


Choosing between ClickHouse® and Aurora PostgreSQL often comes down to a single question: are you building features that need to analyze millions of events quickly, or are you managing transactional data that changes frequently? The architectural differences between these databases create performance gaps that can reach 100x for certain workloads, while Aurora maintains advantages for others.
This guide compares how ClickHouse® and Aurora PostgreSQL handle analytical queries, examines their cost structures and operational requirements, and explains when to use each database or both together in a hybrid architecture.
How ClickHouse® and Aurora PostgreSQL differ under the hood
ClickHouse® and Aurora PostgreSQL use completely different architectures that determine how fast they can process your queries. ClickHouse® stores data in columns, where all values for a single field live together on disk. Aurora PostgreSQL stores complete rows together, which means every field in a record sits next to each other.
This storage difference matters when you're running queries. If you want to count page views by day across 100 million events, ClickHouse® only reads the timestamp and event type columns. Aurora has to read entire rows, including user IDs, session data, and everything else, even though you don't need that information for your query.
Columnar vs row storage
When ClickHouse® stores your data, it groups all timestamps together, all user IDs together, and all event types together. This layout works well for analytical queries because most aggregations only touch a few columns out of many, delivering 10x to 100x faster performance on OLAP workloads.
Aurora stores complete records as units. If you have a users table with 20 fields, Aurora keeps all 20 fields for each user stored together. This makes it fast to fetch or update a single user's complete profile, but slow to scan millions of users just to count how many signed up each month.
Column storage also compresses better. A column of timestamps with sorted values compresses down to a fraction of its original size because compression algorithms work well on similar, sequential data. In real-world usage, Character.AI achieved 15-20x average compression using ClickHouse®'s columnar format.
Primary index vs B-tree indexes
ClickHouse® uses sparse indexes that sample your data rather than tracking every single row. When you query by timestamp, ClickHouse® checks these samples to skip entire blocks of data that don't contain relevant timestamps. This means less data read from disk.
Aurora uses B-tree indexes that maintain pointers to every row. These indexes are excellent when you need to find user ID 12345 or update a specific order, but they add overhead during writes because every insert or update requires index maintenance.
Compression and on-disk layout
ClickHouse® applies compression at the column level using algorithms like LZ4 and ZSTD. Time-series data with sorted timestamps often compresses by 90% or more, which means you're storing and reading far less data.
Aurora compresses data too, but row-based storage doesn't compress as effectively because each row contains mixed data types that don't compress well together.
Quick summary of benchmark results
For analytical queries that aggregate millions of rows, ClickHouse® typically runs 10x to 100x faster than Aurora PostgreSQL. Check out the results on Clickbench. Aurora maintains better performance for transactional operations where you're updating individual records frequently.
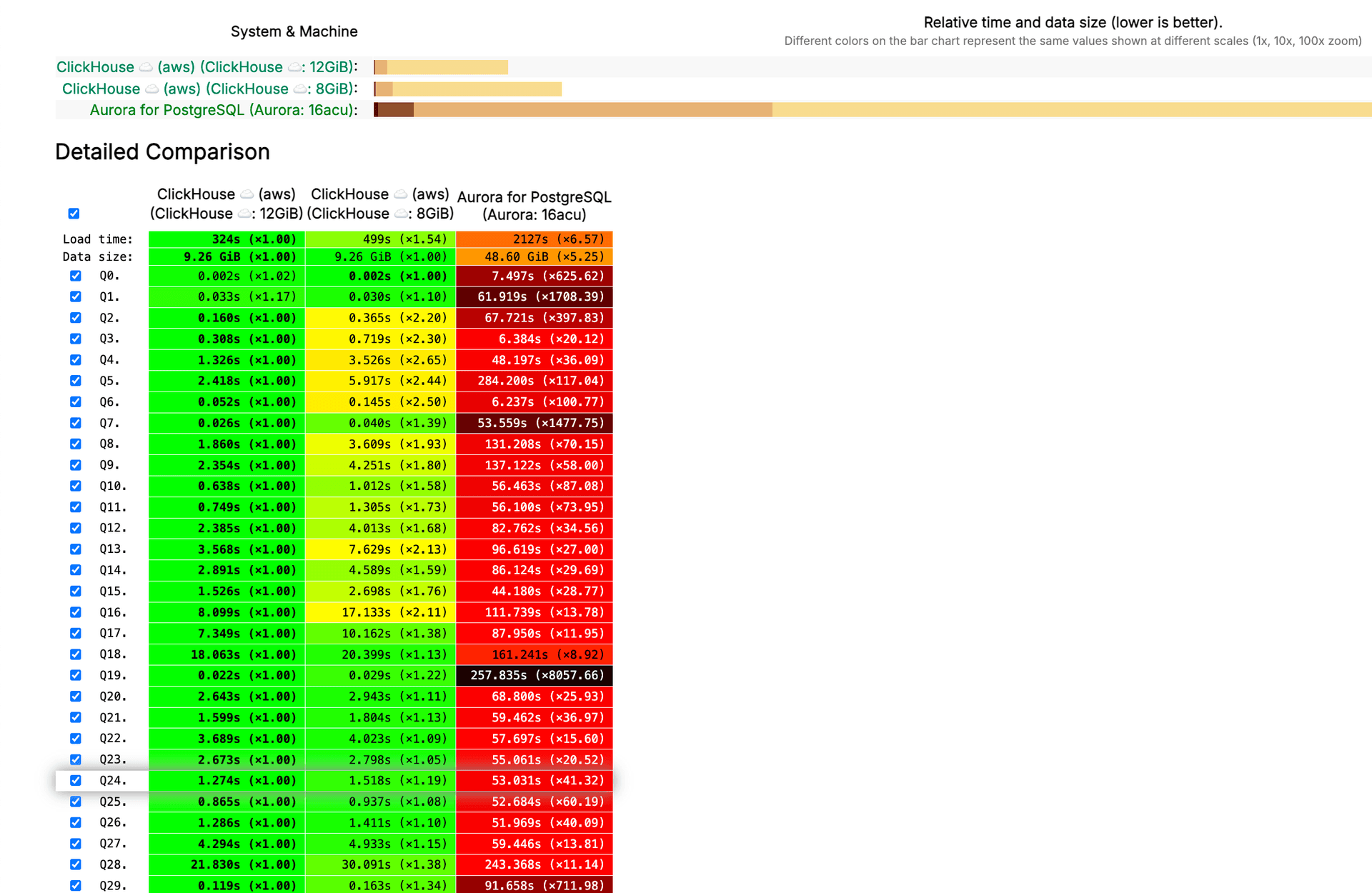
When you're scanning a billion events to compute daily active users, ClickHouse® often responds in under 100 milliseconds. Aurora can take seconds or minutes for the same calculation, depending on your dataset size and query complexity.
For single-row lookups by primary key, Aurora responds in under a millisecond. ClickHouse® can handle these queries but isn't optimized for them, often showing higher latency for point lookups.
Where Aurora PostgreSQL still wins
Small row-level transactions
When your application inserts, updates, or deletes individual rows frequently, Aurora handles these operations more efficiently. Each transaction completes in milliseconds with immediate visibility to subsequent queries.
ClickHouse® is optimized for batch inserts and append-only data. While it supports updates and deletes through mutations, these operations run asynchronously in the background rather than completing immediately.
Strict ACID semantics
Aurora provides full ACID compliance with multi-version concurrency control, which lets multiple transactions proceed simultaneously without blocking each other. Transactions can be rolled back if they fail, and changes stay isolated until committed.
ClickHouse® provides atomicity for single-table operations but lacks full multi-table transaction support. If your application needs to update inventory and orders atomically, or requires complex rollback logic, Aurora is the better fit.
PostgreSQL extensions and tooling
The PostgreSQL ecosystem includes thousands of extensions for full-text search, geospatial data, JSON processing, and specialized data types. Aurora supports most of these extensions, giving you access to mature, well-tested functionality that your team might already know.
When ClickHouse® delivers order-of-magnitude speedups
Append-only event data
Log processing, clickstream analytics, and IoT sensor data fit ClickHouse® perfectly because they involve continuous writes of new events without updates or deletes. The columnar format and sparse indexing excel at scanning and aggregating large event streams.
Analyzing user behavior across millions of page views to compute conversion funnels or retention cohorts runs 50x to 100x faster in ClickHouse®. A query that takes 30 seconds in Aurora might complete in 300 milliseconds in ClickHouse®.
Time series aggregations
Queries that group data by time windows and compute aggregations like counts, sums, or percentiles show the biggest performance gap. ClickHouse® only reads the timestamp and metric columns, not entire rows.
Real-time dashboards that refresh every few seconds benefit from this speed. In benchmarks with 1 billion documents, ClickHouse® executed aggregations in under 400 milliseconds while PostgreSQL took hours. Aurora often can't keep up with the query load when multiple dashboards run concurrent aggregations over billions of rows.
High-cardinality joins
Joining tables with millions of unique values in join keys, such as user IDs or product SKUs, performs better in ClickHouse® because of its distributed hash join algorithms. Aurora's query planner can struggle with these joins, especially when both tables are large.
Cost comparison for large analytics workloads
Total cost of ownership differs significantly between ClickHouse® and Aurora when running analytical workloads at scale. Storage, compute, and data transfer costs all factor into the comparison.
ClickHouse®'s columnar compression typically reduces storage costs by 5x to 10x compared to Aurora for the same dataset. A 1TB table in Aurora might require only 100GB in ClickHouse® after compression.
Aurora charges based on instance size and hours of operation. You pay for provisioned capacity whether you're running queries or not. ClickHouse® Cloud and managed services like Tinybird often use pay-per-query pricing, where you pay for actual query execution time.
Operational overhead and scaling paths
Managing database infrastructure involves different tradeoffs between Aurora and ClickHouse®. Aurora offers more automation for traditional database operations, while ClickHouse® requires more expertise to operate at scale.
Aurora provides automatic failover to a standby instance within the same availability zone, typically completing in under 30 seconds. ClickHouse® requires manual configuration for high availability using replication and ClickHouse® Keeper, though managed services handle this automatically.
ClickHouse® scales horizontally by adding more nodes to a cluster, distributing both data and query processing across machines. Aurora primarily scales vertically by moving to larger instance types with more CPU and memory.
Hybrid pattern: keep OLTP in Aurora, analytics in ClickHouse®
Many teams use both databases together, with Aurora handling transactional workloads and ClickHouse® serving analytical queries. This approach leverages the strengths of each system for its intended workload. This hybrid approach is gaining traction, with ClickHouse®'s market mindshare growing from 1.2% to 5.7% in the open-source database category as of 2025.
Change data capture tools like Debezium or AWS Database Migration Service can stream changes from Aurora to ClickHouse® in near real-time. This keeps your analytical database synchronized with your transactional system.
With CDC, there's typically a few seconds of lag between when data changes in Aurora and when it appears in ClickHouse®. Your application needs to handle this eventual consistency, especially for features like real-time dashboards.
Migration checklist without downtime
Enable CDC on Aurora
First, configure Aurora to publish database changes using logical replication. This requires setting the rds.logical_replication parameter to 1 and creating a publication for the tables you want to replicate.
Set up a replication slot to ensure Aurora retains change logs even if the ClickHouse® consumer falls behind.
Backfill historical tables
Export existing data from Aurora using pg_dump or AWS Data Pipeline, then convert it to a format ClickHouse® can ingest efficiently, such as Parquet or CSV. Insert this historical data into ClickHouse® before starting the CDC stream.
Validate the row counts and sample data between Aurora and ClickHouse® to ensure the backfill completed correctly.
Validate results and cut traffic
Run the same analytical queries against both Aurora and ClickHouse®, comparing results to verify correctness. Small differences might occur due to floating-point precision or timezone handling.
Once you're confident in the data quality, start redirecting a small percentage of analytical queries to ClickHouse®. Monitor query performance and error rates, then gradually increase the percentage.
Performance tuning tips in a managed ClickHouse®
Even with a managed service, understanding how to optimize ClickHouse® queries and table structures helps you get the best performance.
The MergeTree table engine is the standard choice for most analytical workloads in ClickHouse®. It supports primary keys, partitioning, and efficient data compression. For time-series data, partition by day or month using the PARTITION BY clause.
CREATE TABLE events (
timestamp DateTime,
user_id UInt64,
event_type String,
properties String
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (user_id, timestamp);
The ORDER BY clause defines the sort order and sparse primary index. Choose columns that appear frequently in WHERE clauses and GROUP BY operations, putting the most selective columns first.
Materialized views pre-compute aggregations and store the results in a target table. This is particularly useful for queries that run frequently and always compute the same aggregations.
CREATE MATERIALIZED VIEW daily_user_events
ENGINE = SummingMergeTree()
ORDER BY (user_id, date)
AS SELECT
user_id,
toDate(timestamp) AS date,
count() AS event_count
FROM events
GROUP BY user_id, date;
The materialized view updates automatically as new data arrives in the source table. Queries against the materialized view run much faster because they read pre-aggregated data.
Key takeaways and next steps with Tinybird
ClickHouse® delivers significantly better performance than Aurora PostgreSQL for analytical workloads, particularly when dealing with large-scale aggregations, time-series data, and read-heavy queries. Aurora remains the better choice for transactional workloads that require frequent updates and strict ACID compliance.
Many teams use both databases in a hybrid architecture, keeping transactional data in Aurora while replicating it to ClickHouse® for analytics. This approach lets you leverage the strengths of each system.
If you're considering ClickHouse® for your analytical workloads but concerned about operational complexity, Tinybird provides a managed ClickHouse® platform that handles infrastructure, scaling, and optimization. You can define data pipelines as code, deploy them instantly, and access your data through REST APIs without managing clusters.
Sign up for a free Tinybird plan to start building with ClickHouse® in minutes. The platform includes local development tools, built-in observability, and automatic scaling.
Frequently asked questions about ClickHouse® vs Aurora PostgreSQL
Does ClickHouse® support full ACID transactions?
ClickHouse® provides atomicity for single-table operations but lacks full multi-table transaction support like traditional RDBMS systems. For workloads requiring complex transactions across multiple tables with rollback capabilities, Aurora PostgreSQL is the better choice.
How do I secure ClickHouse® to match Aurora IAM policies?
ClickHouse® supports role-based access control and can integrate with external authentication systems, though the configuration differs from Aurora's native AWS IAM integration. Managed services like Tinybird handle authentication and provide token-based API access with fine-grained permissions.
Can I run ClickHouse® inside AWS private subnets?
Yes, ClickHouse® can be deployed within VPCs and private subnets. Managed services like Tinybird handle the network configuration automatically, allowing you to keep your data within your cloud provider's network boundaries while accessing it through secure APIs.
/