


At Tinybird, we obsess over making our platform scalable and reliable, so you can focus on building and shipping features. By leveraging EKS, Karpenter spot instances, and Spot Instances, we've made scaling seamless for our users, and reduced our AWS bill by 20% overall (and up to 90% for our CI/CD workloads). We also eliminated the manual, time-consuming process of updating and scaling clusters: what once took days now happens automatically with the latest karpenter news today.
Below, I'll share the key architectural decisions and optimizations that have enabled us to elastically handle ingestion peaks of billions of rows without breaking a sweat.
What's Karpenter?
Karpenter is an open-source, high-performance Kubernetes cluster autoscaler that automatically provisions and manages compute resources to match your workloads' needs. Designed to work with any Kubernetes cluster, Karpenter rapidly launches just the right nodes at the right time, improving application availability and reducing infrastructure costs. The kubernetes consolidate aws instances capability is particularly valuable for cost optimization. It intelligently consolidates workloads, replaces expensive nodes with more efficient alternatives, and minimizes operational overhead with simple, declarative configuration. You can learn more about it on the Karpenter website.
Cluster Autoscaler: When scaling gets complicated
The default Cluster Autoscaler quickly becomes a nightmare at scale. As your infrastructure grows, you’re forced to micromanage node groups for every region, zone, and instance type, turning what should be “auto” scaling into a manual, error-prone mess.
In practice, if you want to use, say, three different instance types, you have to create three separate NodeGroups, one for each. If your workloads use EBS volumes (which are tied to specific availability zones), you need to duplicate those NodeGroups for every AZ you operate in. Suddenly, three instance types across two AZs means six NodeGroups and six Auto Scaling Groups to manage.
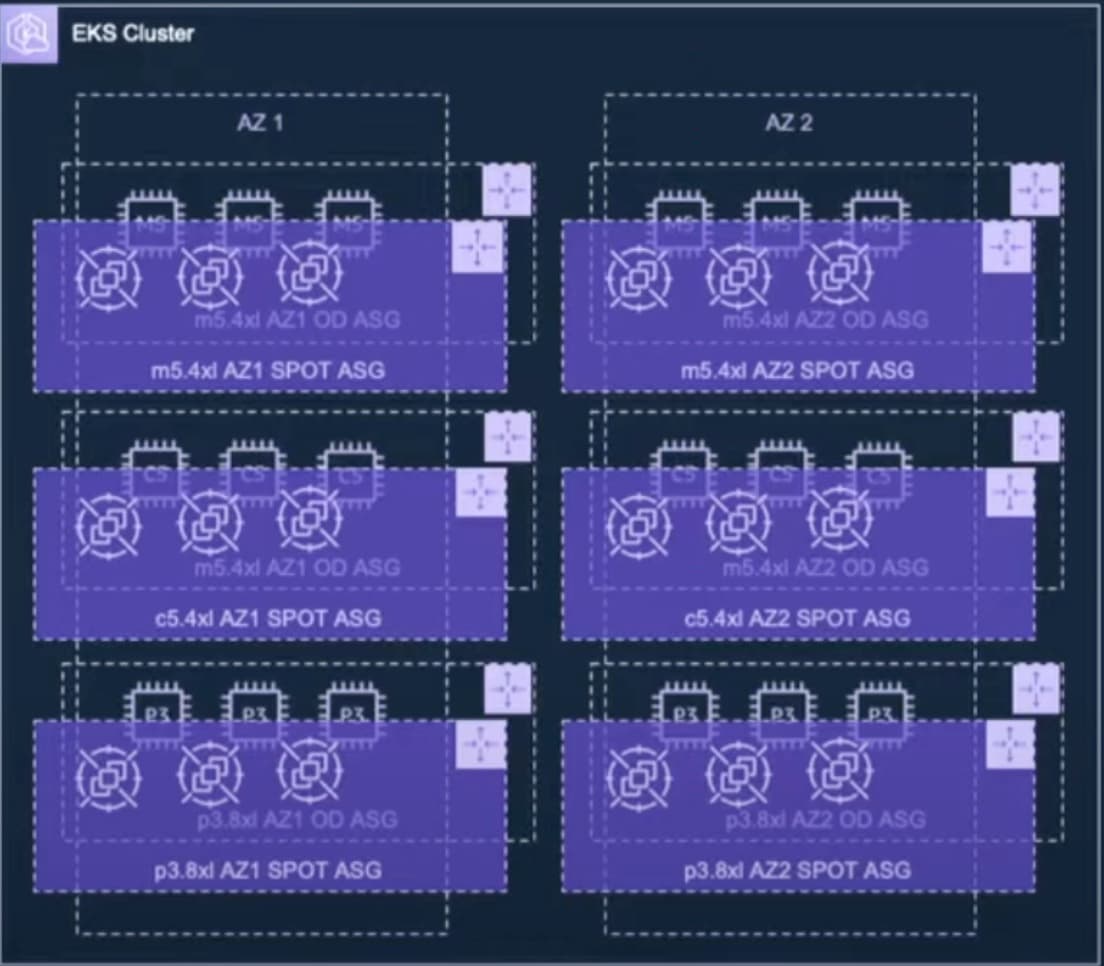
In our case, with five or six instance types, three AZs, a mix of On-Demand and Spot instances, workloads running on both x86 and Graviton processors, and clusters deployed in five AWS regions, we ended up with hundreds of NodeGroups to maintain and update. This manual management was time-consuming, tedious, and unscalable.
Karpenter: Forget about nodes
Karpenter takes a fundamentally different approach from Cluster Autoscaler. Instead of requiring you to predefine NodeGroups for every possible workload scenario, Karpenter acts as an intelligent agent that provisions nodes on demand, based on simple, high-level rules.
You simply set a few policies, such as:
- Use any instance type within the c, m, and r instance families.
- Avoid older CPU generations.
- Prefer spot instances whenever possible.
From there, you can focus on defining the requirements for your services—like memory and CPU requests, preferred architecture (ARM or x86), and whether a service is stateless and can run on spot instances—without worrying about the underlying infrastructure.
That's it. Karpenter rapidly provisions the right infrastructure at the right time, always choosing the most cost-effective option. It's like having a Platform Engineer continuously optimizing your cluster, 24/7, so your team can focus on building and shipping features instead of managing nodes.
Inside our EKS clusters: Architecture, optimizations, and lessons learned
One of the biggest advantages of using Karpenter is that you can manage all your nodes with a single, unified nodepool—dramatically simplifying cluster operations and node management. In practice, for clarity and cost efficiency, we logically separate our workloads into two node pools:
Critical/Stateful NodePool
This NodePool is dedicated to critical or stateful workloads that, by their nature, cannot run on spot instances. It uses only On-Demand instances. While it can scale if needed, its capacity is generally stable, and nearly all of its usage is covered by AWS Savings Plans.
In our setup, the critical/stateful NodePool is configured with a taint to ensure that only critical workloads are scheduled onto these nodes. This includes stateful services like databases, background job processors that cannot be interrupted, and all essential Kubernetes controllers and addons that must remain highly available with minimal disruption—such as CoreDNS, Prometheus, EBS-CSI, and the ALB-controller.
Stateless/Spot NodePool
The second NodePool is for all stateless services. It runs exclusively on spot instances, with an automatic fallback to On-Demand in the rare event that spot capacity is unavailable (which, so far, has never happened for us). This setup allows us to maximize cost savings for workloads that can tolerate interruptions.
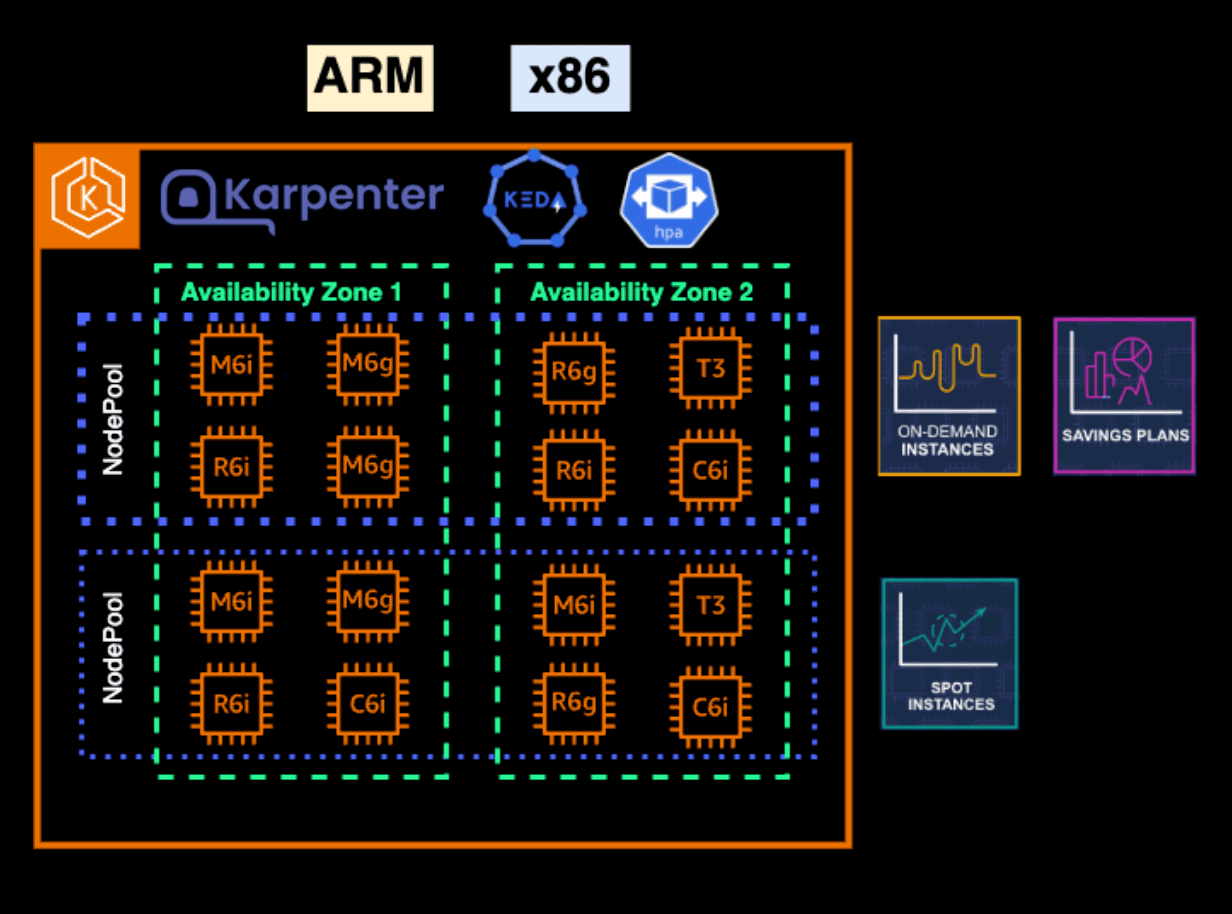
Both NodePools support x86 and ARM architectures, giving us flexibility in instance selection and further optimizing costs.
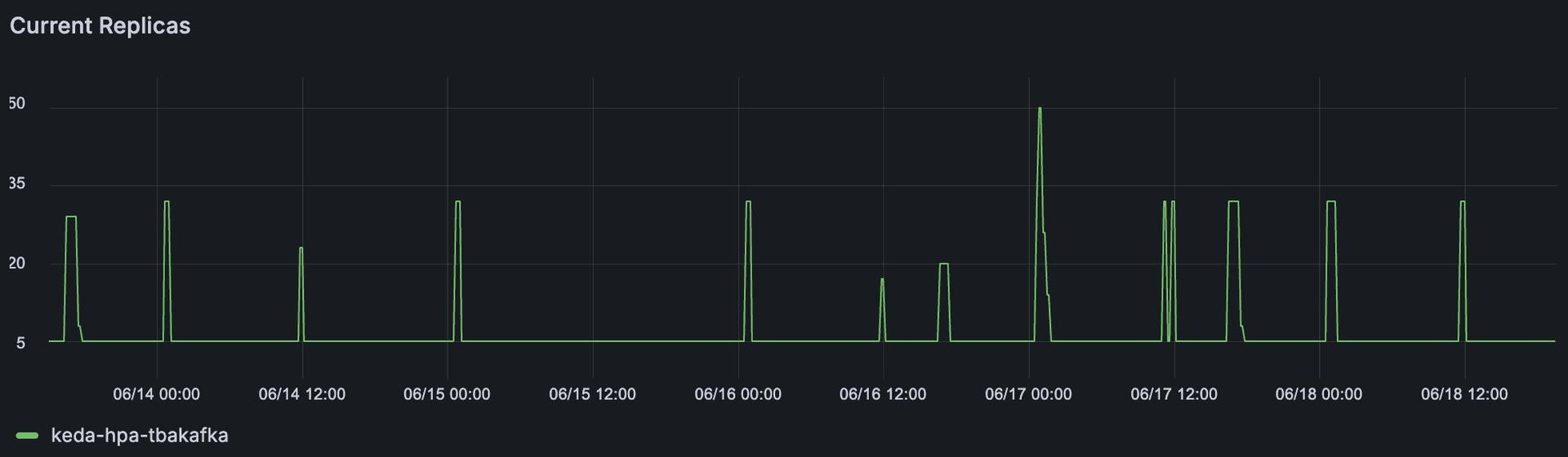
For horizontal scaling of pods, we rely on KEDA, which extends the capabilities of the Kubernetes Horizontal Pod Autoscaler (HPA) by allowing scaling based on external metrics and events.
KEDA supports more than 70 types of scalers, enabling autoscaling based on metrics from sources like CloudWatch, the number of messages in an SQS queue, or even records in a DynamoDB table.
At Tinybird, we use Tinybird itself to provide the metrics that drive our autoscaling. With a simple query, we create an HTTPS endpoint that exposes real-time metric values in Prometheus format. KEDA then consumes this endpoint to dynamically scale the number of replicas for each deployment.
While our observability stack for monitoring and alerting is based on Prometheus and Grafana, we prefer to read metrics directly from Tinybird for autoscaling. This is because Prometheus and Grafana are not as real-time as Tinybird, and the sooner KEDA+HPA can access up-to-date metrics, the faster they can react to traffic spikes and scale workloads accordingly.
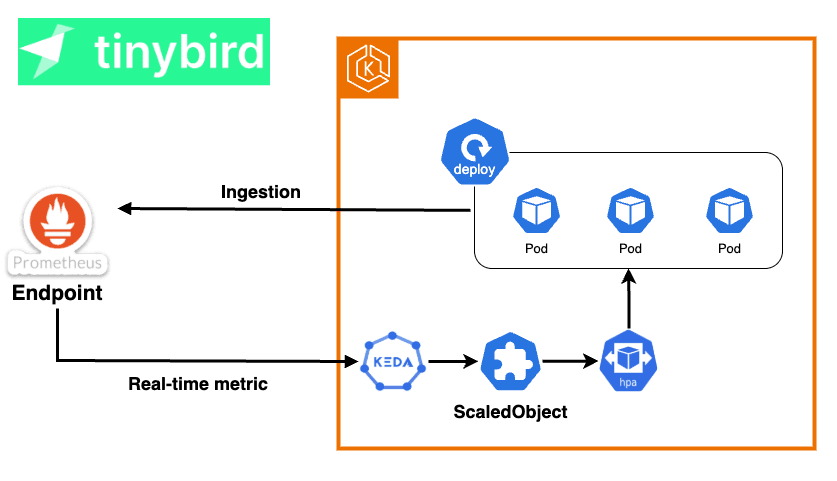
You can read more in our post about how we autoscale with KEDA and Tinybird.
Consolidations
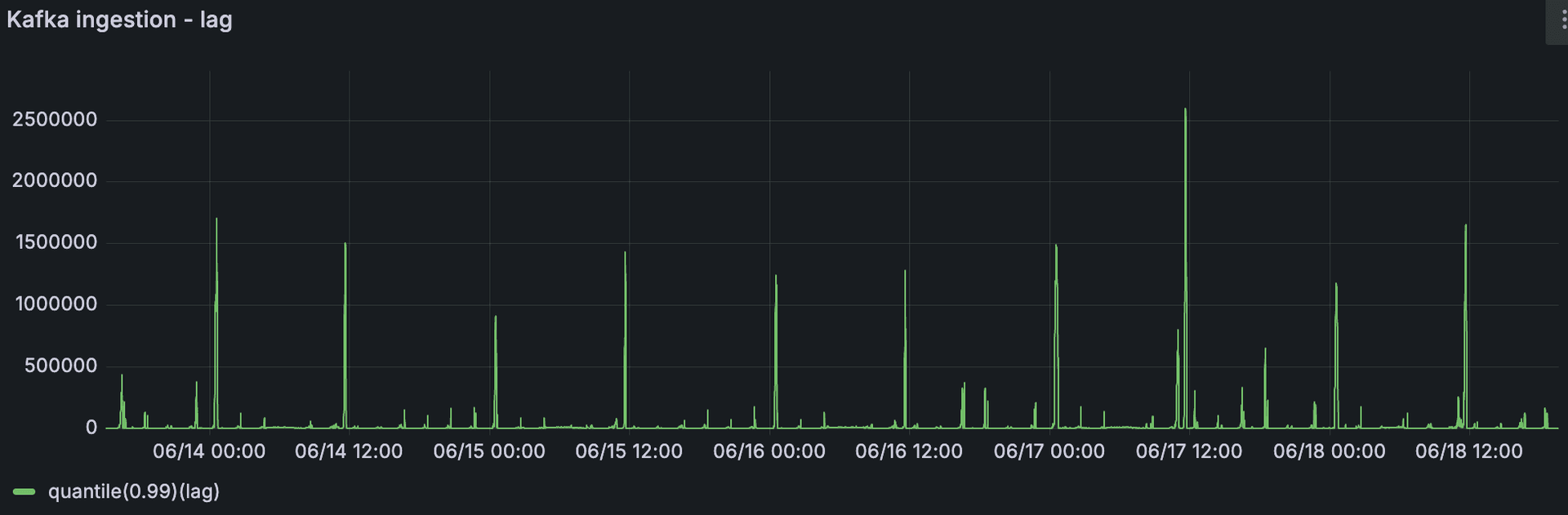
Consolidations are the optimization decisions Karpenter makes to reduce cluster costs. Even if the number of pods remains constant, Karpenter can detect underutilized nodes and decide to remove them, rescheduling their pods onto other nodes. This process helps keep your infrastructure lean and efficient. For example, the following graph shows Karpenter's activity in one of our clusters over a 48-hour period, including node provisioning, termination, and consolidation actions, even though there were no significant fluctuations in workload.
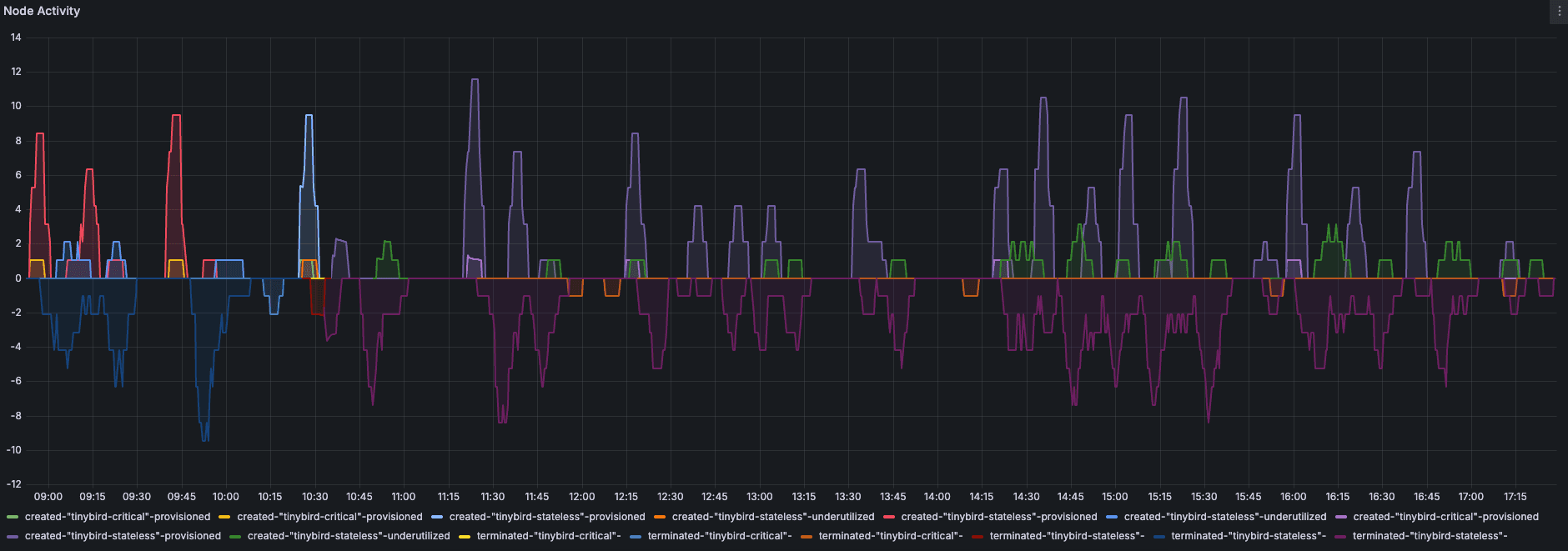
However, every consolidation involves moving pods, so it's crucial to prepare your workloads to avoid 500 errors or micro-downtimes. Here are some best practices we've found essential:
- Graceful shutdowns: Make sure your pods have properly configured graceful shutdown periods so they can terminate cleanly.
- Pod Disruption Budgets (PDBs): Set up PDBs to ensure not all pods from a deployment are terminated at once, maintaining service availability.
- TopologySpreadConstraints: Use these to distribute replicas evenly across availability zones, improving resilience and fault tolerance.
With your deployments properly configured for graceful shutdowns, PDBs, and topology spread constraints, you can let Karpenter consolidate nodes whenever it finds optimization opportunities.
Here are three Karpenter settings that have worked exceptionally well for us:
1. Don't restrict Karpenter to a small set of instance types
One of the first instincts when implementing Karpenter is to restrict it to only the latest instance generations, such as r7 or m7. However, this is actually a mistake. Limiting Karpenter in this way can reduce its ability to optimize for cost and availability, as it works best when it has access to a broad range of instance types and families.
Embrace Karpenter's philosophy: "Forget about nodes." The more instance types and families you allow, the better Karpenter can optimize and the greater your potential savings.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: tinybird-node-pool-stateless
spec:
expireAfter: 168h
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: tinybird-stateless
requirements:
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- "4"
- key: topology.kubernetes.io/zone
operator: In
values:
- us-east-1a
- us-east-1b
- us-east-1c
- key: kubernetes.io/arch
operator: In
values:
- amd64
- arm64
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
taints:
- effect: NoSchedule
key: tinybird.co/stack
value: stateless
2. Use Disruption Budgets for critical periods
If you know you have a critical workload window (e.g., 8am–12pm), set a Disruption Budget to prevent consolidations during that time, keeping your cluster extra stable when it matters most.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: my-node-pool
spec:
disruption:
consolidationPolicy: WhenUnderutilized
budgets:
- nodes: "30%" # Allows up to 30% of nodes to be disrupted
reasons:
- "Empty"
- "Drifted"
- "Underutilized"
- nodes: "0" # Prevent consolidations during peak traffic period
duration: "4h"
schedule: "0 8 * * *"
3. Set node expiration policies
We recommend configuring nodes to expire and recycle every 24 or 48 hours. This not only helps mitigate issues like memory leaks—by ensuring pods are recreated before they crash due to OOM errors—but is also extremely useful for security. By regularly recycling nodes, you ensure that each new node installs the latest critical security patches at boot time, keeping your cluster up to date and secure.
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: ttl-based-disruption-pool
spec:
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: 48h # Nodes expire after 2 days
Karpenter deployment: What you need to know
A critical best practice when deploying Karpenter is never to run the Karpenter controller on the same NodePools that it manages. The reason is simple: if the node running the Karpenter controller is removed or fails to start, Karpenter itself becomes unavailable and cannot provision new nodes—potentially leading to cluster downtime.
One approach is to create a small, dedicated NodeGroup (using Terraform, for example) with a couple of nodes, disable autoscaling, and schedule two Karpenter replicas there. However, this comes with drawbacks: those nodes are often underutilized, you have to maintain and update the NodeGroup manually, and it undermines the core benefit of Karpenter—freeing you from node management and manual updates.
The recommended solution is to deploy Karpenter on AWS Fargate
Fargate is a serverless compute engine managed by AWS that integrates seamlessly with EKS. By defining a Fargate profile with a selector for the Karpenter pods, you ensure that Karpenter always runs independently of the nodes it manages. This setup eliminates the risk of Karpenter becoming unavailable due to node disruptions and removes the operational overhead of maintaining a dedicated NodeGroup.
resource "aws_eks_fargate_profile" "karpenter_profile" {
cluster_name = aws_eks_cluster.eks_cluster.name
fargate_profile_name = "karpenter"
pod_execution_role_arn = aws_iam_role.karpenter-fargate.arn
subnet_ids = ["<subnet_1>", "<subnet_2>"]
selector {
namespace = "karpenter"
labels = {
"app.kubernetes.io/name" = "karpenter"
}
}
}
In your EKS cluster, Karpenter pods scheduled on Fargate will appear as nodes, but instead of a specific EC2 instance type, you'll see the resources allocated within Fargate.
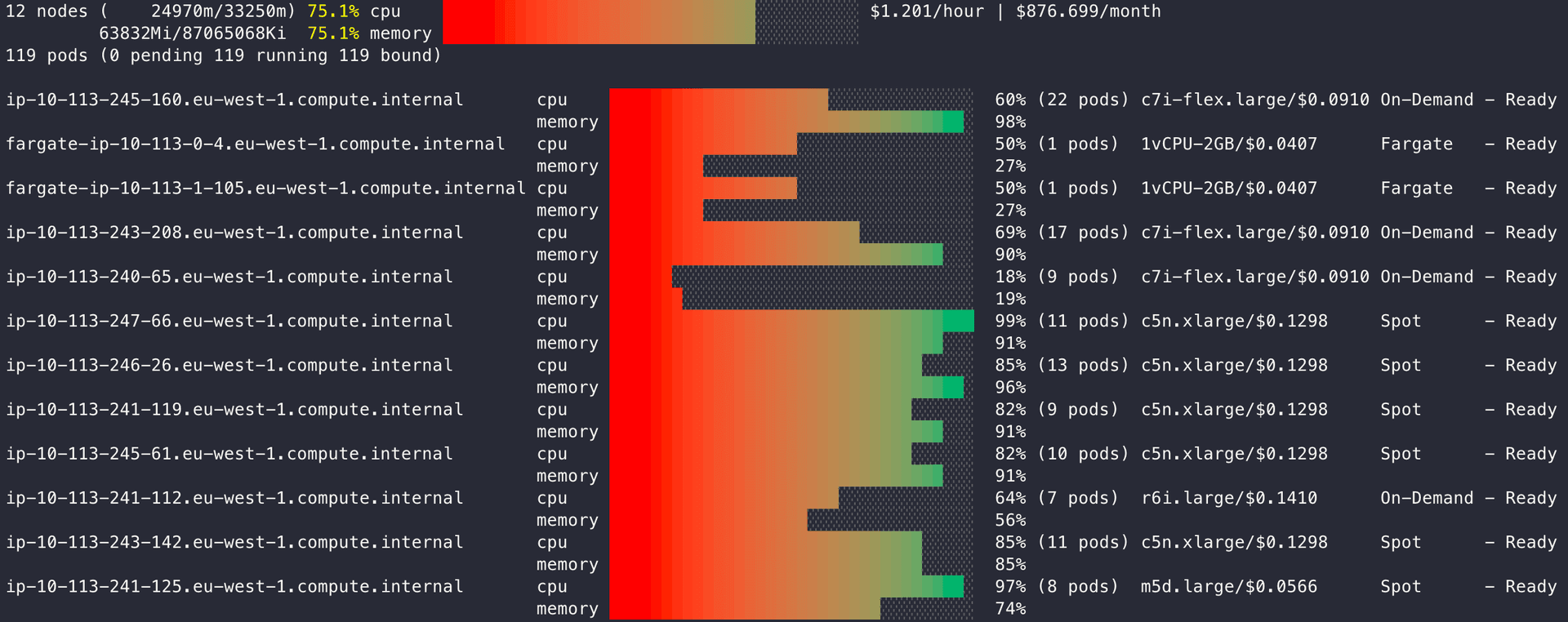
From Zero to Ready: Minimizing node and pod startup times
Karpenter is impressively fast at scaling—capable of provisioning a new node in under a minute. But launching a node is just the first step. The real challenge is reducing the total time until your pods are actually scheduled and ready to serve traffic.
Here are two quick tips that have made a big difference for us:
1. Local image caching with Harbor and Kyverno
While Karpenter+KEDA+Tinybird can get a node up in less than 45 seconds, the next bottleneck is pulling container images. On a fresh node, Kubelet must download all required images from the registry, and some services use large images. To speed this up, we use Harbor, an open-source registry, as a local cache within our cluster. When a new node is provisioned, it pulls images from Harbor instead of fetching them from ECR every time. We automate this with a Kyverno policy that dynamically rewrites ECR image DNS to point to our local Harbor cache at pod startup.

apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: ecr-replace-image-registry-to-harbor
annotations:
policies.kyverno.io/title: Replace Image Registry ECR to Harbor
spec:
background: false
rules:
- name: replace-image-registry-pod-containers-legacy
match:
any:
- resources:
kinds:
- Pod
namespaces:
- tinybird
mutate:
foreach:
- list: "request.object.spec.containers"
patchStrategicMerge:
spec:
containers:
- name: "{{ element.name }}"
image: "{{ regex_replace_all('<accountID>.dkr.ecr.eu-west-1.amazonaws.com/(.*)$', '{{element.image}}', 'harbor.tinybird.app/aws/$1' )}}"
2. Using BottleRocket AMIs
All our nodes run on BottleRocket, an open-source Linux distribution sponsored and supported by AWS, purpose-built for running containers on ECS or EKS. BottleRocket includes only the essential system packages, which reduces the attack surface and vulnerability risk—and, importantly, it significantly cuts down node boot times.
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: microservices
spec:
amiFamily: Bottlerocket
# removed additional config
userData: |
[settings]
[settings.kubernetes]
registry-qps=25
registry-burst=50
serialize-image-pulls=false
tags:
managed-by: karpenter
tinybird.k8s.workload: critical
karpenter.sh/discovery: my-cluster-name
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 60Gi
volumeType: gp3
deleteOnTermination: true
- deviceName: /dev/xvdb
ebs:
volumeSize: 120Gi
volumeType: gp3
deleteOnTermination: true
throughput: 500
iops: 3000
snapshotID: snap-09a75da610666d675
By combining these strategies, we've dramatically reduced the time from node provisioning to having all pods up, running, and ready to serve traffic by 2 minutes—a significant improvement that helps us maintain responsiveness during scaling events.
Conclusions
Adopting Karpenter has been a game-changer for our infrastructure at Tinybird. By moving away from the operational complexity of traditional node group management and embracing Karpenter's intelligent, just-in-time autoscaling, we've unlocked a new level of efficiency, resilience, and cost savings. Our AWS bill has dropped significantly, our clusters scale faster and more reliably, and our team spends far less time on manual operations.
But the real value goes beyond just cost reduction. With Karpenter, we can focus on what matters most: delivering features and value to our customers, not wrestling with infrastructure (which is, appropriately, the same value proposition that Tinybird gives to our customers). The combination of Karpenter, Spot Instances, KEDA, and smart observability—powered by Tinybird has allowed us to build a platform that is both robust and agile, ready to handle rapid growth and unexpected spikes without breaking the bank or sacrificing reliability.
We've also learned that success with Karpenter isn't just about flipping a switch. It's about understanding your workloads, preparing your deployments for disruption, leveraging local caching and optimized AMIs, and following best practices for controller placement and node diversity. The payoff is worth it: faster scaling, higher availability, and a platform where infra fades into the background and just works.
If you're running Kubernetes at scale, especially on AWS, Karpenter is a tool you can't afford to ignore. And if you want to see how real-time analytics and observability can supercharge your autoscaling, check out what we're building at Tinybird. Our own platform is not just the engine behind our analytics APIs—it's the secret sauce that helps us scale smarter and react faster.
Ready to make your infrastructure leaner, faster, and more resilient? Give Karpenter a try and let Tinybird help you unlock the power of real-time data in your stack.