

About the company
LocalStack enables tens of thousands of developers to spin up a light but fully featured cloud stack on their local machine, providing the same functionality and APIs as a real AWS cloud environment for local development and CI pipelines.
“We had some audacious goals for our product which we thought were unattainable with our capacity at the time. Tinybird made it possible.”
Thomas Rausch
Co-founder at LocalStack
Problem
LocalStack wanted to let users see real-time history of API calls made within their instance and aggregate anonymized data to understand product usage. Their simple MySQL data pipeline became a serious bottleneck as the user base grew to 10,000+ developers and 100,000+ instances. The usage dashboard took several seconds to load, and they had no room to scale for their planned open source telemetry.
Why Tinybird
LocalStack migrated from MySQL to Tinybird simply by exporting CSV files - data was in Tinybird in seconds. They built managed connectors to separate sessions and events, combining cold and hot data in real-time. Tinybird's "ingest > transform > expose" data flow made it easy to develop migrations for both batch and real-time data.
Results
- Instant migration. Data migrated from MySQL via CSV export in seconds.
- Unified product view. All events formatted uniformly across all products in a single view.
- No data engineers required. Founder built scalable data pipelines on his own before hiring any dedicated data engineers.
- Expanded use cases. Now combining product usage with GitHub issues to direct engineering resources.
1. About LocalStack
Tens of thousands of developers use LocalStack as part of their local development workflow or in automated CI pipelines. Using LocalStack, developers can spin up a light but fully featured cloud stack on their local machine that provides the same functionality and APIs as if they were developing in a real AWS cloud environment. If you rely on real AWS accounts just for testing, you should definitely give LocalStack a try!
2. Big goals... and an infrastructure problem
LocalStack wanted to let their users see the real-time history of API calls made within their instance so that they can make sense of how their cloud applications interact with the AWS API. Likewise, LocalStack wanted to anonymize and aggregate that data so they could better understand how their own product was being used. To do so, they built a simple data pipeline on top of their client usage data using a self-hosted MySQL database.
In the early days, this worked fine. But as the company and their user base grew to where it is now (10,000+ devs and 100,000+ instances), the database quickly became a serious bottleneck. The usage dashboard that customers relied on was taking several seconds to load, and the queries they used to aggregate data for their internal goals started to max out their infrastructure.
On top of that, LocalStack had a huge goal to open up anonymized telemetry recording for their open source product, which meant adding data from hundreds of thousands more machines to their data pipeline. The volume of data they'd add from their open source product was orders of magnitude higher than what they were already dealing with, and it was clear that their existing MySQL infrastructure wasn't going to keep up. There was simply no room to scale.
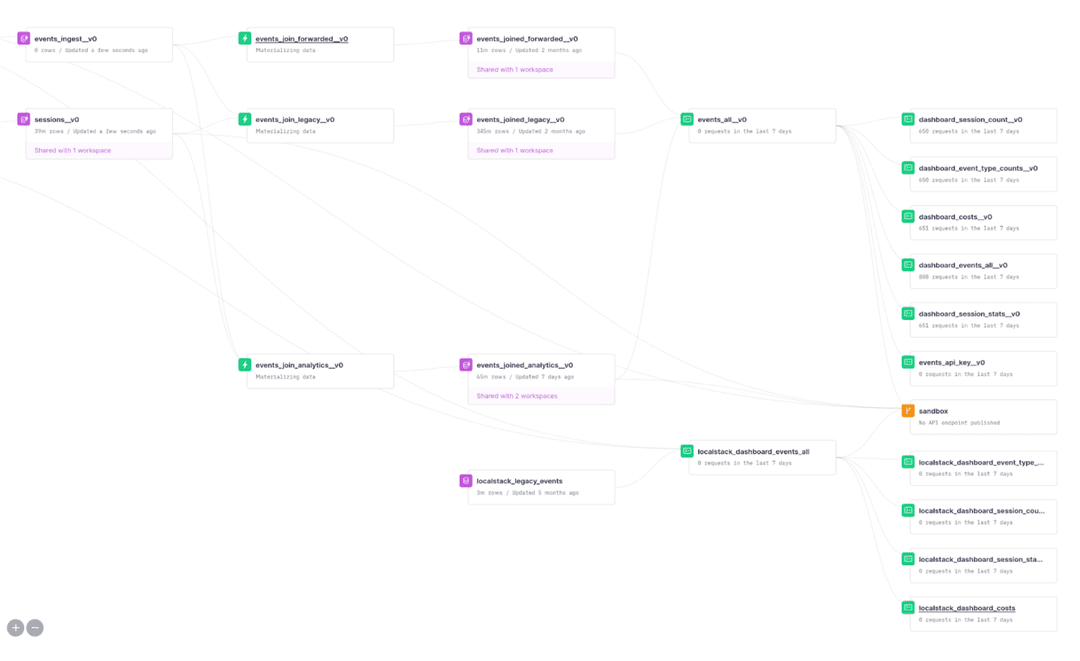
3. All the products in one realtime view
Thomas Rausch, Co-Founder at LocalStack, rallied his team to find performant ways to build the next iteration of their data analytics infrastructure. They wanted a solution that would scale out of the box, serve aggregation queries at low latency, and, importantly, allow for an easy and painless migration off of their existing pipeline. This is when they found Tinybird. They were able to migrate from their old database to Tinybird simply by exporting CSV files. The data was in Tinybird in seconds. Literally.
After the initial migration, Thomas and the team still had to reconcile data coming from older instances of LocalStack which were still sending events in a format that was tailored to their old MySQL database. Using Tinybird, they built a managed connector that separated sessions and events, so that they could combine cold data and hot data, all in real-time. Tinybird's "ingest > transform > expose" data flow made it a breeze to develop these migrations, which worked both for batch and realtime data. Now, all events are formatted uniformly in a single view, so the team can see how instances across all their products perform.
4. Tinybird is a perfect tool for small, fast teams
The best part for Thomas? He was able to build scalable data pipelines using Tinybird on his own before they had even hired any dedicated data engineers. With Tinybird in place he's able to focus purely on improving the product. He's seen Tinybird helps startups with small teams scale their data products, without the typical complexity. Since implementing Tinybird, they've combined product usage metrics from their internal operational data with GitHub issues raised by customers, for a better understanding of where to direct engineering resources. They've even taken it one step further, and use that same analytics infrastructure to identify product errors in realtime - before the customer even needs to report them.
Since implementation, the team has been exploring using Tinybird to provide more fine-grained in-product analytics to their customers. In the coming months, they expect to serve way more analytics data to customers through their dashboards, which enables tracing and observability of cloud applications that run on LocalStack, and help optimize applications before they are deployed to the cloud.




