Analyze the performance of your API Endpoints¶
This guide explains how to use pipe_stats and pipe_stats_rt, giving several practical examples that show what you can do with these Service Data Sources.
Tinybird is all about speed. It gives you tools to make real-time queries really quickly, and then even more tools to optimize those queries to make your API Endpoints faster.
Of course, before you optimize, you need to know what to optimize. That's where the Tinybird pipe_stats and pipe_stats_rt Data Sources come in. Whether you're trying to speed up your API Endpoints, track error rates, or reduce scan size (and subsequent usage costs), pipe_stats and pipe_stats_rt let you see how your API Endpoints are performing, so you can find performance offenders and get them up to speed.
These Service Data Sources provide performance data and consumption data for every single request, plus you can filter and sort results by Tokens to see who is accessing your API Endpoints and how often.
Confused about the difference between pipe_stats_rt and pipe_stats? pipe_stats provides aggregate stats - like average request duration and total read bytes - per day, whereas pipe_stats_rt offers the same information but without aggregation. Every single request is stored in pipe_stats_rt. The examples in this guide use pipe_stats_rt, but you can use the same logic with pipe_stats if you need more than 7 days of lookback.
Prerequisites¶
You'll need a high-level understanding of Tinybird's Service Data Sources.
Understand the core stats¶
In particular, this guide focuses on the following fields in the pipe_stats_rt Service Data Source:
pipe_name(String): Pipe name as returned in Pipes API ("query_api" in the event it is a Query API request).duration(Float): the duration in seconds of each specific request.read_bytes(UInt64): How much data was scanned for this particular request.read_rows(UInt64): How many rows were scanned.token_name(String): The name of the Token used in a particular request.status_code(Int32): The HTTP status code returned for this particular request.
You can find the full schema for pipe_stats_rt in the API docs.
Example 1: Detect errors in your API Endpoints¶
If you want to monitor the number of errors per Endpoint over the last hour, you could do the following:
Errors in the last hour
SELECT pipe_name, status_code, count() as error_count FROM pipe_stats_rt WHERE status_code >= 400 AND start_datetime > now() - INTERVAL 1 HOUR GROUP BY pipe_name, status_code ORDER BY status_code desc
If you have errors, this would return something like:
OUTPUT
Pipe_a | 404 | 127 Pipe_b | 403 | 32
And that's it! With just one query, you can see in real time if your API Endpoints are experiencing errors, and investigate further if so.
Example 2: Analyze the performance of API Endpoints over time¶
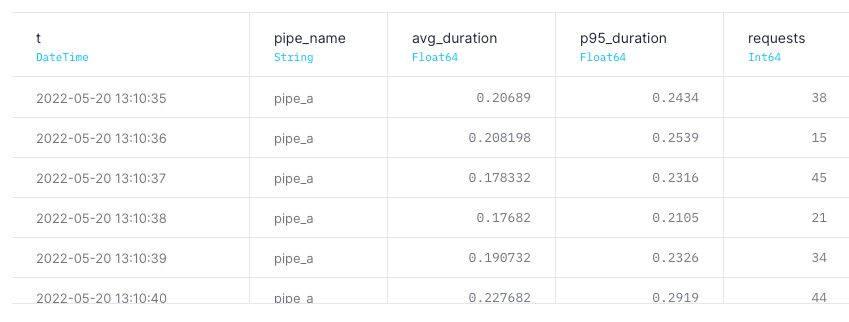
You can also use pipe_stats_rt to track how long API calls take using the duration field, and seeing how that changes over time. API performance is directly related to how much data you are reading per request, so if your API Endpoint is dynamic (for instance, maybe it's receiving start and end date parameters that alter how long a period is being read), request duration will vary.
API Endpoint performance over time
SELECT
toStartOfMinute(start_datetime) t,
pipe_name,
avg(duration) avg_duration,
quantile(.95)(duration) p95_duration,
count() requests
FROM tinybird.pipe_stats_rt
WHERE
start_datetime >= {{DateTime(start_date_time, '2022-05-01 00:00:00', description="Start date time")}} AND
start_datetime < {{DateTime(end_date_time, '2022-05-25 00:00:00', description="End date time")}}
GROUP BY t, pipe_name
ORDER BY t desc, pipe_name
Example 3: Find the Endpoints that process the most data¶
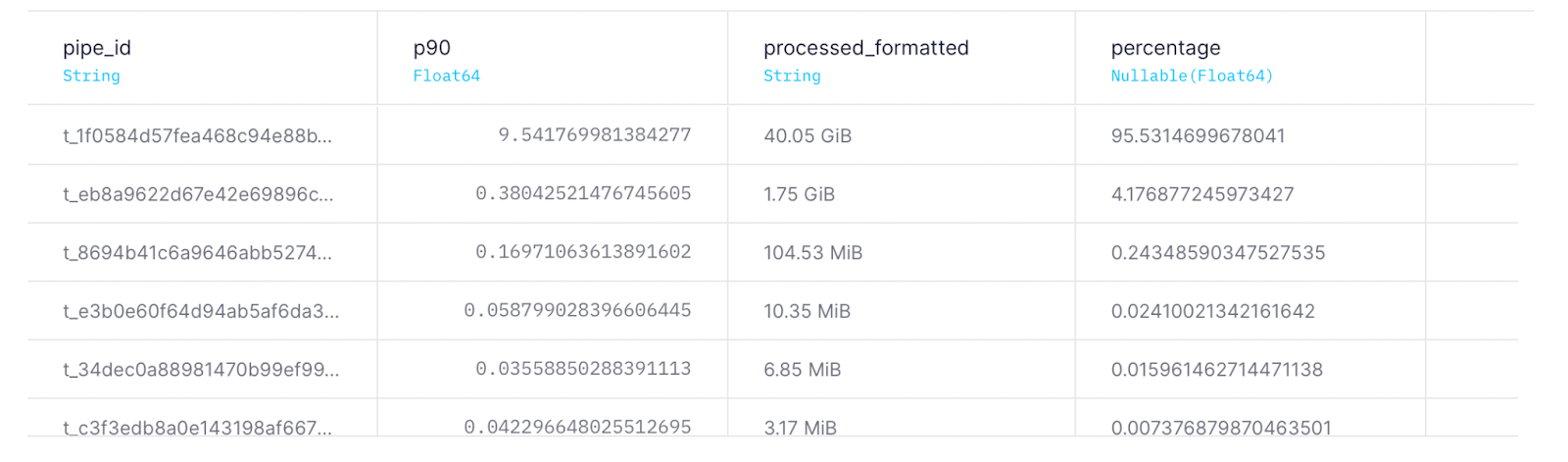
You'll want to find Endpoints that repeatedly scan large amounts of data. These are your best candidates for optimization to reduce time and spend.
Here's an example of using pipe_stats_rt to find the API Endpoints that have processed the most data as a percentage of all processed data in the last 24 hours:
Most processed data last 24 hours
WITH ( SELECT sum(read_bytes) FROM tinybird.pipe_stats_rt WHERE start_datetime >= now() - INTERVAL 24 HOUR ) as total, sum(read_bytes) as processed_byte SELECT pipe_id, quantile(0.9)(duration) as p90, formatReadableSize(processed_byte) AS processed_formatted, processed_byte*100/total as percentage FROM tinybird.pipe_stats_rt WHERE start_datetime >= now() - INTERVAL 24 HOUR GROUP BY pipe_id ORDER BY percentage DESC
Modifying to include consumption of the Query API¶
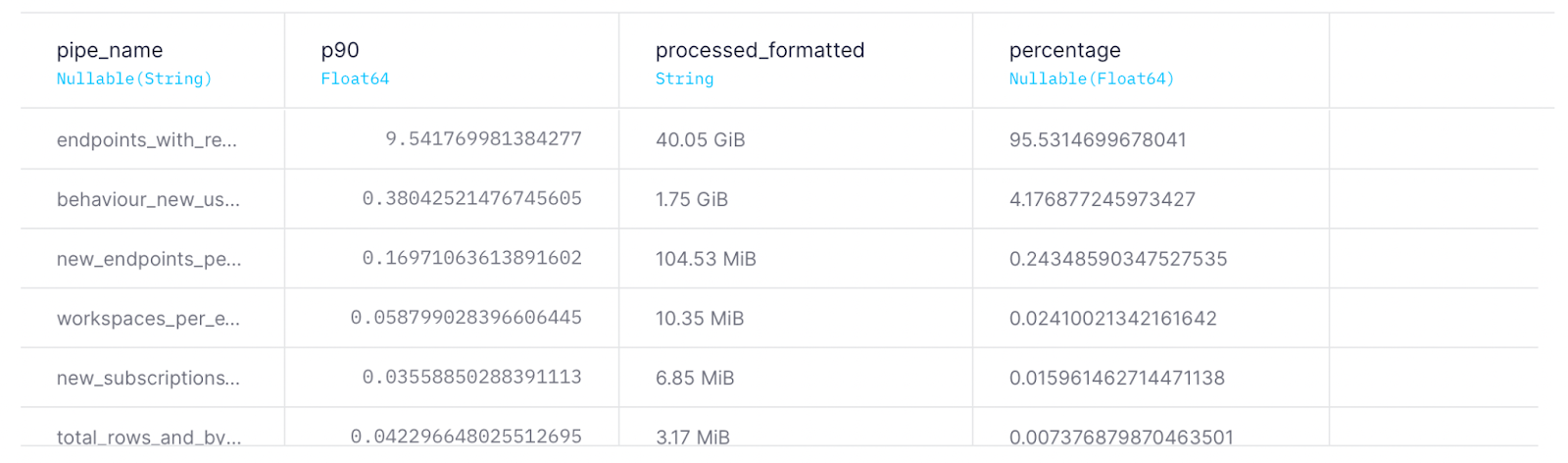
If you use Tinybird's Query API to query your Data Sources directly, you probably want to include in your analysis which queries are consuming more.
Whenever you use the Query API, the field pipe_name will contain the value query_api. The actual query will be included as part of the q parameter in the url field. You can modify the query in the previous section to extract the actual SQL query that is processing the data.
Using the Query API
WITH ( SELECT sum(read_bytes) FROM tinybird.pipe_stats_rt WHERE start_datetime >= now() - INTERVAL 24 HOUR ) as total, sum(read_bytes) as processed_byte SELECT if(pipe_name = 'query_api', normalizeQuery(extractURLParameter(decodeURLComponent(url), 'q')),pipe_name) as pipe_name, quantile(0.9)(duration) as p90, formatReadableSize(processed_byte) AS processed_formatted, processed_byte*100/total as percentage FROM tinybird.pipe_stats_rt WHERE start_datetime >= now() - INTE RVAL 24 HOUR GROUP BY pipe_name ORDER BY percentage DESC
Example 4: Monitor usage of Tokens¶
If you use your API Endpoint with different Tokens, for example if allowing different customers to check their own data, you can track and control which Tokens are being used to access these Endpoints.
Here's an example that shows, for the last 24 hours, the number and size of requests per Token:
Token usage last 24 hours
SELECT count() requests, formatReadableSize(sum(read_bytes)) as total_read_bytes, token_name FROM tinybird.pipe_stats_rt WHERE start_datetime >= now() - INTERVAL 24 HOUR GROUP BY token_name ORDER BY requests DESC
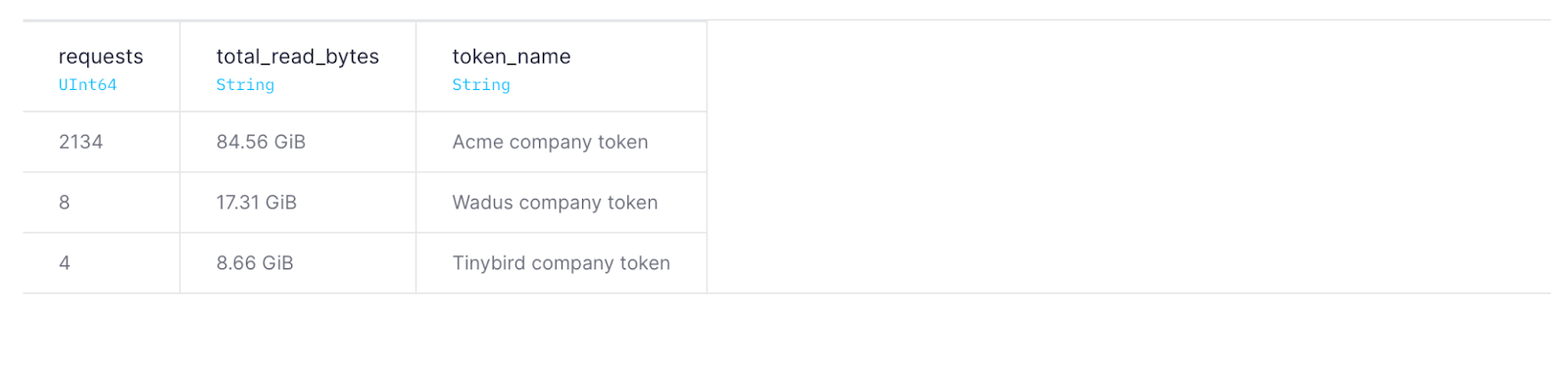
In order to obtain this information, you can request the Token name (token_name column) or id (token column).
Check the limits page for limits on ingestion, queries, API Endpoints, and more.
Next steps¶
- Want to optimize further? Read Monitor your ingestion.
- Learn how to monitor jobs in your Workspace.
- Monitor the latency of your API Endpoints.
- Learn how to build Charts of your data.