how Tinybird has addressed the specific challenges we had with our old architecture.
High-frequency data ingestion is super easy
One of the features that we love the most about Tinybird is the ability to ingest data directly from our web crawling core at high frequency.
To add new data to our data source, we just make an authenticated HTTP call to the Tinybird high-frequency ingestion (HFI) endpoint, and the data is instantly loaded and available to our users at different endpoints.
This saves us a ton of time creating batch ingestion pipelines, and we even developed a Python module and integrated it with our web crawling core to make this ingestion even faster. The Tinybird HFI endpoint is technically still an experimental feature as of the time I wrote this, but we have been using it for several months with no problems.
Every day, we hit the HFI endpoint more than 10k times. Each hit can contain hundreds or even thousands of records from our web crawling engine. Every week, we add more than 200M new rows to our datasets, and that’s just the beginning, as we are adding new data sources almost every week.
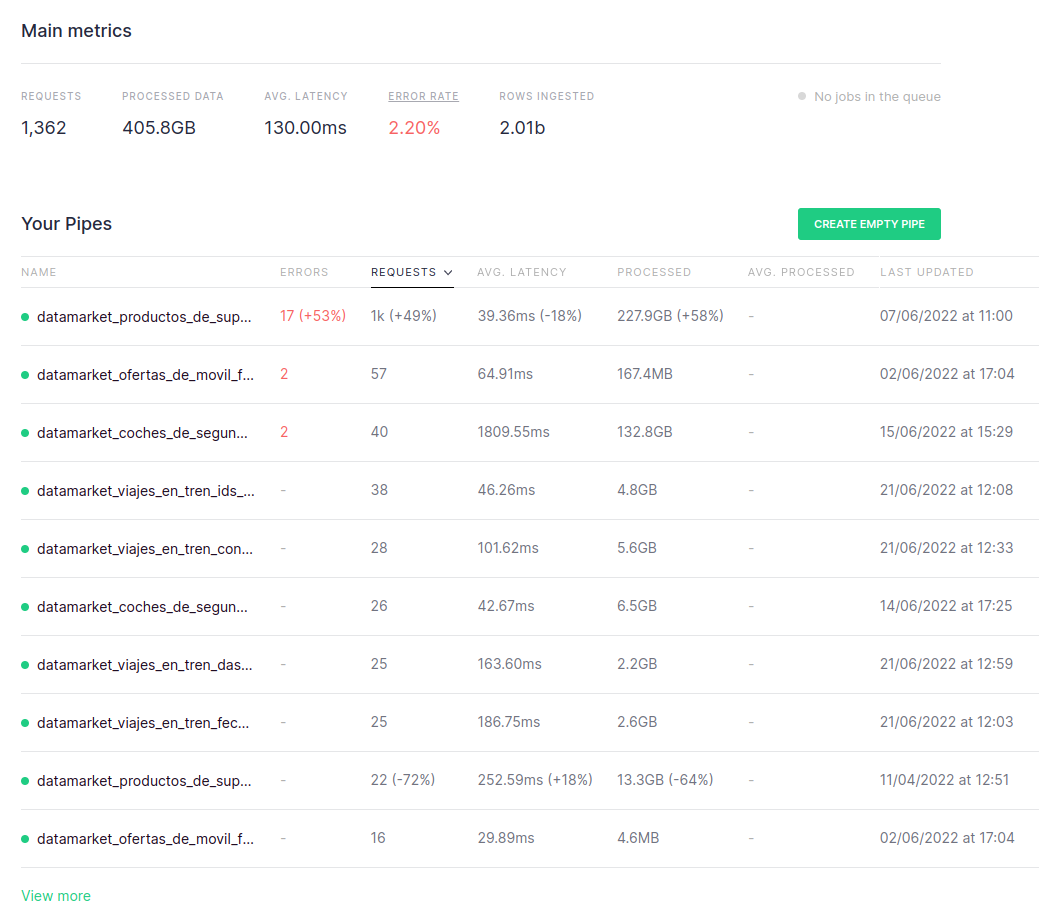
Because Tinybird is built on top of ClickHouse®, we can use cool features like the ReplacingMergeTree engine, which allows us to define some columns as deduplication keys, and then push our data to Tinybird and have duplicates managed automatically by the engine.
Row-level tokens make user access control painless
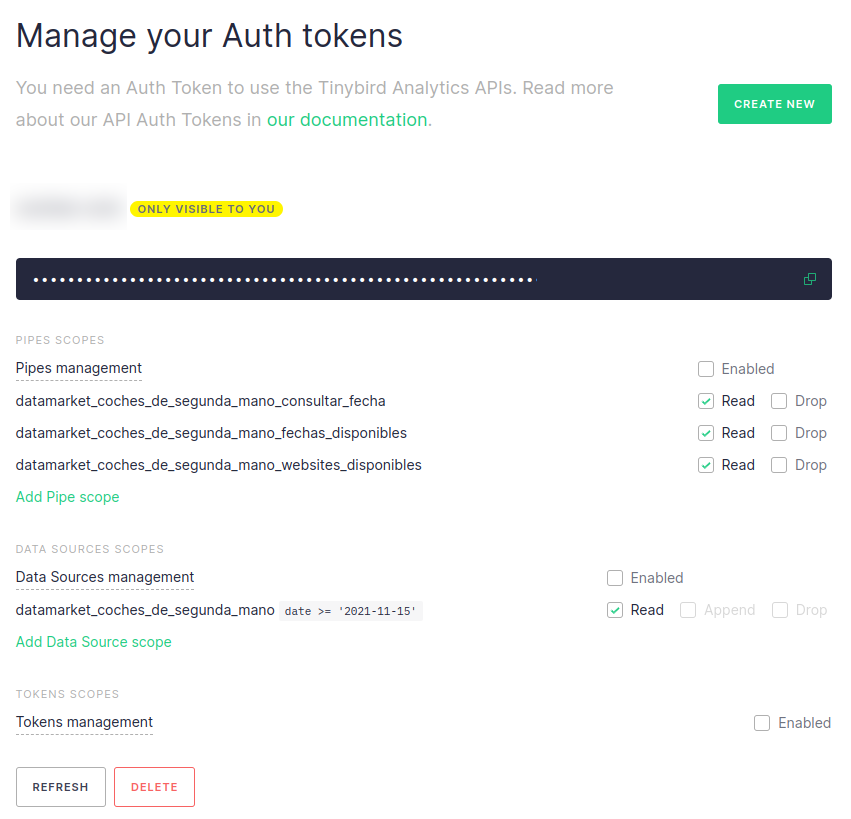
Tinybird’s token-based data access architecture has made it so much easier for our team to manage customer data access based on their subscription details, which has helped us to scale our data sharing operations much more easily.
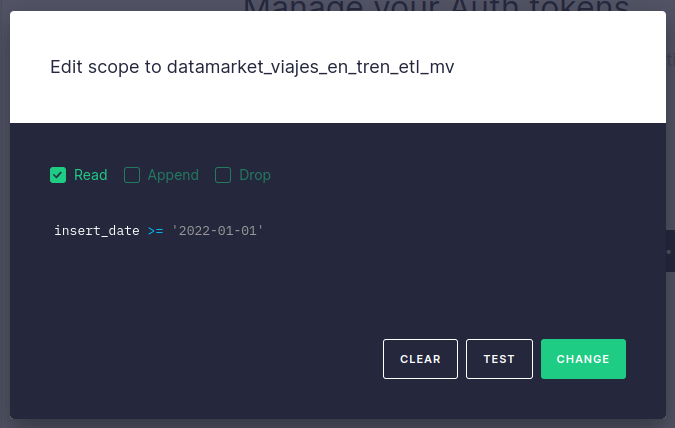
With Tinybird, we create a token for each client that governs their access to the data endpoints that we create. We can assign specific scopes to the tokens to choose which endpoints our customers can access, but that’s just the beginning. Each token can include a filter, defined in SQL, to enable row-level access. We can add a simple SQL statement to limit by date (e.g. timestamp >= subscription_datetime) or by any other column (e.g. city = ‘Madrid’):
In the event a client buys a new dataset or wants access to an extended history of an existing one, we can automatically add a new scope to their token, or modify the existing one.
Processing pipelines
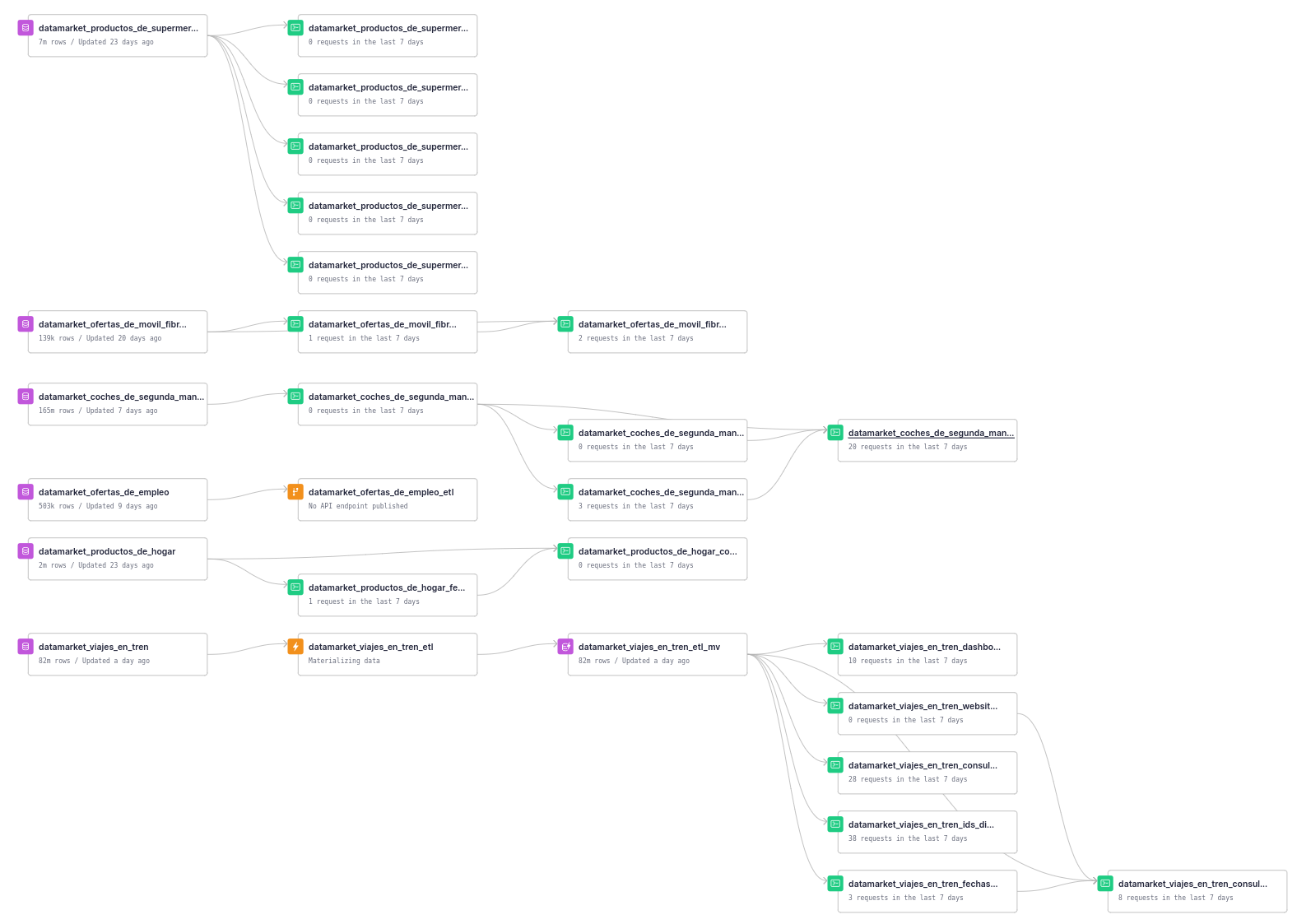
Tinybird’s “Pipes” feature makes it very simple for us to create versions of our datasets exactly the way our clients need them. If you’ve used dbt, you’ll understand how Pipes work. Basically, each pipe consists of chained nodes of SQL, and each subsequent node can query over the results of the prior node.
Not all members of our team are Data Engineers, so the Pipes feature makes it really easy for even semi-technical team members to easily transform the data and support our clients. It’s a huge plus for our team to have such a simple and intuitive way to transform the data.
Also, our datasets become exponentially more valuable when they are combined with other complementary datasets. We can load all of our datasets into Tinybird, and define joins across datasets in our Pipes. These transformations happen automatically as new data is ingested, so endpoints that rely on joins always serve fresh data, which is incredibly valuable to us and our customers.
What Tinybird means for our team
Finding Tinybird has been huge for us. All of the features I just described fit our use case like a glove, and we've actually enjoyed implementing them! We had originally started trying Tinybird with some of our more popular datasets, but now that we’ve validated the use case and seen what it can do, we’re transitioning everything over to the new infrastructure. It should put us in a good position to continue to scale our datasets and deliver a really great customer experience.
If you're interested to learn more about our Tinybird use case, you can find me in the Tinybird community Slack or on LinkedIn.