


In the vast universe of data storage and manipulation, the quest for efficient text search methods constantly challenges even the most experienced data engineers. Text-based data presents a very unique set of problems, especially when you need to check if the text is contained within some text (and you need to do this in real-time!). The contents of this blog post describe an exploration our team did that was born out of a challenging use case presented by one of our customers. They had billions of rows of log-based text data and wanted to know how they might scour through this data without having to do a full scan every time.
Tinybird is built on ClickHouse® and helps data teams build scalable real-time data products by enabling them to unify all their data, develop real-time transformations with SQL, and surface data products to their entire organization through auto-generated high-concurrency, low-latency APIs. We have a number of in-house experts in ClickHouse® and are often frequent contributors to open-source ClickHouse® as well. As such, we often help customers like this improve performance and lower their costs through ClickHouse® query performance.
Read on for more information about how Bloom filter text indexes can be used to optimize real-time text search in ClickHouse®. And if you’re interested in joining our team, please check our careers page and apply.
If you’d like to try out Tinybird, we have an always free plan that will get you started. You can build your first real-time data API in minutes.
The problem
Conventional wisdom posits that text search without any unique provisions will invariably entail a full scan, an approach akin to looking for a needle in a haystack.

Undoubtedly, full scans are anything but efficient, causing undue strain on your system's resources, stalling productivity, and increasing your compute costs.
Moreover, the standard indexing techniques provided by ClickHouse®, such as Primary or Sorting Keys, aren't particularly suitable for or flexible enough to handle text-based searches using clickhouse bloom filter and bloom filter clickhouse technologies. The performance boosts they do offer are effectively relegated to specific text search use cases like exact matches or matching the beginning of the text—cases where you can leverage alphabetical sorting of the text you're searching.

If you need to achieve more complex use cases like substring matching, these indexing techniques won’t help. You need to use something different to avoid full scans.
The solution
This is where ClickHouse®'s "Data Skipping Indexes" come into play. These specialized indexes can be used to massively improve the performance of text searches on ClickHouse®. The magic of Data Skipping Indexes lies in their structure—they contain relevant information about what's contained within a certain granule (or multiple granules) of the table. The granularity size, dictated by the engine settings, allows for more efficient data processing, effectively making it possible to bypass the arduous full scan approach.
In this post, I will delve into the intricacies of using Data Skipping Indexes. In particular, I'll explain the implementation of clickhouse text search optimization with Bloom filter indexes with ClickHouse®, and how they can be the game-changer for text search. I will also walk you through the results of a performance test we ran using real data.
What is a Bloom filter? 🚀
Among all the Data Skipping Indexes available in ClickHouse®, there is one that we’re looking at specifically in this post: the Bloom filter "family". These indexes are based on Bloom filters, which are a probabilistic data structure used to determine if an item is in a set of elements.
The probabilistic part means that if an element is in the set, the response is "Maybe the element is in the set", but if it is not, the response is "It's definitely not in the set". This means that there can be false positives (i.e., "Maybe the element is in the set", but when you actually check it, it turns out that it isn't present).
Bloom filters work by utilizing a fixed-size bit array and multiple hash functions. When an element is inserted into the filter, the hash functions generate a set of positions in the array, and those positions are set to 1. To check if an element is in the filter, the hash functions are applied to the element, and if any of the corresponding positions in the array are not set to 1, then the element is definitely not in the filter. However, if all positions are set to 1, it is possible that the element is in the filter (although there is a chance of a false positive).
Let’s explore how this works with a concrete example. Imagine we created a Bloom filter of 3 bits and 2 hash functions and inserted the strings "Hello" and "Bloom" into the filter. If the hash functions match an incoming value with an index in the bit array, the Bloom filter will make sure the bit at that position in the array is 1. Take a look at this gif:
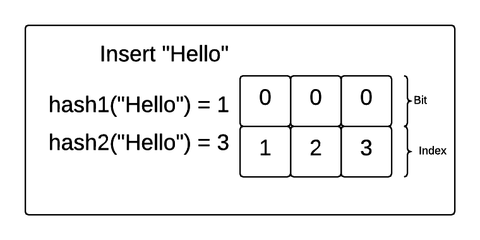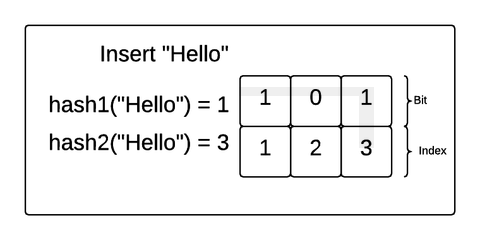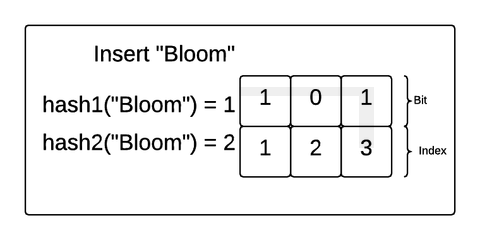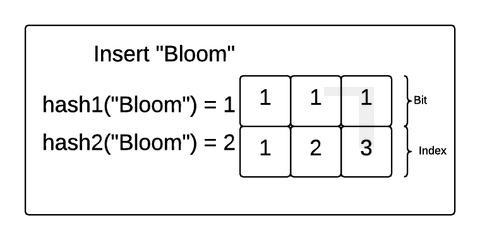
In this example, "Hello" was hashed to 1 by the first hash function and 3 by the second hash function. So, the Bloom filter made sure the bits at index 1 and 3 were flipped to 1. Then, "Bloom" was hashed to 1 and 2. The Bloom filter made sure those were both a 1 as well (even though position 1 already had a 1).
When you query in a Bloom filter, the key gets hashed with each of the hash functions. If the output bits of the hashed key are all 1, they would probably exist in the element set. If any of them is a 0, we know for sure that the key we are searching for is not in our list.
Bloom filter use cases
Today, Bloom filters are widely used across many technologies including databases, networks, and distributed systems. They serve to reduce the need for expensive disk or network operations, thus improving performance. For example:
- Databases may use Bloom filters to avoid costly disk reads when searching for nonexistent keys.
- Web browsers utilize them to check URLs against a list of malicious websites.
- Web applications use them to determine whether a user ID is already taken.
- Recommendation engines use them to filter out previously shown posts.
- Spellcheckers use them to check words for misspellings and/or profanity.
Bloom filters in ClickHouse®
Alright, so you can probably see where this is going by now. In this case, you want to use a Bloom filter in ClickHouse® to check if the text you are looking for might be in the table.
Done! Well, not quite. The "element in set" operation doesn't seem very useful on its own, since usually the text search isn't "search for an exact match of this text", it's usually more "search for strings that contain this substring within them".
For example, if you want to buy a car, you likely won’t begin your search with FIAT Fiorino Cargo Base 1.3 Mjet 80cv E6. You would probably start by searching for something like fiat fiorino, and look around the results a bit (now Google is going to shower me with car ads).
Text processing 📖
In order to achieve this in ClickHouse®, you need to take one additional step in order to be able to use this "element in set" operation and get the kind of search that you need: splitting the text into chunks that can be processed through the Bloom filter.
ClickHouse® currently offers two ways to do this. Each of them involves splitting the text using different certain criteria, and both have an effect on the searches that you will be able to perform. The data that results from splitting the text is what you use to build the sets of items present in a granule (or granules).
Tokenization
The first of these is tokenization. This basically means splitting the text using any kind of whitespace (blank spaces, dashes, punctuation marks, etc.) as delimiters, attempting to isolate whole words. This presents a problem for text-based searches.
Since tokenization targets whole words, the performance gains it offers when used for Bloom filters will only apply to searches where you’re looking for whole words surrounded by whitespace. It would work for your “fiat fiorino” search, but not for searches where you want to find all text with particular prefixes or suffixes, for example.
Tokenization can be useful in some cases, but it’s too limited for more complete text searches. This was especially true for our customer’s use case, where their log data was not strictly "natural language", making whitespace delimiting unreliable.
n-grams
The second (and more interesting) option is n-grams, which basically means that the text is split into groups of n consecutive characters. Imagine a string of text flowing from left to right, with an 'n-gram window' of size 4 moving across the text, one character at a time. Here's how that might look for your example text "Hello_world!":
This means that for the text "Hello_world!", the resulting 4-grams (n=4) would be:
Each of these 4-grams can be used as a separate index entry in the database, providing a highly granular, and thus very efficient, means of indexing the text.
The only limitation is that a search for a substring has to include at least n characters, in this case, 4, to ensure a match is found within the indexed 4-grams. For example, searching for a three-character substring such as 'wor' might not yield a result, since it is not long enough to match any of the 4-grams.
The devil is in the details 😈 How to configure ClickHouse’s Bloom filter
ClickHouse’s n-gram Bloom filter looks like this:
This means that:
- The type of Bloom filter index is ngrambf
- The n-gram window size is 4
- The size of the Bloom filter is 1024 bytes
- The number of hash functions is 1
- Skipping index granularity is 1 (this is why I kept writing "granule or granules"; in this case, each entry of the index has data from 1 granule, with the default settings, meaning 8192 rows)
The idea here is that a bigger Bloom filter/element set and/or a higher number of hash functions will return fewer false positives, but conversely, each evaluation will be more expensive (so creating a huge Bloom filter with a lot of hash functions is generally not a good idea).
The number of false positives also depends on the total number of elements in the set (each element is a 4-gram), but the number of elements in the set depends on the number of rows that go into each entry of the index, and that's affected by the granularity setting. The fewer total elements, the better, with the downside of having to do more evaluations for each search.
As you can probably tell, there are lots of factors at play here, and they interact heavily with each other, so the best way to decide these numbers is to actually try a lot of them, and decide what works best in a set of scenarios that you are interested in.
In this case, we did some of the work for you and ran a performance test to determine which n-gram configuration would work best for a specific use case.
Performance gains 💪
And now what you've been waiting for since the first sentence of this post: a ClickHouse® performance comparison between the default text search and Bloom filters for searching for text values in logs.
Test conditions:
- A sub-sample of all log data from the last 10 days from this customer’s dataset ended up being about ~130GB of uncompressed log data. This data was selected as a representative sample of what a worst-case scenario query would scan.
- We then performed a search over all this log data for the term "lambda". This was a somewhat uncommon term, with only around 230 occurrences in the dataset.
- Finally, we recorded the query time, query scan, and size of the index vs the size of the column.
Settings used in testing:
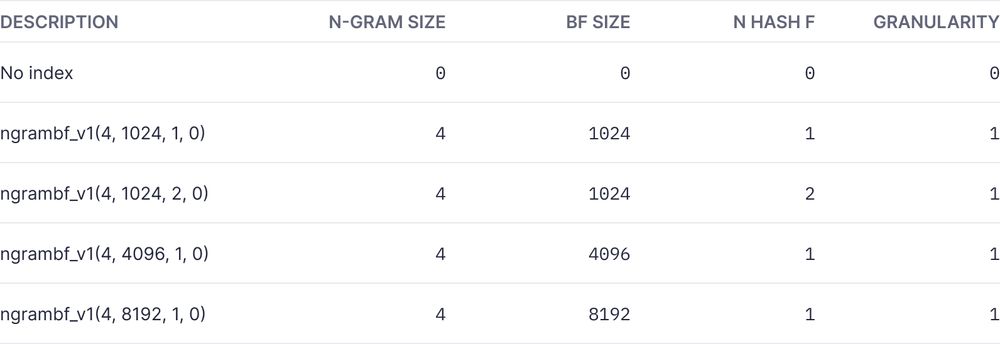
The results:
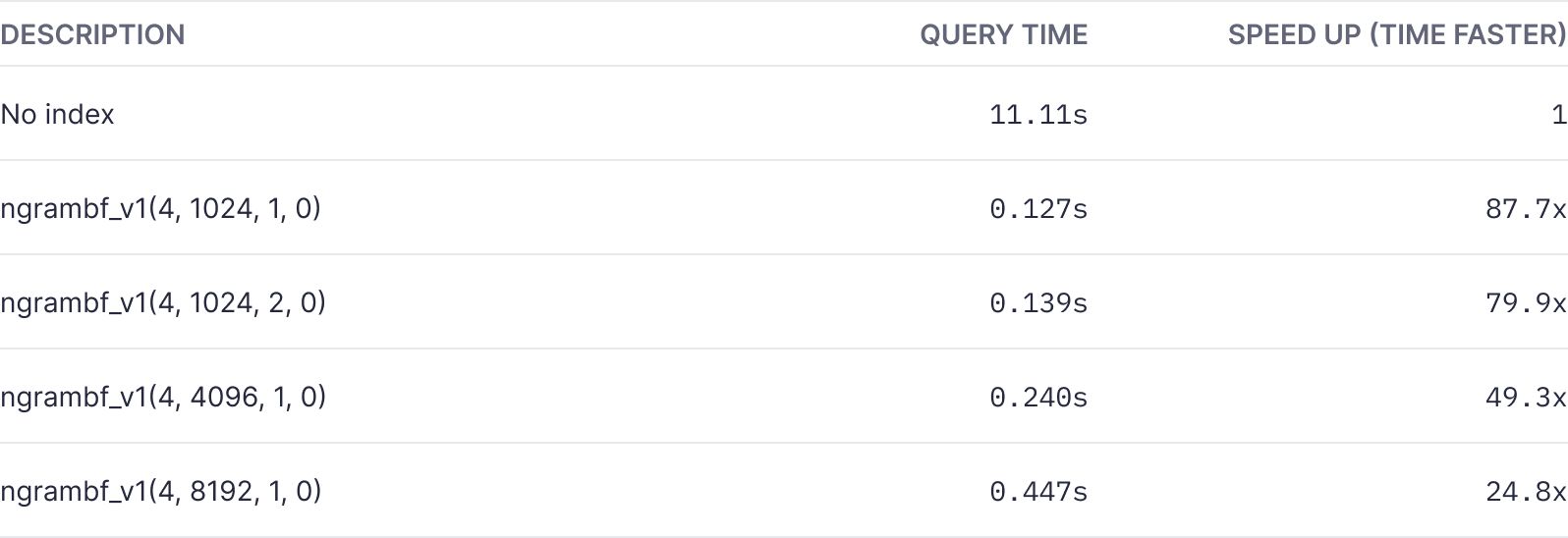
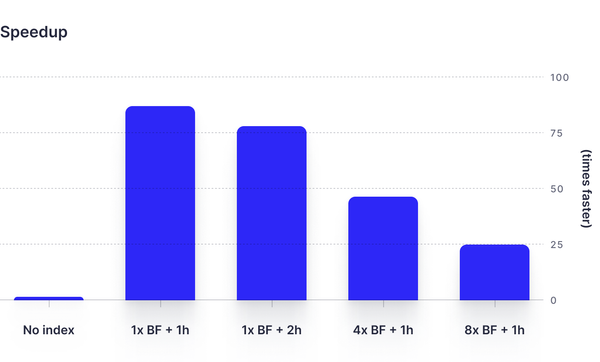
Speedup:
Here you can see the amount of time the query took to run for each Bloom filter configuration, compared to a non-indexed query time.
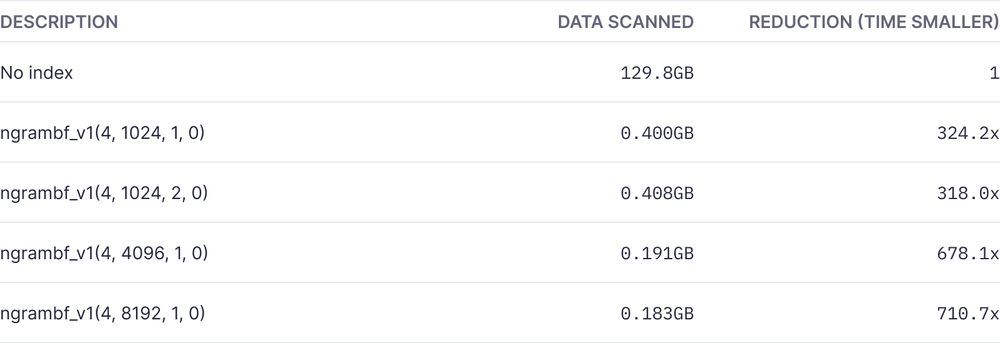
Scan size:
Here you can see the amount of data scanned for each Bloom filter configuration, compared to a non-indexed scan.
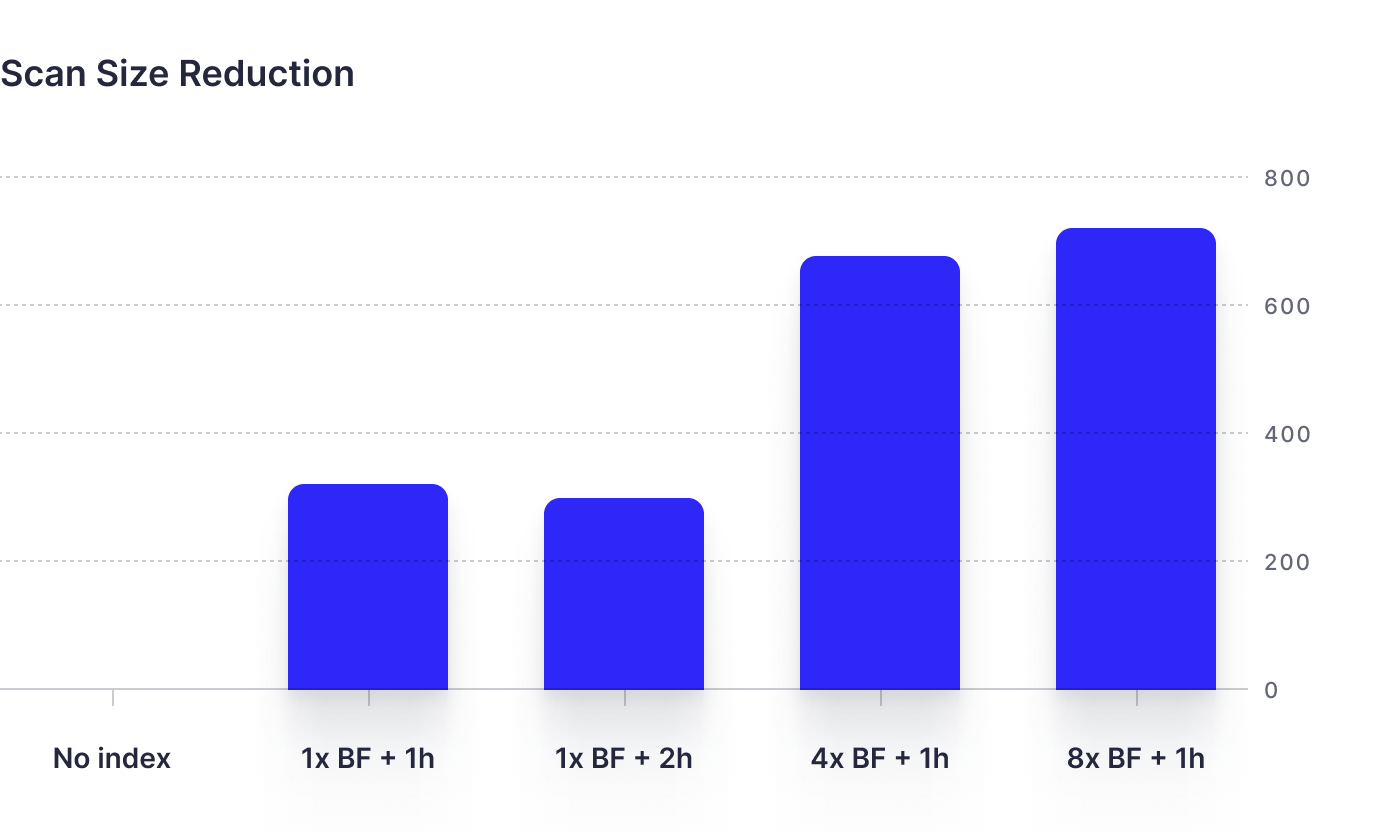
Combined results: Query time and scan size
Here you can see the tradeoffs between query time and scan size for the different configurations.
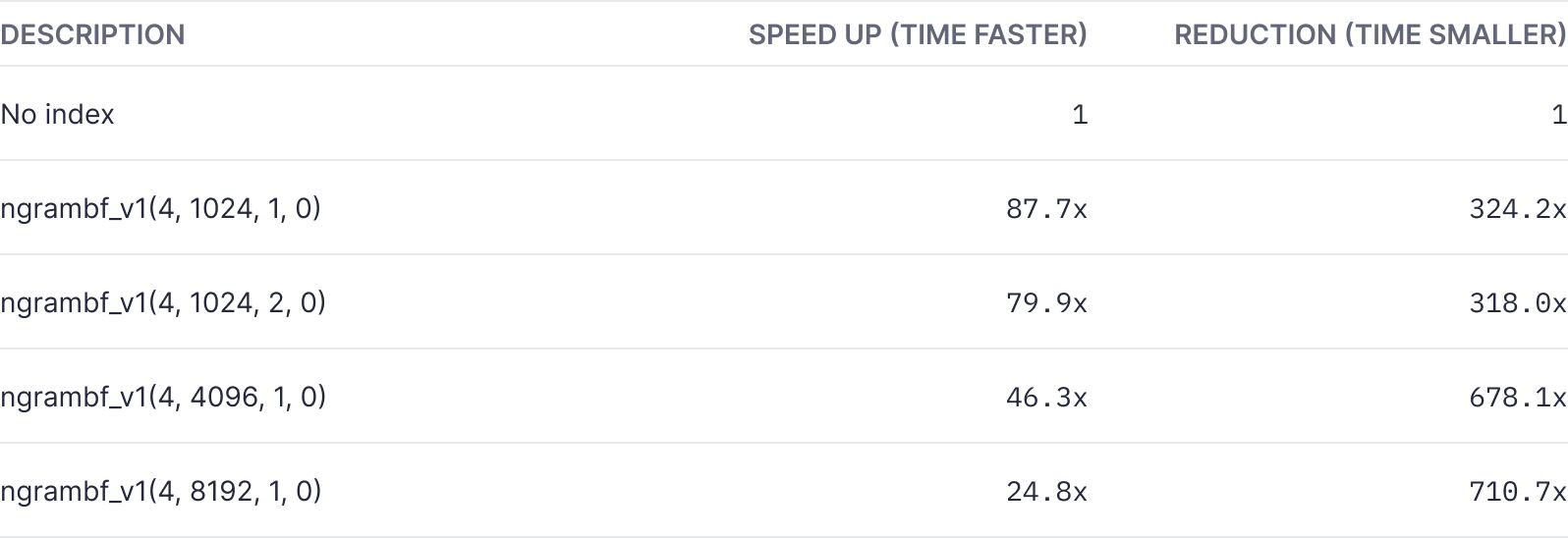
Storage used: Bloom filter index vs. actual data
To understand the tradeoff of storing the Bloom filter, this chart shows how much compressed data storage the Bloom filter index occupied versus the compressed storage of the actual data.
Our conclusions from this performance test
tl;dr: Bloom filters significantly boost ClickHouse®'s search efficiency for uncommon terms, as shown in our tests of log data. While a Bloom filter notably speeds up query times and reduces the amount of data scanned, it also increases storage needs. We found that optimal configuration depends on balancing performance enhancement and storage cost for each use case.
From our tests of ~130GB of log data, we found that Bloom filters can significantly enhance ClickHouse®'s search capabilities, particularly when searching for uncommon terms. Applying a Bloom filter to the search for the term "lambda" led to drastic reductions in query time and scan size across various configurations. Notably, for our dataset, the ngrambf_v1(4, 1024, 1, 0) configuration delivered an impressive speedup, with a query time approximately 88 times faster than a non-indexed search, while reducing the scanned data by a factor of 324.
However, these improvements come with the cost of increased storage. For instance, the ngrambf_v1(4, 8192, 1, 0) configuration increased storage by around 32% of the column size. Moreover, while the ngrambf_v1(4, 8192, 1, 0) configuration provided less of a speedup factor (around 25 times faster), it achieved the greatest reduction in scanned data.
Since our customer favored speed over reducing scan size, and storage increase was not a critical issue, they ultimately chose the ngrambf_v1(4, 1024, 1, 0).
These results underscore the importance of identifying the right balance based on your specific needs. They also highlight the potential of Bloom filters to substantially improve the efficiency of searches within ClickHouse® but with consideration of the trade-off in storage and specific use-case requirements. And finally, (and most importantly), there is no one-size-fits-all configuration for Bloom filters. We encourage you to conduct performance tests on your own data to determine the optimal settings for your specific needs.
How to create a Bloom filter index in ClickHouse®
If you’re this far, and you’re ready to speed up your text searches, we will walk you through the steps required to create a Bloom filter index in ClickHouse®.
1. Create an index:
This command creates a new Bloom filter index on a specified column in your database. The TYPE ngrambf_v1(4, 1024, 1, 0) indicates the type of index (n-gram Bloom filter) and its parameters (n-gram size, Bloom filter size, number of hash functions, seed value). The GRANULARITY 1 specifies the index granularity level, meaning an index entry will be created for each row of data.
2. Materialize the index:
This command forces ClickHouse® to build the index for the existing data in the table. By default, an index in ClickHouse® only starts working for the data inserted after the index creation. So, MATERIALIZE INDEX is necessary to apply the index to the pre-existing data. (This is similar to populating a Materialized View in Tinybird).
3. Drop the index:
This command removes the previously created index (your_index_name) from the table your_table in the database your_database. This might be useful if the index is no longer needed or if it's taking up too much space.
What are the disadvantages of using a Bloom filter?
While Bloom filters provide significant advantages in terms of memory efficiency and speed, they also come with certain limitations.
- First, they don't support the deletion of elements. The overlapping of bits by multiple elements makes it impossible to clear the bits corresponding to a particular item without risking false negatives.
- Another limitation is the unavoidable rate of false positives. Though it can be mitigated to some degree by increasing filter size or the number of hash functions, complete elimination of false positives is not achievable.
- Bloom filters on disk pose an operational inefficiency due to the necessity for random access. The hash functions yield random indices, leading to high latency during disk operations.
- The search functionality of Bloom filters is case-sensitive, requiring additional steps to deal with varying case inputs. However, you can easily workaround this by storing all elements in lowercase, but this can affect data integrity in some cases.
- Bloom filters can also be storage-intensive, ranging from an additional 5% to 30% of the column size based on your settings. This could have implications for systems with storage constraints.
- Additionally, the efficacy of Bloom filters declines with short queries. They require a minimum of a 4-character long string for search, making them less suitable for shorter terms.
Final thoughts
Searching through large volumes of text-based data can be a complex and resource-intensive process. The standard full-scan approach, akin to finding a needle in a haystack, is impractical for real-time operations. While traditional indexing methods offer some relief, they often fall short when dealing with text data. This is where ClickHouse®'s Data Skipping Indexes, particularly Bloom filters, offer an efficient alternative. Bloom filters are probabilistic structures that check if an item exists in a set, thereby reducing expensive operations and enhancing performance.
The key to this efficient search process is text processing via tokenization and n-grams. Tokenization allows text to be broken down into manageable chunks, while n-grams create overlapping character clusters for more comprehensive search patterns. N-grams, despite being heavier, provide a more versatile approach, making them a critical part of the process.
Our tests on a sizable log data set revealed that Bloom filters significantly boost ClickHouse®'s text search efficiency. They reduce query time and scan size drastically, although they do require additional storage. The optimal configuration for Bloom filters depends on the specific use case and requires a balance between improved performance and increased storage costs. In essence, while Bloom filters provide a robust solution for text searches in ClickHouse®, thorough understanding and testing are key to unlocking their full potential.
Related blog posts and resources:
- https://systemdesign.one/bloom-filters-explained/
- https://altinity.com/blog/skipping-indices-part-2-bloom-filters
- https://clickhouse.com/docs/en/optimize/skipping-indexes
- https://chistadata.com/bloom-filters-with-clickhouse-use-cases/
- https://www.instana.com/blog/improve-query-performance-with-clickhouse-data-skipping-index/
FAQ about Bloom filters in ClickHouse®
What are ClickHouse®'s Data Skipping Indexes, and how do they improve text search?
ClickHouse®'s Data Skipping Indexes allow for a more efficient text search process. They contain information about what's within a specific granule of the table, allowing the system to skip unnecessary data and directly locate the relevant information.x
How does a Bloom filter enhance the efficiency of text searches in ClickHouse®?
A Bloom filter is a data structure that helps determine if an item exists within a set of elements. Its application in ClickHouse® can significantly speed up text searches as it can quickly check whether the searched text might be within a given set.
What is the difference between tokenization and n-grams in text processing for ClickHouse®?
Tokenization and n-grams are two methods of splitting text in ClickHouse®. Tokenization involves splitting text around whitespaces and punctuation, isolating whole words, while n-grams involve splitting the text into groups of n consecutive characters. The latter offers a more granular and effective approach for text searches.
How to configure ClickHouse®'s n-gram Bloom filter for optimal text search performance?
Configuring ClickHouse®'s n-gram Bloom filter involves setting parameters such as the size of the Bloom filter, the number of hash functions, and the skipping index granularity. Adjusting these parameters can help reduce false positives and optimize search performance. However, the ideal configuration largely depends on your specific data and use cases.
Does Tinybird support Bloom filters?
Currently, Bloom filter indexes are not generally available in Tinybird. However, we did enable them for this Enterprise customer. If you think you need a Bloom filter with your data in Tinybird, reach out to us in the Tinybird Slack community or through your dedicated Enterprise Slack channel.
How does a Bloom filter improve the efficiency of searching for uncommon terms in large datasets?
Bloom filters can greatly improve the efficiency of searching for uncommon terms in large datasets by reducing the need for expensive disk reads. It quickly determines whether the term might be present in the data set, allowing the system to bypass unrelated data.
What are the benefits and drawbacks of using Bloom filters in ClickHouse®?
Bloom filters can significantly speed up text searches and reduce the amount of data scanned in ClickHouse®. However, this comes with increased storage needs due to the nature of the Bloom filter data structure. It's important to find a balance based on specific requirements and storage capabilities.
Why is performance testing important when configuring Bloom filters in ClickHouse®?
Performance testing is crucial when configuring Bloom filters because it helps determine the optimal settings for your specific needs. It enables you to find the right balance between query speed, scan size reduction, and storage usage.
What is Tinybird?
Tinybird is a real-time analytics API platform that makes it easier to work with large amounts of data. It is designed to ingest, store, and analyze large datasets in real-time, providing users with the ability to gain insights and make data-driven decisions quickly and efficiently.
How does Tinybird use ClickHouse®?
Tinybird leverages the power of ClickHouse®, an open-source column-oriented database management system, as the underlying technology for data storage and management. ClickHouse®'s capability for high-speed data insertion and querying combined with Tinybird's analytical tools and intuitive API interface provide an efficient way to handle large volumes of data.