


Data analytics is changing. Batch is out. Real-time is in. And with this shift comes a new mindset, new tools, and new terminology that data engineers have to master.
Real-time data processing is growing in both importance and adoption among data teams. Its value can’t be understated, and data engineering and data platform teams are turning to tech and tools that can help them achieve it.
In this post, I’ll explain what real-time data processing is, why it isn’t what you think it is, and show you some useful reference architectures to help you plan, manage, and build a real-time data processing engine.
What is Real-Time Data Processing?
Real-time data processing is the practice of filtering, aggregating, enriching, and otherwise transforming real-time data as quickly as it is generated. It follows event-driven architecture principles to initiate data processing rules upon event creation.
Real-time data processing is but one gear in the machinations of real-time data and real-time analytics. Sitting squarely between real-time data ingestion and real-time visualization (or real-time data automation!), real-time data processing links the engine and the caboose of a real-time data train.

But don’t assume that just because it’s the middle child of the real-time data family it should go unnoticed by you and your team.
Mixed metaphors aside, the systems and tools that enable real-time data processing within real-time streaming data architectures can quickly become bottlenecks. They’re tasked with maintaining data freshness on incoming data, ultra-low query latency on outgoing data, and high user concurrency while processing bigger and bigger “big data”.
If you’re building a real-time analytics dashboard that needs to display milliseconds-old data with millisecond query latency for thousands of concurrent users, your real-time data processing infrastructure must be able to scale.
What is real-time data?
Real-time data has 3 qualities:
- It’s fresh. Real-time data should be made available to downstream use cases and consumers within seconds (if not milliseconds) of its creation. This is sometimes referred to as “end-to-end latency”.
- It’s fast. Real-time data queries must have a “query response latency” in milliseconds regardless of complexity. Filters, aggregates, and joins are all on the table when you’re building real-time analytics, and complex queries can’t slow you down. Why? Because real-time analytics often integrate with user-facing products, and queries that take seconds or more will dramatically degrade the user experience.
- It’s highly concurrent. Real-time data will almost always be accessed by many users at once. We aren’t building data pipelines for a handful of executives browsing Looker dashboards. We’re building in-product analytics, real-time personalization, real-time fraud detection, and many more user-facing features. Real-time data is meant for the masses, so it needs to scale.
Real-time vs. Batch Processing
Real-time data processing and batch processing are fundamentally different ways of handling data. Real-time data processing handles data as soon as possible, ingesting, transforming, and exposing data products as soon as new data events are generated.
In contrast, batch processing handles data on some periodic schedule, using ETL/ELT workflows to occasionally extract data from source systems, transform it, and load it into things like cloud data warehouses.
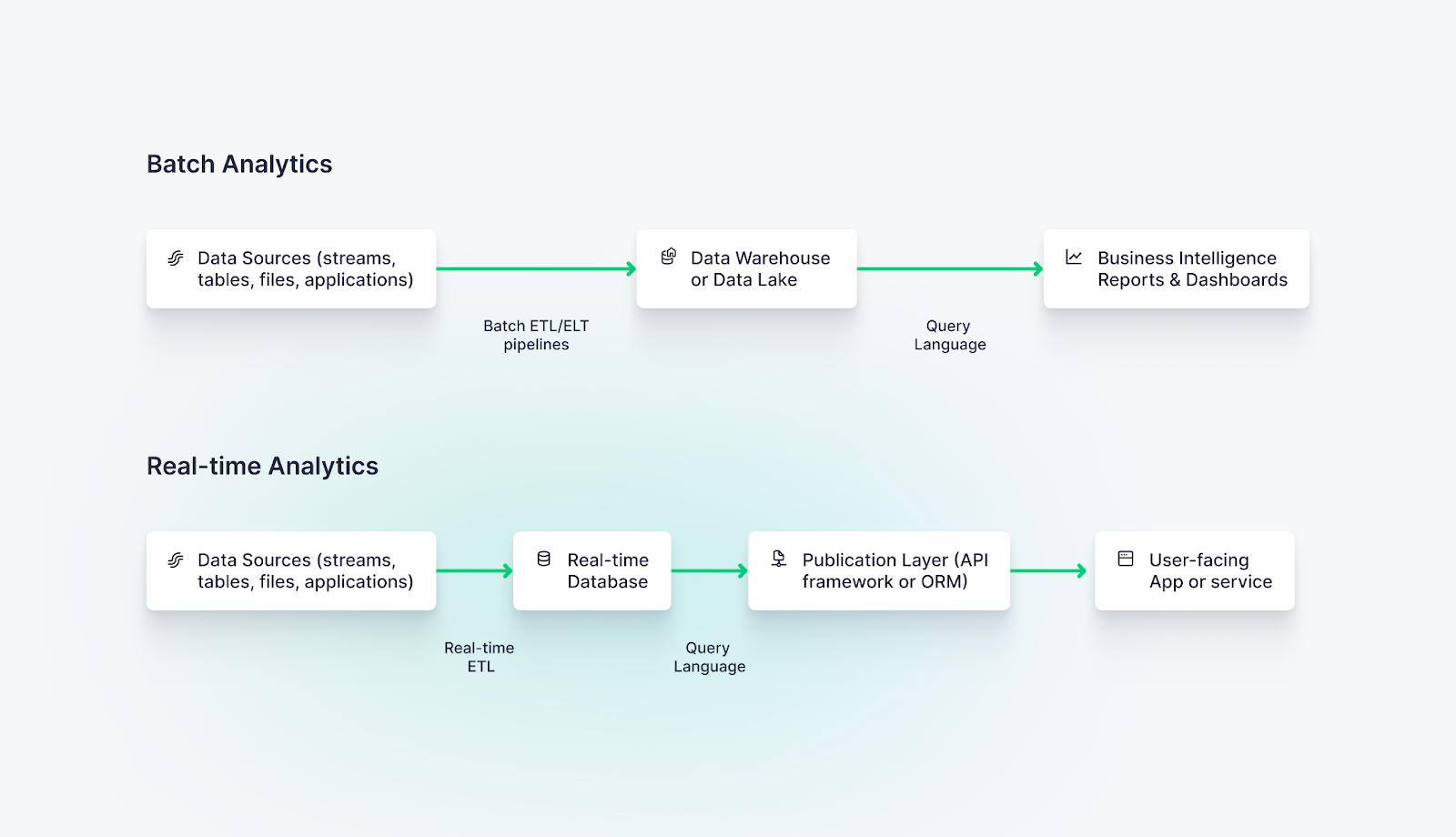
The differences between real-time data processing and batch data processing should be apparent simply by name: One happens in “real-time”, and the other happens in “batches”. Beyond their names, some important points draw a thick line between the two:
- Data Ingestion. Real-time data processing and batch processing use very different data ingestion patterns.
Real-time data processing follows event-driven architectural patterns. Data processing is triggered as soon as events are generated. As much as possible, real-time data processing systems avoid data ingestion patterns that temporarily store event data in upstream systems (though real-time change data capture workflows can sometimes be a unique exception).
Batch data processing, on the other hand, generally requires that events be placed in an upstream database, data warehouse, or object storage system. This data is occasionally retrieved and processed on a schedule. - Data Tooling. Real-time data processing and batch processing use very different toolsets to achieve their aims.
Real-time data processing relies on event streaming platforms like Apache Kafka and Confluent, serverless functions like AWS Lambdas, or real-time change data capture for data ingestion and to trigger processing workflows. They utilize stream processing engines like Apache Flink (or derivatives thereof, e.g., Decodable) to process data in motion and/or real-time databases (specifically those that support real-time materialized views) like ClickHouse® to perform complex filters, aggregations, and enrichments with minimal latency.
Batch data processing, on the other hand, uses orchestrators or schedulers like Airflow, Dagster, or Prefect to occasionally run Python code or Spark jobs that retrieves data from a source system (sometimes inefficiently), load the data into a cloud data warehouse, and transform it within the warehouse using tools like dbt. - Access Modalities. Real-time data processing and batch data processing serve different purposes for different users, and the way they expose data to downstream consumers is quite different.
Real-time data processing generally supports user-facing features that demand low-latency data access for many concurrent users. It’s designed for operational decision-making, real-time visualizations, real-time analytics, and automation.
Batch processing supports long-running analytical queries that don’t require low latency and for must serve only a few business intelligence or data science consumers. It’s designed for strategic decision-making and long-term forecasting.
Real-Time Data Processing vs. Stream Processing
Real-time data processing and stream processing are not the same. Stream processing is a subset of real-time data processing that deals with limited state and short time windows. Real-time data processing encompasses data processing with large state over unbounded time windows using real-time databases that support high-frequency ingestion, incremental materialized views, and low-latency queries.
The core difference between real-time data processing and stream processing is that real-time data processing is optimized for large volumes of data stored over long periods.
Stream processing engines like Apache Flink or ksqlDB struggle to transform data over unbounded time windows or with high cardinality. Real-time data processing leverages a full OLAP to run transformations over unbounded time windows on data with many fields that have potentially high cardinality.

Real-time data processing utilizes a real-time database to either store transformations in real-time within materialized views or maintain long histories of raw data sets that can be accessed at query time. The choice of a highly optimized, columnar, OLAP storage enables low query latency even for complex analytics over large amounts of data.
How Real-Time Data Processing Actually Works
Real-time data processing isn’t magic. It’s a sequence of fast, predictable steps that happen the moment new data appears.
Every millisecond matters, so each component in the chain has to be tuned for speed and scale.
From event capture to action
At its core, a real-time pipeline starts when an event is created. A user clicks a link, a sensor sends a reading, or a payment is approved.
Efficient real-time data ingestion ensures that these inputs are captured and normalized the instant they occur.
That event enters the system through an event bus or a connector and is instantly normalized—timestamped, structured, and ready for processing.
Once standardized, events are enriched with context: metadata like user ID, location, or device type. This makes the data meaningful, not just fast.
From there, processing engines apply transformation logic in motion. They aggregate, filter, or join incoming streams before the data ever touches disk. The result is an end-to-end workflow that runs continuously, not periodically.
In-memory computation and ultra-low latency
Real-time systems run almost entirely in memory. They don’t wait for writes, indexes, or stored procedures.
They use RAM as the active compute layer, keeping latency in the microseconds instead of seconds. Understanding what is low latency is key to optimizing these real-time performance goals.
In-memory processing lets you evaluate millions of events per second while still supporting complex operations like time-windowed aggregations or anomaly detection. Hot data lives in memory for immediate analytics, while colder data moves to storage for historical queries.
This “hot/cold” split is how modern systems keep both speed and cost under control.
Stateful correlation and composite events
Events rarely matter on their own. What matters is how they relate to one another.
A single login attempt is harmless. Ten failed logins followed by a large transfer might not be. Real-time processors keep track of state so they can correlate related events over time.
When multiple signals combine into a pattern, the system emits a composite event—a higher-level insight that other services can act on instantly.
The same principle applies to missing data. If an expected heartbeat from a sensor doesn’t arrive, that absence itself becomes an event. Real-time pipelines can detect what happened, and what didn’t, equally fast.
Filtering noise and enriching meaning
Not all data deserves attention. Filtering reduces volume and noise, allowing critical signals to pass through while irrelevant ones drop away.
At the same time, enrichment adds context that raw streams lack.
Real-time systems can look up reference data, map IDs to names, or attach risk scores in motion. Together, filtering and enrichment keep pipelines both fast and intelligent.
Continuous decisions and instant reactions
Once a rule or pattern triggers, action follows immediately. It might be an alert, an API call, or an automated workflow. These reactions are often programmatic, defined by business logic that can change on the fly without redeploying code.
Every processed event feeds into the next decision. The output of one rule can become the input of another, forming a self-reinforcing network of automation.
This is the heartbeat of modern data products: sense, decide, and act—all before the user notices.
Blending live and historical data
Real-time doesn’t mean ignoring the past. Some of the most powerful systems combine streaming data with historical baselines.
They compare current activity against weeks or months of history to detect deviations or predict outcomes.
This hybrid view—fresh plus historical—enables use cases like live dashboards, demand forecasting, and fraud scoring.
Tools for real-time data visualization make these insights accessible and actionable, turning raw streams into clear understanding of what’s happening and why.
It’s the difference between seeing what’s happening and understanding why it’s happening.
To efficiently manage stored event data alongside streaming workloads, many teams rely on modern databases like PostgreSQL, which offer strong consistency, extensibility, and integration with real-time analytics frameworks.
Architectural Principles for Reliable Real-Time Platforms
Real-time data systems don’t just need to be fast. They need to be reliable, consistent, and scalable under unpredictable workloads. Here’s what makes that possible.
From “store–analyze–act” to “analyze–act–store”
Batch systems follow a simple order: collect, store, analyze, act. Real-time pipelines flip it around. They analyze and act first, then store results afterward for compliance or retrospection.
This inversion eliminates decision latency. Actions happen while the data is still in flight, not minutes or hours later. It’s the shift from after-the-fact insight to immediate response.
Elastic scaling and fault tolerance
Traffic spikes. Sensors flood. Campaigns go viral. Real-time platforms absorb all of it through elastic scaling—adding compute and memory on demand as volume grows.
Designing real-time streaming data architectures that scale is essential to maintain consistent performance under variable workloads.
Failures are inevitable, but downtime isn’t. Distributed coordination, automatic retries, and checkpointing keep streams alive even when nodes fail. Exactly-once delivery ensures that no event is processed twice, and none are lost along the way.
Ordering guarantees and consistency
Order matters. Processing events out of sequence can destroy meaning. Real-time systems preserve temporal ordering through sequence IDs, partitioned topics, and consistent clocks.
Combined with idempotent operations, this guarantees that results stay accurate even during retries or restarts.
Observability and replay
You can’t fix what you can’t see. Observability gives engineers real-time visibility into throughput, latency, and stream health. Tracing tools follow a single event through every hop in the pipeline, making debugging fast and precise.
Sometimes you need to go back in time. Replay mechanisms let teams reprocess historical streams to apply new logic or recover lost state. Checkpointing ensures the system can resume exactly where it left off after a failure.
Correlation and pattern detection at scale
Real-time pipelines can detect patterns that span thousands of concurrent streams. They don’t just count or average—they understand context.
By correlating events across time and source, they can surface anomalies, detect trends, and trigger actions automatically. This is how systems identify DDoS attacks, sudden traffic drops, or behavioral shifts as they happen, not after.
Event-driven automation loops
Every event can lead to another. A system alert can trigger a scaling operation; a fraud flag can block a transaction; a new data point can refresh a dashboard.
These event-driven loops connect analytics directly to automation. Over time, they evolve into self-optimizing systems where outcomes continuously adjust to live feedback.
Security and governance in motion
Processing live data requires strict control. Encryption, authentication, and fine-grained access permissions must operate as fast as the data itself.
Compliance demands auditability—the ability to trace how every event was used and when. Real-time doesn’t mean reckless; it means secure by design.
Predictive and proactive intelligence
The logical next step after reacting in real time is predicting what comes next. By combining streaming data with online machine learning, systems can detect trends early and automate preemptive actions.
Predictive fraud detection, demand forecasting, and maintenance alerts are all outcomes of this approach. It’s the point where “real-time” becomes “ahead of time.”
Building trust in milliseconds
Reliable real-time architectures build trust through consistency. Every query, every event, every user interaction happens fast and correctly—every single time.
This is how modern data teams deliver experiences that feel instantaneous and dependable, whether it’s a dashboard updating live or an API returning data that’s only milliseconds old.
Examples of Real-Time Data Processing
Some examples of real-time data processing include:
- Real-time fraud detection
- Real-time personalization
- Real-time marketing campaign optimization
- Real-time anomaly detection
Real-time fraud detection is a great example of real-time data processing. A real-time fraud detection engine ingests a financial transaction event, compares transaction metadata against historical data (sometimes using online machine learning) to make a fraud determination, and exposes its determination to the point of sale or to ATMs within milliseconds.
Real-time fraud detection is a great example of real-time data processing at work.
This is distinctly a real-time data processing example because of its requirement for maintaining state. Real-time fraud detection systems must maintain long histories of transaction data which are used to train and update online feature stores or heuristical models that perform the real-time data processing as transactions stream in. They support streaming data ingestion and low-latency, high-concurrency access.
Real use cases for real-time data processing
Real-time data processing has wide adoption across many industries. Some examples of real-time data processing can be found in:
- Real-time personalization on e-commerce websites
- Real-time operational analytics dashboards for logistics companies
- User-facing analytics dashboards in SaaS
- Smart inventory management in retail
- Anomaly detection in server management
… and many more such use cases. Let’s dig into more detail on how real-time data processing plays a role in these industries.
Real-time personalization in e-commerce
Real-time personalization is a means of customizing a user’s online experiences based on data that is collected in real time, including data from the current browsing session.
A classic real-time personalization example involves eCommerce websites placing customized offers in front of a visitor during browsing or checkout. The customized offers might include products that closely match items that the visitor viewed or added to their cart.
Achieving this use case requires real-time data processing. The data from the user’s browsing session must be captured and processed in real-time to determine what kinds of personalized offers to place back into the application during their active session.
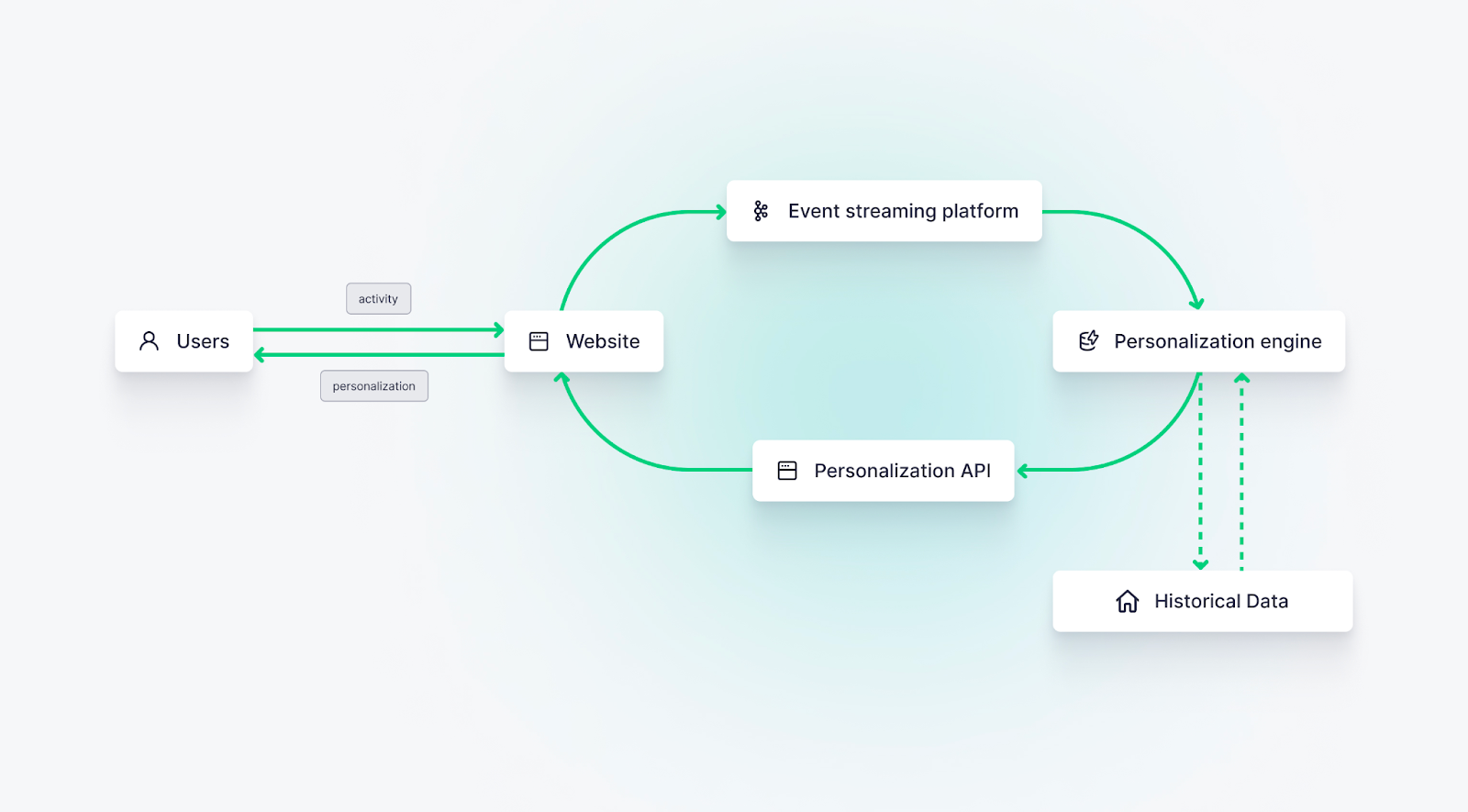
The entire process, from ingestion to personalization, can take only a few seconds, at most.
Operational analytics in logistics
Consider an airline company seeking to track luggage across a network of airplanes, airports, and everywhere in between. A real-time data platform can use real-time data processing to analyze streaming data from IoT sensors and “tags on bags”. This data is used to update real-time dashboards that help airline staff keep track of baggage, handle passenger offloading events or gate changes, and other last-minute requirements in a busy airport terminal.
User-facing analytics in SaaS
One of the most common applications for real-time data processing is user-facing analytics, sometimes called “in-product analytics” or "embedded analytics".
SaaS users often want analytics on how they and their teams are utilizing the software, and user-facing analytics dashboards can provide that information.
However, if the data is out of date, then the user experience suffers. Real-time data processing makes it possible for SaaS users to get up-to-date analysis on their usage in real time.
Smart inventory management in retail
Related to real-time personalization, smart inventory management involves making faster, better decisions (perhaps even automated decisions) about how to appropriately route product inventory to meet consumer demand.
Retailers want to avoid stockout scenarios - where the product a user wants to buy is unavailable. Using real-time data processing, retailers can monitor demand and supply in real time and help forecast where new inventory is required.
This can result in a better shopping experience (for example by only showing products that are definitely in stock) while also allowing retailers to reroute inventory to regional distribution hubs where demand is highest.
Anomaly detection in server management
Direct Denial of Service (DDoS) attacks can bring down a server in a heartbeat. Companies that operate hosted services, ranging from cloud providers to SaaS builders, need to be able to detect and resolve DDoS attacks as quickly as possible to avoid the collapse of their application servers.
With real-time data processing, they can monitor server resources and real-time requests, quickly identify DDoS attacks (and other problems) through real-time anomaly detection, and shut down would-be attackers through automated control systems.
Real-time Data Processing Reference Architectures
If you’re trying to build a real-time data platform, real-time data processing will serve an essential role.
Every real-time data processing architecture will invariably include real-time data ingestion, often through the use of an event streaming platform like Kafka. In addition, some form of stream processing engine or real-time database will be used to transform the data in real time. Finally, a low-latency API layer will be used to expose data in various formats and power user-facing analytics, automation, and real-time visualization.
Below you’ll find some common reference architectures for real-time data processing.
The user-facing analytics architecture
In this reference architecture, events are captured through an event bus such as Apache Kafka and ingested into a real-time database, which is responsible for real-time data processing. Application users interact with real-time analytics produced by the database using a low-latency, high-concurrency API.

The operational analytics architecture
In this reference architecture, events are captured and stored in a real-time database by the same method as above. In this example, however, it is not users who access real-time analytics through an API, but rather operational automation systems that utilize real-time data processing to initiate software functions without human intervention. The real-time database is also used in a way that is functionally similar to (though not the same as) stream processing, preparing data for batch processing in a data warehouse.

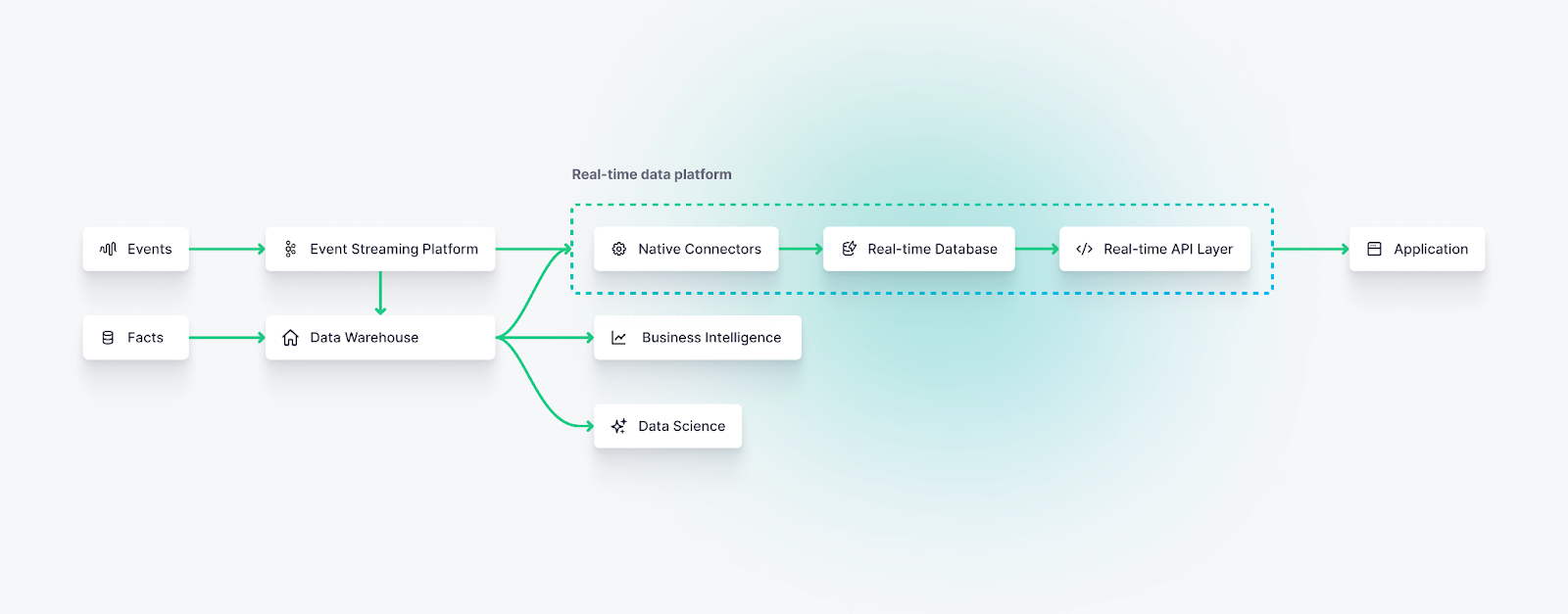
The real-time data platform architecture
In this architecture event streams and fact tables are ingested into a real-time data platform, which integrates real-time data ingestion (through native data connectors), a real-time database, and a real-time API layer into a single functional interface.
In parallel, the data warehouse supports batch data processing for business intelligence and data science workloads.
Real-Time Data Processing Tools
As mentioned above, real-time data processing involves some combination of event streaming, stream processing, real-time databases, real-time APIs, and real-time data platforms.
Event Streaming Platform
You can’t have real-time data processing without real-time data ingestion, and event streaming platforms are the go-to technology here.
Some examples of event streaming platforms include:
Stream Processing Engines
Stream processing engines may or may not be utilized in real-time data processing. In the absence of a real-time database, a stream processing engine can be used to transform and process data in motion.
Stream processing engines are able to maintain some amount of state, but they won’t be able to leverage a full OLAP as do real-time databases.
Still, they can be an important part of real-time data processing implementations both with and without real-time databases.
Some examples of stream processing engines include:
Real-time databases
Real-time databases enable real-time data processing over unbounded time windows. They often support incremental materialized views. They support high write frequency, low-latency reads on filtered aggregates, and joins (to varying degrees of complexity).
Some examples of real-time databases include:
Real-time API layer
Real-time data processors must expose transformations to downstream consumers. In an ideal world, this happens through a real-time API layer that enables a wide variety of consumers to access and utilize the data concurrently.
Real-time data platforms
Real-time data platforms generally combine some or all of the components of a real-time data processing engine.
For example, Tinybird is a real-time data platform that supports real-time data ingestion through its HTTP streaming endpoint or native Kafka connector, real-time data processing through its optimized ClickHouse® implementation, and a real-time, SQL-based API layer for exposing real-time data products to consumers.
How to get started with real-time data processing
If you’re looking for a platform to handle real-time data processing integrated with streaming ingestion and a real-time API layer, then consider Tinybird.
Tinybird is a real-time data platform that handles real-time data ingestion and real-time data processing. With Tinybird, you can unify both streaming and batch data sources through native data connectors, process data in real-time using SQL, and expose your processed data as scalable, dynamic APIs that can integrate with myriad downstream systems.
For more information about Tinybird, dig into the product, check out the documentation, or try it out. It’s free to start, with no time limit or credit card needed. If you get stuck along the way, you can join our active Slack community to ask questions and get answers about real-time data processing and analytics.