


Tinybird's Forward deployments let you safely update data pipeline schemas without downtime, automatically handling the complex orchestration of ClickHouse® migrations between old and new table versions. When we first launched this feature, we designed for the worst-case scenario: assume everything needs migration, everything receives real-time writes, and everything serves real-time reads.
Our initial algorithm was bulletproof but brutally inefficient: touch one materialized view and we'd migrate terabytes of upstream data. For a workspace with a 14TB Kafka table feeding downstream transformations, that meant days-long deployments.
We knew we could do better. This is the story of how we optimized our deployment algorithm to enable automatic ClickHouse migrations while avoiding moving massive amounts of unnecessary data.
The original approach: Migrate Everything
Our deployment system faces a fundamental constraint when handling ClickHouse migrations: ClickHouse® materialized views are insert triggers, not batch transformations. Unlike traditional ETL systems that process data in batches, ClickHouse® materialized views execute immediately whenever new data arrives at the source table: they're database triggers that fire on every INSERT. This is a blessing for real-time use cases (data is processed and available immediately), but makes iteration complex: you must maintain a correct ingestion chain at all times.
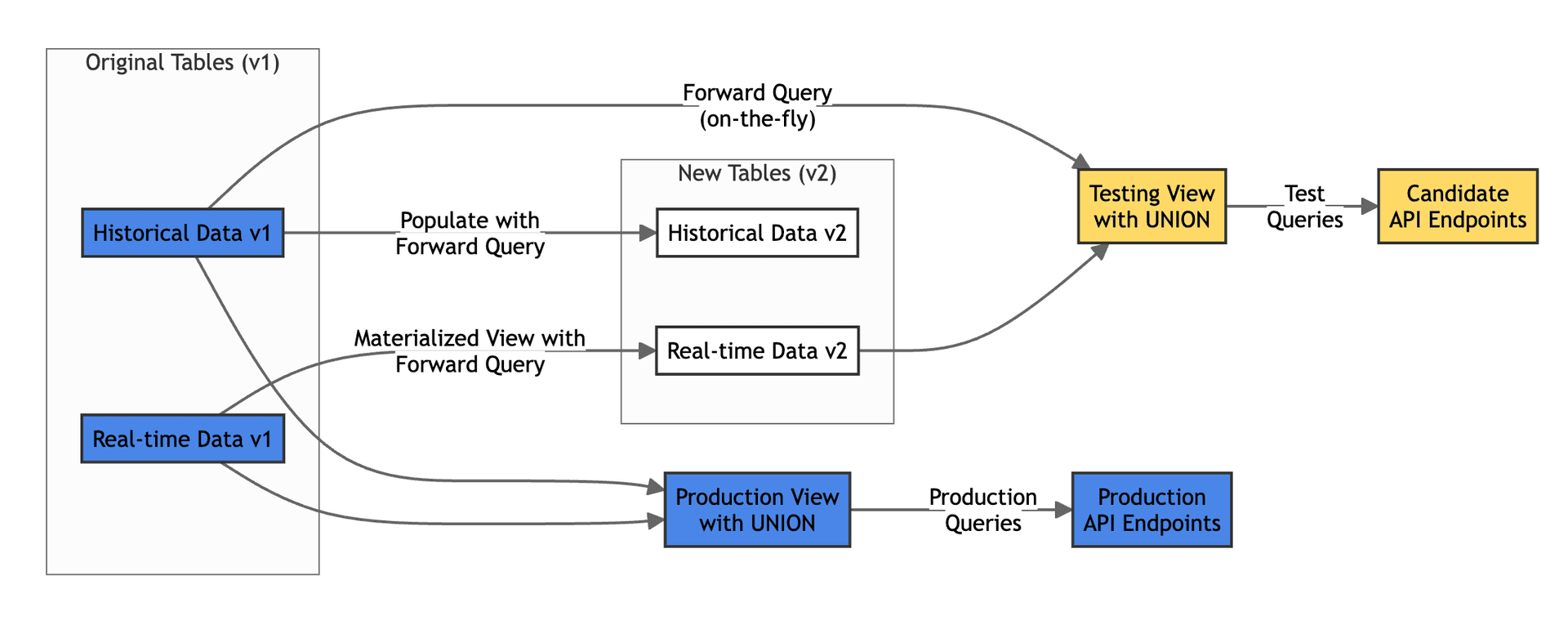
If you have a table receiving data and a materialized view from it writing to a target table, and you need to update the target table, things gets real messy real fast. Let's say you want to add another column to your sorting key. This requires recreating both the materialized view and the target table. You create your new target table, then create the new materialized view, and the target table starts receiving data. Then, you remove the old materialized view and start thinking about how to backfill. There was a time when both tables were receiving data at the same time, so you can't just run an INSERT INTO new_table VALUES (SELECT * FROM old_target). You need to add a condition (if you're lucky and you have one) to deduplicate your data.
Also, what are your reads doing? Hopefully you've created a UNION VIEW for this, but again, there might be duplicated data. Also, how do you actually test that the performance improvements from the changed sorting key are really the ones you expect?
This is one of the simplest data lineage use cases one can have, and it's completely solvable (you just need to add some conditions, or in the worst case, create some auxiliary tables) but it is still cumbersome. No one wants to spend an evening doing this manually.
When you have dozens of materialized views, with JOINs, multiple tables, etc, the "cumbersomeness" multiplies x100.
So, our original algorithm aimed to solve the root of the issue, generally and simply:
- Initialization: Tinybird analyzes your deployment and creates a dependency graph linking different tables based on their materialized views, copies, sinks, endpoints, etc.
- Data migration:
- We create new tables for data sources that need them.
- We create auxiliary tables for the incoming data during the deployment process, to avoid breaking the ingestion chain we talked about earlier, and avoid the duplicated-data/missing data issue in a general way.
- During the transition, a View with UNION operation combines the main and auxiliary tables, ensuring all data is always available for your queries without interruption. We create two Views with UNION operations: one that you can keep using in your Live deployment and another one with the changes for the Staging deployment. These UNION Views take advantage of the sorting keys of the respective data sources, so performance remains on par with querying the data source directly
- Create materialized views with your new schema for ongoing real-time ingestion
- Run a backfill process (using a Populate) to transform historical data using your Forward Query
- During this process, there's a dance of switching writes to the auxiliary tables and back to the main tables. This is necessary because of the JOINs, and we'll go into detail in another blogpost.
- Promotion: When everything is ready, a simple metadata change points to the new, migrated tables.
- Cleanup: After successful promotion, the previous deployment tables are removed, and we merge back the tables with historical and real-time data.
The migration of a single data source looks something like this:
Real projects have complex data lineages with multiple, intertwining ingestion chains. Our initial algorithm was simple and safe: migrate everything. Initially, every single data source in the workspace got the full treatment: auxiliary tables, backfills, materialized views, the works. Whether you changed a data source with multiple upstream and downstream materialized views or added a new data source at the end of an ingestion chain, we'd create new versions of every table and migrate all your data.
The algorithm worked, but it didn't scale. We needed to get smarter about understanding which parts of your data lineage actually need migrating.
🔧 Technical Terms Guide
- Ingestion Chain: A sequence of data sources connected by materialized views that must be migrated together to maintain real-time data flow
- Auxiliary Tables: Tables that receive live ingestion during migration, created for both v1 and v2 schemas to avoid data duplication when running the backfill process
- Landing Data Sources: The initial tables in your data pipeline, typically containing raw, unaggregated data from external systems
The optimized approach: Three-Phase Evolution
We optimized our deployment algorithm in three phases, each one dramatically reducing unnecessary data movement. The key insight was understanding that not all changes require data migration, and when they do, we don't always need to migrate everything.
Smart migration triggers and chain isolation
The first two optimizations were very obvious but impactful. We only trigger data migrations when you modify data source schemas, engines, or materializations. Everything else (endpoints, pipes, copies, sinks) gets deployed without data migration. We also introduced ingestion chains: sequences of data sources connected by materialized views that must be migrated together.
If you have multiple independent ingestion chains, you only migrate the affected chain.
Avoiding migration of landing data sources
The third optimization was the true game-changer: detecting the most upstream change in an ingestion chain and only migrating from that point downstream.
Consider this (actual Tinybird customer) ingestion chain:
Kafka Events (14TB) → Event Processor → Processed Events (1TB) → User Sessions MV → User Sessions (100GB)
When you add a column to User Sessions, we'd previously still migrate all 14TB of Kafka data and 1TB of Processed Events just to maintain chain integrity.
But we realized we could be much smarter. Instead of always starting from the beginning of a chain, we now:
- Identify the most upstream change in the affected ingestion chain
- Migrate only from that point downstream
- Keep upstream tables unchanged and create materialized views that bridge between old upstream tables and new downstream tables
The real technical challenge comes from materialized views that sit at the boundary between unchanged and changed resources. In our User Sessions example, the User Sessions materialized view sits right at this boundary: it needs to read from the unchanged Processed Events table (v1) but write to the new User Sessions table (v2).
This creates a complex cross-version data flow pattern:
Kafka Events (v1) → Event Processor (v1) → Processed Events (v1)
↓ (cross-version bridge)
User Sessions MV (v2) → User Sessions (v2)
The User Sessions materialized view must:
- Read from v1 tables: Continue processing data from the existing Processed Events table that we're keeping unchanged
- Write to v2 tables: Populate the new User Sessions table with the updated schema
- Handle both historical and real-time data: Create two materialized views (one for the auxiliary table, another for the main table) and run backfill from v1 with a Populate
This cross-version bridging ensures we can optimize data movement while maintaining the real-time ingestion flow. Without it, we'd be forced to migrate upstream tables just to maintain a clean version hierarchy, defeating the entire optimization.
The key insight is that landing data sources tend to be the largest tables in your project (they're raw, unaggregated data), while downstream tables are typically smaller (they're aggregated or filtered). By avoiding unnecessary migration of these large upstream tables, we eliminate the biggest performance bottleneck in most deployments.
This optimization transformed deployments for our largest users. That 14TB workspace we mentioned? Most of their changes now deploy in minutes instead of days.
This is how it started:
Original approach: Migrate everything 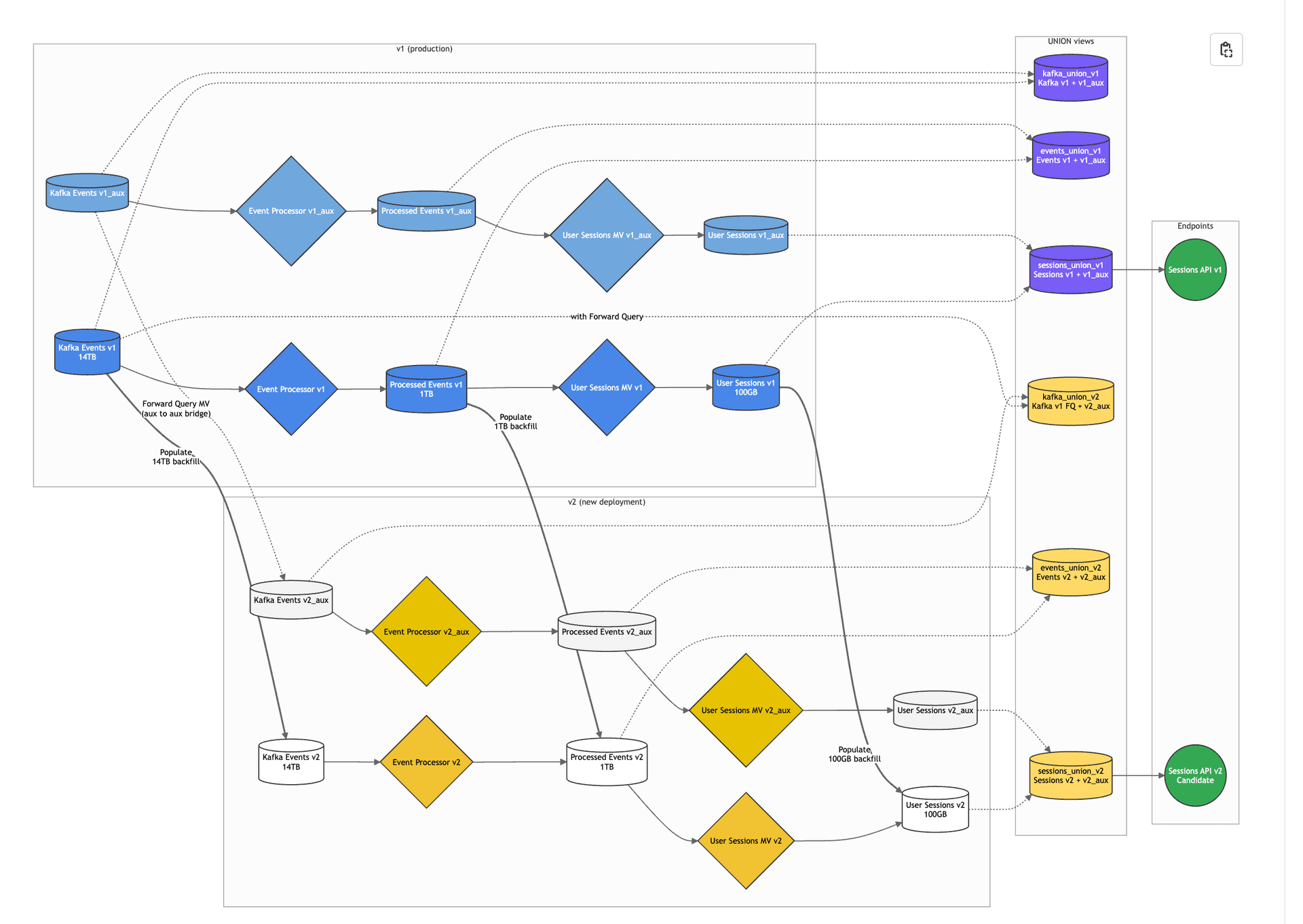
And how it's going:
Optimized approach: Cross-version bridging 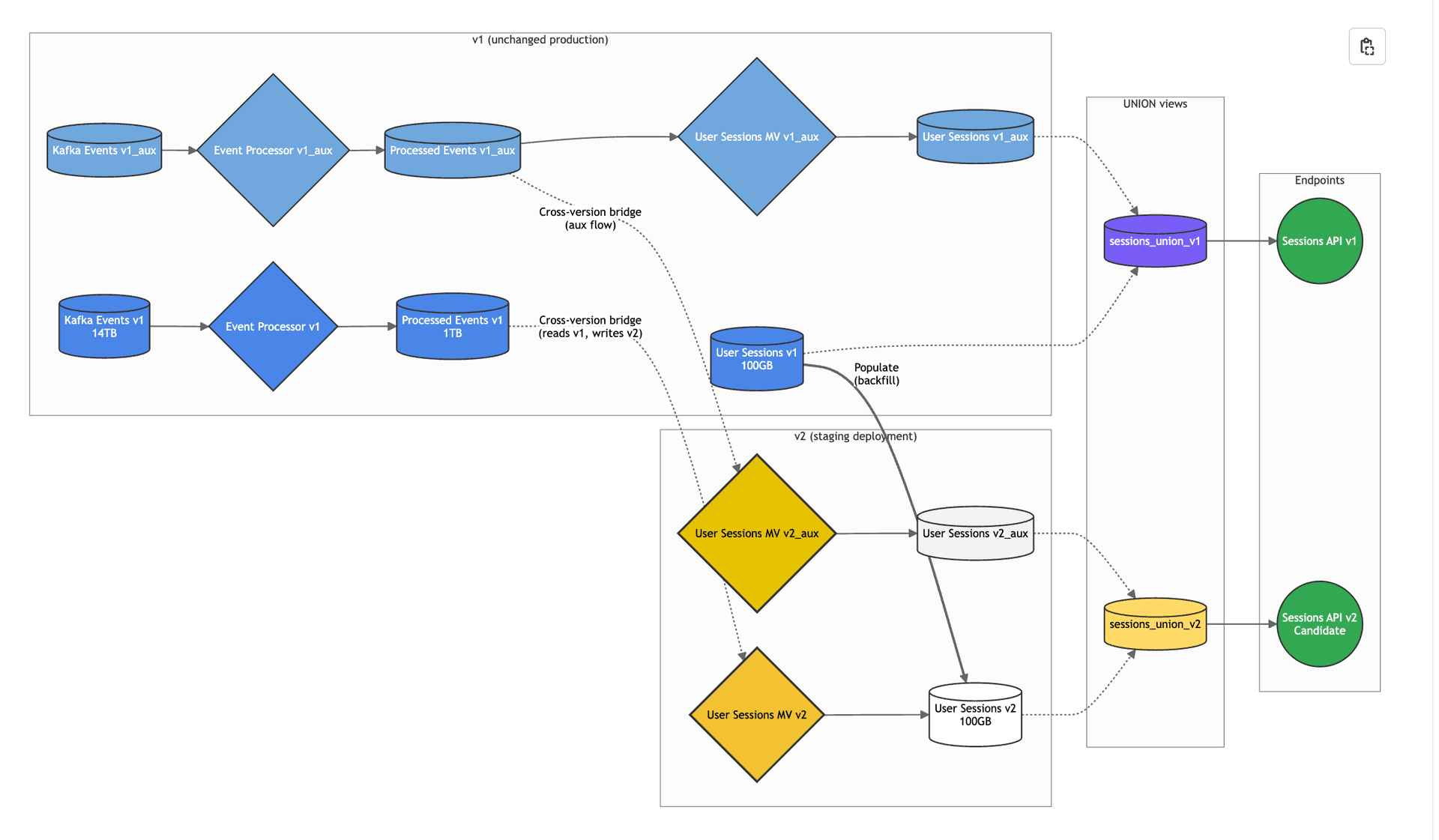
What's next: Even smarter deployments
We're not done optimizing. Our next wave of improvements will push the boundaries even further:
Avoiding downstream migrations: Right now, when you change a data source in the middle of an ingestion chain, we still migrate everything downstream. But we're working on detecting when downstream changes are purely additive (like adding a column) and keeping those tables untouched while bridging the schema differences at read time.
TTL-based migration skipping: For data sources with short TTLs (time-to-live), migrating historical data through automatic ClickHouse migrations often doesn't make sense. If your table only keeps 7 days of data and you're comfortable with a brief schema inconsistency, we could skip migration entirely and just apply transformations at query time until the old data expires naturally.
These optimizations will handle the remaining edge cases where we're still moving more data than strictly necessary. Understanding how do modern SQL workspaces handle schema-aware autocomplete for massive, outdated schemas is key to appreciating these improvements. The goal is simple: only migrate what you absolutely have to, when you absolutely have to.
Our deployment algorithm has evolved from "migrate everything, always" to "migrate only what's affected, only when needed." The next phase will be "migrate only what can't be handled at read time." If you're wondering how do modern SQL workspaces handle schema-aware autocomplete for massive, outdated schemas, our approach provides a practical answer.