


If you’re looking to add stream processing capabilities to your existing Kafka infrastructure, ksqlDB may have made your shortlist. As a companion to Kafka, ksqlDB has many strengths as an SQL-based stream processing engine. But it also has limitations, some of which can become significant hurdles for data and engineering teams.
In this post, I will provide an in-depth comparison between ksqlDB, the original streaming SQL engine for Apache Kafka, and Tinybird, a real-time data platform designed for speed and scalability.
In this post, I'll explore the strengths and limitations of ksqlDB, and explain how Tinybird can replace ksqlDB for certain stateful stream processing use cases.
My objective is to delve deep into the features, strengths, and weaknesses of ksqlDB, demonstrate how Tinybird can address ksqlDB's limitations, and equip you with the knowledge to make informed decisions about the most suitable tool for your real-time use cases.
What is ksqlDB?
ksqlDB is an open source streaming SQL engine for Apache Kafka, developed and maintained by Confluent. ksqlDB is built on top of Kafka Streams, a client library for writing stream processing applications over Kafka.
Whereas Kafka Streams demands custom code in Python or Java, ksqlDB abstracts stream processing with an SQL layer that’s more comfortable for a wider range of users. This is a deliberate choice of ksqlDB to sacrifice flexibility in favor of ease of use.
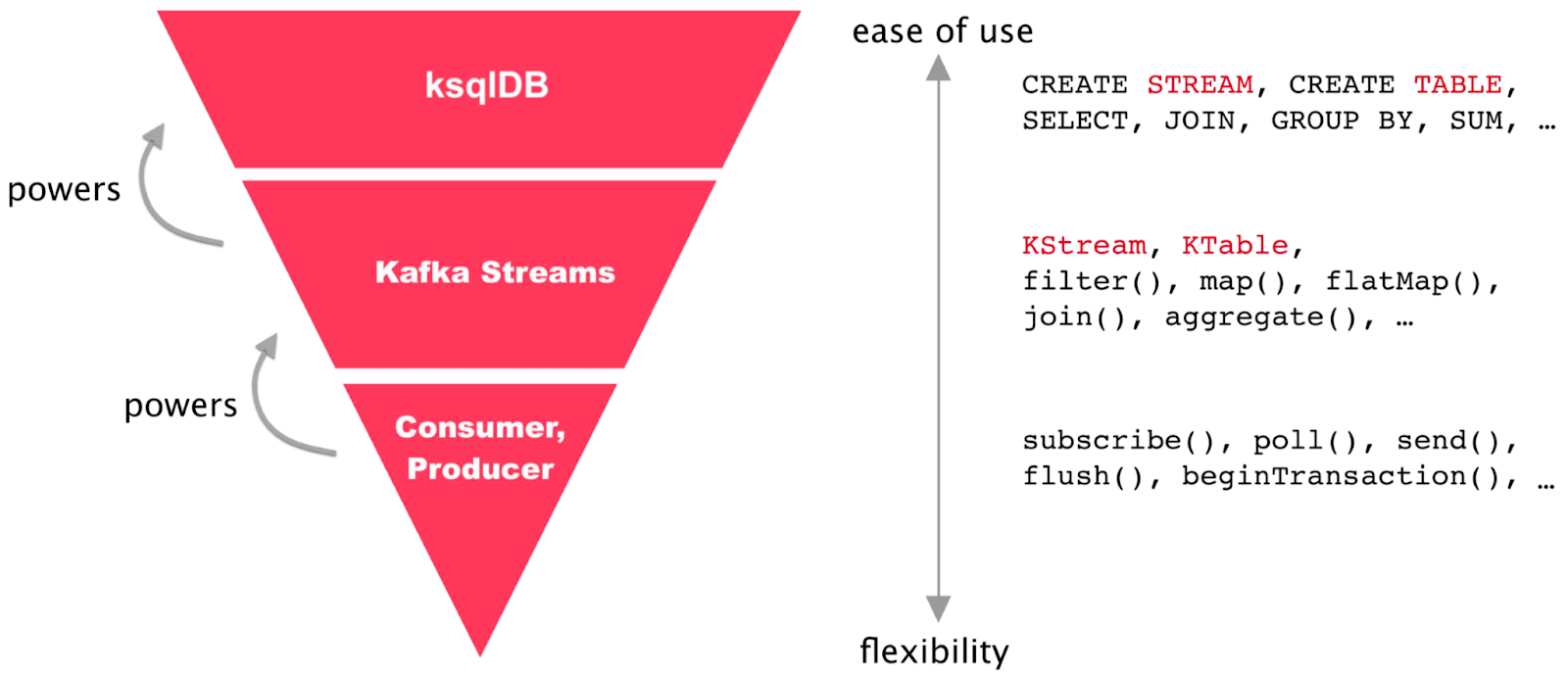
With ksqlDB, you can transform, enrich, aggregate, and filter streams of data in real-time. It supports event time processing and can handle late-arriving data.
ksqlDB is deployed as a cluster of servers that sit adjacent to a Kafka cluster. This means that, while you can reuse your existing Kafka cluster as the storage layer, there is additional hardware and software to deploy and manage. Confluent offers a managed ksqlDB service alongside their managed Kafka service at an additional cost.
Like any technology, ksqlDB has its strengths and weaknesses, which users should consider when deciding if it's the right tool for their use case.
Strengths of ksqlDB
ksqlDB is very good for certain uses cases, particularly stateful stream processing with minimal state. It's much easier to use and learn than Kafka Streams thanks to its SQL abstraction, and it integrates well with the Kafka ecosystem.
ksqlDB is easier to use than Kafka Streams
Compared to the more esoteric Kafka Streams, ksqlDB lowers the stream processing entry barrier by abstracting the complexities of Python and Java for data processing into a simple SQL engine. Users can define streams declaratively, with simple SQL statements, which makes it much easier to use by a broader group of people.
ksqlDB has real-time data processing capabilities
As a stream processing engine, ksqlDB allows for real-time data processing and transformations over streaming data, which is crucial in today's fast-paced business environment. Compared to batch-based Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) modalities and tools, which by nature cannot handle stream data processing, ksqlDB is optimized to process and transform data in flight, sourcing from Kafka topics and sinking into downstream systems (including Kafka) in a matter of milliseconds.
ksqlDB is optimized for real-time data processing and transformations over small time windows and narrow tables with low cardinality fields.
For example, assume you had an e-commerce store emitting events to a Kafka topic called sales with the following schema:
If you wanted to convert the timestamp to a different format before passing it to a new Kafka topic, ksqlDB would be a great choice of tooling. Similarly, if you wanted to route messages to different topics by their UTM code or some custom Kafka headers, ksqlDB would work very well. Or perhaps you want to create a new field that concatenates the item_id with the utm. Again, ksqlDB would be perfect.
ksqlDB has a tight integration with Kafka
Perhaps the most attractive aspect of ksqlDB is its tight coupling with Apache Kafka. As a tool developed by the creators of Apache Kafka, ksqlDB integrates very well with the Kafka ecosystem and can leverage Kafka's scalability and fault tolerance.
Limitations of ksqlDB
Despite its strengths, ksqlDB is not perfect for certain use cases, especially when state starts growing. As such, you may consider alternatives if your use case requires more complex aggregations over large time windows.
ksqlDB is inefficient with long-running or high-cardinality aggregation
Routing, filtering, and running basic transformations over streaming data are the strengths of ksqlDB, and while it can perform some aggregations, it will suffer under more complex scenarios requiring large amounts of state.
ksqlDB relies on Kafka for state storage, and Kafka itself uses RocksDB as the underlying storage engine. RocksDB is a very fast, persistent key-value store. It is perfect for serving Kafka’s intended purpose as a distributed append log, where new events are simply appended to previous events and streamed in order.
However, it creates some inefficiencies for stream aggregating over long time windows or when grouping by high-cardinality fields.
ksqlDB cannot handle aggregations over unbounded time windows and struggles when grouping fields have high cardinality.
This state is kept in non-durable memory on ksqlDB, so for durable storage, ksqlDB pushes state onto a state changelog topic in Kafka. This presents challenges for complex aggregations, particularly where there may be many fields under aggregate, or if you need to store many windows, rather than a rolling window.
Consider the same sales topic I presented above, but now you want to calculate the rolling sum of sales grouped by UTM codes over a 15-minute window.
You could reasonably use ksqlDB to maintain this aggregation, assuming utm was a low cardinality field with few unique values. This is because you need to maintain very little state: If you have, say, 12 UTM codes, that’s only 12 key-value pairs to maintain.

But, what if you wanted to maintain an aggregate of revenue generated per item on a store selling hundreds or thousands of unique items? Here, ksqlDB would have a hard time.
In this scenario, where item_id has high cardinality, the state could be represented in a single event, with a key-value pair for each item: {item_id: sum()}. Assuming you had 500 unique items, the state has 500 key-value pairs. ksqlDB struggles to deal with high numbers of keys in state, quickly saturating the CPU.
Let’s consider an even more complex situation: maintaining revenue per item per hour and storing these hourly aggregations for up to a week.
With 24 hours per day over 7 days, you’d have 168 windows to maintain. With 500 unique items, you’d be forced to maintain 84,000 state values. This amount of state storage would rapidly cripple ksqlDB.
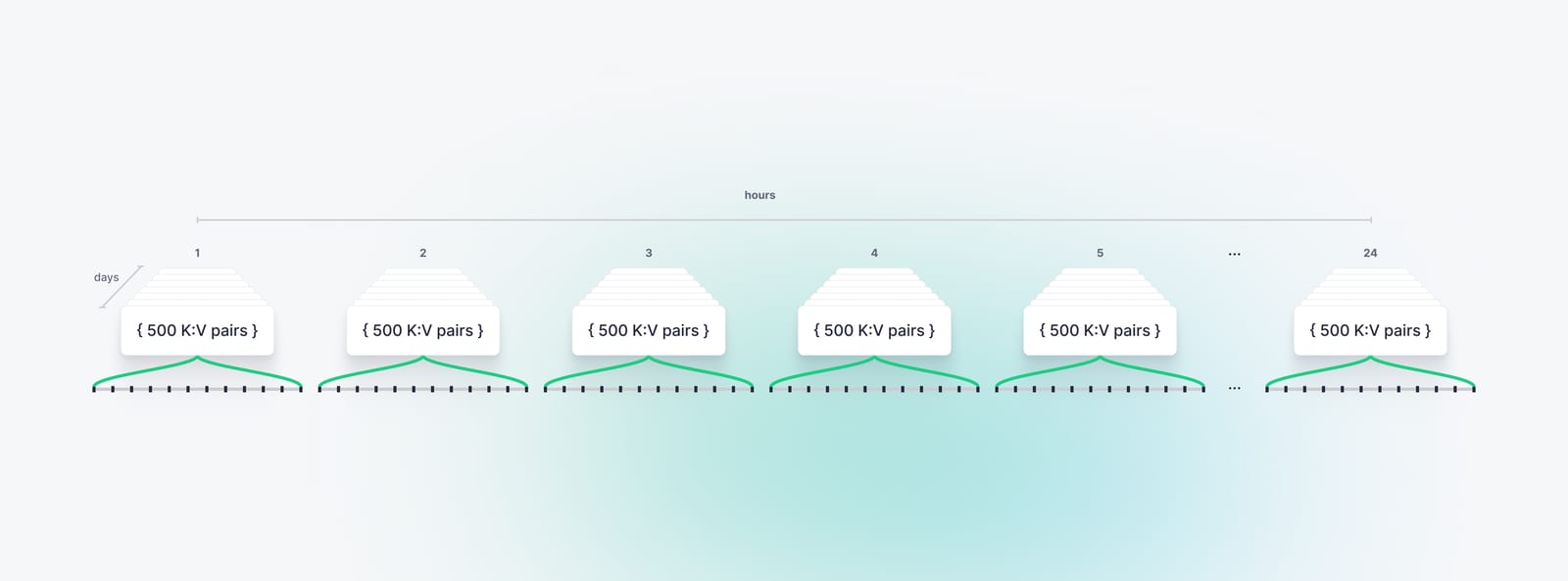
The problems here extend beyond just storing state, for the simple reason that calculating and persisting time-based aggregations are only valuable as an enabler for downstream use cases.
For example, suppose you wanted to compare the current performance of an item against its historical performance, perhaps when running a sale or offer. To do this, you would need to compute the latest state and retrieve the relevant historical state during the query.
You could, of course, naively compare the current state against the same window from yesterday, but this is an unintelligent approach. Instead, you’d want to compare the current aggregate state of the item against one or more aggregates of the historical state, for example, comparing against the item’s average performance in the same window in the past week or the item’s average performance across all windows in the past week.
In either case, you’d need to use the historical states at query time to compute two new aggregate values and compare them against the current aggregate. In the above example, you would need to scan all 84,000 keys in the Kafka state change topic to calculate the average only for a single item.
You can see how processing each message quickly becomes untenable, and, unfortunately with ksqlDB, the options to optimize are limited.
ksqlDB is not optimized for analytics
As I mentioned above, ksqlDB relies on Kafka as its source of stored data, and Kafka itself uses RocksDB as the underlying storage engine. In general, key-value storage modalities are not optimized for running real-time analytics.
One of the core tenants behind optimizing analytics for speed and scale is to read less data. The less data you must scan for each query, the fewer compute resources you require and the faster you can return a response with limited hardware. As a corollary, you’ll spend less money running each query.
To facilitate fast reads for analytics, most OLAP storage engines utilize “data skipping” techniques. Columnar storage is quite common for analytical systems, as it breaks incoming rows into their distinct columns and stores data in columns sequentially on disk. The data of one column is stored together and is indexed or ordered by a key.
When a query on such a system needs to aggregate a single column, it reads only the data in that column and never needs to read any of the other columns from disk.
Furthermore, because the data is indexed by a key, the query may even skip certain rows within that column. It’s common to index time series data by timestamp, and if a query aggregates on a specific time range, it can skip much of the data. It will start reading when it reaches the first value within the range, then read until it is out of the range again, with confidence that there is no more data to be read.
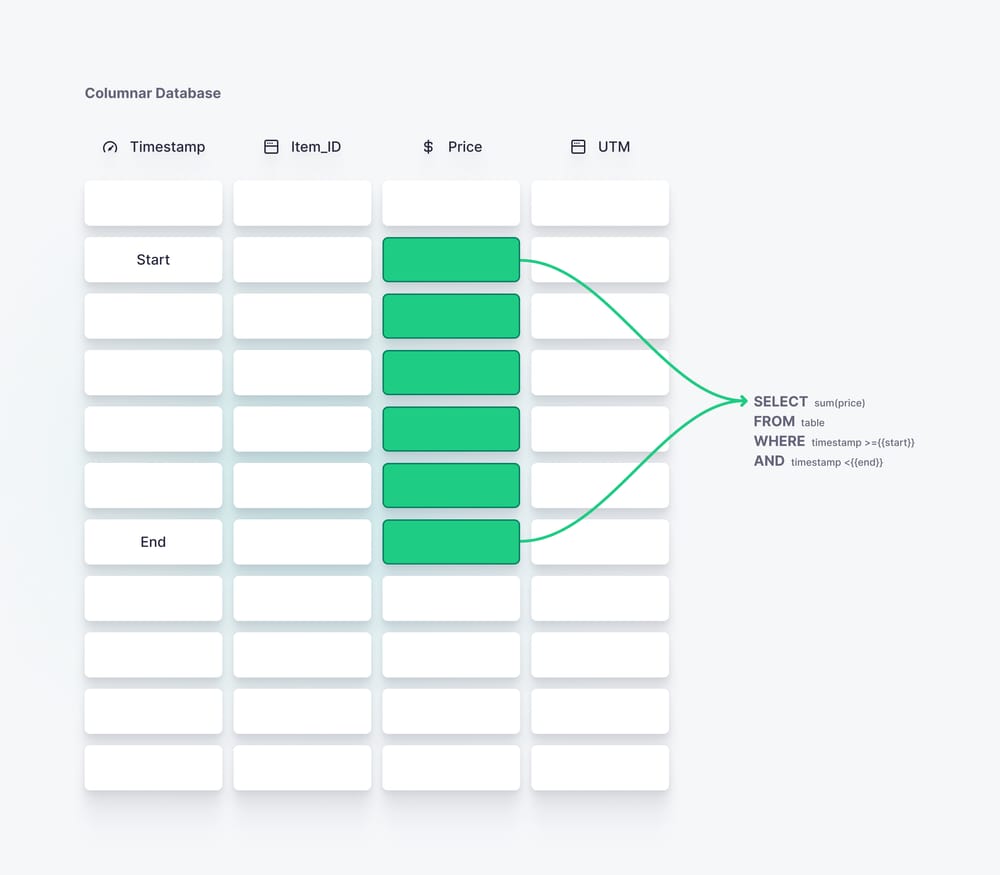
Conversely, a key-value append log like Kafka does not have any of these capabilities. An event is stored in its entirety as a single key-value pair, and it is stored on disk in the order that it arrives. When a ksqlDB query aggregates over a Kafka topic, all events (and all of the event fields) in the topic must be read and evaluated by the query.

And unfortunately, there’s not much you can do about this. ksqlDB simply has very little room to minimize the amount of data scanned and thus optimize query performance.
ksqlDB is not a database
Despite what the influencers may tell you, neither Kafka nor ksqlDB are databases or query engines in their own right. Behind every SQL query run on ksqlDB is a Kafka Streams application, and every query executed in ksqlDB creates its own instance of a Kafka Streams worker threads. This means that every query uses its own consumers and producers, which adds overhead to every query.
When performing aggregations, ksqlDB must store the current aggregation in memory. To do this, it creates an instance of RockDB to use as the state store. This state store has a memory overhead of 50MB in addition to the memory used to store the actual state data. One state store is used per partition, meaning a single topic with 6 partitions will consume 300MB of memory purely in overheads for the state store.
Because ksqlDB carries a fair amount of overhead, the official documentation recommends separate clusters for each use case.
Because of the lack of optimization and significant overheads, the official recommendation is to deploy a ksqlDB cluster per use case to guarantee resources to specific use cases. This can quickly become untenable both in terms of maintaining many clusters and the associated costs, but also in simplifying mapping and cataloging all of the use cases and their supporting clusters. As if data engineers needed another thing to try to maintain in the back of their minds.
ksqlDB places extra strain on Kafka
Kafka is critical infrastructure for companies that rely on streaming data for operational intelligence and user-facing analytics. It is likely serving many downstream use cases across multiple products and teams, and it has been carefully scaled - from the amount of hardware, through to the configuration of replication and partitioning on topics - to handle a known load.
Adding ksqlDB to Kafka puts additional pressure on Kafka for both read and write operations. Every ksqlDB "push" query is another constant consumer on a topic, while every "pull" query will be an ad-hoc/inconsistent consumer that may read an entire topic in one burst.
This additional load can be hard to predict and can impact other use cases that depend on the same Kafka cluster.
In some cases, ksqlDB will also need to write to Kafka, putting further strain on the infrastructure. These cases may include:
- Queries that repartition the incoming topic, creating a new topic and pushing repartitioned data into it.
CREATE STREAMqueries, which create additional output topics for the result of the query.- Queries using stateful operations, that need to write data into new state changelog topics in Kafka as its persistent state store.
- ksqlDB commands, which can be logged into a commands topic
Many ksqlDB queries place added strain on your Kafka cluster.
Adding ksqlDB to your Kafka setup often requires an increase in the size of your Kafka cluster to handle the load. Scaling those workloads may also require complex maintenance tasks over existing Kafka topics, such as repartitioning.
ksqlDB adds operational complexity
ksqlDB is intrinsically tied to Kafka, which means that not only will you need to introduce and manage the ksqlDB service, but it will also impact how you manage Kafka itself.
Deploying and scaling the ksqlDB service demands many considerations. For example, running ad-hoc or “interactive” queries requires that a ksqlDB cluster be configured in “Interactive” mode, while other clusters may run in “Headless” mode. If you can’t keep track of which cluster is which, you’ll have confusion over where to execute specific workloads.
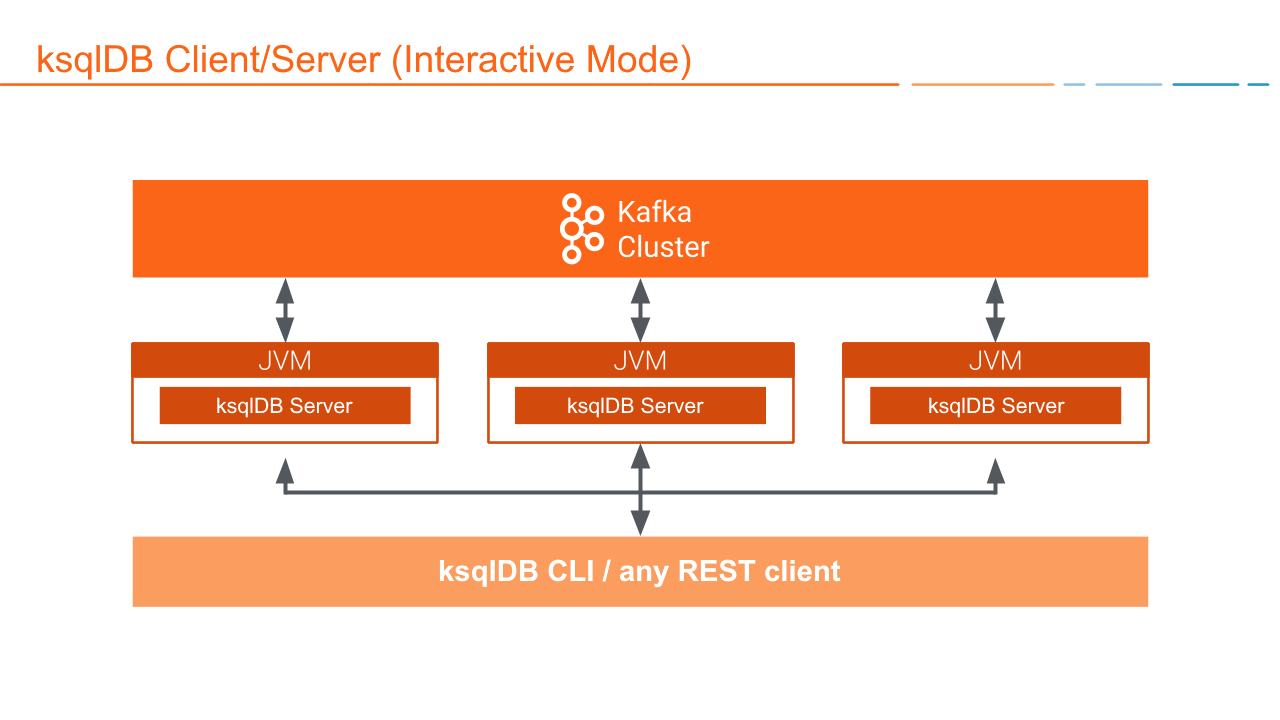
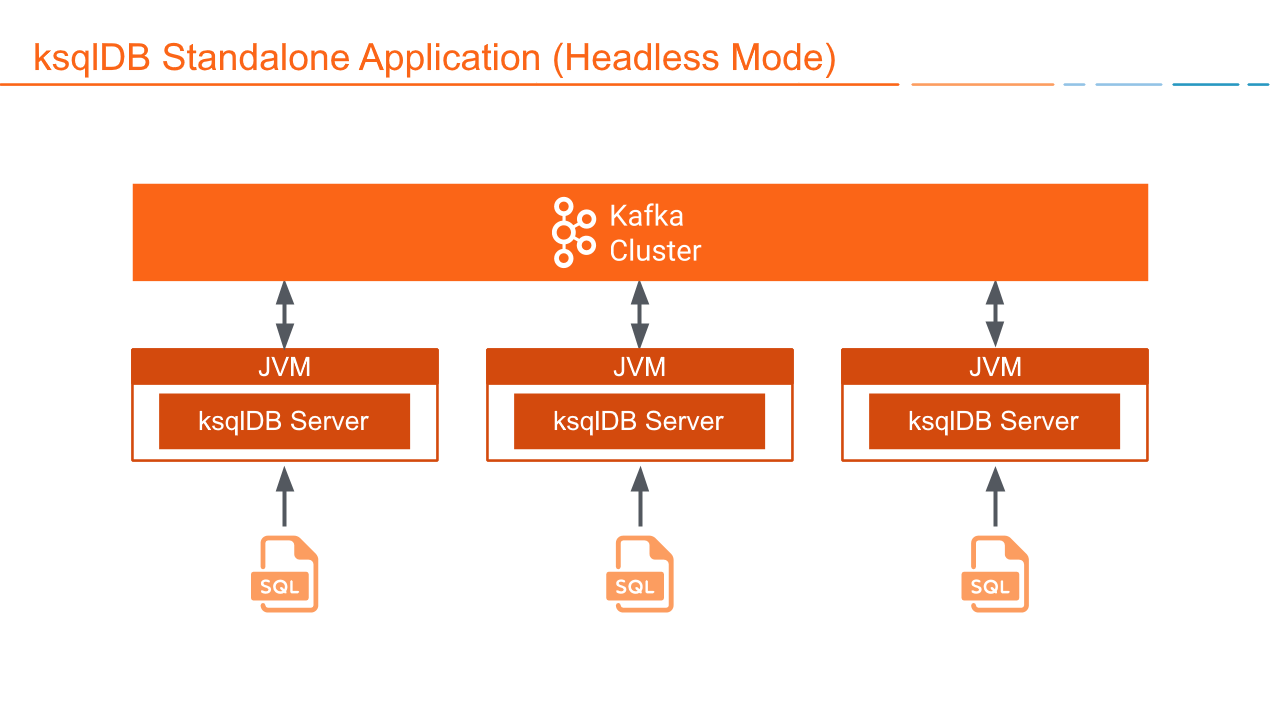
In addition, ksqlDB has no load balancing mechanism to equitably share resources between queries. One large workload can easily consume the cluster’s resources and starve other queries. To circumvent this, you must configure multiple ksqlDB clusters to segregate workloads, which creates more services to maintain and often introduces config drift.
Sizing a ksqlDB cluster can also be challenging. You must be able to calculate how much memory a cluster needs to handle the local state store requirements, considering both the overhead of the RocksDB service plus the workload itself. You’ll also need to set aside memory for the JVM heap while keeping sufficient memory available for the OS page cache. For CPU, there is a complex calculation requiring testing throughput on a single node, and then extrapolating CPU seconds across machines, however, this calculation changes based on the size of messages.
Further, you must also consider the added strain on Kafka itself, as well as the network throughput between Kafka and ksqlDB. All queries that ksqlDB runs add extra load onto Kafka, in addition to the extra write load of streaming tables and state change topics. All data that is processed by ksqlDB must traverse the network link between ksqlDB and Kafka, and so that link must also be capable of transferring data at the desired throughput while taking into account any other network traffic that may be using the same routing.
Lastly, consider that, in the case of a ksqlDB failure, any state must be retrieved from Kafka. For aggregations with significant state, this not only means a large amount of data will be consumed from a topic, but it can significantly delay service recovery. ksqlDB must consume all of the previous state changes from the change topic to recalculate the latest state, and only after this can the service resume. Any delay caused by the recovery of the state introduces further lag to the consumer, meaning that the actual ksqlDB workload falls further behind and must catch up.
Is your head spinning yet?
ksqlDB adds challenges when hiring
ksqlDB can undoubtedly lower the barrier to writing a stream processing application by abstracting the interface to SQL. But if the discussion above is any indicator, deploying and scaling those applications into production still requires deep knowledge of Kafka and the infrastructure requirements of ksqlDB.
It's impossible to run and scale ksqlDB without deep Kafka knowledge and expertise.
With ksqlDB, building new stream processing use cases isn’t as simple as just writing some SQL. You will need to have deep Kafka expertise on hand, which makes it harder to empower other users to work with ksqlDB.
And while SQL expertise is common, Kafka expertise is both harder to find and more expensive.
What is the future of ksqlDB?
As I mentioned above, ksqlDB was built and is maintained by Confluent. Interestingly, Confluent recently acquired Immerok, a managed Apache Flink service created by some of the original Flink team. Since the acquisition, Confluent has subtly positioned Flink as its future stream processing engine, giving it prominent placement across agendas in its global Kafka, Current, and Data In Motion events.
ksqlDB is entirely owned by Confluent. It is not part of the Apache Software Foundation like Kafka, and it uses the Confluent Community License. In the event that Confluent favors Flink for future stream processing use cases, ksqlDB might run the risk of becoming unmaintained by Confluent. If that happens, another commercial vendor cannot take its place.
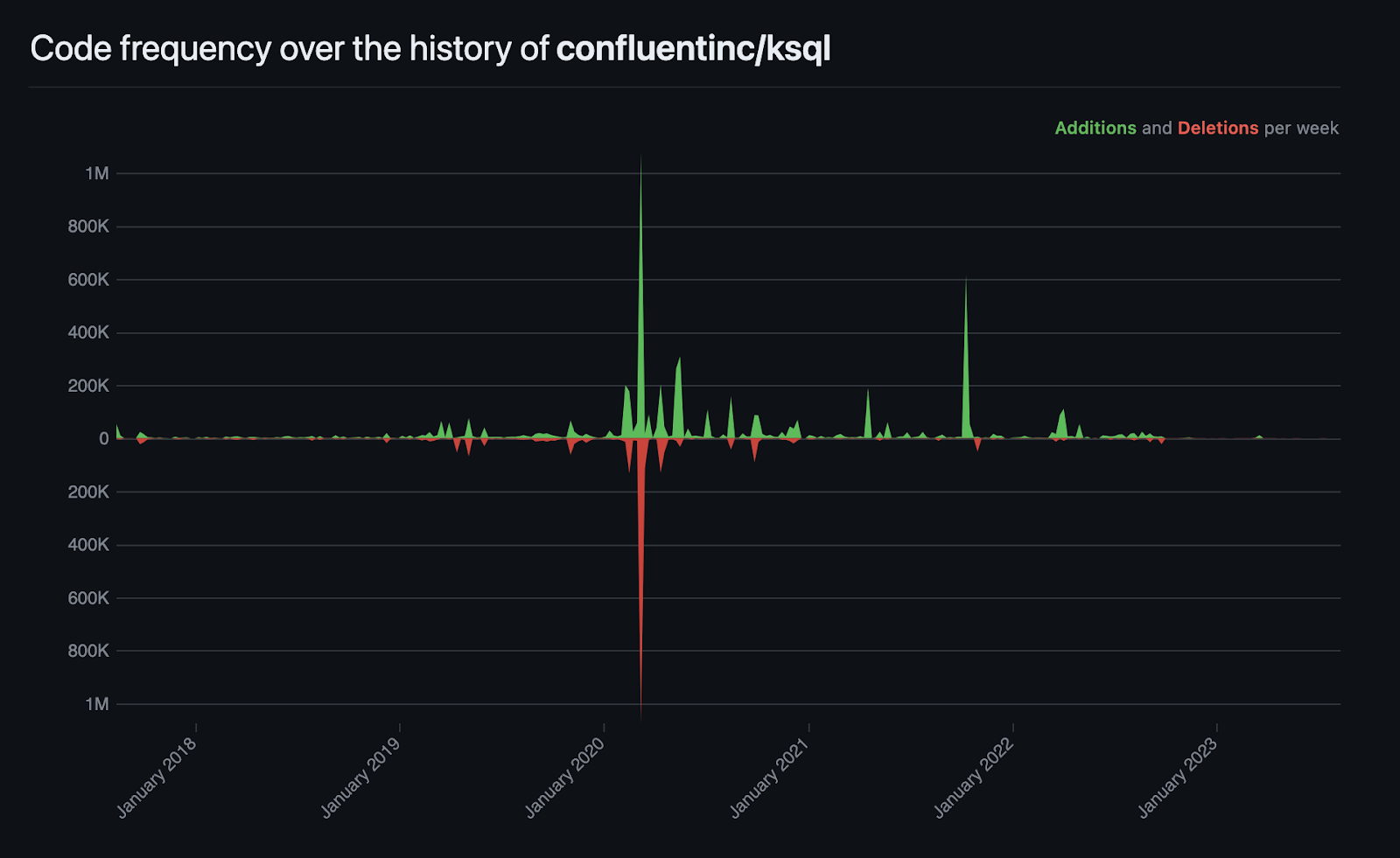
And though this may be speculative, consider that activity in the ksqlDB GitHub repo has already hit record lows. Before the acquisition, ksqlDB had up to 80 active contributors, mostly from Confluent employees. In 2023, there have been only 10 active contributors, with the lowest code change frequency the project has ever seen.
Update: December 2025
The streaming ecosystem around Kafka has shifted quite a bit in the last couple of years. Confluent has doubled down on Apache Flink with a fully managed Flink service in Confluent Cloud across AWS, GCP, and Azure, positioning Kafka plus Flink as a unified platform for real-time pipelines and next-generation applications. This reflects a broader trend toward cloud-native, serverless stream processing where you do not manage clusters yourself and can mix continuous processing with analytics on the same platform.
At the same time, SQL-first streaming engines and real-time databases like ClickHouse®, Tinybird, Materialize, and RisingWave are increasingly used to take streams from Kafka and turn them into low-latency analytics APIs instead of doing everything directly inside Kafka.
Within that context, ksqlDB sits in a slightly awkward middle ground. Community conversations frequently question its long-term future, pointing to its proprietary license, relatively small contributor base, and the fact that Confluent's strategic messaging is now centered around Flink. At the same time, some vendors and practitioners note that ksqlDB is still actively used and continues to receive updates, which makes it a reasonable choice for teams already invested in the Kafka ecosystem that need simple SQL transformations and small window aggregations without introducing another engine.
For new projects, however, many teams evaluate Flink or an external real-time analytics platform when they expect high-cardinality state, complex joins, or long retention, since these tools are better aligned with the industry shift toward OLAP-backed streaming analytics and AI-ready data products.
Given this risk, and the challenges presented above, it may be wise to consider a ksqlDB alternative. Tinybird is one such choice.
What is Tinybird?
Tinybird is a real-time data platform for data and engineering teams to develop highly-scalable real-time analytics APIs over streaming data.
Like ksqlDB, Tinybird abstracts the complexities of streaming data transformations with an ergonomic SQL query engine. Unlike ksqlDB, however, Tinybird's query engine isn't an abstraction, but rather a part of an integrated real-time database optimized for performing complex analytics and aggregations over streaming data maintaining any amount of state, small or large.
How Tinybird Addresses ksqlDB's Limitations
Tinybird can be used as an alternative to ksqlDB for stateful stream processing when state becomes very large. As Tinybird is built over an OLAP database, it is optimized for storing and accessing large amounts of state as a part of a streaming data architecture.
Tinybird is efficient at real-time analytics over unbounded time windows
Whereas ksqlDB struggles with state storage for complex aggregations, Tinybird has no such limitations.
Tinybird’s Materialized Views provide powerful functionality for managing state while processing streaming data in real time. With Materialized Views, transformations are defined in SQL just as they would be in ksqlDB, then persisted in state and updated as new events arrive. Like ksqlDB, Tinybird can maintain an incremental materialization that is updated as each event passes through the materialization query (think of this like ksqlDBs push queries) and also supports late arriving data. Unlike ksqlDB, Tinybird stores materialization state into a highly efficient, columnar database that is optimized for aggregations over unbounded time windows.
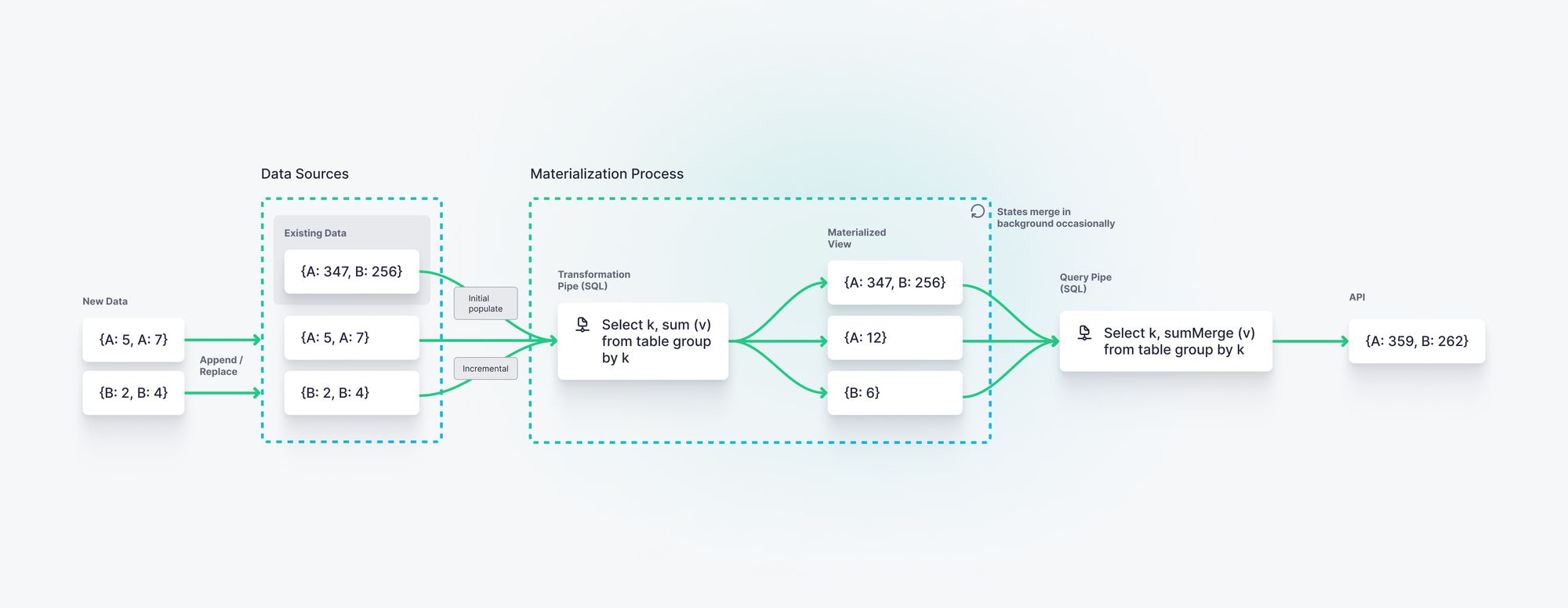
Materialized Views in Tinybird can calculate complex aggregations over hundreds of thousands of events per second, and store many billions of rows of state. Consider the example I shared above, where ksqlDB struggled to store 84,000 keys in state.
In Tinybird, this would translate simply to 84,000 rows held in a database table: one row per item per hour. Tinybird routinely stores and performs analytics over tens of billions of rows, with queries returning in milliseconds, so querying a state table of 84,000 rows would be considered a minuscule operation.
Tinybird routinely runs real-time aggregations over billions of rows. Operations that would saturate ksqlDB are trivial on Tinybird.
Critically, Materialized Views in Tinybird can process streaming data incrementally as it arrives, and the state can be used just like any other table to power any additional query, regardless of workload or use case. Use the state in ad hoc analyses, or in future materializations for comparison or additional aggregates.
Since the states are stored efficiently in a columnar database, these computations are significantly more efficient than those in ksqlDB. The effect is a query engine that can maintain orders of magnitude more state than ksqlDB while making it seem like you’re processing queries over much less, thanks to the efficient indexing and data skipping techniques.
Because of this, state for materializations can be stored at a much higher granularity, even “per minute” (or finer). The values can be re-aggregated at lower granularity as needed per use case.
Tinybird is optimized for analytics
Tinybird is a purpose-built platform for running real-time analytics, from the storage layer through to its query engine. Rather than relying on Kafka as the underlying storage layer, Tinybird includes a highly-optimized columnar storage engine in ClickHouse®.
Unlike ksqlDB, which utilizes Kafka for storage and stores data in the order it is generated, Tinybird can sort data by one or more keys. This offers better performance and more flexibility. Data in Tinybird can be ordered by any condition that makes sense for the kind of queries that will read the data.
For example, if you wanted to calculate the revenue generated by a particular item, your query would look something like this:
If your raw data table were indexed by timestamp, this query would require a full table scan. Tinybird fortunately makes it trivial to create new tables with optimized sorting keys. Instead of using timestamp as a primary key, you could instead index by a tuple of (item_id, timestamp). In this case, data would be first ordered by item_id, and then by timestamp.
With this key, all of a single item’s events are stored sequentially on disk. To calculate this sum, Tinybird would scan only the data where item_id = 123 and only the price column. The query could be further optimized if filtered by timestamp, for instance, if you wanted the revenue for a particular item from a certain time range.
Tinybird leverages ClickHouse®'s data skipping indexes, which massively reduce read operations for aggregations.
These optimizations are not possible with ksqlDB, but they are standard practice in Tinybird, and they are not only critical for better performance but also for reducing costs. The more rows you scan, the more time the query takes. The more time a query takes, the more hardware you need to be able to keep performance high (for an individual query, but also because a cluster is not only handling just one query). In Tinybird, you might return a query over millions of rows in less than a millisecond, whereas with ksqlDB it could take minutes, with disastrous effects on performance, cost, or both.
Tinybird places no added load on Kafka
Tinybird consumes data from Kafka and writes it into local storage in ClickHouse®. This storage is optimized for millisecond latency analytics, and supports incrementally updating, “push-style” materialized views and “pull-style” ad-hoc queries.
Tinybird is just one additional consumer to a Kafka topic, placing zero added overhead on your Kafka cluster.
Queries in Tinybird run over this storage, and no longer depend on Kafka. Tinybird is simply one additional consumer to your Kafka cluster, and Kafka is only used to feed Tinybird with fresh data as it arrives. Tinybird reads from Kafka in real time and new events are available for query within seconds. Tinybird never writes back to Kafka and places zero additional overhead on your Kafka cluster.
Tinybird minimizes operational complexity
Tinybird is a managed, serverless real-time data platform, and it scales transparently to meet the demands of your use cases. With Tinybird you don’t need to set up, manage, or maintain any hardware or install any software on existing machines. You don’t have to worry about planning capacity or sizing calculations, so there is no need to try and calculate how many machines, or how much CPU, memory, and disk is needed for your use case. With Tinybird, data and engineering teams can focus entirely on building use cases, trusting Tinybird to scale up and down on demand.
Furthermore, Tinybird’s costs align with use cases in production. Pricing is largely influenced by the amount of data processed by published APIs (those called by user-facing applications). Furthermore, exploratory queries are free, so prototyping carries a much smaller price tag.
Tinybird eases resource concerns
As a true database, Tinybird can be used by data engineers, software engineers, and analysts alike. Since it is entirely decoupled from Kafka, Tinybird users can build real-time data pipelines without understanding any of the Kafka semantics.
Like ksqlDB, Tinybird’s core interface for data processing is SQL. Unlike ksqlDB, the platform is designed around a database, with SQL as the primary query language. It’s not an abstraction over Kafka Streams but is optimized for SQL users regardless of their familiarity with lower-level Kafka concepts.
Since it is decoupled from Kafka, scaling with Tinybird required no additional expertise beyond SQL.
As such, hiring engineers to work with Tinybird is much easier than doing so with ksqlDB, since the demand for Kafka expertise will not grow as you work with Tinybird.
Conclusion and further reading
To summarize, the pros and cons of ksqlDB are:
Pros
- Easy to use compared to Kafka Streams
- Capable of real-time data processing transformations
- Good for routing, filtering, and small-windowed aggregations over low-cardinality fields
- Tightly integrated with the Kafka ecosystem
Cons
- Not suitable for complex aggregations over unbounded time windows
- Inefficient storage of state
- Added load to Kafka cluster
- Scaling demands Kafka expertise
- Potential obsolescence
Tinybird addresses many of these drawbacks by providing a real-time analytics engine built over a real-time database. Like ksqlDB, Tinybird can handle real-time data processing at scale, but it expands upon ksqlDB’s abilities by offering stateful stream processing over unbounded time windows and wide tables with high-cardinality fields.
For more information on ksqlDB, check out these resources:
- ksqlDB GitHub Repository
- ksqlDB Documentation
- ksqlDB Architecture
- ksqlDB Capacity Planning Guide
- Why I recommend my clients NOT use ksqlDB and Kafka Streams - Jesse Anderson
For further reading on Tinybird and all things real-time data, check out the following resources:
- Tinybird Website
- Tinybird Documentation
- Tinybird Kafka Connector Docs
- Real-time Analytics: A Definitive Guide
- Real-time Databases: What Developers Need to Know
- Real-time Streaming Data Architectures that Scale
- When to Use Columnar Databases
- What are Materialized Views (and why do they matter for real time)?
Try Tinybird
Interested in trying Tinybird as an alternative to ksqlDB? Check out Tinybird’s pricing, sign up for free, or connect with our team for more info.