


Choosing between ClickHouse® and MariaDB ColumnStore often comes down to a single question: can MariaDB's columnar engine scale to the same performance levels as a database purpose-built for analytics? Both systems use columnar storage and claim to handle large-scale analytical workloads, but their architectures diverge in ways that matter for real-world performance.
This comparison examines how ClickHouse® and MariaDB ColumnStore differ in storage design, cluster architecture, query performance, and operational complexity to help you determine which database fits your analytical workload.
ClickHouse® overview
ClickHouse® is a columnar database built for analytical workloads where you’re aggregating, filtering, and scanning large amounts of data. Instead of storing data row-by-row like traditional databases, ClickHouse® stores each column separately, which means queries only read the columns they need.
This design makes ClickHouse® fast for analytics because most analytical queries touch a few columns across many rows. When you run a query that calculates the average price across a billion transactions, ClickHouse® reads just the price column instead of loading entire rows with customer names, addresses, and other fields you don’t need.
ClickHouse® was originally developed at Yandex to handle web analytics at massive scale. The database uses vectorized query execution, processing thousands of rows at once instead of one at a time. You can run ClickHouse® on a single server for smaller workloads or scale it horizontally across clusters using a shared-nothing architecture where each node owns its own data.
MariaDB ColumnStore overview
MariaDB ColumnStore is a storage engine that runs inside MariaDB, designed to handle analytical queries alongside MariaDB’s traditional transactional workloads. Think of it as an add-on that gives MariaDB columnar storage capabilities, similar to how InnoDB handles transactional data.
ColumnStore came from the InfiniDB project and was integrated into MariaDB to provide data warehousing features. You can have both InnoDB tables for transactions and ColumnStore tables for analytics in the same database server. However, the two storage engines remain separate, so you can’t join an InnoDB table with a ColumnStore table directly without moving data between them first.
Storage engine differences
How each database organizes data on disk determines most of its performance characteristics. Both systems use columnar storage, but they take different approaches to segmenting, indexing, and compressing that data.
Columnar segmentation in ClickHouse®
ClickHouse® stores data in a table engine called MergeTree, which breaks data into immutable parts. Each part contains data sorted by a primary key, and ClickHouse® merges parts in the background to keep query performance consistent. The primary key here isn’t unique like in MySQL; it’s more of a sorting key that determines how data is physically ordered on disk.
ClickHouse® uses sparse indexing, storing index entries for every 8,192 rows instead of every single row. This keeps indexes small and lets the database skip entire blocks of data that don’t match your query filters. When a query comes in, ClickHouse® checks the sparse index to figure out which data parts and granules to read, then scans only the specific column files it needs.
Extent mapping in ColumnStore
MariaDB ColumnStore organizes data into extents, which are fixed-size blocks of compressed columnar data. Each extent holds data from a single column, and in multi-node setups, extents get distributed across nodes. ColumnStore uses dictionary encoding for compression, replacing repeated values with smaller integer codes and storing the mapping separately.
An extent map tracks which extents contain which data ranges, allowing ColumnStore to skip irrelevant extents during queries. The extent-based approach is less granular than ClickHouse®’s sparse indexing though, which can mean reading more data than strictly necessary for selective queries.
Cluster architecture and scaling paths
ClickHouse® scales horizontally using a shared-nothing architecture where each node stores and processes its own subset of data. You create distributed tables that automatically route queries to underlying local tables on each shard. Each shard processes its data in parallel, then results get aggregated at a coordinator node, which can be any node in the cluster.
MariaDB ColumnStore supports multi-node deployments but uses a different architecture. A ColumnStore cluster separates user modules that coordinate queries from performance modules that store and process data. This separation provides some parallelism, but ColumnStore’s query coordination is less mature than ClickHouse®’s distributed execution, and adding nodes doesn’t always give you linear performance improvements.
Shared-nothing shards
In ClickHouse®, distributed tables are virtual tables that route queries to local tables on each shard. Each shard operates independently and processes queries in parallel, with no shared storage or coordination overhead during query execution. Any node can act as the coordinator, which eliminates single points of failure and allows for linear scaling as you add more nodes to the cluster.
Tiered storage with SSD and object store
ClickHouse® supports tiered storage policies that automatically move older data from fast local SSDs to cheaper object storage like S3. Hot data stays on fast disks for low-latency queries, while cold data gets archived to reduce costs. Queries can still access data in object storage, just with higher latency. This makes it economical to keep years of historical data without paying for expensive SSD capacity for everything.
Multi-node ColumnStore deployments
MariaDB ColumnStore’s multi-node architecture uses a primary user module to coordinate queries and distribute work to performance modules. Production environments require at least 64 CPU cores and 128 GB RAM to scale effectively. Performance modules store data locally and execute queries on their assigned data. While this provides some parallelism, ColumnStore’s query coordination doesn’t match ClickHouse®’s sophistication, and adding nodes often provides diminishing returns rather than linear scaling.
Data ingestion and mutation workflows
How you load data and handle modifications affects both operational complexity and query performance. ClickHouse® and MariaDB ColumnStore take different approaches here, reflecting their different design priorities.
Streaming inserts with Kafka or HTTP
ClickHouse® supports high-throughput streaming ingestion through multiple protocols: HTTP, native TCP, and connectors for Kafka, Kinesis, and other streaming platforms. ClickHouse® batches incoming inserts into parts automatically, merging them in the background to maintain query performance.
For real-time use cases, ClickHouse® can ingest millions of rows per second while maintaining sub-second query latency. The database handles deduplication through ReplicatedMergeTree tables and can guarantee exactly-once semantics when combined with proper ingestion patterns.
Batch bulk-load into ColumnStore
The cpimport utility loads data from flat files in bulk, which is faster than row-by-row inserts. For continuous data ingestion, you typically load data into InnoDB tables first, then periodically transfer batches to ColumnStore tables using SQL statements.
This batch-oriented approach adds operational steps compared to ClickHouse®’s streaming ingestion. You manage the staging process and schedule bulk loads, which introduces latency between when data is written and when it becomes available for analytics.
Handling updates and deletes
ClickHouse® doesn’t support traditional row-level updates or deletes. Instead, it provides lightweight delete and update operations that mark data for deletion or modification, with actual removal happening during background merges. For use cases requiring frequent updates, you can use ReplacingMergeTree or CollapsingMergeTree table engines that handle updates through insert-only patterns.
MariaDB ColumnStore supports SQL UPDATE and DELETE statements, but these operations are expensive because they require rewriting entire extents. Frequent updates or deletes can significantly degrade performance. For analytical workloads, both systems work best with append-only patterns where data is inserted once and rarely modified.
Query performance benchmarks
Multiple independent benchmarks have compared ClickHouse® and MariaDB ColumnStore on analytical workloads. While specific numbers vary based on hardware and query patterns, the general trend shows ClickHouse® outperforming ColumnStore by significant margins on most query types.
ClickHouse® outperforms MariaDB by orders of magnitude on ClickBench queries, suggesting it is better optimized for high-concurrency, real-time analytics use cases:
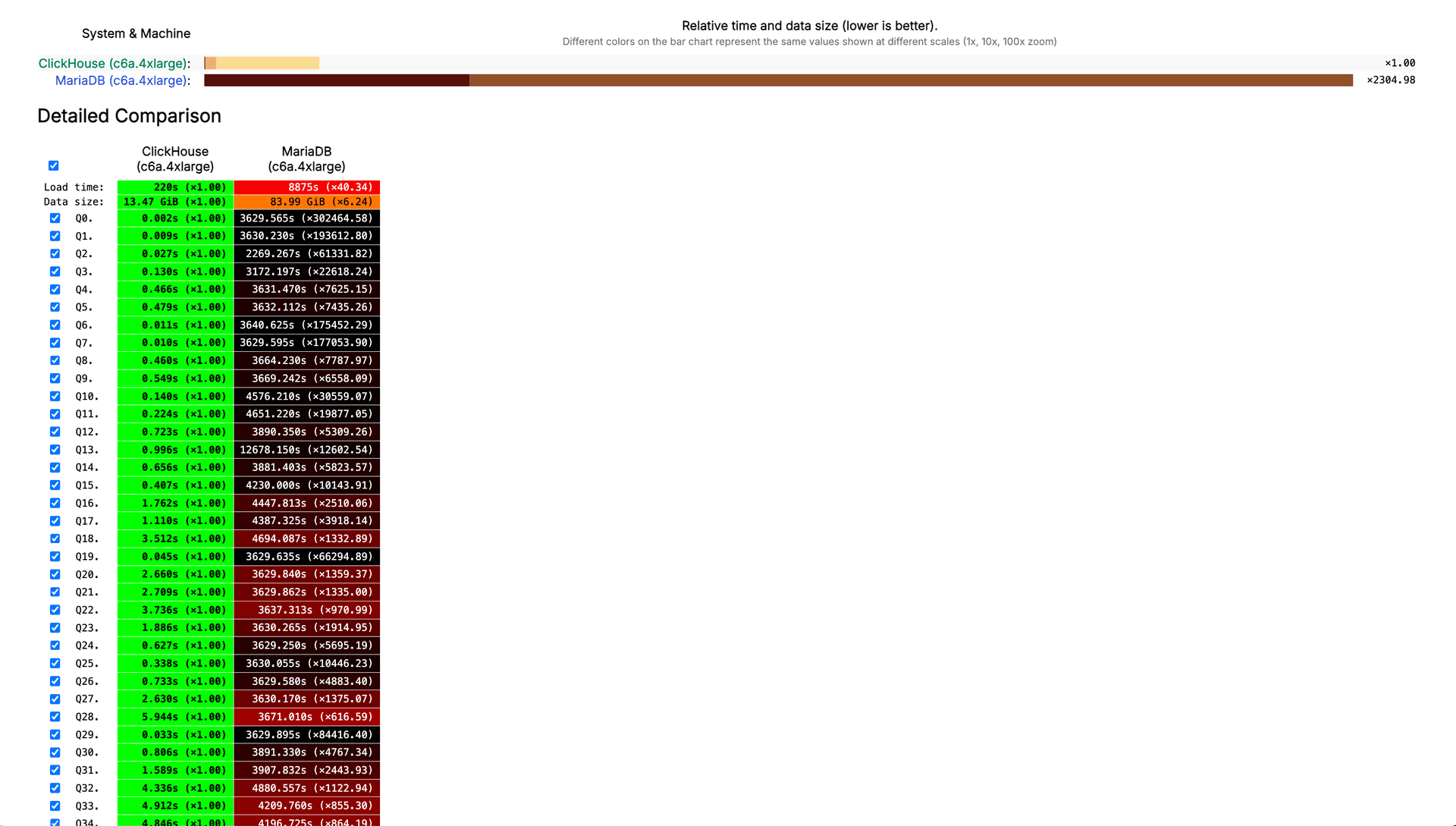
Star schema benchmark results
The Star Schema Benchmark tests OLAP query performance using a data warehouse schema with fact and dimension tables. Percona’s benchmark comparing ClickHouse® and ColumnStore on this workload showed ClickHouse® completing most queries faster, sometimes by 10x or more. ColumnStore performed better on a small number of queries involving complex joins, but ClickHouse®’s vectorized execution and better indexing gave it an advantage on aggregations and scans.
Time-series aggregation latency
For time-series workloads with high-cardinality data, ClickHouse®’s columnar compression and sparse indexing provide substantial performance advantages. Queries that aggregate metrics across time windows complete faster in ClickHouse® because it can skip irrelevant data more effectively. ColumnStore’s extent-based storage requires reading more data blocks, which increases query latency on selective time-range queries.
Concurrent dashboard scenarios
When multiple users run analytical queries simultaneously, both systems can handle concurrent load, but ClickHouse® generally maintains better performance under high concurrency. ClickHouse®’s query execution is more CPU-efficient due to vectorization, and its ability to use multiple CPU cores per query helps it serve dashboard queries with consistent latency. ColumnStore can struggle with query coordination overhead when many concurrent queries hit the cluster.
Compression and storage efficiency
Both ClickHouse® and MariaDB ColumnStore use columnar compression, but their compression algorithms and effectiveness differ. Compression matters because it reduces storage costs, decreases disk I/O, and can improve query performance by reducing the amount of data read from disk.
ClickHouse® supports multiple compression codecs:
LZ4: Fast compression and decompression with good compression ratios, suitable for most workloadsZSTD: Higher compression ratios thanLZ4with slightly slower decompression, good for cold dataDeltaandDoubleDelta: Specialized codecs for time-series data that exploit sequential patterns
You can specify different compression codecs for different columns based on their data characteristics. ClickHouse® typically achieves compression ratios of 10x or higher on real-world datasets, with some workloads seeing 30x compression or better.
MariaDB ColumnStore primarily uses Snappy compression, which prioritizes speed over compression ratio. While Snappy is fast to decompress, it generally achieves lower compression ratios than ClickHouse®’s more aggressive codecs. This means ColumnStore requires more storage space for the same data, which increases costs and can slow queries that need to read more data from disk.
SQL dialect and function coverage
Both systems support standard SQL, but with different levels of completeness and different extensions. MariaDB ColumnStore benefits from MariaDB’s mature SQL parser and supports full ANSI SQL including complex joins, subqueries, and window functions. ClickHouse®’s SQL dialect has some limitations and non-standard extensions, though it covers most common analytical query patterns.
ClickHouse® lacks full support for correlated subqueries and has limited support for certain SQL features like recursive CTEs. However, ClickHouse® provides specialized functions for analytical workloads that MariaDB lacks, such as advanced time-series functions, probabilistic data structures, and machine learning functions. For most analytical queries, ClickHouse®’s SQL dialect is sufficient, but applications requiring complex SQL logic may find MariaDB’s compatibility easier to work with.
When MariaDB ColumnStore performs better
MariaDB ColumnStore makes sense for organizations already invested in the MariaDB or MySQL ecosystem who need analytical capabilities without adopting a separate database. If you’re running transactional workloads on MariaDB InnoDB and need to add analytics, ColumnStore allows you to keep everything in one database server.
ColumnStore also works better for workloads that require frequent updates or deletes on analytical data. While these operations are still expensive in ColumnStore, they’re at least supported through standard SQL, whereas ClickHouse® requires workarounds. If your use case involves modifying historical data regularly, ColumnStore’s UPDATE and DELETE support may be worth the performance tradeoff.
For small to medium analytical workloads where query performance requirements are measured in seconds rather than milliseconds, ColumnStore provides adequate performance with lower operational complexity than running a separate ClickHouse® cluster. The ability to use familiar MySQL tools and the simpler learning curve can outweigh ClickHouse®’s performance advantages for teams without specialized database expertise.
Operational complexity in production
Running any distributed database in production requires operational expertise. Both ClickHouse® and MariaDB ColumnStore have operational considerations, but they differ in maturity, tooling, and complexity.
Backup and restore processes
ClickHouse® provides built-in backup functionality that can snapshot data to local disks or object storage. The clickhouse-backup tool from Altinity offers more advanced features like incremental backups and restoration to different clusters. ClickHouse®’s immutable parts make backups straightforward since data files don’t change once written.
Observability and alerting
ClickHouse® exposes detailed metrics through system tables that track query performance, resource usage, and cluster health. You can query these system tables just like regular tables to build custom monitoring dashboards. ClickHouse® also integrates with Prometheus, Grafana, and other monitoring tools through exporters.
Version upgrades and rolling restarts
ClickHouse® supports rolling upgrades where you upgrade nodes one at a time while the cluster continues serving queries. Replicas handle queries while their shard-mates are being upgraded. ClickHouse®’s versioning is generally stable, though major version upgrades sometimes require careful testing.
MariaDB ColumnStore upgrades can be more complex because of the tight coupling between user modules and performance modules. Upgrading a ColumnStore cluster often requires coordinated downtime, especially for major version changes.
Integrating ClickHouse® with existing MySQL stacks
Many organizations run MySQL or MariaDB for transactional workloads and want to add ClickHouse® for analytics without replacing their existing infrastructure. Several integration patterns allow you to use both databases together.
Replicating binlog into ClickHouse®
ClickHouse® can consume MySQL binary logs to replicate transactional data in real-time. The MaterializedMySQL database engine creates a replica of a MySQL database inside ClickHouse®, automatically converting InnoDB tables to ClickHouse® MergeTree tables. Changes in MySQL are reflected in ClickHouse® within seconds, allowing you to run analytical queries on near-real-time data without impacting your transactional database.
The MaterializedMySQL engine in ClickHouse® consumes binlog events automatically, so you write once to MySQL and the data appears in ClickHouse® without additional application code.
Serving APIs alongside OLTP
A common pattern is to use MySQL for transactional APIs that handle user writes and ClickHouse® for analytical APIs that power dashboards and reports.
This hybrid architecture lets you optimize each database for its workload. MySQL handles ACID transactions with row-level locking, while ClickHouse® handles high-throughput analytical queries with columnar scans.
Hybrid storage strategy
Some organizations use both MariaDB ColumnStore and ClickHouse® depending on the use case. ColumnStore might handle internal reporting where SQL compatibility and integration with existing MariaDB infrastructure matter more than raw performance. ClickHouse® handles customer-facing analytics where sub-second query latency is required.
This approach adds operational complexity since you’re running two analytical databases, but it allows you to match each workload to the most appropriate tool.
Tinybird for simplified ClickHouse® adoption
Managing ClickHouse® infrastructure requires expertise in distributed systems, query optimization, and operational best practices. Tinybird is a managed ClickHouse® service that handles infrastructure setup, scaling, and maintenance so developers can focus on building features rather than managing databases.
Tinybird provides a complete platform for integrating ClickHouse® into application backends:
- Managed ingestion: Handles data loading from streaming sources like Kafka and HTTP
- Auto-scaling clusters: Manages ClickHouse® clusters with automatic scaling based on workload
- REST API generation: Generates authenticated REST APIs from SQL queries without custom application code
- CI/CD workflows: Allows developers to define data pipelines as code and deploy with standard workflows
The platform eliminates common ClickHouse® operational challenges like tuning MergeTree settings, managing replicas, and monitoring query performance. Tinybird’s API layer adds authentication, rate limiting, and parameter validation automatically. For teams that want ClickHouse®’s performance without the infrastructure work, Tinybird provides the fastest path from data to production APIs.
You can create a free account at https://cloud.tinybird.co/signup and start building with ClickHouse® in minutes rather than weeks.
FAQs about ClickHouse® vs MariaDB ColumnStore
Can I run both engines without double-writing?
Yes, you can replicate MySQL transactional data to ClickHouse® using binlog replication while keeping ColumnStore for mixed workloads. The MaterializedMySQL engine in ClickHouse® consumes binlog events automatically, so you write once to MySQL and the data appears in ClickHouse® without additional application code. This approach avoids duplicating write operations across systems and keeps your transactional and analytical databases synchronized.
How mature is community support for MariaDB ColumnStore?
MariaDB ColumnStore has smaller community adoption compared to ClickHouse®, with fewer third-party integrations and community-contributed tools. ClickHouse® benefits from broader ecosystem support including connectors for most data platforms, extensive documentation, and active development. The ClickHouse® community is larger and more active, which means faster bug fixes, more frequent releases, and better resources for troubleshooting.
Does ClickHouse® support distributed transactions?
No, ClickHouse® does not support ACID transactions across multiple nodes, focusing instead on eventual consistency for analytical workloads. Each insert operation is atomic at the partition level, but ClickHouse® doesn’t provide distributed transaction coordination across shards. MariaDB ColumnStore offers better transactional consistency when integrated with MariaDB’s InnoDB engine, though ColumnStore tables themselves don’t support full ACID properties either.
/