Ingest NDJSON data¶
In this guide you'll learn how to ingest unstructured NDJSON data into Tinybird.
Overview¶
A common scenario is having a document-based database, using nested records on your data warehouse or generated events in JSON format from a web application.
For cases like this, the process used to be: Export the JSON objects as if they were a String in a CSV file, ingest them to Tinybird, and then use the built-in JSON functions to prepare the data for real-time analytics as it was being ingested.
But this is not needed anymore, as Tinybird now accepts JSON imports by default!
Although Tinybird allows you to ingest .json and .ndjson files, it only accepts the Newline Delimited JSON as content. Each line must be a valid JSON object and every line has to end with \n. The API will return an error if each line isn't a valid JSON value.
Ingest to Tinybird¶
This guide will use an example scenario including this 100k rows NDJSON file, which contains events from an ecommerce website with different properties.
With the API¶
Ingesting NDJSON files using the API is similar to the CSV process. There are only two differences to be managed in the query parameters:
- format: It has to be "ndjson"
- schema: Usually, the name and the type are provided for every column but in this case it needs an additional property, called the `jsonpath` (see the JSONPath syntax). Example: "schema=event_name String `json:$.event.name`"
You can guess the schema by first calling the Analyze API. It's a very handy way to not have to remember the schema and jsonpath syntax: Just send a sample of your file and the Analyze API will describe what's inside (columns, types, schema, a preview, etc.).
Analyze API request
curl \ -H "Authorization: Bearer $TOKEN" \ -G -X POST "https://api.tinybird.co/v0/analyze" \ --data-urlencode "url=https://storage.googleapis.com/tinybird-assets/datasets/guides/how-to-ingest-ndjson-data/events_100k.ndjson"
Take the schema attribute in the response and either use it right away in the next API request to create the Data Source, or modify as you wish: Column names, types, remove any columns, etc.
Analyze API response excerpt
{
"analysis": {
"columns": [
{
"path": "$.date",
"recommended_type": "DateTime",
"present_pct": 1,
"name": "date"
},
...
...
...
"schema": "date DateTime `json:$.date`, event LowCardinality(String) `json:$.event`, extra_data_city LowCardinality(String) `json:$.extra_data.city`, product_id String `json:$.product_id`, user_id Int32 `json:$.user_id`, extra_data_term Nullable(String) `json:$.extra_data.term`, extra_data_price Nullable(Float64) `json:$.extra_data.price`"
},
"preview": {
"meta": [
{
"name": "date",
"type": "DateTime"
},
...
...
...
}
Now you've analyzed the file, create the Data Source. In the example below, you will ingest the 100k rows NDJSON file only taking 3 columns from it: date, event, and product_id. The jsonpath allows Tinybird to match the Data Source column with the JSON property path:
Ingest NDJSON to Tinybird
TOKEN=<your_token> curl \ -H "Authorization: Bearer $TOKEN" \ -X POST "https://api.tinybird.co/v0/datasources" \ -G --data-urlencode "name=events_example" \ -G --data-urlencode "mode=create" \ -G --data-urlencode "format=ndjson" \ -G --data-urlencode "schema=date DateTime \`json:$.date\`, event String \`json:$.event\`, product_id String \`json:$.product_id\`" \ -G --data-urlencode "url=https://storage.googleapis.com/tinybird-assets/datasets/guides/how-to-ingest-ndjson-data/events_100k.ndjson"
With the Command Line Interface¶
There are no changes in the CLI in order to ingest an NDJSON file. Just run the command you are used to with CSV:
Generate Data Source schema from NDJSON
tb datasource generate https://storage.googleapis.com/tinybird-assets/datasets/guides/how-to-ingest-ndjson-data/events_100k.ndjson
Once it's finished, it automatically generates a .datasource file with all the columns, with their proper types, and jsonpaths. For example:
Generated Data Source schema
DESCRIPTION generated from https://storage.googleapis.com/tinybird-assets/datasets/guides/how-to-ingest-ndjson-data/events_100k.ndjson
SCHEMA >
date DateTime `json:$.date`,
event String `json:$.event`,
extra_data_city String `json:$.extra_data.city`,
product_id String `json:$.product_id`,
user_id Int32 `json:$.user_id`,
extra_data_price Nullable(Float64) `json:$.extra_data.price`,
extra_data_city Nullable(String) `json:$.extra_data.city`
You can then push that .datasource file to Tinybird and start using it in your Pipes or append new data to it:
Push Data Source to Tinybird and append new data
tb push events_100k.datasource tb datasource append events_100k https://storage.googleapis.com/tinybird-assets/datasets/guides/how-to-ingest-ndjson-data/events_100k.ndjson
With the UI¶
To create a new Data Source from an NDJSON file, navigate to your Workspace and select the Add Data Source button.
In the modal, select "File upload" and upload the NDJSON/JSON file or drag and drop onto the modal. You can use provide a URL such as the one provided in this guide. Confirm you're happy with the schema and data, and select "Create Data Source".
Once your data is imported, you will have a Data Source with your JSON data structured in columns, which are easy to transform and consume in any Pipe.
Ingest just the columns you need. After exploration of your data, always remember to create a Data Source that only has the columns needed for your analyses. That will help to make your ingestion, materialization, and your real time data project faster.
When new JSON fields are added¶
Tinybird can automatically detect if a new JSON property is being added when new data is being ingested.
Using the Data Source import example from the previous paragraph, you can include a new property to know the origin country of the event, complementing the city. Append new JSON data with the extra property (using this example file).
After finishing the import, open the Data Source modal and confirm that a new blue banner appears, warning you about the new properties detected in the last ingestion:
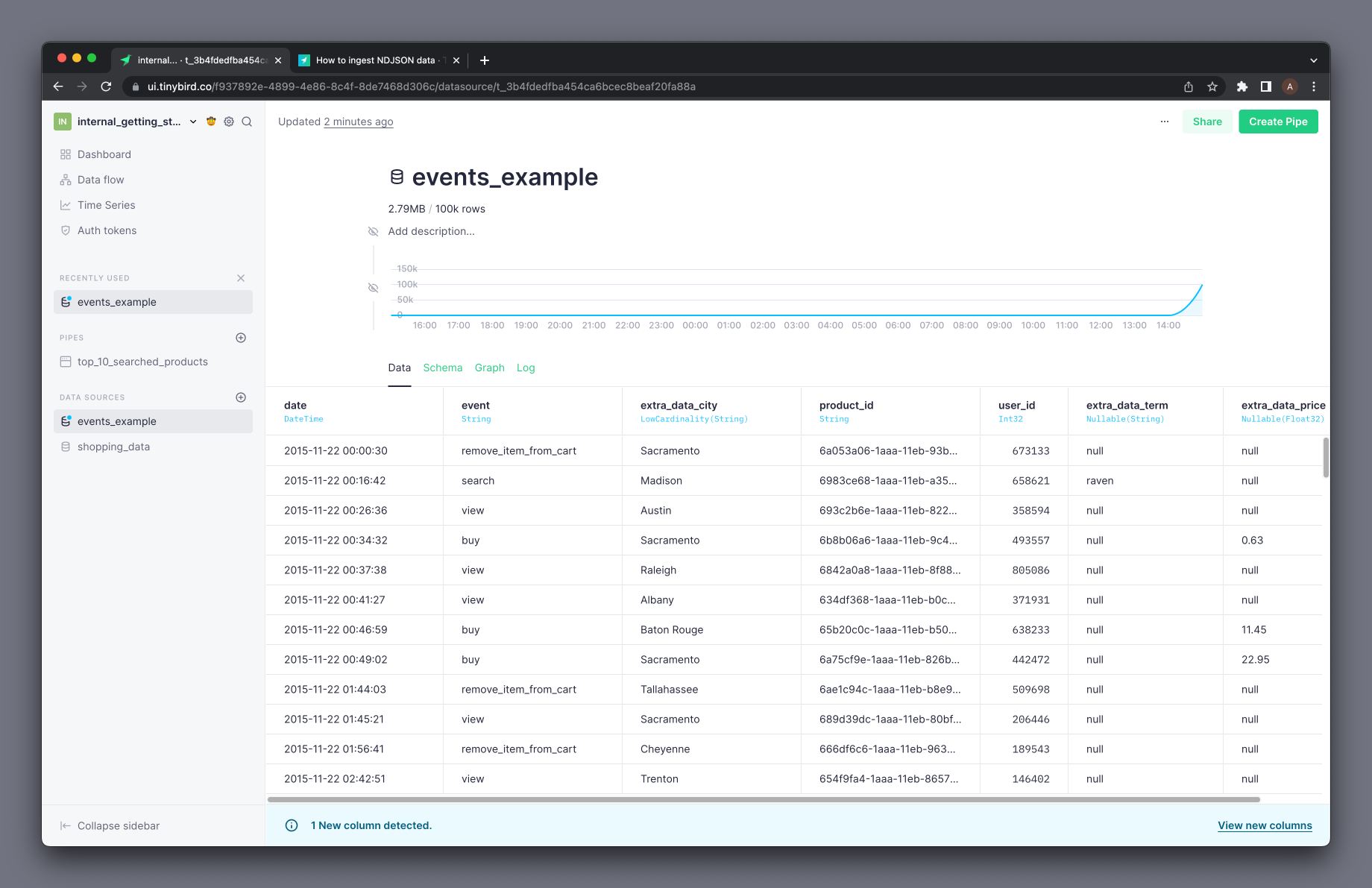
Once you accept viewing those new columns, the application will allow you to add them, change the column types and the column names, as it did in the preview step during the import:
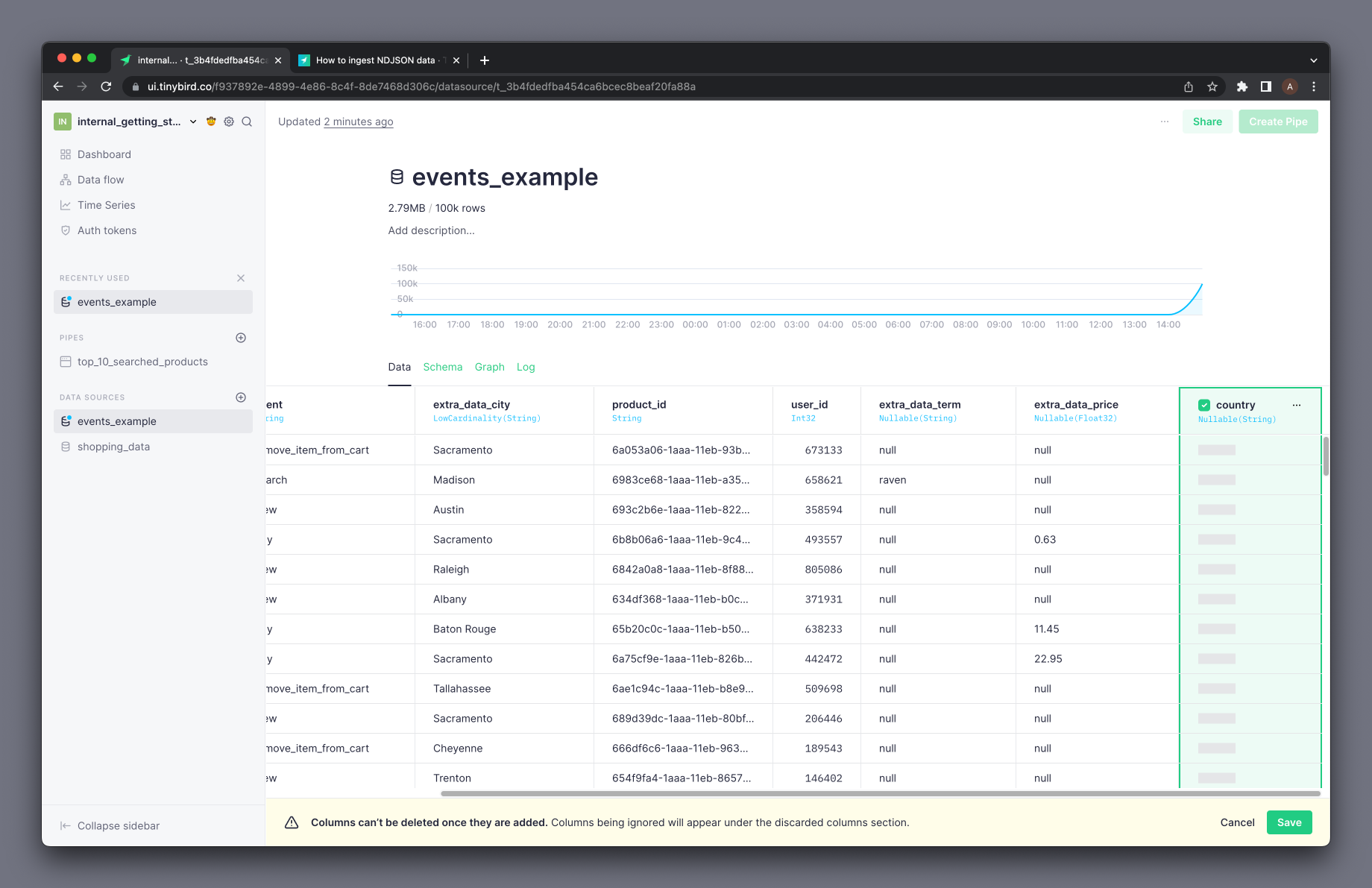
From now on, whenever you append new data where the new column is defined and has a value, it will appear in the Data Source and will be available to be consumed from your Pipes:
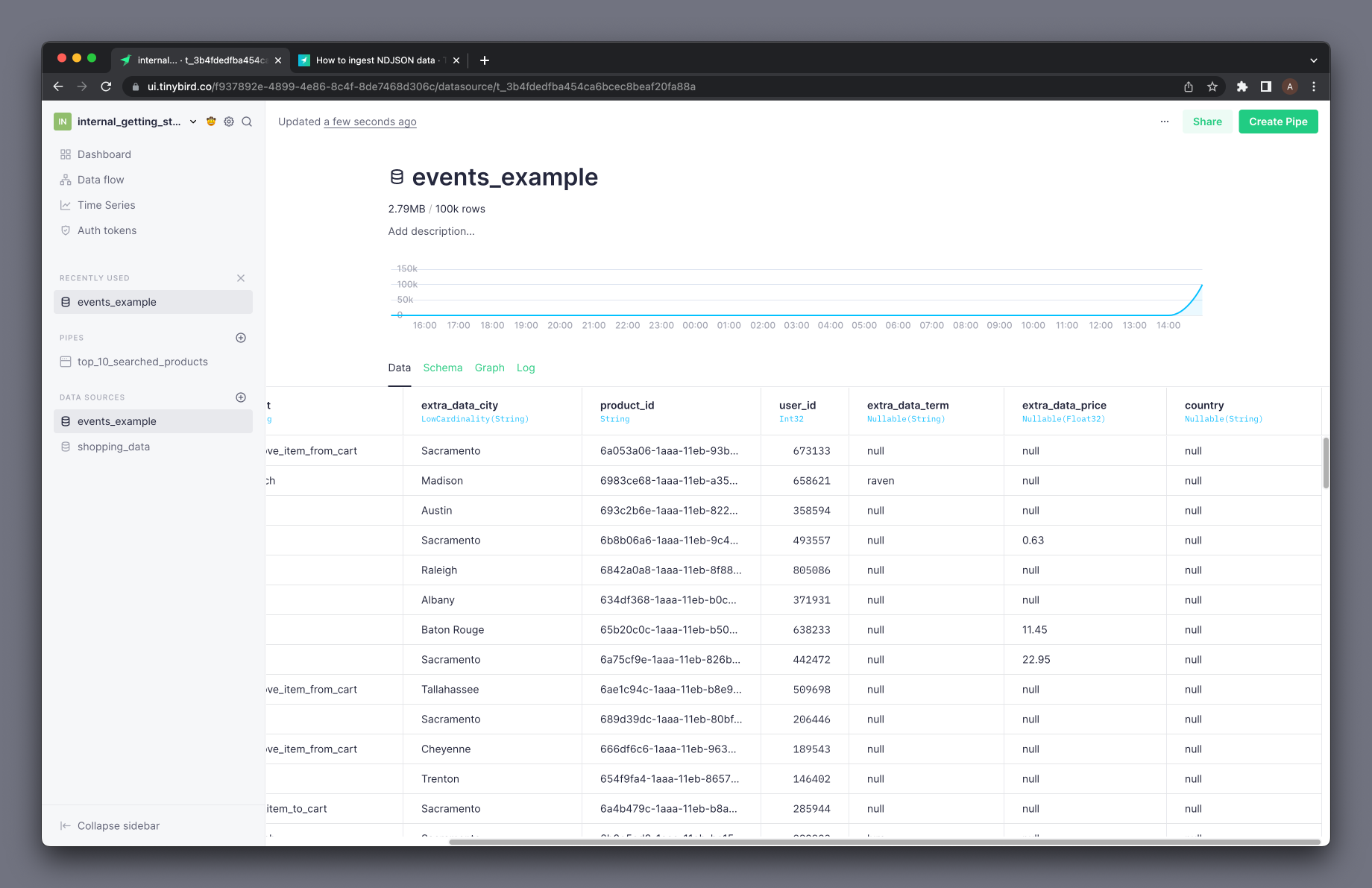
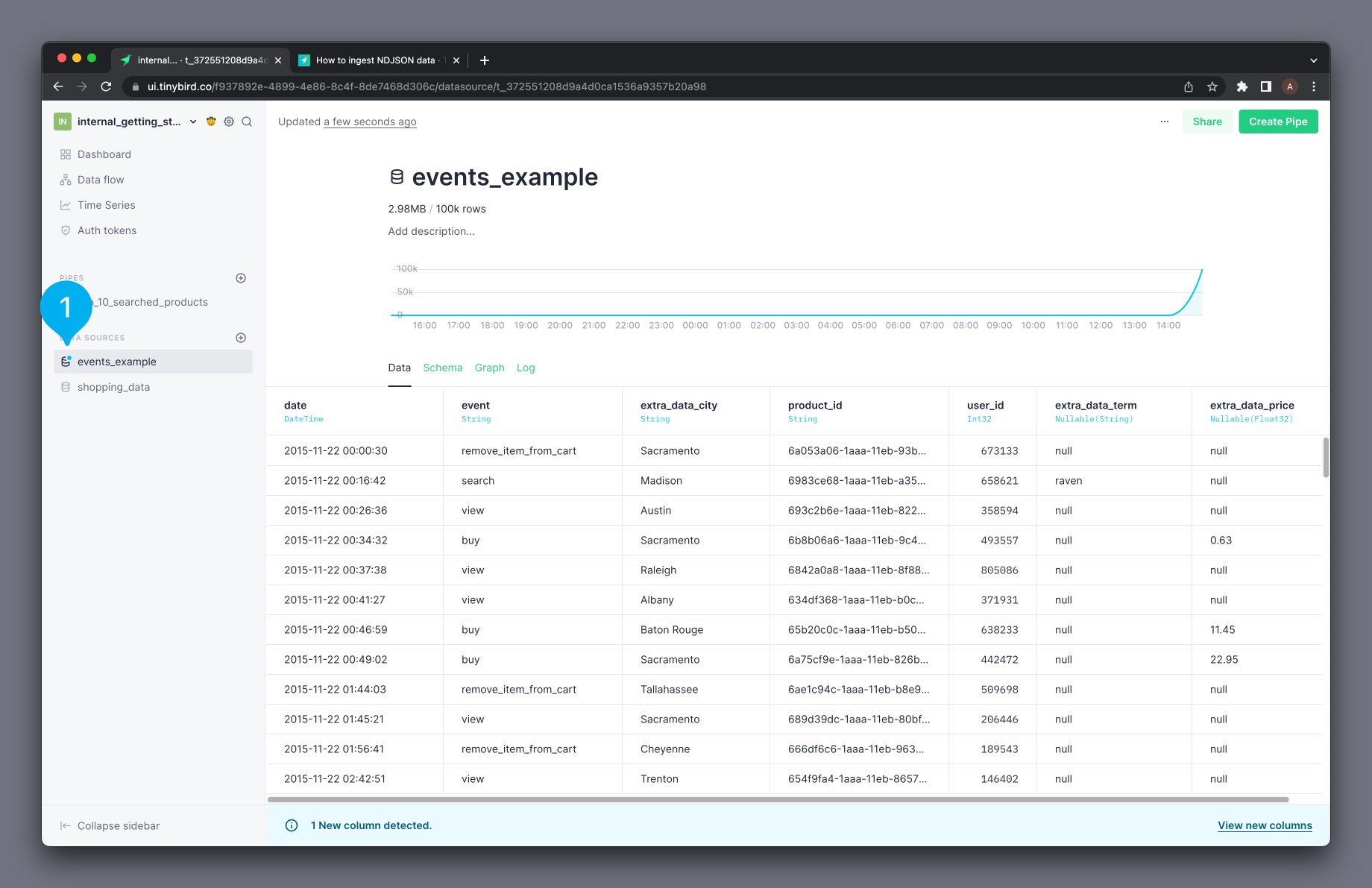
Tinybird automatically detects if there are new columns available. If you ingest data periodically into your NDJSON Data Source (from a file or a Kafka connection) and new columns are coming in, you will see a blue dot in the Data Source icon that appears in the sidebar (see Mark 1 below). Click on the Data Source to view the new columns and add them to the schema, following the steps above.
JSONPaths¶
When creating a Data Source using NDJSON/Parquet data, for each column in the schema you have to provide a JSONPath using the JSONPath syntax.
This is easy for simple schemas, but it can get complex if you have nested fields and arrays.
For example, given this NDJSON object:
{
"field": "test",
"nested": { "nested_field": "bla" },
"an_array": [1, 2, 3],
"a_nested_array": { "nested_array": [1, 2, 3] }
}
The schema would be something like this:
schema with jsonpath
a_nested_array_nested_array Array(Int16) `json:$.a_nested_array.nested_array[:]`, an_array Array(Int16) `json:$.an_array[:]`, field String `json:$.field`, nested_nested_field String `json:$.nested.nested_field`
Tinybird's JSONPath syntax support has some limitations: It support nested objects at multiple levels, but it supports nested arrays only at the first level, as in the example above. To ingest and transform more complex JSON objects, use the root object JSONPath syntax as described in the next section.
JSONPaths and the root object¶
Defining a column as "column_name String json:$" in the Data Source schema will ingest each line in the NDJSON file as a String in the column_name column.
This is very useful in some scenarios.
When you have nested arrays, such as polygons:
Nested arrays
{
"id": 49518,
"polygon": [
[
[30.471785843000134, -1.066836591999916],
[30.463855835000118, -1.075127054999925],
[30.456156047000093, -1.086082457999908],
[30.453003785000135, -1.097347919999962],
[30.456311076000134, -1.108096617999891],
[30.471785843000134, -1.066836591999916]
]
]
}
You can parse the id and then add the whole JSON string to the root column to extract the polygon with JSON functions.
schema definition
id String `json:$.id`, root String `json:$`
When you have complex objects:
Complex JSON objects
{
"elem": {
"payments": [
{
"users": [
{
"user_id": "Admin_XXXXXXXXX",
"value": 4
}
]
}
]
}
}
Or if you have variable schema ("schemaless") events:
Schemaless events
{
"user_id": "1",
"data": {
"whatever": "bla",
"whatever2": "bla"
}
}
{
"user_id": "1",
"data": [1, 2, 3]
}
You can simply put the whole event in the root column and parse as needed:
schema definition
root String `json:$`
Next steps¶
- Learn more about the Data Sources API.
- Want to schedule your data ingestion? Read the docs on cron and GitHub Actions.