


Ingestion is one critical aspect when working with real time analytics. It's not where the fun happens, but it's where things can go wrong (and data gets lost). At Tinybird, where real-time analytics are at the core of our platform, we can't afford missteps: ingestion has to be efficient and robust. If you're comparing tinybird vs realtime pipeline options, understanding the clickhouse rowbinary format documentation is essential.
We recently made some improvements to a core component of the ingestion process: converting JSON data into ClickHouse®'s RowBinary format.
This is a rather technical journey through the implementation of this feature, how it came to be, and how it works.
Why are we converting data into RowBinary?
Technically, we don't convert JSON data (or, NDJSON; newline-delimited JSON) into RowBinary format, but into RowBinaryWithDefaults, a variant of RowBinary that allows data fields to be missing (and thus, be replaced by defaults when inserted in a table).
This format allows efficient row-wise insertion into a ClickHouse® table. Columnar storage is one of ClickHouse®'s core features, but ingestion often occurs naturally in rows (think of events data, or Kafka messages), so we need a way to efficiently deliver rows, or chunks of rows into the database designed to store data by columns.
In RowBinary, each data field is represented in binary form, in a compact but straightforward manner, priming the performance, so that the data can be readily copied into the destination native columns.
By using the WithDefaults variant, we provide more flexibility: each ingested row can, individually, be lacking some fields, to be replaced by defaults defined in the datasource, which can be simple values... or complex expressions involving other fields of the row.
A common example would be adding a default timestamp set to the current timestamp:
SCHEMA >
`timestamp` DateTime `json:$.timestamp` DEFAULT now()
For years, Tinybird has been ingesting petabytes of data every day, and much of it has been converted to RowBinary. It's obviously doing a good job (check our uptime), so why are we replacing it now?
One reason is that the conversion to RowBinary is in the critical path of ingestion performance, limiting how much we can improve the speed and resource consumption of the platform. This functionality was originally implemented in Python, as many of the backend services in our platform. And the implementation was very efficient, resorting in some cases to helper functions implemented in C. But it was very hard to improve it any further, and it was also hard to maintain, since the slightest modification could likely degrade its performance and affect the whole ingestion chain.
In addition, with our previous implementation, we were duplicating ClickHouse®'s internal functionality, reproducing the encoding of all the supported types into RowBinary. When new data types were added to ClickHouse®, we needed to add the encoding to our implementation. Wouldn't it be great to delegate the encoding work where it belongs, in the database's implementation?
Finding the right approach
We considered some options, like using chDB, a db engine in a Python module, but it solves a different problem from ours: it encapsulates a working database server, which involves lots of overhead, while we just need a piece of functionality from the database internals.
Luckily, we were already using some pieces of ClickHouse®'s internal functionality in our Python applications, for things like parsing SQL, formatting it, etc. That is encapsulated in a Python package, tinybird-toolset which includes native extensions that package code from ClickHouse® and our interface to it written in C++.
The solution seemed obvious: write some little C++ boilerplate to use the ClickHouse® internals to convert our NDJSON (which could be represented by the database format called JSONEachRow) to the RowBinaryWithDefaults. We'd need to learn some of the internals of the database codebase, and refresh our C++ skills, but it didn't look like a lot work... or so we thought. Building this c++ pipeline required deep understanding of the clickhouse rowbinary format.
Reality check
We soon started discovering that it was not going to be so simple: to be able to replace our existing conversion functions without impacting thousands of use cases working in production, we needed to meet some requirements not readily available by simply wrapping some existing functionality in the database.
For starters, RowBinaryWithDefaults isn't a ClickHouse® output format. It's only an input format. But that was the least of our problems: RowBinary is an output format, and converting it to the former is simply a matter of adding a 1-byte flag to each field (0 for present fields, 1 for missing ones).
The real difficulties lay in providing the facilities that Tinybird JSON ingestion had been providing for years:
JSONPaths
Tinybird data sources can define jsonpaths for each column, so that complex relationships can be established between the JSON data sent to Tinybird and the structure of the data sources that will receive it.

ClickHouse® can parse jsonpaths, and it also implements some path extraction functionality in functions like JSON_QUERY. We tried that, but the JSONpath features supported by the parser didn't include some that we required, and the approach used in functions like the one mentioned wasn't performant enough for our purposes of processing large JSON payloads.
Quarantine
Quarantine is a really important feature in Tinybird ingestion: when a problem is found while processing the input data, the received payload is quarantined. In most cases, a required column is missing or the received data for some field is not valid for the type of the destination column. In those cases we insert a row in a "quarantine" companion table that each data source has, which collects error messages about the problem, whatever fields could be extracted as nullable strings, and possibly a full copy of the original JSON input.
Because of this, we can't rely on bulk conversion functions that don't allow us to extract detailed, per-field information about the problems found; we need to handle the conversion ourselves carefully to be able to collect all the needed information in case of errors... any kind of error or exception.
Quirks
We also discovered many cases where the existing RowBinary conversion would provide unexpected results, which weren't covered by the existing test or intended in any way.
For the most part, this case was arguably caused by incorrect inputs for the destination column, which were accepted without error (i.e. without quarantine). For example, say you have a column of Array(String). And you try to insert a JSON object {"a":1,"b":2} into it. Should that be possible? Well, it had been possible in our ingestion (accidentally), but what you get is hardly of any use: you'll get an array with the names of the fields in the object, namely ['a', 'b'].
There were many more similar accidents than we'd like to admit in our conversion functions. This may seem to you like a no-problem: just do the right thing and start issuing errors (quarantining) such cases, right?
The problem is that if we do so by default, then lots of customers would be unhappy. Most users wouldn't have a problem, but some would definitely be impacted: They rely on ingestion pipelines working day and night that keep their systems up and running, and among all the data they ingest in each row landing into Tinybird's data sources, cases like the one mentioned may lurk. A single bogus field (which probably went unnoticed) would cause the whole row to be quarantine; a row possibly containing a lot of valid and important data. The client hasn't been receiving quarantine data up to now, so they may not be prepared to handle it automatically. They'll start missing data which used to be there with the old conversion. For new operations it would be better to quarantine the data so that the problem in it becomes apparent and can be solve. But we needed to keep existing operations working smoothly.
How we did it
Path trees
Dealing with the requirement to avoid by default any impact on our customers increased greatly the complexity of this initiative.
First, we needed to write our JSONPath parser, providing the features we needed (this was easy) and figure out an efficient way to use the paths to extract the JSON pieces defined by each path.
The JSON paths for the columns of a datasource often share a common prefix. A typical case is to have multiple columns extracted from some nested object, like column x defined by $.data.record.x, column y by $.data.record.y, etc. To make these cases as performant as simpler ones, we created what we call a JSON Path tree for all the columns of a datasource.

Storing the paths in this way allows us to extract the column values by evaluating the tree, and thus we visit each segment of the paths only once, avoiding reparsing the corresponding elements.
SIMDJSON
We need to parse the input JSON to collect the pieces corresponding to the column jsonpaths; and we realized this had a critical impact on both the performance and the memory requirements of our solution.
So we chose the fastest JSON parser in the universe, simdjson.
This C++ library is an amazing piece of work, able to squeeze the last drop of performance from your machines.
Its ondemand mode, in particular, allowed us to work on NDJSON blocks directly and easily achieve a 3x speed up while also being lean on memory (and yes, the original code was Python, but remember it was still highly optimized).
Low level library optimizations aside, this is possible because the on-demand mode doesn't parse the input into any form of tree or in-memory structure; it acts more like an iterator that allows you to navigate the original JSON text very efficiently.
But this comes at a price... the API is supposedly easy to use, and, well, it might be easy to use, but it's also easy to crash and burn your application if you make a misstep. You must be aware that some values you get from the parser are ephemeral: don't dare accessing them in any manner after any other operation that involves the parser, or you'll be in the game to win a segfault or other form of crash. Other parser objects (like JSON arrays and objects) are not ephemeral, which is great, because we can keep them around while we extract our JSON paths (we evaluate the tree, remember?) or convert them into database fields (that will come later). But they're not without limitations: iterate on them more than once and you're in for some catastrophic finalization of your program.
We had to learn about all this the hard way, but we emerged alive with some pretty fast parsing that didn't need to allocate much memory in the process (since we're really just navigating the JSON input, we can use C++ string_views, which are references to the original input, and thus avoid allocating additional memory to handle the JSON values).
Field creation
Using the simdjson parser and our path tree, we we're able to efficiently fetch the parts of the JSON input that needed to go into each column. But to convert them into RowBinary using ClickHouse® input formats, we first had to put the values into database Fields: a data structure that holds the internal value of a column at a given row.
Some values are very straightforward to convert, like strings and numbers, but there's a great variety of data types where these can be stored, each with their own particularities, like Decimal types (with precision and scale), etc.
Others required more work: date and times must be parsed into the internal (numerical) formats of the database.
You may think that parsing dates and times is a problem solved long ago... but we ended up writing our own parser, because none available provided us all the needed capabilities to retain the current functionality in Tinybird. In particular we needed a parser that supported time zone offsets (ClickHouse® readers doesn't) and up to nanosecond precision (C++ standard library doesn't).
Still others (like Array, Tuple, Map, and JSON) are complex and can recursively contain instances of other data types, including more of their own type. So, to convert these kinds of elements we need to continue parsing (navigating into them, really) the pieces of JSON we got from simdjson.
We reused ClickHouse®'s numerical parser when possible, but we ended up writing a pretty complex field-creation recursive system to handle all the supported types and produce Field values that could be readily converted into RowBinary using the data types of ClickHouse®.
To handle the idiosyncrasies and weird conversion cases of the old code, we introduced a legacy-conversion-mode which is now used by default and activates the special handling of all the cases discovered. By disabling it in the future, we'll be able to offer a more sensible and consistent treatment of invalid cases that will help users validate their data. But we must yet determine how to best introduce this feature without impacting existing customers.
Error handling
Any robust system, like Tinybird's platform, must be designed to fail. Failures will happen and they must be handled safely. During the RowBinary conversion, all kinds of problems, anticipated (like invalid formats) or unanticipated (unexpected, should-not-happen situations) must be handled gracefully. The result of the conversion is always two chunks of RowBinary data: one for the successfully converted rows, and another for those quarantined.
We use exceptions to handle the situations that lead to switching from the successful path to the quarantine path.
In some cases, an error affects a single column, and we can collect the error information and continue extracting other columns (and possibly finding more errors). In others, that's not possible (think of non-JSON content in a row), and the whole input must be quarantined with a generic error message. And some require special handling: simdjson can encounter a problem that puts it in an unrecoverable error mode; the parser is no longer alive and we need to restart parsing at another point of the input to continue parsing the rest of the NDJSON block if possible.
Development and putting into production
To achieve a implementation acceptable for production, we needed to make sure that no changes in the way the data is quarantined (or not), nor the RowBinary values produced, would affect existing users.
We started by making sure all the test cases we had for the old implementation produce the same results with the new one.
But the accidental quirks mentioned above were not covered by tests, of course, so we needed to find as many of those cases as possible. We did this in three stages:
First we ingested some of our data twice, with the old and new conversion and compared results. Tinybird eats our own food as much as possible, so we have a lot of our own metrics and other ops data going through our platform that we could use. We found many problems this way.
Then we started controlled tests, where we enabled the feature in production while closely monitoring the regions and workspaces where the feature was activated. This was useful mostly in finding issues about the conversion operation, like the impact on the event loop lag on some applications, which needed some adjusting. And on one occasion we also found one of those accidental peculiarities of the old conversion that caused a stream of events to start being quarantined. We were prepared for this, so the ingestion was switched immediately to use the old conversion, and, that's the nice thing about our quarantine, we just needed to inform the customer and re-ingest their quarantined data to avoid any data loss.
This prompted us to be more methodical in finding more edge cases that had escaped us so far. We wrote (well, an AI agent wrote, with our guidance) a test data generator that produced random cases. This is not trivial, because we had to generate JSON paths, data types, and data rows in coordination to produce both compatible and incompatible cases. This revealed a lot of new problems that needed attention. Since then, we've been gradually activating the feature in production without finding new problems.
At the moment, we are enabling this feature generally only for our Events API. We'll soon activate it for other services like the data sources API and connectors.
Performance
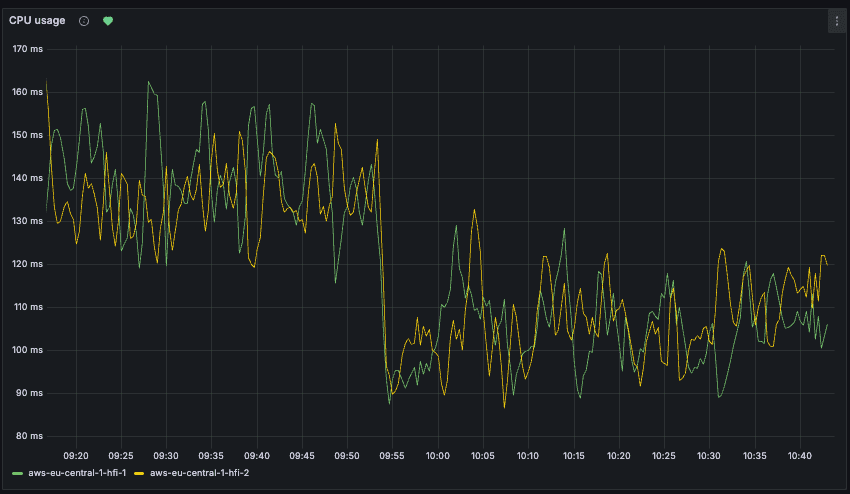
And the performance improvements? Here's a chart showing the decrease of CPU usage on two processes handling Events API requests in one of our smallest regions; while the potential gains are more modest compared to larger, high-activity regions, the improvement is still clearly evident, about a 30% decrease in CPU usage. The new conversion functions where enabled at 09:53.
Outcomes & Learnings
We got a bunch of positive results from this experience:
- Performance: We use the platform more efficiently, which means higher capacity for the same cost for our clients.
- Reliability: We became aware of the quirks of our ingestion that we hadn't yet noticed. Now they're documented, and we have tests to maintain code that needs to preserve them (as well as plans to overcome them).
- Alignment with ClickHouse®: We're now more in-sync with the database internals: we rely on it to take care of properly encoding into RowBinary.
- Simplified Maintenance: We have code that is easier to maintain: concerns are better separated than in the old code and modifications are not as likely to impact performance.
- Knowledge: We learned a lot of C++ and ClickHouse® internals! This c++ pipeline work deepened our understanding of the clickhouse rowbinary format documentation, which helps when evaluating tinybird vs realtime pipeline options.
Although, of course, this wasn't a bed of roses:
- It took us months to complete an initiative that we had greatly under-estimated.
- Some potential performance gains are still unfulfilled: either we need to implement a non-legacy ingestion mode, or more work is still needed in some areas to improve memory handling, etc.
Eventually, we'll write the follow up post once we've figured out that last one.