


The same techniques software engineering teams use to collaborate on and deploy software products must also apply to real-time data products.
We’ve proclaimed this mantra at Tinybird from the start, and we’ve been writing about it for years. Mature data teams now recognize that it’s important to treat data pipelines as software projects. This spans many facets of software engineering best practices, from architecture design to clean code to testing to CI/CD.
As you build real-time data pipelines in Tinybird, one thing is certain: Your data model will change. Your schemas will change. Your API will change. The only constant is change. So when you want to make changes, you need to lean on tried and true processes and workflows that enforce quality, enhance collaboration, standardize releases, and protect production.
As you build real-time data pipelines in Tinybird, the only certainty is change.
Until today, it was up to you to figure all of this out. Because of that, deploying a new table schema or testing different sorting keys or merging new endpoints into production in a real-time data pipeline often felt risky, painful, and slow.
When working with real-time data, the challenges faced by both our customers and the data community at large were many. Here are some we’ve heard specifically:
- There was no clear source of truth. The production Workspace didn’t match the Data Project files. Where should you do your work?
- There was no audit log or traceability. Who changed what, when, why, and how?
- There was a fear of breaking something. It was too easy to make breaking changes to schemas or Endpoints. What if this brings down production?
- There was no clear way to collaborate. Git workflows weren’t enforced. The flexibility was nice, but it hurt bigger teams especially. How can we manage Tinybird Data Projects among large, distributed teams?
- There was no standard workflow. How should we iterate, test, and deploy to ensure quality and consistency?
- There were no best practices enforced. Things like linting, fixtures, quality assurance, and code reviews weren’t well integrated with the Tinybird workflow. Why can’t we work with Tinybird like other software projects?
- It was too easy to make hot changes in production. Tinybird’s workflow and tools actually encouraged editing resources directly in production. Where are the branches?
- It required tribal knowledge to deploy changes: To contribute to the team and edit the Data Project, newcomers had to learn a new tool (the Tinybird CLI). Why can’t we just use Git?
That’s a tough pill to swallow. We chose not to enforce what we’ve now learned are best practices, erring on the side of flexibility to give teams of all shapes and sizes the ability to define and document their own workflows. But we’ve learned that our lack of opinions was short-sighted. Our customers, including Vercel, Split, Platzi, FanDuel, and others, have consistently asked us for guidance on how best to version and deploy their Data Projects.
As we refined our guidance, we developed strong opinions about the way you should work with data, even integrating these opinions into our own development and customer support workflows. Now, those opinions have made their way into our product, so that all of our customers can benefit.
We've developed strong opinions about the right way to build and iterate real-time data pipelines.
Today, the way you work with data gets an upgrade. Iterating real-time data pipelines is very, very hard. And we’ve learned through trial, error, and long hours of customer support the patterns and practices that make it easier. Now, we’re enforcing those patterns, because the same techniques that software engineering teams use to collaborate on and deploy software products must also apply to real-time data products.
Introducing Versions: Integrated Version Control and CI/CD for Tinybird Data Projects
Today, Tinybird brings you Versions: a safer, more collaborative, more standardized way to work with Data Projects in Tinybird. Now, you can iterate your Data Projects and release directly from Git, just like you work with any other software project.
Now, you can iterate your Data Projects and release directly from Git, just like you work with any other software project.
Tinybird was founded on the principle that performance is table stakes, but developer experience wins. It’s in our spirit to help data end engineering teams develop more quickly, ship more confidently, and more easily maintain their real-time data products in production. Versions is the fruit of that spirit.
With Versions, we’re advancing the field of data engineering one step further toward proven software engineering principles. As more data engineers and developers focus on building real-time data products, we’re plugging the gap. Versions brings the best of distributed version control and CI/CD to the real-time world, making it safer, more reliable, and more consistent to deploy changes to your real-time data products in production.
“Tinybird gives us everything we need from a real-time data analytics platform: security, scale, performance, stability, reliability, and a raft of integrations. But what really makes it stand out is the simplicity and elegance of the Tinybird user experience. When we brought in our pilot users to evaluate several different real-time data tools, they preferred Tinybird over the others.”
With Versions, data and engineering teams can:
- Track changes to their Data Projects. Manage versions of Tinybird Data Projects in code using the same Git-based workflow you have come to love.
- Collaborate more effectively. Work more productively within big teams to deliver high-quality, tested real-time data products at scale.
- Deliver with confidence. Automate the build, test, and deployment workflow for Data Projects with simple and secure CI/CD.
Read on to learn more about Versions and how Tinybird is devoted to helping data and engineering teams build fast data products, faster.
The new way to work with Data Projects
For the last few months, a handful of Tinybird customers have been piloting Versions for us in private beta. The feedback we’ve gained has been tremendously valuable, and we feel confident that it’s ready for a public beta. Over the coming weeks, we’ll be rolling out Versions to our Enterprise and Pro customers on an as-needed basis.
We'll be rolling out Versions to Enterprise and Pro customers on an as-needed basis. If you'd like access, please join the waitlist.
With Versions comes a new way to work in Tinybird that alleviates many of the pains enumerated above. If you’d like access to Versions in your Tinybird Workspaces, please join the waitlist. We’ll let you know when it’s available for your Workspaces.
In the meantime, read on to learn more about this new workflow, and find links to documentation and additional resources to help you understand the ins and outs of this powerful new release.
Versions: The Core Concepts
Before we dive into the workflow, let’s talk about some new concepts introduced by the Versions release:
1. The Data Project. The Data Project is not a new concept per se, but its importance increases considerably with this release. The Data Project is a set of files that describes how your data is stored, processed, and exposed through API endpoints. It defines your Tinybird resources - Data Sources, Pipes, Endpoints, Connectors, Tokens - and serves as a source of truth. Read more about the Data Project in the docs.
Versions makes iterating your Data Projects more tightly woven with proven Git-based workflows, introducing the same version control, CI/CD, and testing concepts that you used for any other software project.
2. Branches. Branches are ephemeral copies of your Workspace, allowing you to make and test changes without breaking production. You can create new Branches for testing and development. In addition, CI uses ephemeral Branches to automatically check syntax, run regression tests, and perform data quality checks. Read more about Branches in the docs.
3. The Git Integration. Now, you don’t need to work with the CLI. Instead, you collaborate with Git. Connect your Git repositories with your Tinybird Workspace with tb init –git, generate default CI/CD actions, and track Workspace resources by Git commit. You can learn more about the Git integration in this guide.
4. CI/CD Actions. When you integrate with Git, Tinybird will create default CI/CD actions for either GitHub or GitLab (your choice). These CI/CD actions are designed to enforce quality assurance and ease deployments, and you can modify them as needed to enforce the specific contracts and needs that your team has. You’ll find the workflow templates in this GitHub repository.
The default CI process performs linting checks, deploys an ephemeral environment, runs a diff between Main and the new release, and performs regression and fixture tests. The CD process deploys the Workspace, runs a final diff, and performs data quality and DataOps checks. You can learn more about CI/CD with Tinybird Data Projects in this guide.
5. Read-only Pipes in UI. No more hotfixes to prod. Pipes in your Live Release can (and should) be set to read-only in the UI. This ensures and enforces that all production changes are made through the Data Project files and Git-based workflows.
6. Playgrounds! If you want to try a new idea or test some SQL, you can use Playgrounds to build draft Pipes in the UI without worrying about breaking anything or spinning up a new Branch. Playgrounds you create are only visible to you; they aren’t automatically shared with other members of your Workspace, though you can share them on an as-needed basis.
How to work with Data Projects: A quick guide
Below you’ll find the high-level workflows that you’ll adopt with Versions. Where appropriate, we’ve linked to documentation that provides additional details on each step of the process. For more information on iterating your Data Projects and using Staging and Production Workspaces, read this guide.
Step 1. Decide on the structure of your Data Projects
There are many ways to structure your Data Projects depending on your needs and use cases. Some teams will have only one Workspace. In this case, you’ll have one Data Project.
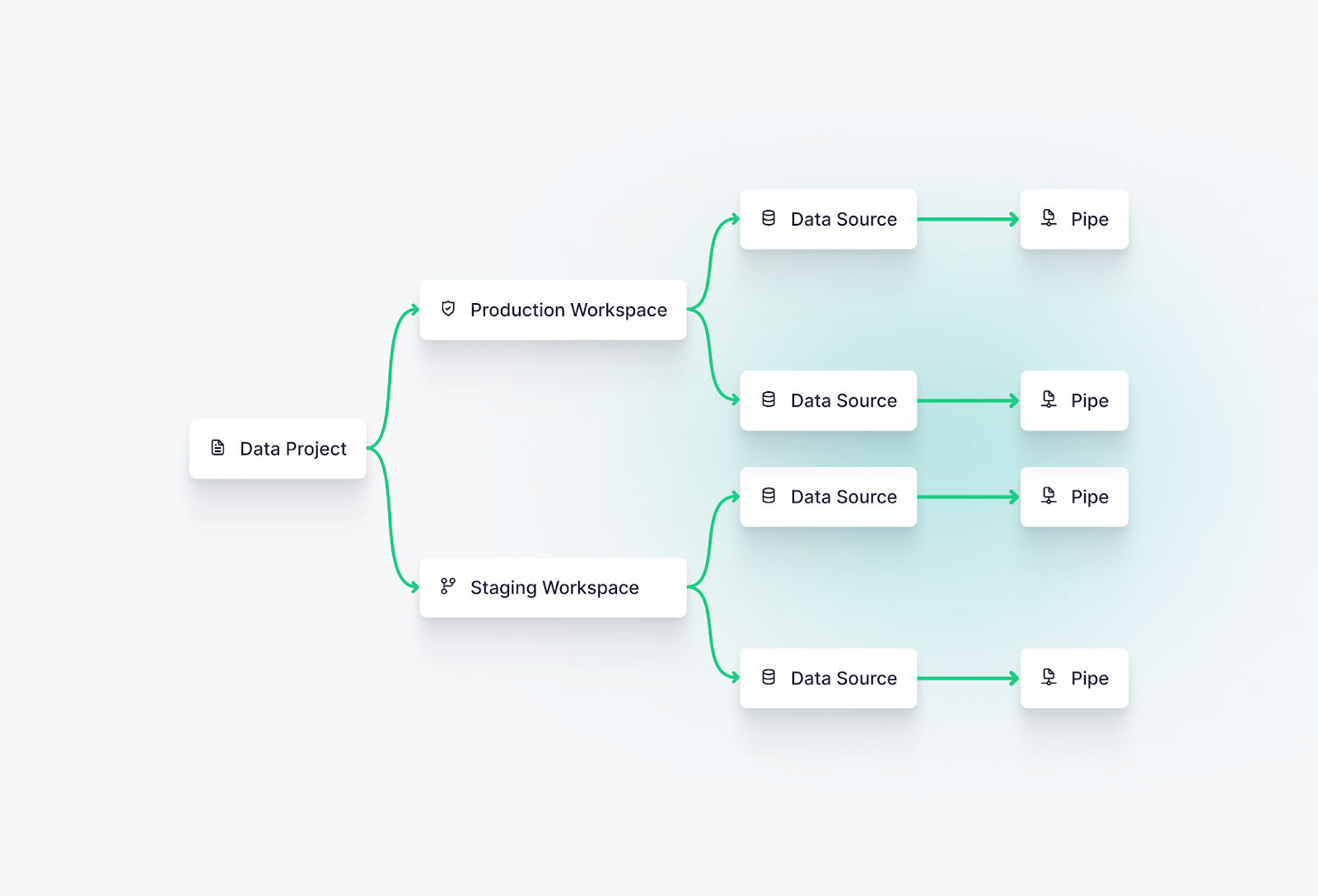
Others may choose to have dedicated Workspaces for pre-production and production. In this case, it is still common to have a single Data Project that governs all resources.
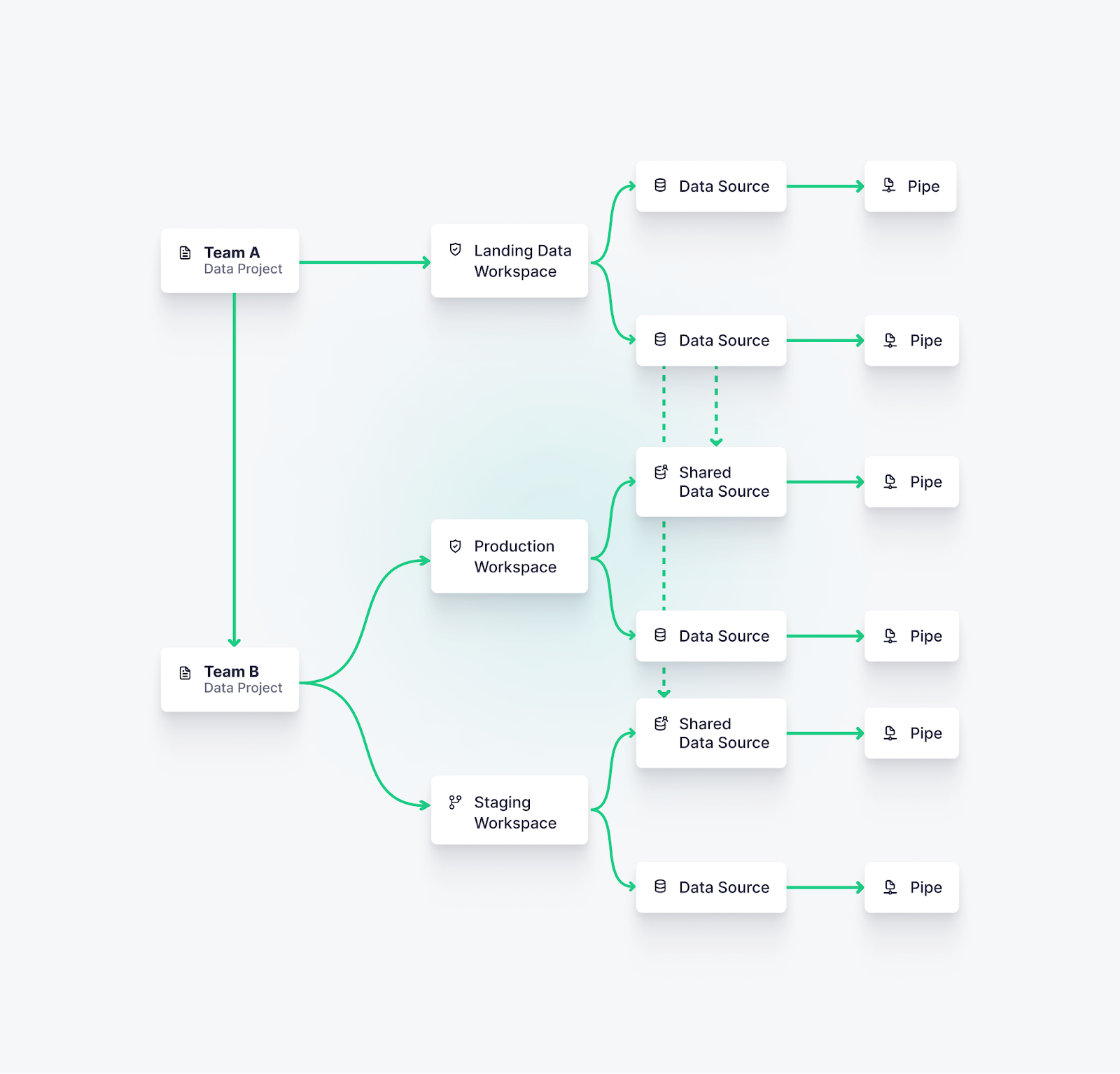
Larger teams may choose to have a “landing Workspace” controlled by data or data platform teams, with Shared Data Sources to other Workspaces for building use cases. In this case, it is wise to create unique Data Projects for each team.
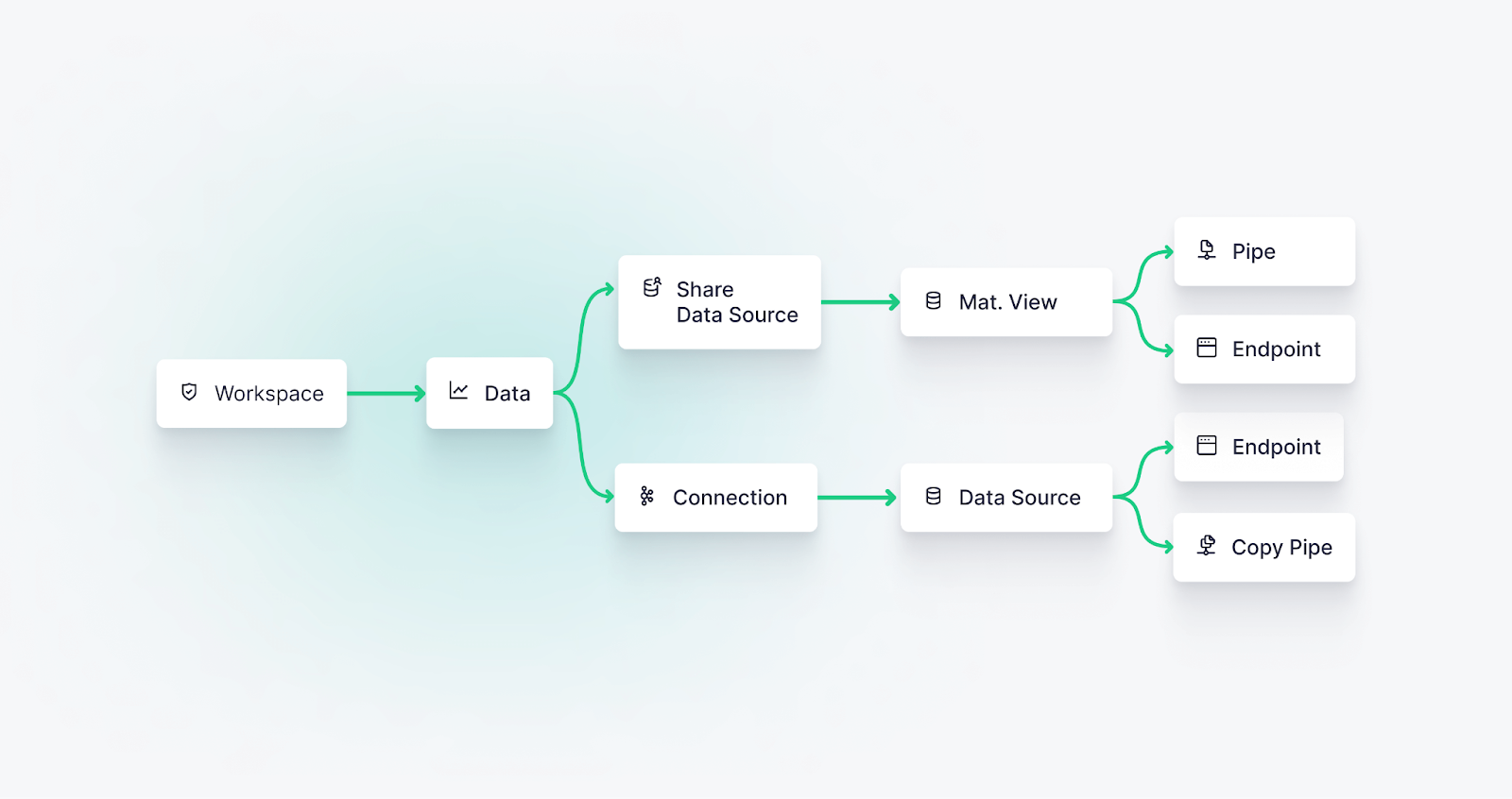
Step 2. Start building your use cases
This is the Tinybird workflow you’re familiar with. Create a Workspace and set up your Data Sources with one of our Connectors, build your Pipes with SQL, and publish your APIs. By default, you’ll be working in your Workspace’s Live Release.
We often recommend that you start in the UI. It’s the best place to quickly iterate and get instant feedback on your first use case. Of course, if you prefer to get started with the CLI and Git immediately, that works too.
Step 3. Protect Production
When you’re ready to deploy, sync your Data Project with Git and push your first commit to your remote.
Once you do this, your Workspace is production-ready and synced with your Git repository. You can (and should) protect your Live Release from the UI.
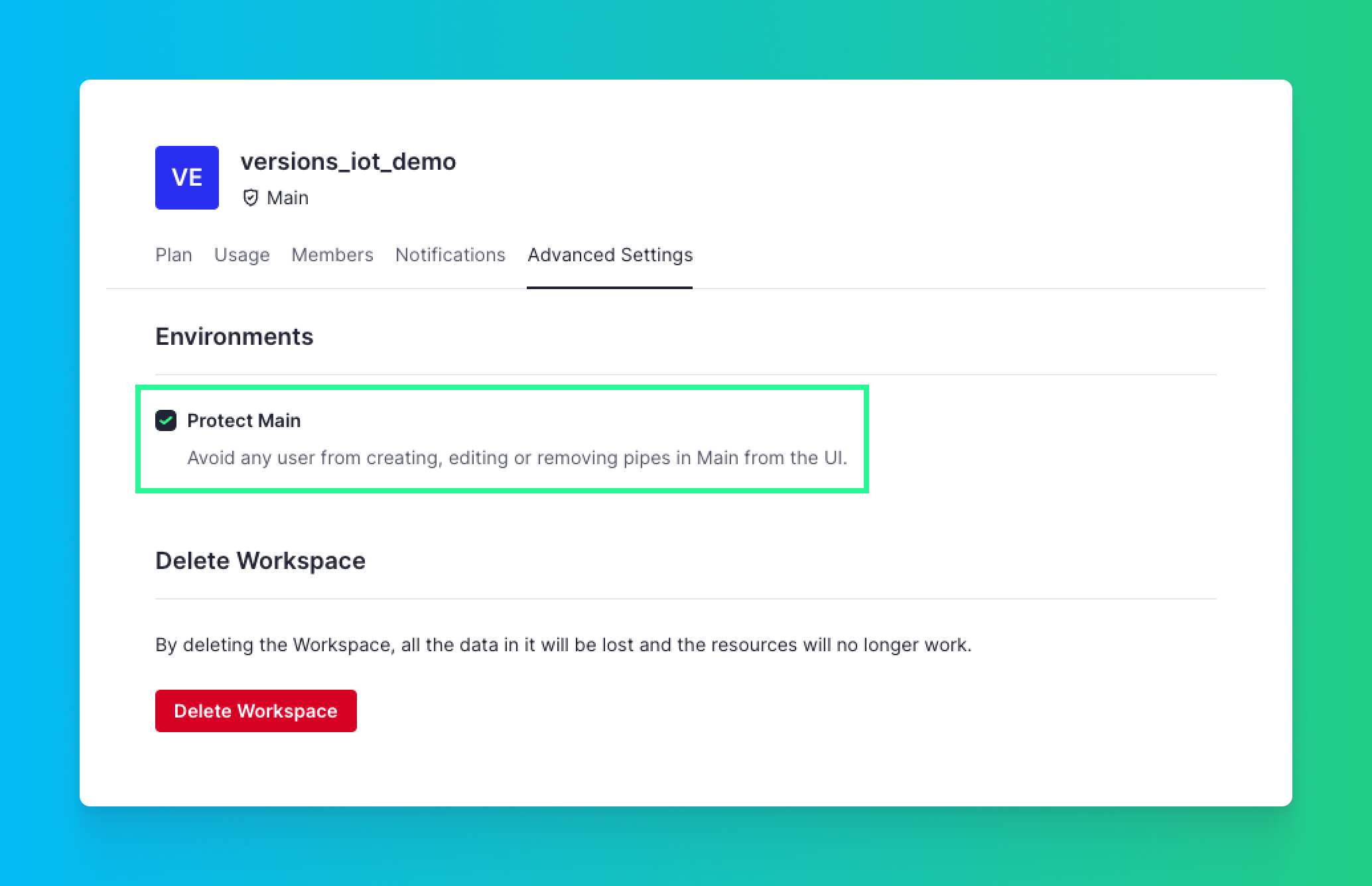
Once you do, you’ll only be able to make changes to Pipes in Main using Git.
For more details on how best to integrate your Data Projects with Git, please read these docs.
If you want to explore within your Live Release using the UI, use Playgrounds. Create Pipes as you normally would, download the Data Project file, and add it to your Git commits.
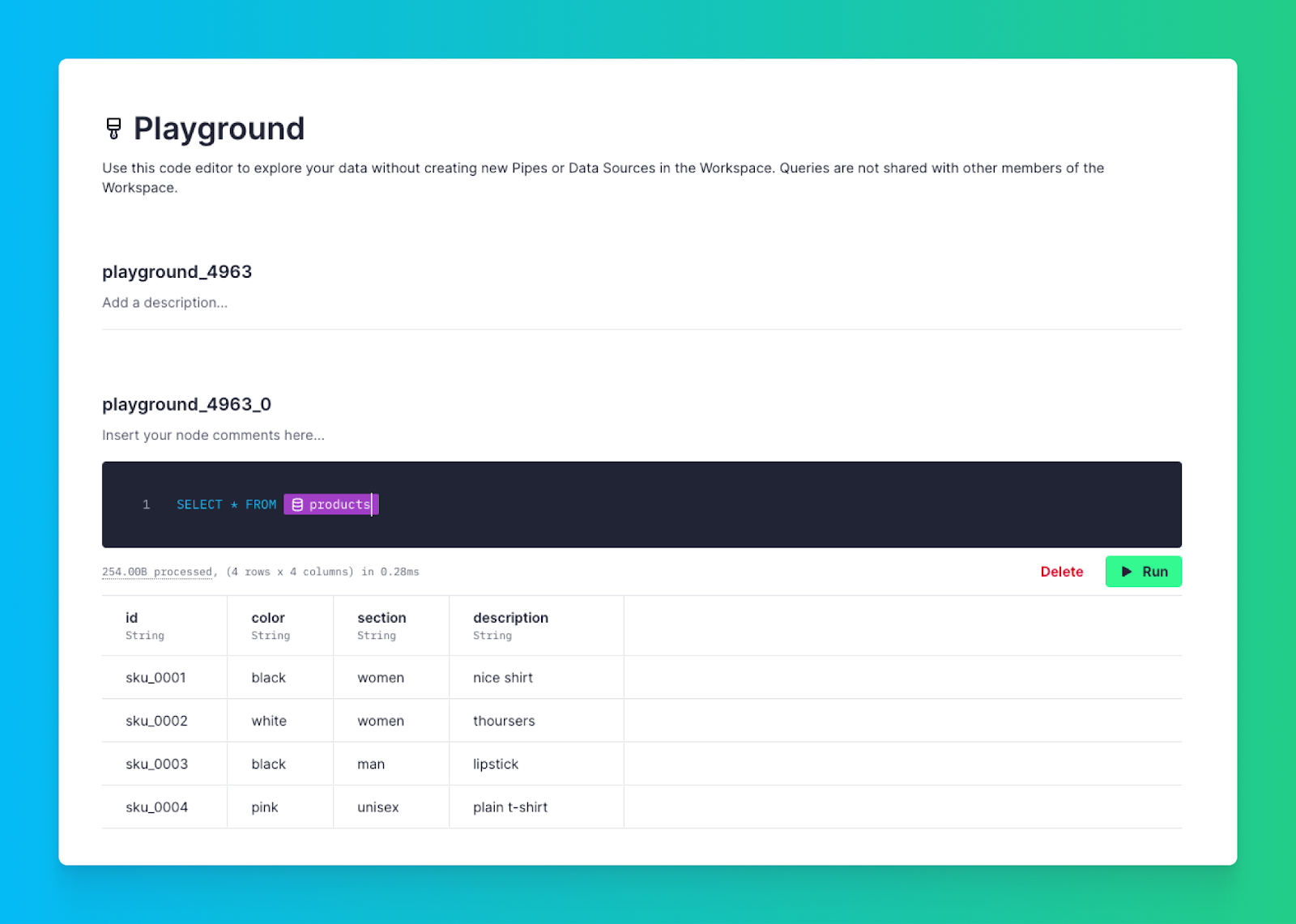
4. Iterate your use cases
Work with your Data Project files as you would any other software project. Make changes to Pipes, change Data Source schemas, add columns, or optimize sorting keys.
As you work, you can use Branches to test what you’re building. Create new Branches and attach data from Production Data Sources for testing.
Once you’re done testing and happy with your changes, push them to a new branch as you would with any software project:
With the CI, you automatically test changes to your real-time data products, helping you avoid downtime and breaking changes. To learn more about setting up CI/CD with Tinybird Data Projects, read this guide. For more information on developing test strategies with Tinybird Data Projects, check out these docs.
Finally, merging your request will trigger the CD that ultimately deploys your changes to your Tinybird Workspace, keeping your Data Project and your Git repository in sync.
What’s next?
This initial release of Versions is just the beginning. With this release, we’re asserting that there is a proper way to work with real-time data pipelines, and we’re enforcing that opinion.
Still, we have plenty of work to do. Even with this new workflow, you still need some “tribal knowledge” to know how to deploy changes to production without breaking things.
We’re working on a few things to make this simpler:
- Releases. Releases in Tinybird will match your Git commits. With Releases, we hope to standardize the deployment process and make it easier to manage your data product lifecycles. We’re working on support for preview/live/rollbacks, semantic versioning and labeling of Data Project files, and other features that will make it easier to track, promote, and revert changes.
- Eliminating the need for tribal knowledge. We’re working to make it clearer and more consistent to make common changes to your Data Projects without needing to know all the dependencies and how changes might break production. This includes making changes to Endpoints, non-breaking schema changes, breaking schema changes, Shared Data Sources and Proxies (shared Pipes), Data Source Connectors deleting resources, token and member management, and more.
During the upcoming weeks, we will share what we’ve learned over the past year or so building this new feature, from the trouble with making multiple quick copies of a Workspace to how we imagined and wrangled the Git integration. We’ll also share incremental release improvements and new features related to this workflow.
If you want access to Versions, please join the waitlist here, and we’ll let you know when it’s your turn.
As always, please bring your questions and feedback about Versions. We’d absolutely love to hear from you. Is this a better experience? What do you love? What’s still missing? Join our active Slack community or reach out to your dedicated Tinybird rep to let us know.
Start iterating in real-time with Tinybird
Tinybird Versions is a huge leap forward for developers and data teams building real-time data products at scale. It’s now safer and more consistent to deploy changes to production in real time without missing a beat.
If you’d like to dig deeper into Versions, check out the documentation listed below or watch the screencast below.
- Working with Git
- CI/CD with Tinybird
- Implementing Test Strategies
- Staging and Production Workspaces
- Deployment Strategies
If you’re new to Tinybird, you can sign up right here. It’s free to start, with no credit card required and no time limit.