


What excites me most about the inflow of AI and LLMs into every nook and cranny of my daily life is the opportunity to point an agent at a big block of data, ask questions, and get answers. I've spent most of my career analyzing data. I like data. I like analyzing data. I used to like writing SQL. Now I don't (mostly). Now that I've tasted the sweet goodness of agentic analytics powered by tools like Vercel AI SDK and Tinybird MCP Server, I'd rather give an agent context and have it query the database for me.
However, this isn't as simple as it sounds. LLMs are surprisingly bad at writing SQL. But with Tinybird (and the Tinybird MCP Server) and the Vercel AI SDK, it's quite straightforward (and mostly prompt engineering).
In this post, I'll show you how to build an agent with sufficient contextual understanding of underlying analytics data - and the tools to query it - so that you can have a chat with your data (any data!). Specifically, I'll build a simple analytics agent for a blog - hosted on the open-source publishing platform Ghost. The agent will tell us which content is performing the best, and why.
The tools for the job:
- Ghost (blog hosting)
- Vercel AI SDK (Typescript agent framework)
- Tinybird (database + analytics MCP + tools)
Blog analytics on Ghost
Ghost is an open source publishing platform, great for anybody who wants to self-host their blogging platform. You can get up and running immediately with Ghost(Pro), their hosted offering, but many publishers choose to self-host.
In either case, the recent release of Ghost 6.0 includes real-time, multi-channel analytics via Tinybird, the platform on which Ghost's analytics run. This ghost tinybird integration is powerful. If you choose to self-host, you'll also get unfettered access to the underlying data in Tinybird. Alongside Ghost, you can use Tinybird Cloud - for managed analytics hosting - or Tinybird self-managed regions for a complete self-hosted setup.
Self-hosting Ghost + Tinybird is straightforward, and I won't cover it here. You can follow Ghost's self-hosting guides to learn how to do it.
For now, I'll assume you've already set up Ghost self-hosted with Tinybird web analytics enabled, and, as a part of that setup, you have created a Tinybird workspace (hosted or self-managed) that is receiving web traffic events from Ghost.
If you don't already have that, but want to follow along anyway, here's how to set up Tinybird for basic testing:
Basic Tinybird setup
tb login
# deploy the Ghost Web Analytics template
tb --cloud deploy --template https://github.com/TryGhost/Ghost/tree/main/ghost/core/core/server/data/tinybird
The template includes a small fixture of sample data you can append for testing:
tb --cloud datasource append analytics_events fixtures/analytics_events.ndjson
You can then query the data in the analytics_events data source to get a basic feel for what's in it:
tb --cloud sql 'select uniq(session_id) from analytics_events'
# Running against Tinybird Local
# uniq(session_id)
# UInt64
# ─────────────────────
# 24
(Or use Tinybird's built-in analytics agent, Tinybird Code):
tb --prompt "How many sessions are there?"
# Based on the data in the analytics_events data source, I can see that you have 24 unique sessions
In addition to the data source holding the blog traffic events, the template aslo includes several SQL-based API endpoints that provide metrics like top pages, top browsers, top sources, etc.
ls endpoints
# api_active_visitors.pipe api_top_browsers.pipe api_top_os.pipe
# api_kpis.pipe api_top_devices.pipe api_top_pages.pipe
# api_post_visitor_counts.pipe api_top_locations.pipe api_top_sources.pipe
You can test the response from any of these APIs locally:
tb endpoint url api_top_browsers --language curl
# curl -X GET "http://localhost:7181/v0/pipes/api_top_browsers.json?site_uuid=mock_site_uuid&timezone=Etc%2FUTC&skip=0&limit=50&token=p.eyJ1Ijo..."
So that's the Tinybird setup. You have data in the database and APIs that query it. Now for the fun part: building an AI agent that can turn a natural language question into helpful insights about our blog traffic.
Creating an analytics agent with Vercel AI SDK and Tinybird MCP Server
You can quickly build a simple analytical CLI agent with the Vercel AI SDK and Tinybird MCP Server. That agent will be able to analyze the blog traffic data stored in Tinybird and answer questions using the set of tools provided by the Tinybird MCP Server.
Setting up the agent basics
We're going to make this as simple as possible: A single Node.js CLI script that will accept a user input via the terminal and print out a response, maintaining a chat history in the context window for multi-message functionality. You'll need to have a recent version of Node installed.
You can start by creating a file, cli.js (full gist here), and importing + installing the packages you'll need:
import { streamText, experimental_createMCPClient as createMCPClient } from 'ai';
import { anthropic } from '@ai-sdk/anthropic';
import { StreamableHTTPClientTransport } from '@modelcontextprotocol/sdk/client/streamableHttp.js';
import readline from 'readline';
import * as dotenv from 'dotenv';
dotenv.config();
Here's what we're importing:
streamTextfunction from the AI SDK to enabling streaming output from the LLMexperimental_createmCPClientfrom the AI SDK to create a client for the Tinybird MCP ServerStreamableHTTPClientTransportsupport from the MCP project, since the Tinybird MCP Server uses StreamableHTTP transportreadlineto enable the CLI interfacedotenvto handle environment variables
Important! Defining a system prompt
The most important task when creating an analytics agent (or any agent) is prompt engineering. As discussed in vercel what we learned building agents at vercel blog, the tooling around agent development is so solid now that 90% of the work is writing a good prompt.
Here's the simple system prompt I gave my agent.
const SYSTEM_PROMPT = `You are a Ghost blog analytics assistant. Your job is the answer the user's questions to help them understand the performance of their Ghost blog, and to provide recommendations about how to improve their blog performance. Use available Tinybird tools to answer questions about page views, visitors, and site data. When querying data, use a default time range of the last 24 hours unless the user specific requests a different time range. Be concise in your responses. Today's date is ${new Date().toLocaleDateString()}.`
This works, but there's plenty of room for improvement. Anthropic's prompt engineering docs are a great reference, specifically for Anthropic models but also for LLMs in general.
Set up the CLI interface
We're using readline to enable a simple CLI chat interface:
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const chatHistory = [];
We're also maintaining the chat history so the agent has full context. Keep in mind this is a naive approach with zero summarization or compaction. There are plenty of resources out their on how to minimize token usage as chat history grows, including retaining only recent messages and summarizing old messages (with another agent), using a vector DB + RAG approach to recall important context, etc. For now, we'll just maintain the full history and eat the tokens :).
Creating an MCP client for the Tinybird MCP Server
Next, we need to instantiate an MCP Client to connect to the Tinybird MCP Server:
let mcpClient = null;
async function initializeMCP() {
// Check to make sure the Tinybird token is available
if (!process.env.TINYBIRD_TOKEN) {
console.error('TINYBIRD_TOKEN environment variable not found');
console.log('Get your token with `tb info ls` and `tb token copy`');
process.exit(1);
}
try {
// Tinybird remote MCP server URL with token for scoped permissions
const url = new URL(`https://mcp.tinybird.co?token=${process.env.TINYBIRD_TOKEN}`);
// Create the client with a unique session ID
mcpClient = await createMCPClient({
transport: new StreamableHTTPClientTransport(url, {
sessionId: `ghost-cli-${Date.now()}`,
}),
});
console.log('✅ Connected to Tinybird MCP server');
// Fetch and list the available tools from the MCP Server
const tools = await mcpClient.tools();
console.log('\nAvailable tools:');
Object.keys(tools).forEach(tool => {
console.log(` • ${tool}`);
});
return tools;
} catch (error) {
console.error('❌ Failed to connect to Tinybird MCP server:', error.message);
process.exit(1);
}
}
A couple notes about this:
- The Tinybird MCP Server requires a Tinybird token for authentication. The token limits the scope of the MCP Server so that it can only access data allowed by the permissions granted that token. This can be really useful when you need to add security policies to your agentic interfaces, and you can even use custom JWTs with row-level policies in multi-tenant environments, for example, where specific users may need to only see data that match their user_id in a shared data source.
- The Tinybird MCP Server includes a list of core tools, like
explore_data,text_to_sql, andlist_datasources. In addition, every published API endpoint in the Tinybird workspace is enabled as a tool. This can be very useful for agents when you want more deterministic results for certain questions. For example, since I have aapi_top_browsersAPI endpoint in my Ghost project, I would an agent to respond to a question likeWhat are the top 3 browsers used to access my blog in the last 7 days?by making a tool call to that API, rather than attempting its own SQL generation. This allows for much more efficient and deterministic analysis for common query patterns. Every Tinybird API Endpoint includes a plaintext description, which can assist the agent with tool discovery and selection. Write good descriptions!
More info about the Tinybird MCP Server, available tools, token scopes, and observability can be found in the Tinybird MCP Server docs. If you're looking to move away from traditional analytics platforms, you might be surprised how quick it can be—you can set up a google analytics alternative in 3 minutes with Tinybird's built-in templates.
Creating the question/answer CLI interface
Now let's create this CLI chat interface! We'll start with a bit of housekeeping: If the user types exit we should exit the chat:
async function askQuestion(question, mcpTools) {
if (question.toLowerCase().trim() === 'exit') {
console.log('👋 Goodbye!');
process.exit(0);
}
(we will also add Ctrl+C handling in the main CLI function).
Then, we add the question to the chatHistory and use the streamText AI SDK function to get a response:
try {
chatHistory.push({ role: 'user', content: question });
const result = await streamText({
model: anthropic("claude-3-7-sonnet-20250219"),
messages: chatHistory,
maxSteps: 5,
tools: { ...mcpTools },
system: SYSTEM_PROMPT,
});
let fullResponse = '';
console.log('\n💭 Thinking...');
The streamText output is a text stream (result) broken up into pieces, that we'll call delta. These deltas can have several different types - like text, tool call, tool result, etc. - that we should handle for a graceful chat output:
for await (const delta of result.fullStream) {
try {
switch (delta.type) {
case 'tool-call':
if (delta.toolName) {
console.log(`\n🔧 ${delta.toolName}`);
if (delta.args && Object.keys(delta.args).length > 0) {
console.log(` args: ${JSON.stringify(delta.args)}`);
}
}
break;
case 'tool-result':
break;
case 'text-delta':
if (delta.textDelta) {
process.stdout.write(delta.textDelta);
fullResponse += delta.textDelta;
}
break;
case 'finish':
console.log('\n');
break;
default:
break;
}
} catch (err) {
console.error(`⚠️ Error: ${err.message}`);
}
}
chatHistory.push({ role: 'assistant', content: fullResponse });
console.log('\n' + '─'.repeat(50));
} catch (error) {
console.error('\n❌ Error:', error.message);
}
}
We're doing some very basic handling here. If the delta is just text, we write the text to stdout. If it's a tool call, we show which tool is being called and any arguments passed to the tool. If it's a tool result, we show nothing. Why? Because tool results are a bit of JSON gobbldygook and require some finesse to parse and look pretty. To me, that felt like a waste of time for this demo. But feel free to play around with parsing the delta.result object yourself :).
Note when the agent finishes we push its response to the chat history to maintain the full context. When building production-grade agents, you'll want to consider the cost implications of your analytics backend. If you're evaluating options, this tinybird vs clickhouse cloud cost comparison breaks down the trade-offs.
Starting the CLI interface
Now we just need a main function to start the CLI, initialize the MCP server, and open the input for questions:
async function startCLI() {
console.log('👻 Ghost Blog Analytics CLI Agent');
console.log('Type "exit" to quit.\n');
console.log('Connecting to Tinybird MCP Server...\n');
const tbTools = await initializeMCP();
const prompt = () => {
rl.question('\n💭 Question: ', async (input) => {
if (input.trim()) {
await askQuestion(input.trim(), tbTools);
}
console.log('');
prompt();
});
};
prompt();
}
// Handle Ctrl+C
process.on('SIGINT', () => {
console.log('\n👋 Goodbye!');
process.exit(0);
});
startCLI().catch(console.error);
The self-calling prompt arrow function creates a continuous prompt loop until a user types "exit" or Ctrl+C. At each interation, the input awaits the result of the askQuestion function, displaying the agent output and starting all over again.
This same agentic approach can be extended to other real-time analytics use cases beyond blog traffic. For example, you could apply similar techniques to perform real-time sentiment analysis with kafka streams and query those insights through an agent interface.
Let's chat with our blog data
Running the agent is as simple as:
node cli.js
Of course, running an analytics agent on a blog pageviews events table containing 31 rows is kind of boring. In theory you could use tb --cloud mock command to generate some mock data, but this may not properly populate the nested JSON in the payload column in such a way that the API endpoints we already have return meaninful data. No problem! I vibe coded a simple data generator that you can use to generate some "realistic" Ghost blog traffic in a way that matches the default Ghost data schema.
Just run the following in your terminal:
node generate-blog-data.js 100000 # outputs an ndjson with 100k rows of "realistic" blog traffic data
tb --cloud datasource append analytics_events name_of_the_generated_ndjson_file.ndjson
You can verify the data was appended:
tb --cloud sql 'select count() from analytics_events'
# Running against Tinybird Cloud: Workspace ghost
# count()
# UInt64
# ───────────
# 100031
With some more data to analyze, you can fire up the agent! Here's an example of the agent helping me identify the top performing blog post and making content recommendations:
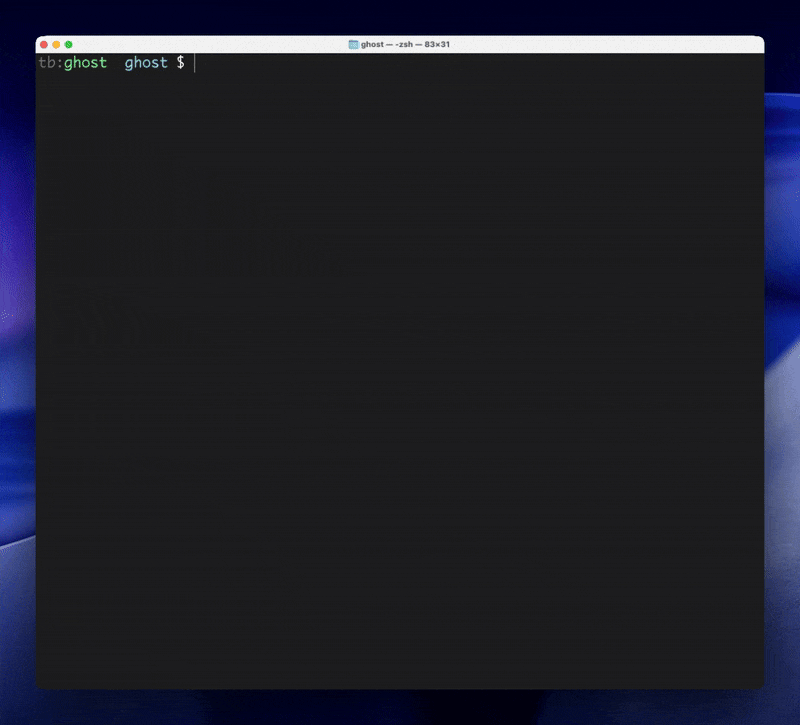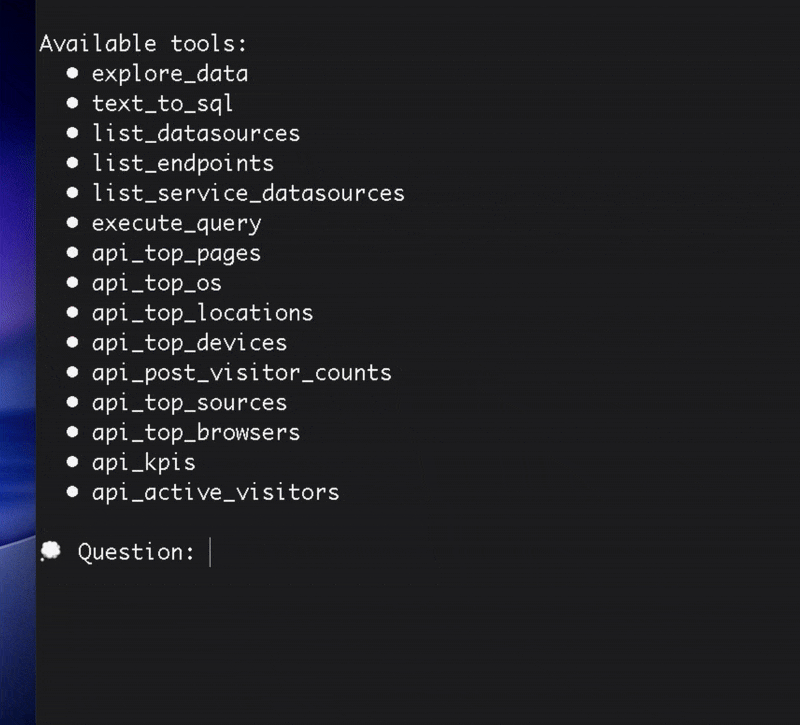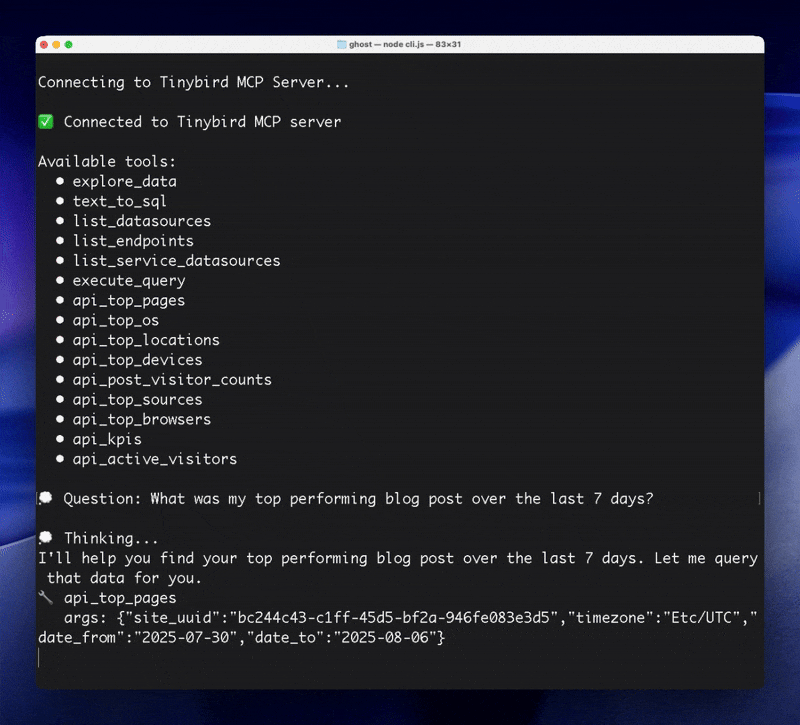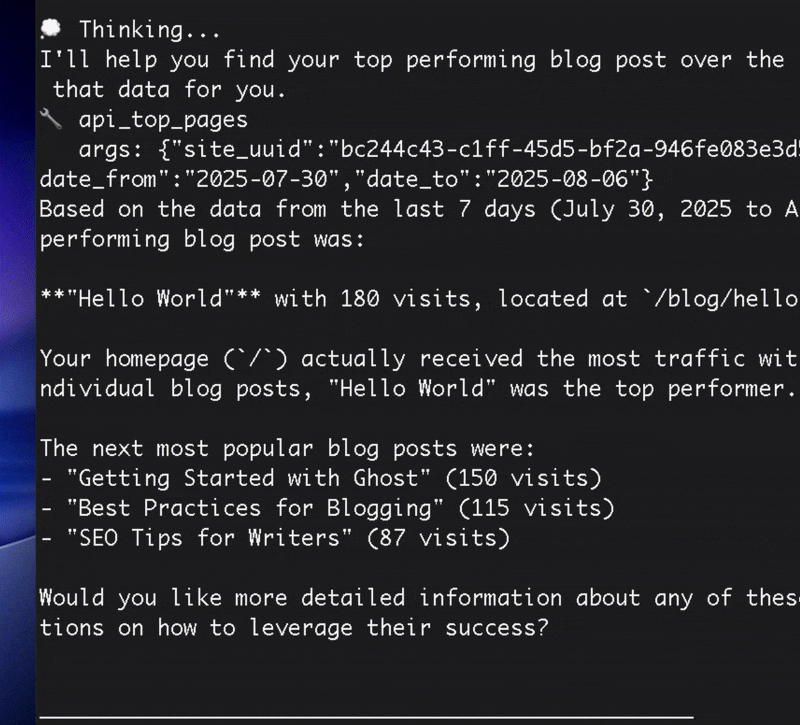
Conclusion
I've showed you how to create a simple analytics agent using the Vercel AI SDK and the Tinybird MCP Server. This ghost tinybird integration example demonstrates the power of combining these tools. In this specific example, we used it to analyze blog traffic data from our Ghost blog, but the concept here can easily be applied to any use case or any kind of data. The only thing that changes is the data you have stored in Tinybird, the token you use to authenticate to the Tinybird MCP Server, and the system prompt. Everything else stays the same. For more insights, check out what we learned building agents at vercel blog.
To get started with Tinybird, sign up for a free account. The Tinybird MCP Server is enabled for all workspaces by default, so you can begin testing this agentic workflow for free.