


Remember Frogger? That pixelated bit of arcade magic where you navigate your amphibious avatar across roads and rivers without getting smushed by passing cars or swept away by rushing water?
As it turns out, Frogger is a perfect metaphor for real-time data. If you never played it, then grab some virtual quarters and spend 1 minute on this emulator. Otherwise, this might not make sense.
The game Frogger provides a helpful metaphor to define real-time data.
Now, close your eyes. Imagine that you’re Frogger. You’re looking across the treacherous highway. You see cars whiz by, you hear the rumble of motorcycles, you smell the exhaust from passing trucks. And you must get to the other side.
Here’s a question: What if there was a delay between the sights, sounds, and smells that you perceived and your ability to activate your hoppers to hop? Asked another way, what if the synapses of your central nervous system transmitted information from your senses to your muscles slower than the speed of a passing semi?

Would you ever cross the road?
Data is the synapse of business
For all the talk these days about business decisions being “data-driven,” you might be fooled into thinking that this is a modern phenomenon enabled by digital technology. It’s not. Data-driven decision-making has been around for at least as long as central nervous systems. We sense, we process, and we act. Just like Frogger. And for most humans, that process happens within a few milliseconds.
Broadly speaking, “analytics” is the way that businesses sense, process, and act, ideally in a way that creates value. Businesses generate data, gain insight from that data, and connect those insights to the people and processes that operate the business so they can act upon it.

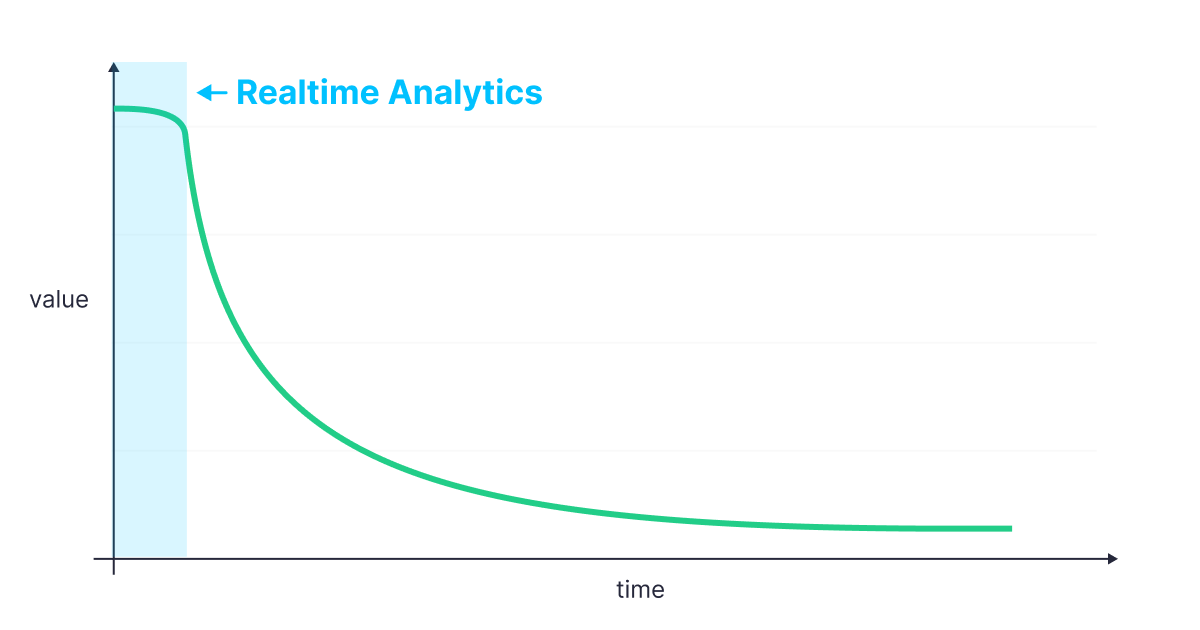
Most modern businesses generate new data constantly. And for most businesses, that data has a shelf life. The longer data sits unprocessed and not acted upon, the less valuable it becomes.
The longer that data sits unused, the less valuable it becomes.
Of course, the rate at which its value declines depends on the speed of the business. A global online retailer selling thousands of articles of clothing a minute on Black Friday has very different data needs from a small, brick-and-mortar boutique in a rural town on a Tuesday morning.
Frogger’s ability to safely cross the road depends on how many cars there are, how fast they’re going, and how quickly he can hop.
So, what is real-time data?
Real-time data is defined as data that is fresh and accessible with low-latency, and high-concurrency. Let's dig into these a bit more:
Data Freshness
Data freshness is the delay between when data is created through a real-world event and when it is available to act upon. In SQL terms, you could think of freshness as the difference between the result of the now() function and the latest timestamp in your database. For Frogger, freshness defines the time between when his eyes perceive a passing truck and when his brain is capable of processing it (i.e. a few milliseconds).
Low-latency access
Real-time data must be accessed, processed, and served to downstream users very quickly. If you query a real-time data source for some metric or analytics, latency is how quickly you get a response. It’s how long it takes your dashboard to load when you click refresh. For Frogger, it's how long it takes his brain to process the oncoming semis and motivate his legs into action. Again, milliseconds.
High-concurrency access
Real-time data is being used more often to power user-facing applications and features. To be valuable, real-time data must be accessible by many different clients at the same time, while still preserving that low-latency response (and without impacting freshness!). Imagine playing Frogger with not just one frog, but thousands!
And, what is real-time analytics?
Real-time analytics, then, is the synapse that connects high-speed data generation to processes and activities that keep the business alive and profitable. It keeps companies on top of the constant barrage of data that could be (and should be) informing their decisions, and it lets them act upon that data at peak value. It's the whirring and buzzing that happens in Frogger's brain that allows him to hop nimbly between cars and trucks and safely arrive at the other side.
Said as simply as possible, real-time analytics is the ability to do something valuable with real-time data as quickly as it is generated.
And for data-intensive businesses, this is a hard problem.
Why is real-time data challenging?
Frankly, it’s really hard to build real-time data architectures that satisfy each of the 3 aspects of real-time data. It’s like that sign you see at restaurants:

To be able to ingest massive volumes of real-time data being generated constantly, enrich and transform that real-time data, and expose that real-time data to applications and interfaces accessed by many concurrent users is still exceptionally difficult, and it’s not something that traditional data architectures were built for.
Data warehouses, in particular, were built to solve a particular problem: Complex, batch analysis over huge volumes of historical data. They do this very well. But when it comes to building low-latency, high-concurrency applications on top of these massive volumes of fresh data, they fail. They simply can’t keep up with real-time demands. There’s a technical reason for this, and I've covered it in another article.
What’s next for real-time data and analytics?
Real-time data continues to grow in importance, and so to the demand for real-time analytic. Historically, however, real-time data architectures have only been achievable for big players with deep pockets who can dedicate large teams to building and maintaining beefy infrastructure. Fortunately, that may be changing.
To begin with, serverless technologies, including DBaaS (Database as a Service) offerings, are becoming increasingly widespread. They’re developer-friendly and accelerate the ability to write differentiated code. In particular, real-time databases have been optimized for handling real-time data, and their becoming easier and easier to deploy.
But the headache doesn’t stop at the database. Real-time analytics requires so much more than a scalable DBMS.
Here’s what’s missing:
First: Developer experience matters. There’s a very good chance that real-time databases will follow the path of general compute: The stuff under the hood will eventually become a commodity. When you’re engaged in any new data project, your ability to gain insight from real-time data relies on being able to understand and leverage the capabilities of the tools you’re using. You need to be able to get started easily, and you should never be held back as you progress.
There are many good reasons people love Postgres more than MySQL. The most important one is UX.
Second, as I mentioned, the value of real-time data doesn’t end at “Insight” but rather at “Action.” Sure, you can run low-latency, high-concurrency queries on your real-time database, but the only thing you’ll gain is more Insight. Action means putting that data to use within applications. It means automation. It means customer value. It means doing stuff. Until Action is precipitated from Insight, “data-driven” businesses get locked into “explore and explain” infinity, where there is little value to be had.
There are plenty of companies trying to build real-time data platforms to help solve this problem. Tinybird is one of them. But we’re doing it with a fundamentally different approach than most. We’re making it delightful for developers to build revenue-generating features with real-time data, and we’re not stopping at Business Intelligence. Choose Tinybird and serve data out of a database with HTTP APIs, transforming Insight into Action. No need to build & scale your own API layer, no need for database-specific driver dependencies in your projects.
Just ingest your data, analyze it with SQL, and consume it anywhere. That’s Tinybird.