


When you embed multi tenant analytics dashboards into your multi-tenant SaaS app, multi-tenancy adds a layer of complexity. Your customers should see their data, and their data only. Nothing erodes user trust faster than data privacy violations caused by leaked datasets across tenants.
Here you'll learn the basics of embedding analytics into your multi-tenant SaaS application, specifically using row-level security policies and JSON Web Tokens (JWTs). You'll find resources for building user-facing analytics in multi-tenant environments using Tinybird, a multi-tenant analytics platform for embedding fast and scalable dashboards into SaaS applications.
What is multi-tenant analytics?
In the context of multi-tenant SaaS, multi tenant analytics is the crossroads of multi-tenancy and user-facing analytics. It simply means that you're capturing data from multiple customers (tenants), storing their data on shared infrastructure, and surfacing tenant-specific metrics to users in the app.
What is multi-tenancy?
Multi-tenancy means that SaaS applications with multiple tenants (customers) use data infrastructure that is shared among all of them. In other words, it's the opposite of dedicated infrastructure for each customer. Data may be shared on the same server, in the same database, or even in the same database table. Multi-tenant architectures are the most common approach to data tenancy in SaaS applications.
With multi-tenancy, multiple app users initiate requests to that shared infrastructure. Multi-tenant applications need multi tenant access control policies and permissions structures that single tenants can access only their data and that they cannot access other customers' data, either accidentally or maliciously.
What is user-facing analytics?
User-facing analytics (aka "customer-facing analytics”) is the pattern of embedding real-time data visualizations or data-driven features into software applications. You’ll implement user-facing analytics if you offer a software service and want to provide real-time data to your end users.
User-facing analytics differs from classic business intelligence (BI) approaches to analytics in that user-facing analytics provides on-demand data interactions and dashboards for external software users.
User-facing analytics introduces requirements that Business Intelligence doesn't have:
- Low-latency query response times
- High-concurrency user access
- High data freshness requirements
User-facing analytics vs. embedded analytics
User-facing analytics and embedded analytics are two sides of the same coin. The end goal is the same: to surface data analytics to end users of an application.
In practice, user-facing analytics generally implies that data features and visualizations are integrated directly into the application code, rather than via embedded business intelligence dashboards developed in external tools. There's an emphasis placed on the analytics experience; it should feel integrated into the overall user experience such that the user doesn't notice a difference between the analytics features and non-analytics features of the application.
Example multi-tenant analytics use cases
Multi-tenant analytics can be found across a wide range of SaaS use cases:
- User-facing Dashboards. Any SaaS company displaying tenant-specific dashboards to app users will likely use multi-tenancy approaches. One example is Factorial, a human resources SaaS that provides in-app dashboards to HR managers to track employee performance and well-being.
- Usage-based Billing: Any SaaS company with usage-based billing will supply pricing observability to their users via user-facing dashboards. This pricing and usage data is often stored in a multi-tenant data architecture. Vercel's multi-tenant usage-based billing analytics system is a good example.
- User-generated Content Analytics. Content platforms build multi-tenant analytics systems to show content creators how end users are engaging with their content. Creator platforms like Canva and web infrastructure companies like Dub are great examples.
Each multi-tenant analytics use case involves sensitive personal and corporate data, where data isolation and data security are critical.
Row-level security in multi-tenant analytics
Row-level security is a critical part of database-driven application development. It’s pretty common to have tables in your application databases containing data from many different sources, and perhaps from different tenants. If that's the case, you need a permissions structure by which users can access specific table rows containing only their data.
As its name implies, row-level security means you can control which rows of a table your users can access. There are different ways to implement row-level security, but the most common approach is based on the value of one or more columns in the table.
For example, if you have a column called Customer ID, you could create a rule that says Customer A can only read rows where the Customer ID column has a value of CustomerA.
In a simple SQL example, you have a table called events that logs an event stream of actions taken by users of your SaaS app, let's say the tenant IDs are stored in a column called customer_id.
Row-level security means filtering in only records containing a desired customer ID:
It’s a primitive example, but you get the point.
How you manage the execution of this query and its row-based security filter depends on your analytics tools.
Now, you could replace the hard-coded filter with a templating language:
In this case, you could pass the customer_id parameter to the API Endpoint using URL parameters, for example: https.api.tinybird.co/my_api.json?customer_id=CustomerA.
This is not secure! It is too easily modified on the client side and should be avoided.
Using JWTs for row-level security
JSON Web Tokens (JWTs) provide an ideal security solution for multi-tenant analytics. They are signed resources encrypted using a server-side key, so they can't be manipulated client-side.
In Tinybird, you can assign row-level READ permissions scopes to the JWT you create for each customer.
For example, Customer A might have a JWT defined as such:
In this example, my_pipe is a Tinybird Pipe, effectively an SQL query exposed as an HTTP Endpoint. When Customer A accesses your app, this JWT is used to secure their requests to the Pipe's Endpoint, ensuring that only their data is surfaced by the request. Any attempt to tamper with the JWT will invalidate its signature, so your customer data stays secure and isolated.
How to safely build multi-tenant analytics in your SaaS
To build multi-tenant analytics into your SaaS, you need an analytics solution that can easily handle multi-tenancy through security policies applied to the analytics API.
Tinybird is a multi-tenant data integration platform developers use to ingest tenant data from multiple data sources into a single table and expose derived analytics as API Endpoints.
Access to Tinybird APIs can be controlled using JSON Web Tokens (JWTs) that support row-level security policies with multi tenant access control. Each tenant gets a unique JWT with a row-level security definition limiting the read scope on the source table to data belonging only to the appropriate tenant. This makes Tinybird an ideal multi-tenant data integration platform.
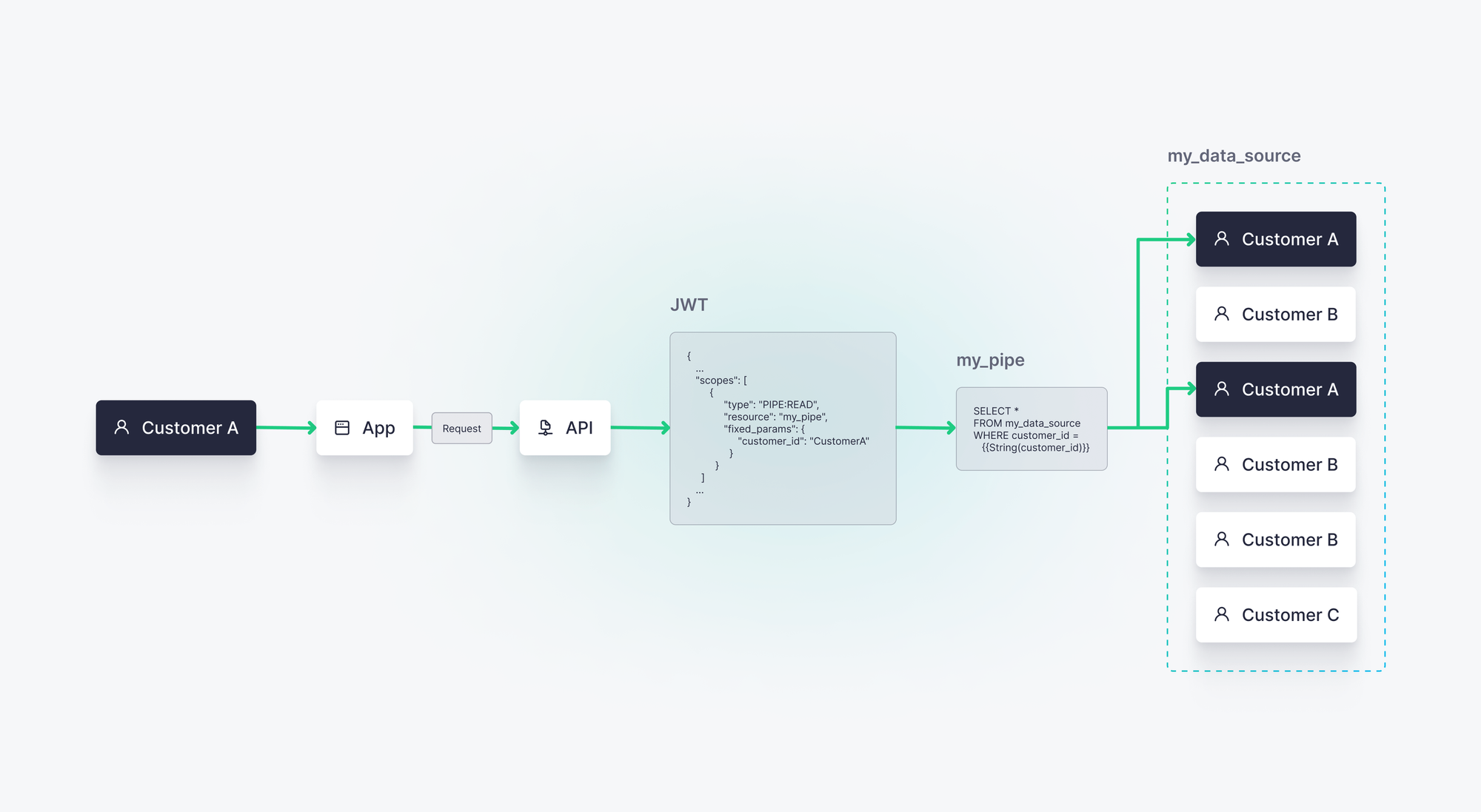
customer_id = CustomerA. This is a much more secure approach to multi-tenant analytics, as any attempts to tamper with the JWT will invalidate its signature and result in rejected requests.Tinybird is an ideal multi-tenant analytics solution because it handles multi-tenancy and user-facing analytics functionality in a single, serverless platform. Companies like Vercel, Canva, FanDuel, Dub, Factorial, and many others use Tinybird to rapidly develop and deploy scalable multi-tenant analytics solutions.
To learn more about building multi-tenant analytics with Tinybird, check out these additional resources: