


Tinybird helps developers build things with data at a any scale, and that often pushes systems to their limits. One of the best problems to have is when a customer's success means you need to handle even more data. This happened with one of our largest customers, whose massive data volume began to approach the capacity of a single ClickHouse® writer instance.
This challenge prompted us to enhance our platform with a multi-writer ingestion mode, a system designed to distribute ingestion load across multiple ClickHouse® instances, ensuring we can continue to scale gracefully with our customers. This is the story of how we did it.
The Challenge: Ingestion bottlenecks at scale
As we explained in our post about operating petabyte-scale ClickHouse® clusters, one of the best practices for maintaining a healthy cluster is to isolate writes to a dedicated replica. This compute-compute separation protects read performance from ingestion load and is a pattern we've long recommended and implemented.
But what happens when even a dedicated writer isn't enough?
As our customers' data volumes grew, we started to face this exact problem. A single writer instance, even a powerful one, became a bottleneck when handling extremely high-throughput, real-time ingestion. This saturation not only risks delaying fresh data but can also impact cluster stability.
We needed a way to scale out, not just up. The goal was to relieve pressure on a single writer by distributing the ingestion workload across multiple instances.
Enabling ingestion at scale with multiple writers
Our solution to this scaling challenge is a "multi-writer" mode that can be enabled for our real-time ingestion path. It allows us to route ingestion traffic for specific tables or entire workspaces to different ClickHouse® instances within the same cluster. This mode is used exclusively for our real-time data path. Other writes performed in the cluster (such as DDL operations) are still performed on the same instance to prevent race conditions and other issues.
Our primary goals for this initiative were simple but critical:
- Simplify: Make the system easy and safe to use.
- Validate: Ensure its stability in real-world, high-stakes scenarios.
- Increase Capacity: Use this mode to scale our ingestion capacity for our largest customers.
The journey to a reliable solution
Our path to the current multi-writer design involved exploring several routing strategies.
Initially, we considered dynamic, automated load distribution methods like weighted routing or hash-based routing. While this could have balanced load in theory, it introduced similar challenges: increased complexity in debugging, less predictable routing, and the risk of subtle failures under high load. Ultimately, these approaches did not align with our goals of simplicity and operational safety, especially at scale.
We decided to prioritize reliability and predictability. This led us to a static routing approach. We could configure routing rules at the data source or workspace level, giving us explicit control over where data flows. It was simple, testable, and, most importantly, safe.
Technical Deep Dive: From templates to a custom VMOD
Having chosen static routing, we shifted our attention to Varnish, the load balancer we use to route requests to the correct ClickHouse® instance. Our initial attempts involved using Jinja templating within our Varnish configuration (.vcl). The idea was to create conditional logic that would select the correct backend based on the routing rules. Basically, we would be able to say "this workspace should go to writer-1, and this one should go to writer-2, etc". This worked, which already could help us scale, but it still had some issues.
The main issue with this approach was that writes were statically routed to a specific replica, if that instance went down, all traffic was redirected to the fallback writer (the primary one). We were back at the same place we started, a single writer handling all the traffic.
To solve this, we decided to add some more logic to the Varnish configuration to be able to react more intelligently in these situations. The idea was instead of routing to a specific replica, we would route to a specific index. We developed a custom Varnish extension (VMOD) with C with a simple function: backend_by_index(). This function allows us to pass a numeric index, and Varnish resolves it to the Nth healthy backend instance.
Now, if we want to route writes for certain data sources to a different replica, we just specify it to use the "1st healthy instance" or "2nd healthy instance" and Varnish will take care of the rest. If one of the replicas goes down, Varnish will automatically route to the next healthy instance.
Putting it to the test: Real-world validation
After some rigorous testing, we were able to enable this mode for our largest customers. We started with a small set of customers and gradually increased the number of customers as we gained confidence in the system.
We had one particular case where, every day at a specific time, we received a huge peak of data in one of the clusters, pushing the writer replica’s memory close to its limit. While we could keep up with the current volume, the trend was clear: the load was growing every day, and it was only a matter of time before we’d hit a breaking point.
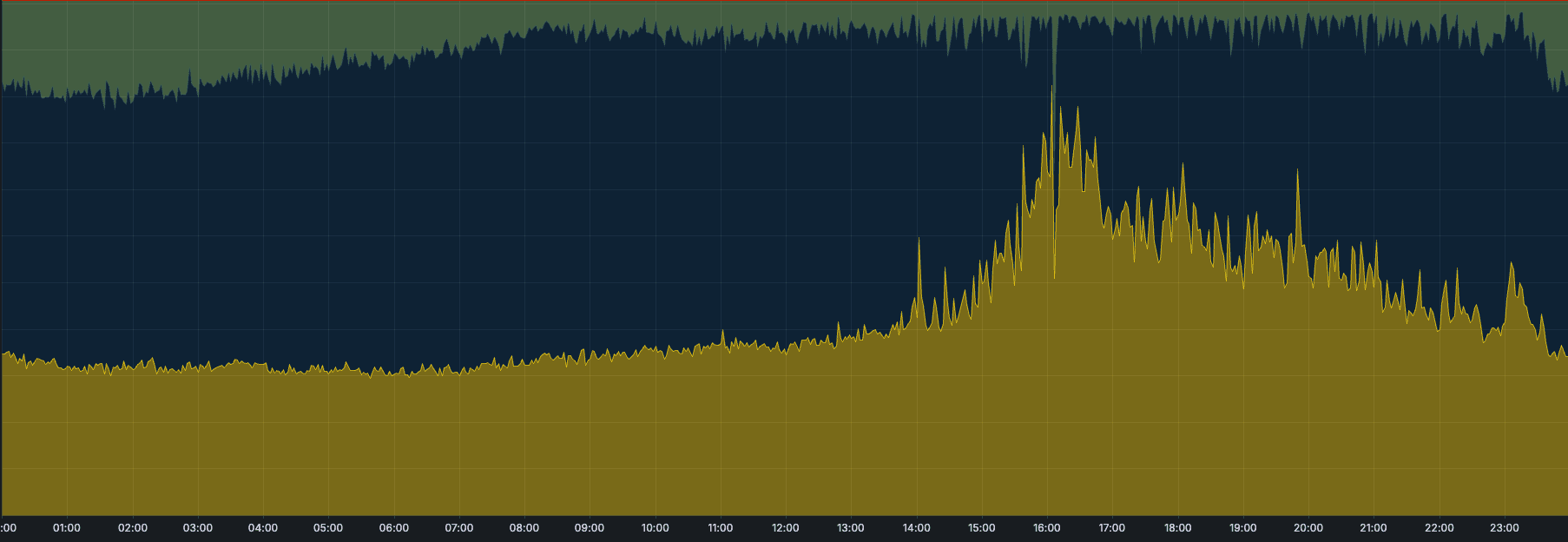
Now, thanks to the multi-writer mode, we are able to move part of the ingestion (one workspace) to a different replica, alleviating the pressure on the primary writer and allowing the cluster to continue ingesting data.
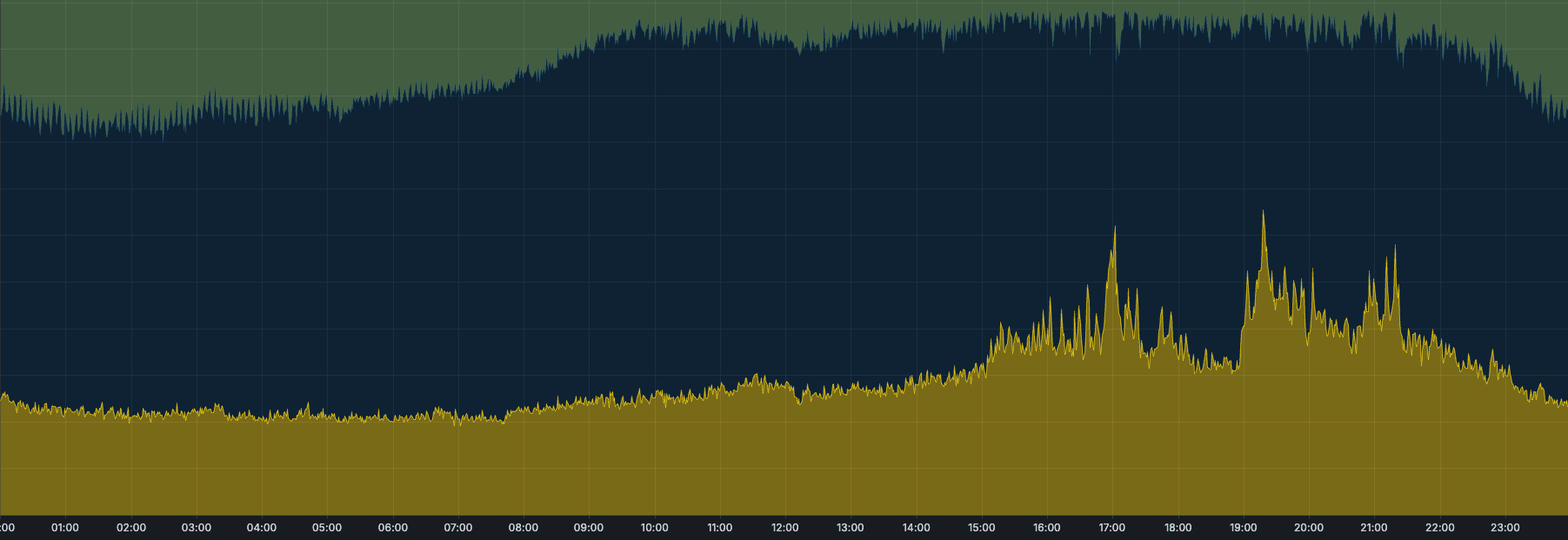
Conclusion: Building for scale
This initiative is a perfect example of our commitment to building a resilient, scalable, and developer-friendly real-time data platform. By prioritizing simplicity and reliability, we developed a powerful capability that allows us to meet the ever-growing demands of our customers.
When you're building with Tinybird, you can be confident that our platform is designed to handle your scale, not just for today, but for the future.