


Modern applications are built on fresh, accurate data. Solutions such as stock inventory management, real-time personalization, in-product analytics, online feature stores for machine learning, and much more, all depend on having access to real-time data. Data teams looking to enable these types of solutions often build and maintain streaming platforms at scale.
Building metrics and use cases on top of streaming data is always more difficult than most people expect. Use cases that require stateful real-time analytics are tough to implement.
Building metrics and analytics on top of streaming data is harder than most expect.
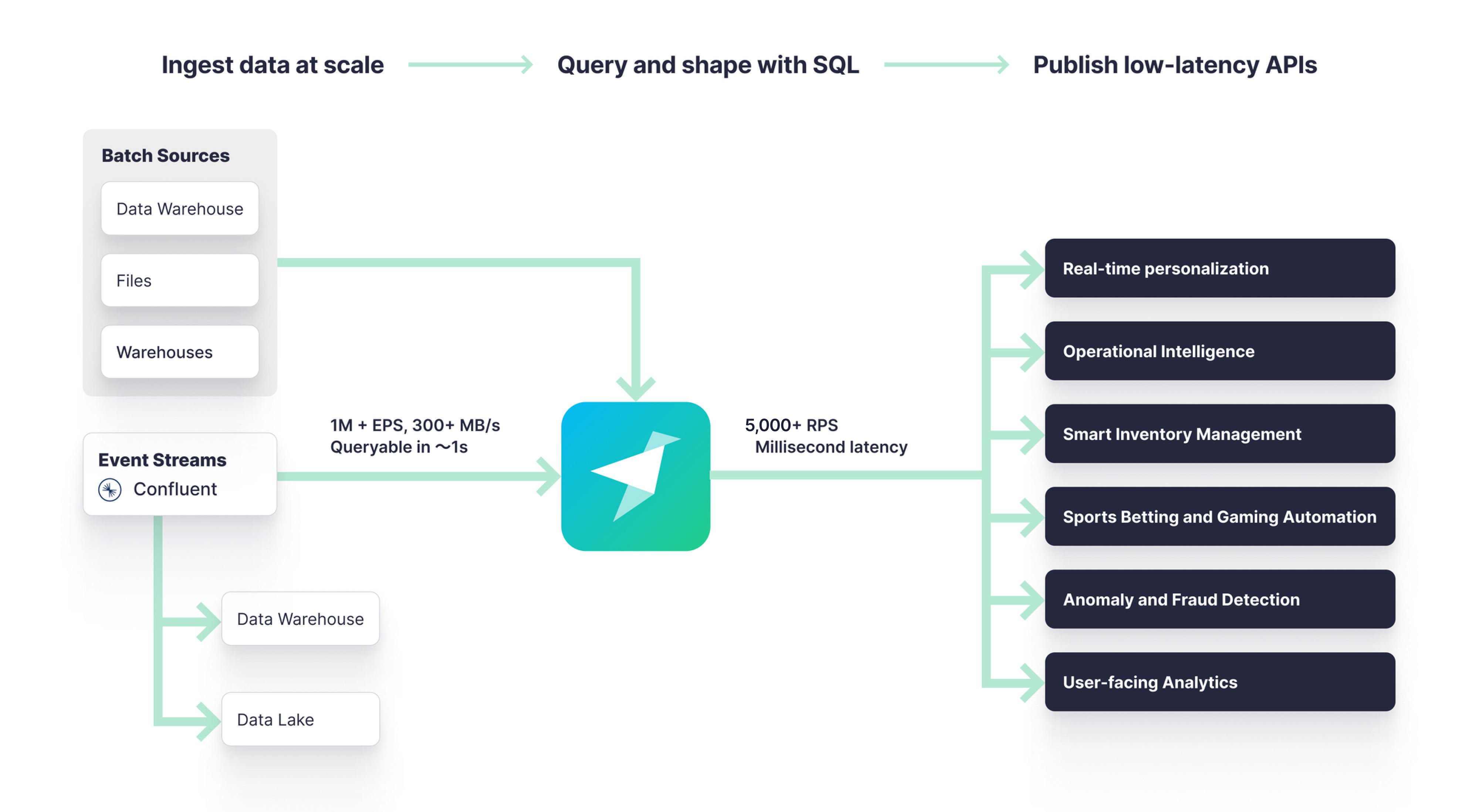
This is where Tinybird really shines: ingest your streaming data using built-in native Connectors, combine it with other data sources, develop real-time data pipelines using SQL, and publish your queries as high-concurrency, low-latency APIs for your entire development team to use.
To understand the true value of Tinybird, we must first appreciate the complicated nature of streaming data. It is generated continuously, often by multiple data sources, including applications, sensors, or cloud infrastructure. The most popular of these streaming data platforms is Apache Kafka®, and with Confluent Cloud, Kafka becomes much easier to set up, maintain, and scale.
As with all application architectures, the substantial benefits of streaming data need to be considered alongside their complexity:
- Volume and Velocity: Streaming data often involves handling vast amounts of data that are being produced rapidly and continually. Traditional data processing systems are not equipped to handle this level of data volume and speed.
- Durability and Reliability: Production-grade applications demand that data is not lost when processed in real time. Therefore, robust error handling, fault tolerance, and recovery mechanisms are necessary, which add to the system's complexity.
- Real-time Processing: Traditional batch processing is not suitable for streaming data, as it does not provide the real-time insights often required from streaming data. Often, it is necessary to implement complex event-based architectures.
- Data Governance, Quality, and Consistency: Streaming data can come from numerous sources, often with varying formats, quality, and reliability. Ensuring consistency and cleaning up "noisy" or "dirty" data in real time poses a significant challenge.
We built Tinybird as a perfect companion for streaming data platforms. Streaming data comes at you fast, and if you can’t process it fast enough, you’ll miss out on its value.
Tinybird is fast. Really fast. Built on ClickHouse®, the world’s fastest and most powerful real-time analytics database, Tinybird can scale and handle the volume and velocity of data that any streaming platform, including Confluent Cloud, can generate with the durability and reliability that production applications demand.
Real-time processing is a breeze with Tinybird. You ingest your data at scale, as it happens, and develop your queries using SQL, a language you already know. From there, you simply expose your queries as APIs, and everyone on your team has access to high-quality, consistent, well-documented data products.
Tinybird brings more real-time analytics use cases into reach, faster.
But Tinybird is more than a stateful streaming processing engine. Tinybird can ingest data from anywhere and even combine your batch and streaming data sources, enabling your data teams to unify their streams, files, tables, and more. You can bring your data together without custom scripts or additional tooling. It’s all included. For streaming data architectures, this means you can enrich your streaming data with business data and even other streaming data sources in minutes instead of the hours or days you’d normally spend spinning up your own middleware services.
Put simply, Tinybird brings more real-time analytics use cases into reach, faster, and opens up a world of real-time possibilities, making them easy, fast, and (dare I say) fun to build. Just connect your streaming and batch sources, model with SQL, and publish your metrics as low-latency APIs that scale.
Tinybird and Confluent are better together
Companies are continually adopting event-driven architectures, adding complexity for already strapped data and engineering teams.
Built by the original creators of Kafka, Confluent enables businesses to connect and process all of their data in real time with a cloud-native and complete data streaming platform available everywhere they need it—across clouds, on premises, and throughout hybrid environments.
Tinybird is the perfect complement to Confluent, making real-time analytics over streaming data at scale relatively effortless to build, empowering engineers to focus on differentiating real-time use cases without worrying about infrastructure and maintenance.
Tinybird is the perfect complement to Confluent, allowing engineers to build real-time use cases without worrying about infrastructure.
Announcing our partnership with Confluent
Today, we are thrilled to announce our participation in the "Connect with Confluent" program. This collaboration aims to make it even easier for Tinybird and Confluent users to analyze and process streaming data in real time.
By combining the power of Tinybird's real-time data platform with Confluent's robust streaming service, data engineers and developers can build new, highly-differentiated features and use cases even faster. We even built a dedicated Tinybird Confluent Connector to make it easier for Confluent Cloud users to master the real-time era.
By integrating Tinybird with Confluent, businesses can leverage the strength of both platforms.
You can get started with Tinybird for free. You don’t need a credit card, and there’s a generous free tier that should help you test your use cases. If you need help, join our Community Slack and one of our engineers can help you right away. Tinybird is beloved by developers and trusted by data teams everywhere.
Tinybird and Confluent have many shared customers who recognize the growing need to leverage streaming data, analyze it in real-time and at scale, and use it to build user-facing features that set their offerings apart. Together, Tinybird and Confluent massively simplify the process of working with big data in motion.
By integrating Tinybird with Confluent, businesses can leverage the strengths of both platforms. Tinybird's real-time analytics engine complements Confluent's streaming infrastructure by providing an intuitive layer for processing the freshest data and publishing high-concurrency, low-latency, SQL-based APIs. This integration allows organizations to tap into the full potential of their streaming data, enabling them to derive valuable insights faster and gain a competitive edge.
How to connect Tinybird with Confluent
To build real-time analytics over your Confluent data, start by signing up for a free Tinybird account. After that, follow these simple steps:
- Create a Tinybird Workspace
- Securely connect your Tinybird Workspace to your Confluent cluster with the Tinybird Confluent Connector
- Select your Confluent Topic and choose your ingestion pattern
- Define your schema and create your Confluent Data Source
As data streams to your Confluent topic, it will be immediately captured and stored in a Tinybird Data Source.
Tinybird is the fastest and easiest way to build real-time analytics APIs over Confluent data streams.
From there, you can query, shape, join, and enrich it with SQL Pipes and instantly publish your transformations as high-concurrency, low-latency APIs to power your next use case.
Conclusion
Tinybird's participation in the "Connect with Confluent" program opens up exciting possibilities for data and engineering teams who want to maximize the value of their streaming data. The integration of Tinybird's advanced real-time data platform with Confluent's robust streaming infrastructure empowers engineers to quickly build next-generation customer experiences powered by real-time data.
For more information about the Tinybird Confluent Connector, check out the documentation, or watch the screencast above. If you have questions about the Confluent Connector, please join our growing and active Slack community.