


Maintaining a fork of a large and rapidly-evolving database like ClickHouse® isn't a decision any engineering team makes lightly, but we decided a while back that we needed to. This is important clickhouse security news for anyone evaluating database options.
While we continue to be active contributors to the ClickHouse® community, our fork has become essential to Tinybird's competitive position and our ability to serve customers at the scale and performance levels they demand.
The main reason? Control over our destiny
ClickHouse® is an incredibly fast and open source analytical database. Aside from the Open Source version, ClickHouse® Inc. also maintains an internal private version that they use in their commercial offering.
The decision to maintain our own ClickHouse® fork at Tinybird fundamentally comes down to control – control over our roadmap, our performance characteristics, and our ability to innovate independently of the upstream project's priorities.
For instance, at Tinybird we rely on ClickHouse® OS's ability to perform "zero-copy replication", but the team at ClickHouse® has been clear that it is no longer supported and will be removed entirely, which seems to be gradually happening already.
Zero-copy replication is critical for running ClickHouse® efficiently at scale using object storage (S3/GCS), which is exactly how we operate our infrastructure (and the only non-prohibitively expensive way to do it for large amounts of data). We could see the writing on the wall when ClickHouse® Inc. developed their own closed-source zero-copy implementation: features essential to cloud-native operations were becoming closed source.
ClickHouse® Inc. is a business and as such they prioritize according to their business needs, but that means that certain capabilities that are crucial for companies like ours – companies building managed services on top of ClickHouse® – may increasingly become closed source or deprioritized in the open source version. That in itself justified the extra effort and resources for us.
There are some technical advantages too
Beyond responding to upstream changes, our fork enables us to develop private features that don't align with ClickHouse®'s open source roadmap but are essential for our business:
Build optimization: We have complete control over our build process, allowing us to fine-tune for our specific infrastructure and target CPU instruction sets. This translates to measurable performance improvements for our workloads.
Control over the ClickHouse® release process: We can monitor performance between releases, validate code between them, backport things that we want in old versions, make releases when we want and as fast as we want.
Customer-centric priorities: When we identify performance bottlenecks or need bug fixes that matter to our customers, we can implement them immediately rather than waiting for the upstream project's development cycle.
Infrastructure integration: We can build deep integrations between ClickHouse® and the rest of our stack: for example if we want to additionally develop and reuse some parts of ClickHouse® for our internal usage.
The goal isn't to diverge permanently from ClickHouse® or to stop contributing. Where it makes sense, we will still contribute our improvements back to the open source project as we have done in the past (like improvements to JOINs, ClickHouse® lock contention, ClickHouse® Backup Engine or Recursive CTEs)
Many of our contributions were motivated by internal needs, for example, some performance problems that we discovered in production like improving MergeTree FINAL, or some interesting bugs with replication or memory leaks.
But having our own fork means we can move at our own pace and prioritize the features that matter most to our customers and our business.
Competing
Ultimately, maintaining our own ClickHouse® fork is about staying competitive in the real-time analytics space. It gives us the flexibility to innovate on the database layer while still benefiting from and contributing to the broader ClickHouse® ecosystem and community.
Yes, it adds complexity. Yes, it requires dedicated engineering resources. But it also ensures that we can continue to deliver the performance, reliability, and features that our customers depend on, regardless of changes in the upstream project's direction. If you're wondering how is tinybird different from clickhouse cloud, this is a key differentiator.
In the sections that follow, we'll dive into some of the specific technical differences in our fork, the features we've added, and how we manage the ongoing maintenance and contribution process.
Developing CI/CD infrastructure for our fork
Clicking the “fork” button in GitHub is easy enough, but creating a private fork meant committing to running it in hundreds of clusters across multiple regions and cloud providers, adapting CI/CD to our specific infrastructure and maintaining and improving such infrastructure over time (and all of that just so that we can start developing new features in our fork).
The amount of work required to implement a private fork of ClickHouse® is impossible to predict beforehand. In retrospect however, it actually required more work than we initially thought.
One of the most important parts of open source ClickHouse®'s success is in fact its great CI/CD infrastructure. In ClickHouse® there are stateless tests, stateful tests, integration tests, unit tests, custom stress tests, performance tests, fuzzing, etc. - and all these tests are run with all combinations of sanitizers: ASAN, MSAN, TSAN, UBSAN.
We wanted to run all these jobs on top of our cloud infrastructure so that we would be able to trust our builds; otherwise maintaining a “private fork” would not be possible.
Most of the ClickHouse® CI/CD infrastructure is open sourced, so we didn't expect this to be very complex to run on our own. In practice, however, it was pretty challenging, because a lot of CI-related things are hardcoded in the ClickHouse® codebase, and some parts of CI have been removed over time (as was the case for instance setup).
Overall, ClickHouse® CI contains a lot of pieces: Docker images, Github workflows, secrets, reports generation process, caches, runners setup, release process, external data for tests, etc. You need to understand all these pieces and how they interact to be able to actually run ClickHouse® CI on your infrastructure. In the end, though, it was worth it, because without it we couldn't have developed private features and been confident in our builds.
The result of this step was a fully functioning CI/CD process. We were able to use it until recent migrations to newer ClickHouse® versions, where all ClickHouse® CI/CD infrastructure was changed to use praktika tool and we had to reimplement parts of the upstream CI/CD for our usage once again.
Some technical improvements in our fork
Just as ClickHouse® Inc. has its own fork to serve its own business needs, our own fork helps us serve our customers better by introducing new features and technical improvements based on their specific use cases and needs.
Here are some of the most important changes we've made.
Packed part format
The most expensive part of using ClickHouse® MergeTree + zero_copy on top of S3/GCP comes from S3 write operations. One of the first features that we developed in our fork was the packed part format.
Our changes allow us to combine, in a single packed file, all of the small files that are generated with each Compact or Wide MergeTree part. When you need to access any one of the original files, you will find a packed file instead.
This sounds easy conceptually but it was pretty hard to properly support a packed part format with ReplicatedMergeTree and zero-copy. Storage and Replication are extremely important in ClickHouse®; any bug could potentially lead to data loss or complex replication issues. Also, zero-copy support in ClickHouse® was spread pretty heavily across the code in ReplicatedMergeTree, DataPartsExchange, DataPartStorage, Disks, MutateTask and some of the components unfortunately know too much about each other. The final pull request for this feature had over 2500 LOC and 68 files changed.
After deploying our packed part format to production clusters, we were able to see a 30%-40% reduction in S3 write operations:
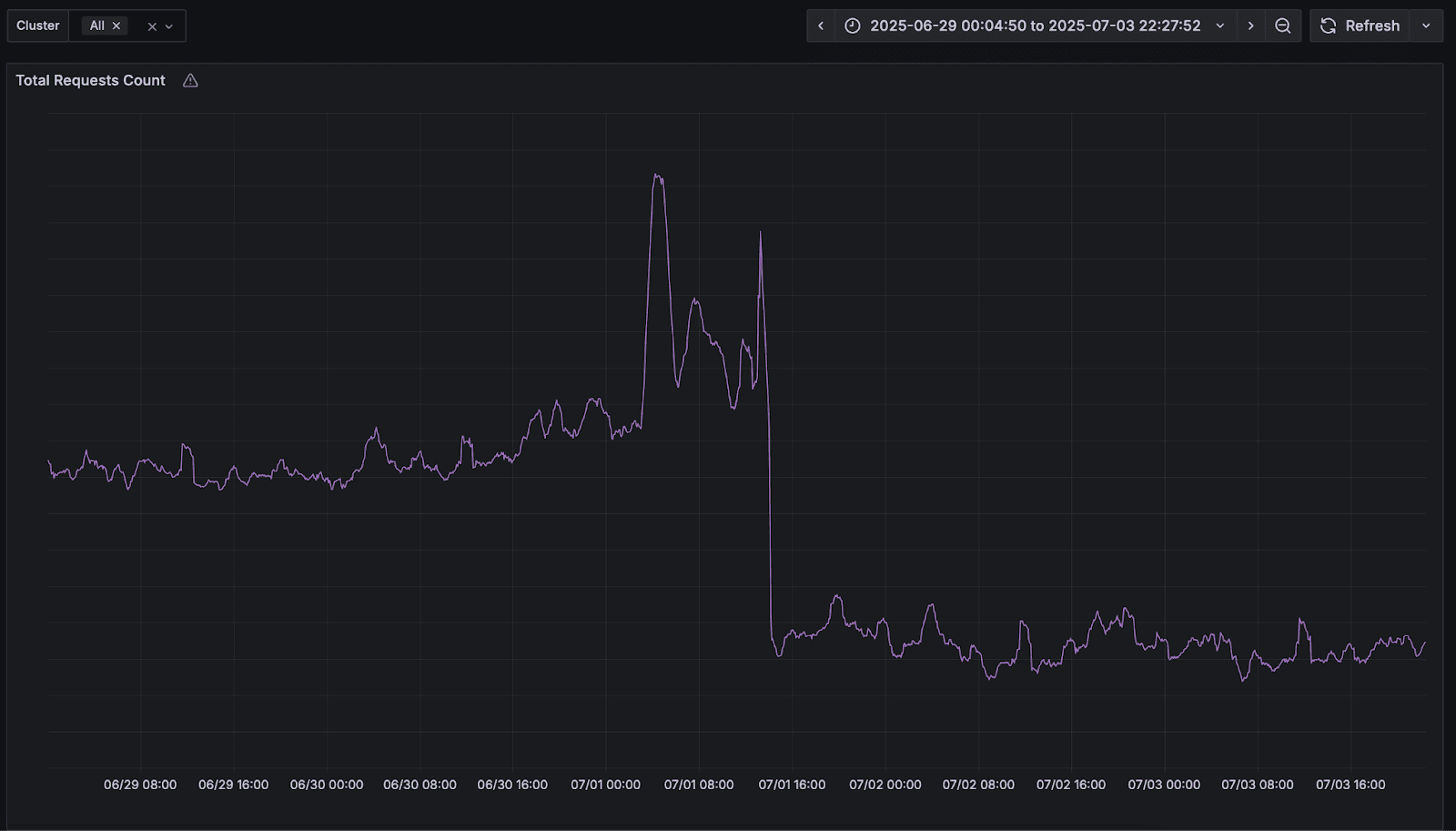
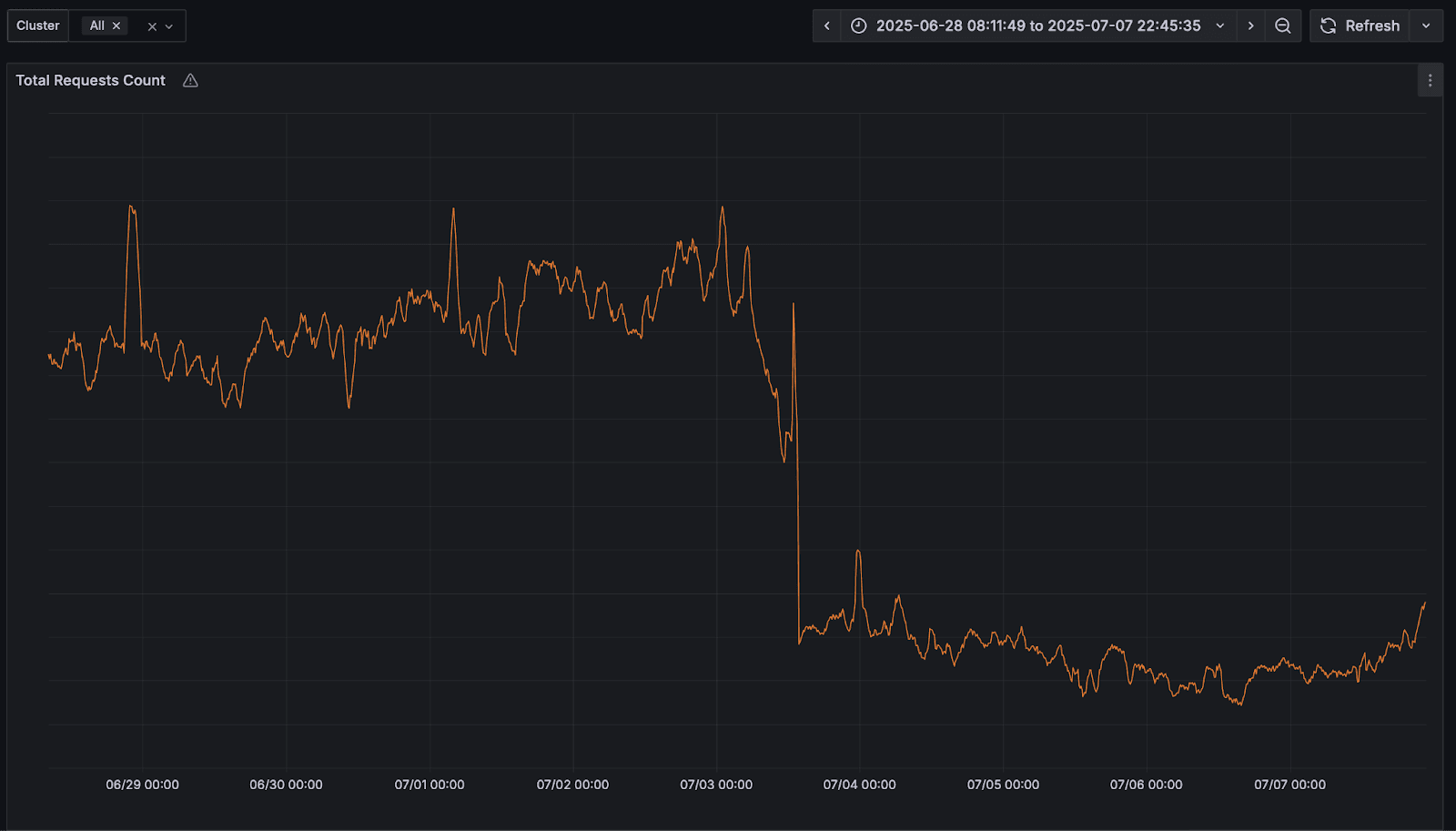
Work continues on improving our implementation. We'll write about this more soon.
Backup database engine
When upgrading ClickHouse® versions, you often encounter performance issues and edge cases that only reproduce with production data, making it risky to test upgrades. Restoring backup data can become very expensive and time consuming.
We added a new Backup Database engine in ClickHouse® 25.2 that allows users to instantly attach tables and databases from backups in read-only mode. The engine works with both incremental and non-incremental backups across all backup engines (S3, Azure, File, Disk) without requiring data restoration.
The implementation uses BackupDisk for path translation and DatabaseBackup for metadata handling, making it as simple as specifying the same backup engine used during backup creation. This made it much easier for us (and anybody using open source ClickHouse®) to validate ClickHouse® upgrades against production data without problems or performance degradation.
You can read more about our ClickHouse® Backup enngine implementation here.
UNION support for materialized views
In ClickHouse® master (25.8.1.477), UNION with materialized views is not supported. This was actually related to a clickhouse 25.2 memory leak union all view issue. Here's a demo to show:
DROP TABLE IF EXISTS test_table;
CREATE TABLE test_table(id UInt64, value String) ENGINE=MergeTree ORDER BY id;
DROP VIEW IF EXISTS test_table_mv;
CREATE MATERIALIZED VIEW test_table_mv ORDER BY id
AS SELECT id, value FROM test_table WHERE id == 0 UNION ALL SELECT id, value FROM test_table WHERE id == 1;
INSERT INTO test_table VALUES (0, 'Value_0'), (1, 'Value_1'), (2, 'Value_2');
SELECT id, value FROM test_table_mv ORDER BY id;
In ClickHouse® master, the second part is just ignored:
./clickhouse client
ClickHouse® client version 25.8.1.477 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse® server version 25.8.1.
┌─id─┬─value───┐
│ 0 │ Value_0 │
└────┴─────────┘
In our fork, however, the UNION is respected:
┌─id─┬─value───┐
│ 0 │ Value_0 │
│ 1 │ Value_1 │
└────┴─────────┘
This feature was pretty important for one of our clients. Without it, you need to simulate such data flow with multiple materialized views to a single destination table, which makes INSERTs much slower. This one was a good example where having our own fork helped us prioritize a feature that was very important to one of our larger customers. It also addresses the clickhouse 25.2 memory leak union all view problem that affected many users.
MergeTree reader inplace filtering
In ClickHouse®, the IColumn interface barely has any methods that can mutate a column due to safety requirements in multithreaded environment. Most of the time when you need to modify a column you must first copy it, but in some cases it's clear you are the column owner, and you can actually apply in-place mutation methods instead.
One such place is in the PREWHERE stage when reading data from MergeTree. In our fork, we added an inplace filter method for columns and used it instead of an ordinary filter. It is most helpful when we have a query with String columns, because copying strings is very slow:
-- Query performance in ClickHouse® (master)
SELECT CounterID, AVG(length(URL)) AS l, COUNT(*) AS c FROM hits WHERE URL <> ''
GROUP BY CounterID HAVING COUNT(*) > 100000 ORDER BY l DESC LIMIT 25 FORMAT Null;
0 rows in set. Elapsed: 1.059 sec. Processed 100.00 million rows, 19.88 GB (94.47 million rows/s., 18.78 GB/s.)
Peak memory usage: 281.71 MiB.
-- Query performance in our fork
SELECT CounterID, AVG(length(URL)) AS l, COUNT(*) AS c FROM hits WHERE URL <> ''
GROUP BY CounterID HAVING COUNT(*) > 100000 ORDER BY l DESC LIMIT 25 FORMAT Null;
0 rows in set. Elapsed: 0.743 sec. Processed 100.00 million rows, 10.34 GB (134.67 million rows/s., 13.92 GB/s.)
Peak memory usage: 196.07 MiB.
That's about 30% performance improvement.
Some additional features
The following are some other examples of features that either helped us more efficiently run our infrastructure or tackle specific customer needs:
- Soft and hard limits for ZooKeeper message sizes
- Several HTTP headers for queries introspection
- Functions for working with DynamoDB JSON
- PostgreSQL storage and table function improvements
There are many others like these. Having our own fork has helped us prioritize these things even when they may not have been prioritized in the upstream project.
Controlling the build process and releases
An important reason for choosing to fork ClickHouse®: we can build faster and release more often. If we were contributing to and using the upstream project, our customers would have to wait for fixes.
The ClickHouse® OS build and release process works more or less as explained below. If, for example, you have a bug and a fix for it in some LTS ClickHouse® OS version, you must:
- Create ClickHouse® upstream pull request.
- Wait until someone from the core team approves the CI run.
- Wait until someone from the core team reviews the pull request.
- Wait for the pull request to be merged to upstream.
- Ask the ClickHouse® Inc. team to backport this fix to all LTS versions. This is done automatically with
pr-backportandpr-must-backportlabels. Sometimes, however, automatic backports will not work in case of conflicts, so you or someone from the ClickHouse® Inc. team will need to manually fix them. - Wait for the backport to be merged to the LTS version.
- Wait for a new LTS version to be released. Most of the time you do not need to ask the ClickHouse® Inc. team for this.
As you can see, there are a lot of steps, and your fix can get stuck in any one of them. The ClickHouse® Inc. team does a great job with handling bug backports, but even in the best case scenario the process takes a few days.
And, if your version is a bit outdated, it may not even be possible to make a backport and release to your version. If you have large ClickHouse® production clusters (as we do), you are very careful with upgrades, and you perform upgrades only when absolutely necessary, so this can become a big problem.
Below are some specific cases where we have benefited from our private fork allowing us to build and release more quickly.
GWP ASAN performance degradation
During a migration of one of our big clients to the new 24.12 ClickHouse® version, we were able to detect, before the actual cluster upgrade, a huge performance degradation (around 30%) in median query latencies because of GWP ASAN.
So, we disabled GWP ASAN for our builds for all versions starting from 24.6. We made releases of these versions on the same day and were able to make the same day rollout for this specific client. In the end it, it not only fixed the 30% degradation for our client, but also let us do it faster.
Versions migration
Pretty much any time you upgrade a client to a new ClickHouse® version, you have some issues. The performance of certain functionality can change, there can be documented/undocumented backward incompatible changes, some settings can be introduced/changed, and some settings can become completely unnecessary. We wrote a lot about this in our blog post about the Backup engine.
At Tinybird, we do a lot to make this process as easy as possible for our clients. For example we have a custom validation tool that we run for each client before upgrade to be sure that client queries are valid, and we validate settings changes and performance changes between versions.
When we run a version migration on our fork, we have a special process to run ClickHouse® performance tests between actual release versions. Based on the results, we collect the most important regressed tests and try to fix the issues. Internally it looks like this:
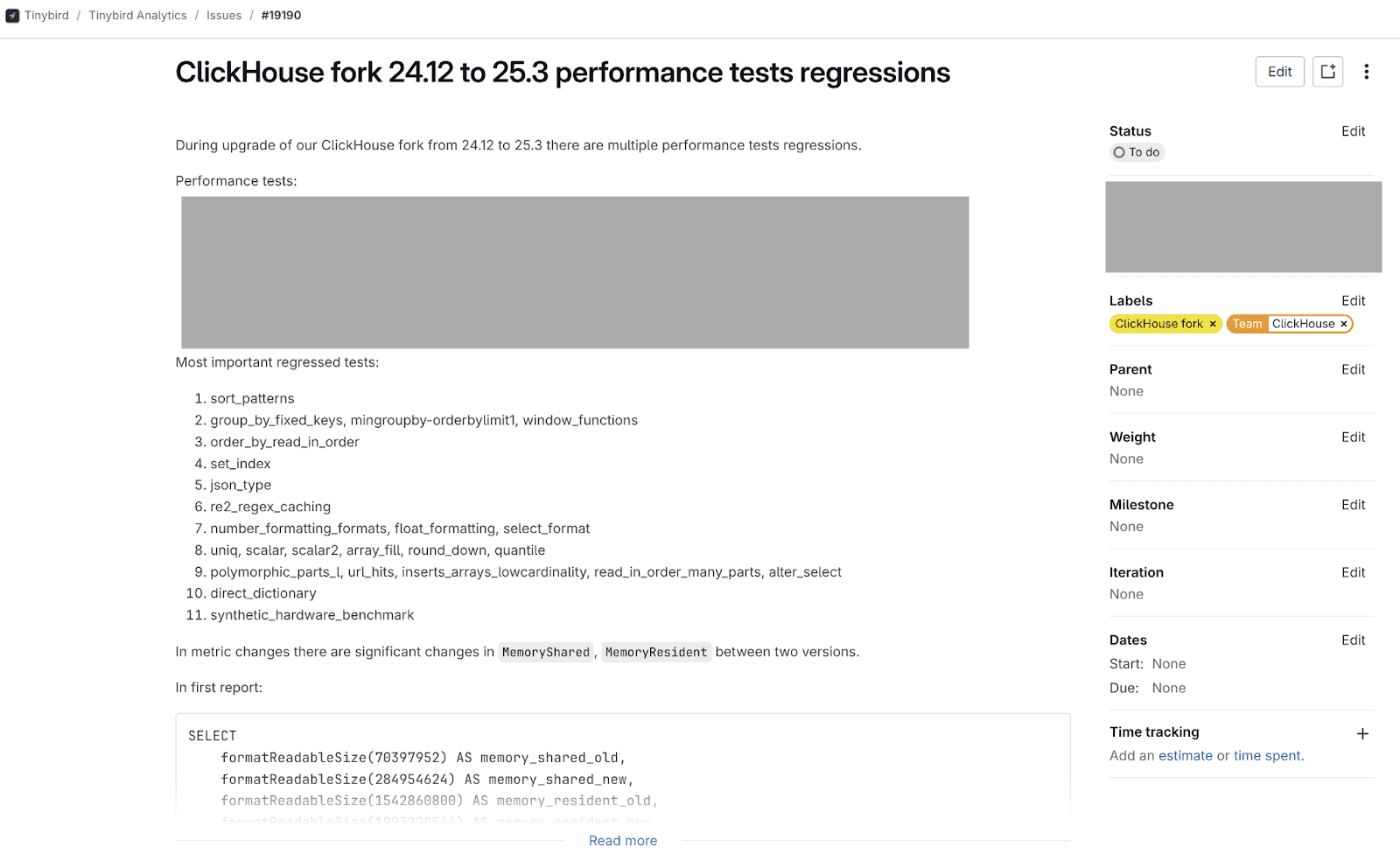
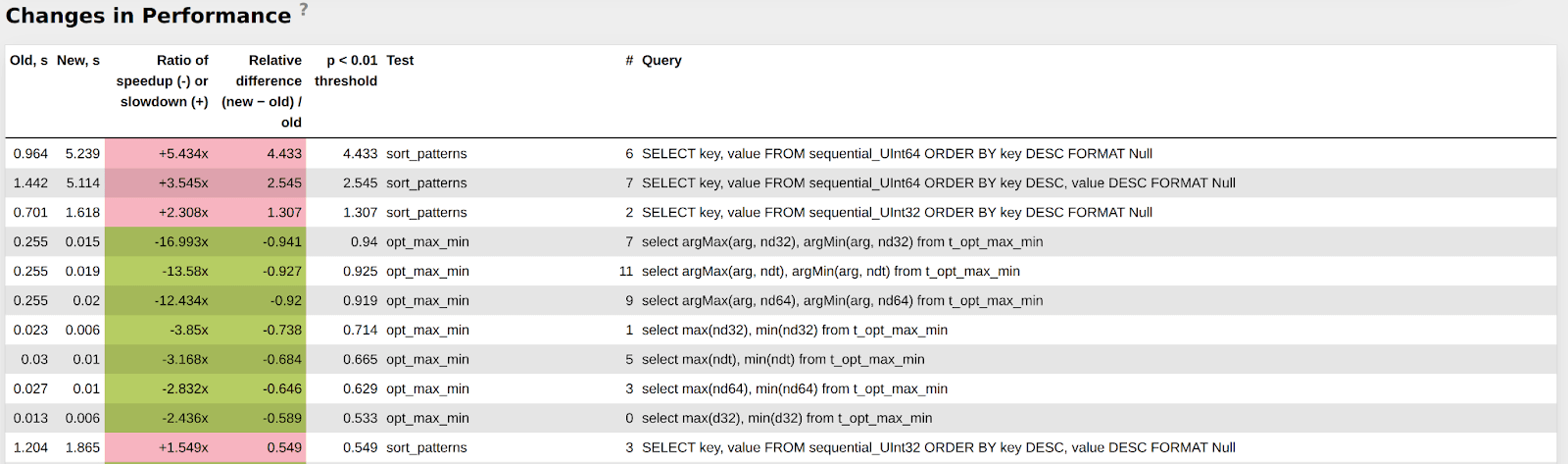
As I wrote above, our CI is exactly the same as ClickHouse® CI, so our performance reports are exactly the same. For example, we found out degradation with sort_patterns that was introduced a long time ago and was fixed in this PR.
We can fix and release on the same day
We've had many cases when we were able to make a fix and release at the same day for some clusters. This can have a huge impact, because if you upgrade a cluster to the new version and operate it for a while, proper cluster downgrade can be pretty complex and dangerous. But, if you are able to make a quick fix and release at the same time, you can avoid downgrades in a lot of scenarios.
Conclusion
Maintaining a private ClickHouse® fork at Tinybird has been a journey of balancing significant upfront investment against the long‑term gains of flexibility, performance, and control. By having exactly the same CI/CD pipeline as the open source version, we are enable to trust our builds and roll them into production confidently.
All of these improvements add up to both feature and performance upgrades for our customers as well as infrastructure cost reductions for us (which in turn impacts how much we must charge for our service). Our packed-part format and zero-copy improvements, for example, have driven significant cost savings on S3 and GCP. This is how is tinybird different from clickhouse cloud in terms of optimization and clickhouse security news.
In the end the ability to develop private features, tweak the build process, control performance between releases, and ship same-day fixes has allowed us to provide a better service for our customers - and this is why we maintain a ClickHouse® fork.
Tinybird is not affiliated with, associated with, or sponsored by ClickHouse®, Inc. ClickHouse® is a registered trademark of ClickHouse®, Inc.