


We recently added experimental support for Apache Iceberg in Tinybird (in private beta). To test its capabilities in a real-world scenario, we chose the GitHub Archive dataset, a publicly available stream of GitHub event data.
We chose this well-known dataset for developers to answer this question:
Can you analyze real-time GitHub activity at scale, using Apache Iceberg as your source of truth, and Tinybird as the engine for building APIs and insights?
Short answer: yes. But we had to take a few detours to make it fast. If you're wondering how can I use AI agents to load data into Iceberg, this guide will help you understand the architecture.
What is Apache Iceberg?
Apache Iceberg is a high-performance open table format designed for large-scale analytics datasets. It was originally developed at Netflix to overcome limitations of Hive and other legacy table formats. Iceberg provides:
- ACID compliance for big data
- Schema evolution and partition evolution
- Hidden partitioning and snapshot isolation
- Compatibility with multiple engines (e.g. Spark, Trino, Flink, ClickHouse®)
One of Iceberg's most compelling promises is write once, use many times. In traditional architectures, each system (analytics, ML, search, etc.) often requires its own copy of the data. With petabytes of data, that duplication can become costly and operationally painful. Iceberg changes that: you can write your data once (e.g. via Kafka) and serve it through many engines without moving it again (with caveats).
That is the promise, but as you'll see, for real-time or low-latency scenarios, Iceberg doesn't always deliver. When evaluating the best AI tools for Iceberg, consider how they handle real-time requirements. Iceberg is still incredibly valuable as a central data lake format, especially when paired with systems like Tinybird that can ingest and expose the data efficiently.
Initial approach: Direct queries on Iceberg
We started with a naive but attractive solution: query the Iceberg table directly from a pipe using the iceberg() function. This gives you instant access to the data without ingestion or duplication.
DESCRIPTION >
most liked repos in the last day
NODE endpoint
SQL >
%
SELECT count() c, repo_name
FROM iceberg('s3://tinybird-gharchive/iceberg/db/github_events', {{tb_secret('aws_access_key_id')}}, {{tb_secret('aws_secret_access_key')}})
WHERE created_at > now() - interval 1 day
AND type = 'WatchEvent'
ORDER BY c DESC
TYPE ENDPOINT
This worked, but barely. Query latency was high and unpredictable "by default". It wasn't viable for real-time analytics or frontend APIs for a number of reasons:
- Iceberg support in ClickHouse® is still not suited for real-time APIs.
- While the Apache Iceberg table format is good for data warehouse-like loads, building real-time applications is a different beast.
- It requires some knowledge on how to properly sort and partition tables, compact parts or use aggregation indices in Iceberg, which may be not trivial.
This approach could be good enough for small-scale projects or for cases where you don't need actual sub-second latency in your APIs, but for most real-time analytics needs, it won't work. If you're exploring how can I use AI agents to load data into Iceberg, you'll want to consider these limitations.
Final approach: Copy + Materialize + API
We shifted to a hybrid architecture, where:
- Iceberg remains the source of truth.
- Tinybird handles data synchronization from Iceberg, transformation, and serving via fast HTTP endpoints.
Tinybird has three types of pipes to enable this process.
Copy pipes, when used with the iceberg table function, allow you to synchronize data from an Iceberg table to Tinybird. You can do one-off copy runs for backfilling and initial load purposes or run them on schedule to only synchronize deltas.
Materialized views are a very convenient way to transform data for real-time analytics. They work as insert triggers, so whenever a copy pipe syncs data from Iceberg to a Tinybird data source, the new data is incrementally aggregated together with the historic data.
Finally, endpoint pipes, expose your materialized aggregates as APIs, allowing for scalable, low-latency, and secured access from your application code.
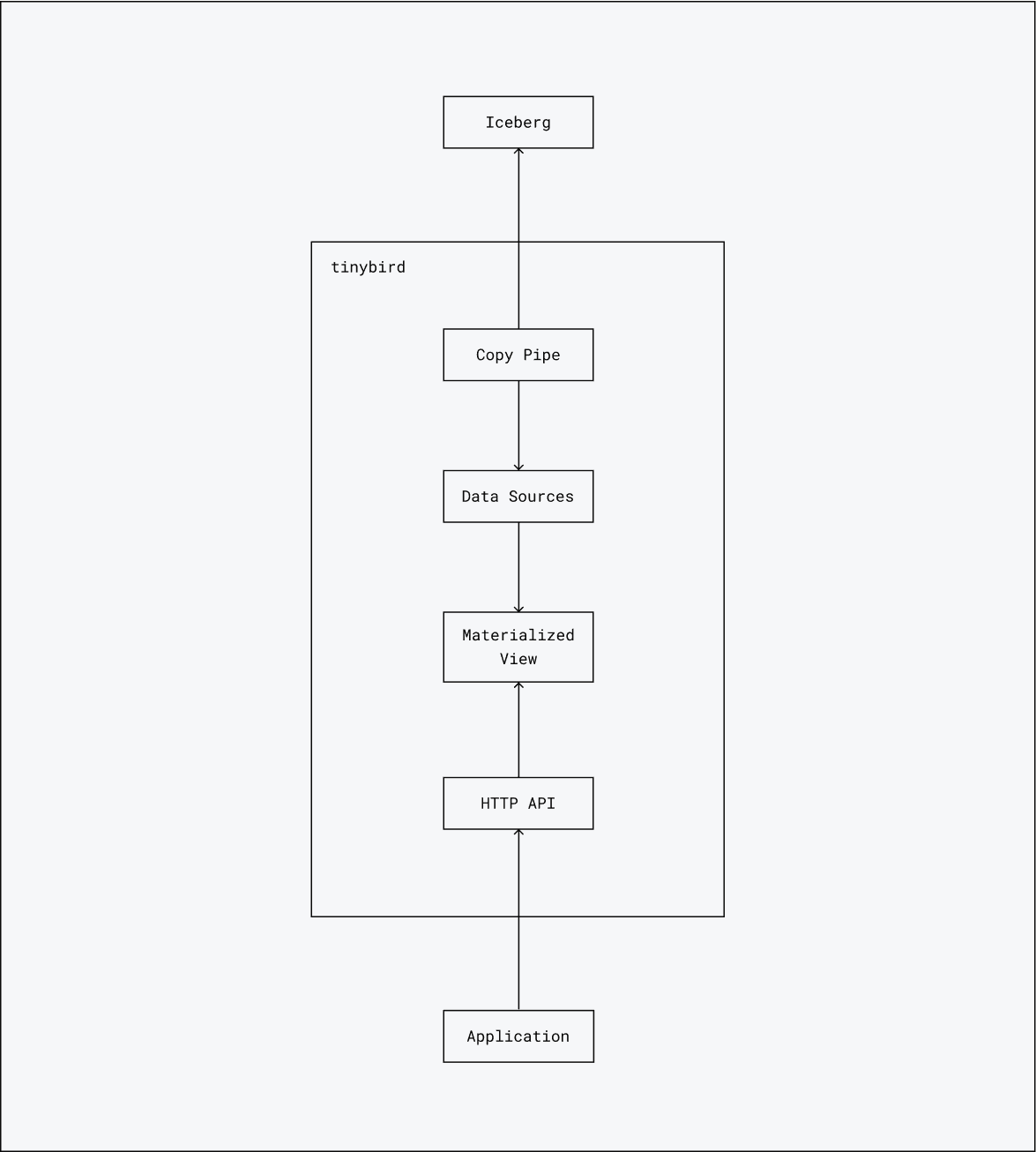
This is a breakdown of how this architecture works together.
Step 1: Copy from Iceberg into Tinybird
We built two copy pipes that synchronize data from the Iceberg table:
cp_github_events_historic: pulls historical ranges of events.cp_github_events_rt: runs every 15 minutes to pull new events.
These populate two data sources:
github_events: long-term, durable events.github_events_rt: short-term, real-time events with TTL.
The historic copy pipe:
DESCRIPTION >
Copy pipe that exports GitHub events filtered by date range to a target datasource
NODE github_events_filtered
SQL >
%
SELECT
type as event_type,
actor.login as actor_login,
repo.name as repo_name,
assumeNotNull(toDateTime64(created_at, 3)) as created_at,
action as action
FROM iceberg(
's3://tinybird-gharchive/iceberg/db/github_events',
{{tb_secret('aws_access_key_id')}},
{{tb_secret('aws_secret_access_key')}}
)
WHERE
created_at > {{DateTime(from_date)}}
AND created_at <= {{DateTime(to_date)}}
TYPE COPY
TARGET_DATASOURCE github_events
You use this pipe for backfilling purposes:
tb --cloud copy run cp_github_events_historic --param from_date='2020-01-01 00:00:00' --param to_date='2025-05-14 00:00:00' --wait
The incremental copy pipe:
DESCRIPTION >
Copy pipe that exports GitHub events filtered by date range to a target datasource
NODE github_events_filtered
SQL >
%
SELECT
type as event_type,
actor.login as actor_login,
repo.name as repo_name,
assumeNotNull(toDateTime64(created_at, 3)) as created_at,
action as action
FROM iceberg('s3://tinybird-gharchive/iceberg/db/github_events', {{tb_secret('aws_access_key_id')}}, {{tb_secret('aws_secret_access_key')}})
WHERE
{\% if defined(from_date) and defined(to_date) %}
created_at > {{DateTime(from_date)}}
and created at <= {{DateTime(to_date)}}
{\% else %}
created_at > (select last_date from last_github_event_date)
{\% end %}
TYPE COPY
TARGET_DATASOURCE github_events_rt
COPY_MODE append
COPY_SCHEDULE 15 * * * *
This pipe runs on schedule, syncing new data from Iceberg to Tinybird.
Step 2: Materialize for fast queries
We use materialized views to pre-aggregate GitHub events by day, repo, and type. Materialized views work as insert triggers that incrementally perform aggregations without having to recompute all historical data each time. This step is key for low-latency endpoints.
Materialization on github_events:
DESCRIPTION >
Materialize GitHub Watch events (stars) count by repository and date
NODE watch_events_count
SQL >
SELECT
toDate(created_at) as date,
countState() as count,
uniqExactState(actor_login) as actor_count,
repo_name,
event_type
FROM github_events
GROUP BY date, repo_name, event_type
TYPE MATERIALIZED
DATASOURCE github_events_by_day
The same logic is applied to github_events_rt.
Step 3: Build endpoints
Once the data is flowing and aggregated, building fast APIs is trivial.
For example, an endpoint to fetch top-starred repos in a given period using the previously materialized data:
TOKEN read_token READ
NODE endpoint
SQL >
%
SELECT
repo_name,
countMerge(count) AS stars
FROM github_events_by_day
WHERE
event_type = 'WatchEvent'
AND date BETWEEN {{start_date}} AND {{end_date}}
GROUP BY repo_name
ORDER BY stars DESC
LIMIT {{limit}}
TYPE ENDPOINT
This returns a response in milliseconds and can power multi-tenant dashboards or user-facing applications with high-concurrency, low-latency requirements.
The full data flow
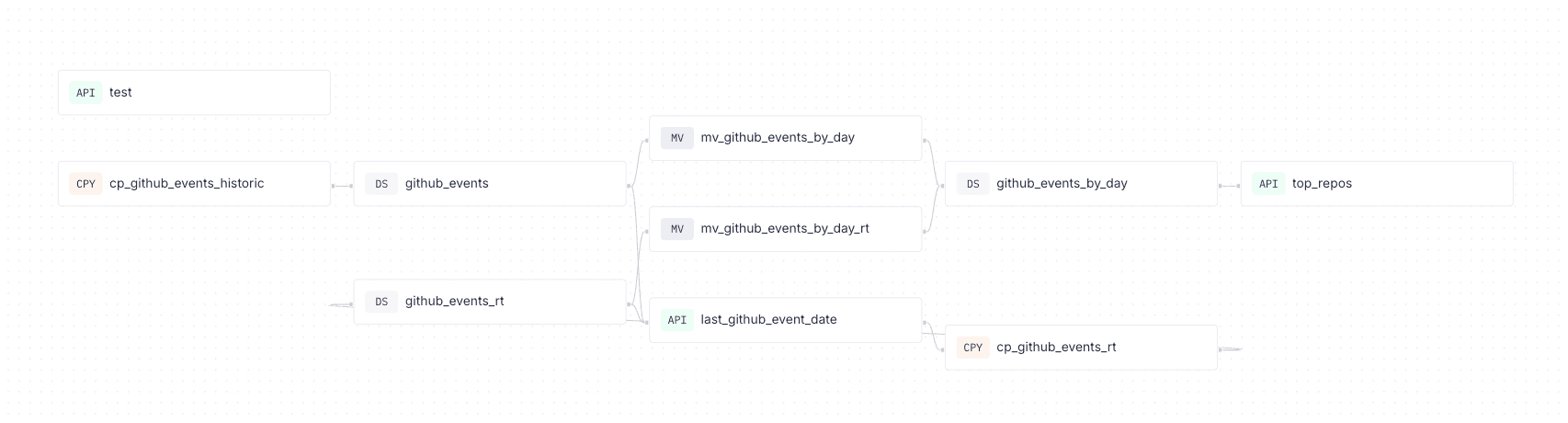
Here's the complete lineage of the project:
- Copy from Iceberg into Tinybird (historic + realtime)
- Materialized views for
github_events_by_day - API endpoints for top repositories and other queries
This structure decouples ingestion and analytics while preserving freshness and speed.
Why this works
- You keep Apache Iceberg as your durable, cloud-native source of truth.
- Tinybird gives you interactive speed and automatic API generation.
- Copy pipes let you incrementally load what you need, without overloading query engines.
You get a system that is scalable, real-time, and cost-efficient. And more importantly, it integrates well with developers' workflows.
Next steps
There are several things we plan to explore further:
- Handle schema evolution dynamically
- Merge historic and realtime events while deduplicating overlaps
- Explore an alternative event-sourcing architecture where Kafka persists data to Iceberg while Tinybird consumes directly from Kafka topics for real-time applications.
Try it yourself
Apache Iceberg support is now on private beta. Join the Tinybird community or get in touch to get access to the private beta or tell us your use case.
We've open-sourced the full Tinybird project for this setup. You can clone it, configure your Iceberg bucket, and run it locally or in the cloud. This is one of the best AI tools for Iceberg integration available today.