


Choosing between ClickHouse® and Citus for real-time analytics often comes down to a single question: do you need the absolute fastest query performance on large datasets, or do you need PostgreSQL's transactional guarantees at scale? Both databases can power real-time analytics applications, but their architectural differences create distinct tradeoffs in performance, consistency, and operational complexity.
This comparison examines how ClickHouse® and Citus handle analytical workloads, from query latency and data ingestion to operational overhead and cost at scale.
How the two engines approach real-time analytics
ClickHouse® is an open-source columnar OLAP database designed for analytical queries on large datasets, while Citus is a PostgreSQL extension that distributes data across multiple nodes. ClickHouse® stores data in columns rather than rows, which means queries only read the specific columns they need instead of entire rows. Citus takes PostgreSQL and spreads it across multiple machines while keeping the familiar PostgreSQL interface.
The architectural difference matters for real-time analytics. When you run a query that aggregates millions of rows, ClickHouse® reads just the columns involved in that aggregation. Citus distributes the same query across worker nodes, but each node still reads full rows because it's built on PostgreSQL's row-based storage. This fundamental design choice affects everything from query speed to how you model your data.
For read-heavy analytics workloads where you're constantly aggregating large amounts of data, ClickHouse®'s columnar approach typically executes queries faster. For workloads that mix transactional writes with analytical reads, Citus offers PostgreSQL's ACID guarantees across a distributed cluster.
Performance benchmark results on typical analytics queries
Benchmarks on real-world analytics workloads show ClickHouse® executing aggregation queries 5x to 10x faster than Citus on the same hardware. The performance gap comes from two factors: columnar storage reads less data from disk, and ClickHouse®'s compression reduces the amount of data that moves through the system.
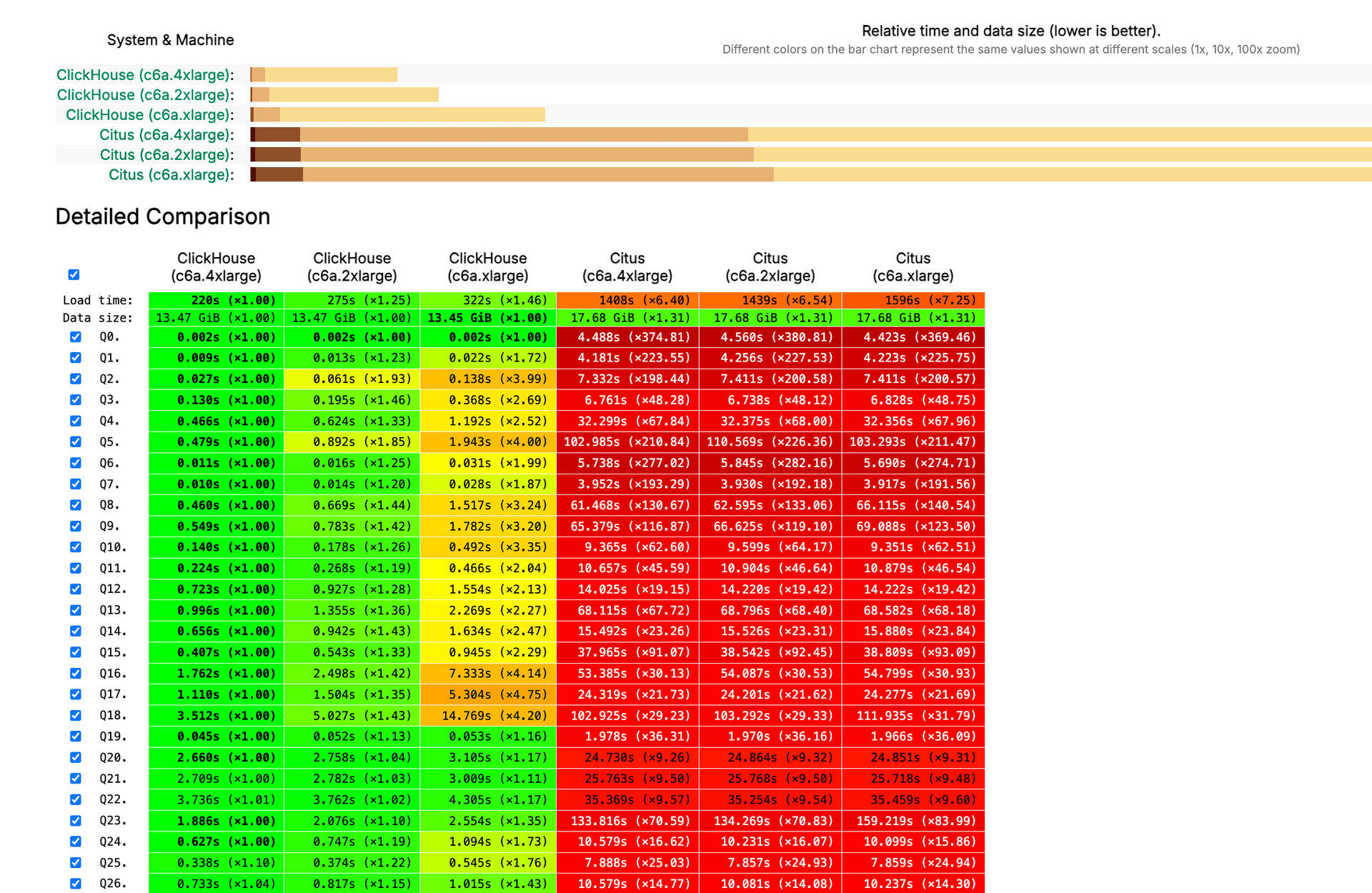
A query that sums revenue across millions of transactions might scan 100GB of data in Citus but only 10GB in ClickHouse® because it reads a single column instead of entire rows. Compression amplifies this advantage, with ClickHouse® often achieving 10:1 compression ratios on typical analytics data, with production deployments like Character.AI reporting 15-20× compression on average.
Aggregation latency
Time-based rollups and GROUP BY operations represent the most common query patterns in analytics applications. ClickHouse® handles aggregations with sub-second latency even on billions of rows because it only touches the columns involved in the calculation. A query computing daily active users by summing a user\_id column across time buckets reads just that column and the timestamp column.
High concurrency stress test
Real-time analytics APIs often serve dozens or hundreds of concurrent users running queries simultaneously. ClickHouse® maintains low latency under high concurrency because each query reads less data from disk. When 50 users each run an aggregation query, ClickHouse®'s columnar format means those queries don't compete as heavily for I/O bandwidth.
Citus distributes concurrent queries across worker nodes, which spreads the load, though the row-based storage creates more disk I/O per query. In practice, ClickHouse® maintains more consistent latency under load for aggregation-heavy workloads.
Compression ratio impact
How much data compression affects both storage costs and query speed. ClickHouse®'s columnar format compresses exceptionally well because similar data types sit together in storage. A column of timestamps compresses better than rows where each timestamp is interleaved with strings, integers, and other types.
- Storage savings: A 1TB PostgreSQL table might compress to 100GB in ClickHouse®, reducing storage costs by 90%
- Query performance: Less data on disk means queries read less from storage, which directly reduces latency
- Network transfer: In distributed setups, compressed data moves faster between nodes
Citus uses PostgreSQL's row-level compression, which typically achieves lower compression ratios. For analytics queries scanning millions of rows, the difference in compression translates directly to how much data moves through the system.
Ingest and update patterns at scale
How a database handles incoming data matters as much as how it runs queries. ClickHouse® optimizes for high-throughput batch inserts, while Citus maintains PostgreSQL's transactional insert model across distributed nodes. The tradeoff is between insert speed and immediate consistency.
ClickHouse® achieves high insert rates by batching data and writing large blocks to disk. If you're ingesting events from Kafka or another streaming source, you buffer thousands of events and insert them together. This approach works well when you can tolerate a few seconds of delay between when data arrives and when it's queryable.
Citus handles inserts more like PostgreSQL, with ACID guarantees and immediate consistency. Each insert is immediately visible to queries, which matters for applications that need to read their own writes instantly.
Streaming inserts per second
ClickHouse® can ingest millions of rows per second on a single node when data arrives in batches of 10,000+ rows. The columnar storage format allows the database to write large compressed blocks efficiently. Real-time analytics applications typically use message queues to buffer events, then insert them in batches every few seconds.
Bulk loads and backfills
Citus parallelizes bulk loads across worker nodes using PostgreSQL's COPY command. The process is straightforward for PostgreSQL users, though total throughput is typically lower than ClickHouse® for the same hardware.
Materialized view maintenance
Pre-computed aggregations reduce query latency by storing commonly accessed results ahead of time. ClickHouse® materialized views update automatically as new data arrives. When you insert a batch of events, ClickHouse® immediately updates any materialized views built on that table, with incremental materialized views delivering hundreds to thousands times faster query performance compared to raw data scans. This means your pre-aggregated metrics stay current without manual refresh logic.
Citus supports materialized views, but they refresh manually or on a schedule rather than updating automatically. There's a delay between when data is inserted and when it appears in the materialized view, which works for batch-oriented analytics but less well for real-time dashboards.
Data modeling and SQL feature parity
Both databases support standard SQL, though they differ in what features they prioritize. Citus maintains nearly complete PostgreSQL compatibility, which means most PostgreSQL queries work without changes. ClickHouse® implements a large subset of standard SQL but optimizes for analytical query patterns rather than full ANSI SQL compliance.
The practical difference shows up in how you model data. Citus allows normalized schemas with many tables joined together, just like PostgreSQL. ClickHouse® works better with denormalized tables where related data sits together, reducing the need for joins at query time.
Joins and secondary indexes
ClickHouse® supports INNER, LEFT, RIGHT, and FULL joins, though it's optimized for queries where one table is much larger than the other. The typical pattern is joining a large fact table with smaller dimension tables. ClickHouse® broadcasts the smaller table to all nodes, which works well when dimension tables fit in memory.
Citus distributes joins across worker nodes by co-locating related data on the same node when possible. If two tables share the same distribution column, Citus performs local joins without shuffling data between nodes. Secondary indexes in Citus work like PostgreSQL indexes and speed up queries filtering on specific values. ClickHouse® uses sparse primary key indexes optimized for range scans rather than point lookups.
Transactions and consistency
Citus provides full ACID transaction support across distributed tables, inherited from PostgreSQL. You can update multiple rows atomically and see consistent data across all nodes. For applications requiring transactional consistency, like financial systems or inventory management, Citus provides the guarantees you need.
ClickHouse® uses an eventually consistent replication model where newly inserted data might not be immediately visible across all replicas. Writes are asynchronous by default, which improves insert throughput but means a query might not see data that was just written. For analytics applications where queries typically look at data that's at least a few seconds old, this tradeoff works well.
Time series functions
Both databases offer functions for working with time series data, though ClickHouse® provides more specialized functions for analytics. Functions like toStartOfInterval(), toStartOfHour(), and toStartOfDay() make it easy to bucket timestamps for time-based aggregations. ClickHouse® also includes functions for time zone handling and date arithmetic.
Citus inherits PostgreSQL's date and time functions, which are comprehensive but less specialized for analytics. The date\_trunc() function provides similar functionality to ClickHouse®'s interval functions. For most time series operations, both databases provide what you need, though ClickHouse®'s specialized functions can make certain queries more concise.
Operational complexity and scaling effort
Managing a distributed database in production involves monitoring, scaling, and maintaining uptime as data grows. ClickHouse® and Citus require different operational skills, with tradeoffs between flexibility and complexity.
ClickHouse® clusters can be deployed in several topologies, from a single node for small datasets to distributed clusters with replication. Setting up production ClickHouse® involves configuring ZooKeeper or ClickHouse® Keeper for coordination, choosing replication factors, and tuning settings for your workload. The learning curve is steep for teams without distributed systems experience.
Citus builds on PostgreSQL's operational model, which is familiar to many teams. Adding Citus to existing PostgreSQL involves installing the extension and configuring worker nodes. The operational model resembles managing multiple PostgreSQL instances, with the added complexity of choosing distribution columns and managing data distribution.
Cluster deployment topologies
A typical ClickHouse® cluster consists of multiple shards for distributing data and multiple replicas for high availability. Each shard stores a subset of the data, and each shard has one or more replicas to handle failures. This shared-nothing architecture scales horizontally by adding more shards, though rebalancing data across new shards requires planning.
Citus uses a coordinator-worker model where a single coordinator node routes queries to worker nodes storing the actual data. Workers can be added to scale storage and query capacity, and the coordinator handles query planning and result aggregation.
Observability and alerting
Monitoring ClickHouse® involves tracking query performance, disk usage, replication lag, and merge activity. ClickHouse® exposes detailed metrics through system tables, and tools like Prometheus and Grafana can collect and visualize these metrics. However, setting up comprehensive monitoring requires understanding which metrics matter for your workload.
Citus monitoring builds on PostgreSQL's existing tools, including pg\_stat\_statements for query analysis and standard PostgreSQL metrics for disk and memory usage. The familiarity of these tools makes it easier for PostgreSQL DBAs to monitor Citus, though distributed queries add complexity because you track performance across multiple worker nodes.
Ecosystem, tooling, and managed service options
The tools and integrations available for a database affect how quickly you can build and deploy applications. ClickHouse® and Citus have different ecosystems reflecting their design goals.
ClickHouse® has a growing ecosystem of native tools, including connectors for Kafka, S3, and various data formats. The ClickHouse® client provides a SQL interface, and there are drivers for most popular programming languages. However, many tools in the broader data ecosystem are built for PostgreSQL and don't work natively with ClickHouse®.
Citus benefits from PostgreSQL's mature ecosystem, which includes thousands of extensions, tools, and integrations. Any tool that works with PostgreSQL can work with Citus, though distributed queries might require adjustments.
PostgreSQL compatibility benefits
Using Citus means you can continue using PostgreSQL tools like pgAdmin, DBeaver, and other database management tools without modification. ORMs like SQLAlchemy, ActiveRecord, and Django ORM work with Citus because it's PostgreSQL with distributed table support.
The PostgreSQL ecosystem also includes extensions for full-text search, geospatial data, and time series data that work with Citus. If you're already using PostgreSQL extensions in your application, migrating to Citus allows you to keep using them while gaining horizontal scaling.
ClickHouse® native ecosystem
ClickHouse®'s ecosystem focuses on high-performance analytics and data ingestion. Native integrations with Kafka allow you to stream data directly into ClickHouse® tables, and the S3 table engine lets you query data stored in object storage without loading it into ClickHouse® first.
Database clients and visualization tools like Grafana, Metabase, and Superset support ClickHouse®, though the setup process might be less polished than with PostgreSQL. For teams building custom analytics applications, ClickHouse®'s HTTP interface and native protocol provide flexible options for querying data programmatically.
Tinybird managed ClickHouse®
Tinybird provides a managed ClickHouse® platform designed for developers who want to integrate ClickHouse® into their applications without managing infrastructure. The platform handles cluster setup, scaling, and maintenance while providing a developer-friendly API layer on top of ClickHouse®.
With Tinybird, you define data sources and SQL queries as code, test them locally, and deploy them as versioned API endpoints. This approach eliminates the operational complexity of running ClickHouse® while providing the performance benefits of columnar storage. The platform includes streaming ingestion, automatic scaling, and built-in observability.
Compared to self-hosting ClickHouse® or using ClickHouse® Cloud, Tinybird focuses specifically on the developer experience for building real-time analytics APIs. The CLI-driven workflow integrates with existing development tools and CI/CD pipelines, and the API-first approach means you can query ClickHouse® from any language or framework without managing database connections.
Cost considerations and pricing models
Infrastructure costs vary significantly between ClickHouse® and Citus depending on your data volume, query patterns, and operational requirements. Understanding these costs helps you make informed decisions about which database fits your budget.
ClickHouse®'s columnar storage and compression mean you can store more data on less disk space compared to row-based systems. A dataset occupying 1TB in PostgreSQL might compress to 100GB in ClickHouse®, reducing storage costs by 90%. However, ClickHouse® benefits from more RAM for optimal query performance, particularly for queries that sort or join large datasets.
Citus costs are more predictable for teams familiar with PostgreSQL, as you can estimate costs based on the number of worker nodes needed to store your data. The coordinator node adds some overhead, but the overall cost model resembles running multiple PostgreSQL instances.
Infrastructure cost at small scale
For datasets under 100GB, both ClickHouse® and Citus can run on modest hardware. A single ClickHouse® node with 16GB of RAM and a few CPU cores can handle millions of rows with sub-second query latency. Citus requires at least two nodes (a coordinator and one worker) for distributed tables, which increases the minimum infrastructure cost.
At this scale, the cost difference might be less important than other factors like team familiarity and ecosystem compatibility. If your team already knows PostgreSQL and you don't need the absolute fastest query performance, Citus provides a path to scale without learning a new database.
Infrastructure cost at large scale
As datasets grow to multiple terabytes, the cost differences become more pronounced. ClickHouse®'s compression and columnar storage mean you need less disk space and can serve queries with fewer nodes. A ClickHouse® cluster handling 10TB of compressed data might require 3-4 nodes with fast SSDs, while a Citus cluster storing the same logical data might need 8-10 worker nodes due to lower compression ratios.
Query performance at scale also affects costs. If ClickHouse® can execute a query in 100ms while Citus takes 1 second, you need fewer ClickHouse® nodes to handle the same query throughput. This performance advantage compounds as query volume increases, making ClickHouse® more cost-effective for read-heavy analytics workloads.
Engineering hours saved
The total cost of ownership includes not just infrastructure but also the engineering time required to build, deploy, and maintain your analytics system. Setting up production ClickHouse® requires expertise in distributed systems, query optimization, and operational monitoring. Teams without this expertise might spend weeks or months learning ClickHouse® before deploying to production.
Citus reduces the learning curve for PostgreSQL teams because the operational model is familiar. However, you still need to understand distributed query planning, choose appropriate distribution columns, and monitor performance across multiple nodes. For teams that want to focus on building features rather than managing infrastructure, a managed service can significantly reduce engineering overhead.
Choosing the right database for your workload
The decision between ClickHouse® and Citus depends on your specific requirements for query performance, consistency guarantees, and operational complexity. Neither database is universally better; each excels in different scenarios.
Choose ClickHouse® when your primary goal is running extremely fast analytical queries on large datasets and your workload is read-heavy. The columnar storage format and specialized aggregation functions make ClickHouse® the best choice for real-time dashboards, user-facing analytics, and applications that need to query billions of rows with sub-second latency. You can tolerate eventual consistency and don't need frequent updates or complex transactional logic.
Choose Citus when you need to scale PostgreSQL horizontally while retaining all of its functionality. You have a mix of transactional and analytical workloads, or you need strong consistency guarantees that PostgreSQL provides. Your team already knows PostgreSQL and wants to leverage that expertise rather than learning a new database system.
For teams evaluating both options, consider starting with a proof of concept that tests your actual query patterns and data volumes. Load a representative sample of your data into both systems and run your most common queries to see which performs better.
Try Tinybird for managed ClickHouse®
If you want the performance benefits of ClickHouse® without the operational complexity, sign up for a free Tinybird account. You can start building real-time analytics APIs in minutes without worrying about cluster management, scaling, or infrastructure maintenance.
Faqs about ClickHouse® vs Citus
Can I run both ClickHouse® and Citus in the same application stack?
Yes, many teams use ClickHouse® for analytics workloads while keeping Citus or PostgreSQL for transactional data. This hybrid approach lets you optimize each database for its strengths, with ClickHouse® serving read-heavy analytics queries and PostgreSQL handling writes and transactional consistency. You can replicate data from PostgreSQL to ClickHouse® using change data capture tools or batch ETL processes.
How difficult is migrating from PostgreSQL to ClickHouse®?
Migration complexity depends on your SQL usage, but ClickHouse® supports most standard SQL with some syntax differences for advanced features. Simple SELECT queries with GROUP BY and WHERE clauses typically work with minimal changes. The main differences appear in how you model data, with ClickHouse® favoring denormalized tables and pre-joined data rather than normalized schemas with many joins. Most teams can migrate a proof of concept in a few days, though production migrations require more planning for data loading and query optimization.
Does ClickHouse® support the same join types as Citus?
ClickHouse® supports INNER, LEFT, RIGHT, and FULL joins, though it's optimized for analytical queries rather than complex transactional joins. The typical pattern is joining a large fact table with smaller dimension tables, which ClickHouse® handles efficiently. Citus supports the same join types with better performance on queries that join multiple large tables, particularly when the tables are co-located on the same worker nodes.
What are the main downsides of each database engine?
ClickHouse® requires learning new optimization patterns and works best with batch inserts rather than single-row writes. The eventual consistency model means newly inserted data might not be immediately visible across all replicas. Citus can struggle with very high-throughput analytical workloads compared to purpose-built OLAP systems, and choosing the right distribution column requires careful planning. Both systems add operational complexity compared to a single-node database, though managed services like Tinybird can eliminate much of this burden for ClickHouse® deployments.
/