Data Platform

Plug in your data,
ship in minutes
Queryable in seconds, fully managed, and built for scale.
$ ❯ curl -X POST 'https://api.tinybird.co/v0/events?name=my_datasource' \ -H "Authorization: Bearer $TB_TOKEN" \ -d '{"timestamp":"2026-01-01","event":"click","value":42}'
Want to use your favourite language? TypeScript and Python SDKs let you define your Tinybird resources as code.
From source to query in seconds
Real Ingestion Use Cases
Millions of events per second,
zero infrastructure to manage
ingests petabytes of data with sub-second latency.
ingested
ingested
latency
“Our devs evaluated Pinot, Druid and Tinybird. They preferred Tinybird for performance, reliability, integrations, and developer experience.”

Damian Grech
Director of Engineering, Data Platform at FanDuel

Why Tinybird
Stop building
ingestion pipelines
ingestion-plan.md
# DIY Ingestion Pipeline
23
Data in ClickHouse
4Real-time queries
5- Build and maintain HTTP ingestion service6- Deploy and manage Kafka consumers7- Write S3/GCS polling and file parsers8- Implement retry logic and deduplication9- Handle schema changes manually10- Build monitoring for every connector11- Days to weeks to production# Tinybird
23
Data in ClickHouse
4Real-time queries
5+ Events API: JSON over HTTP, sub-second6+ Managed Kafka, S3, GCS, and database connectors7+ Auto schema detection and evolution8+ Built-in retries, dedup, and quarantine9+ Full observability on every source10+ Sinks: export to S3, GCS, Kafka11+ Minutes to production
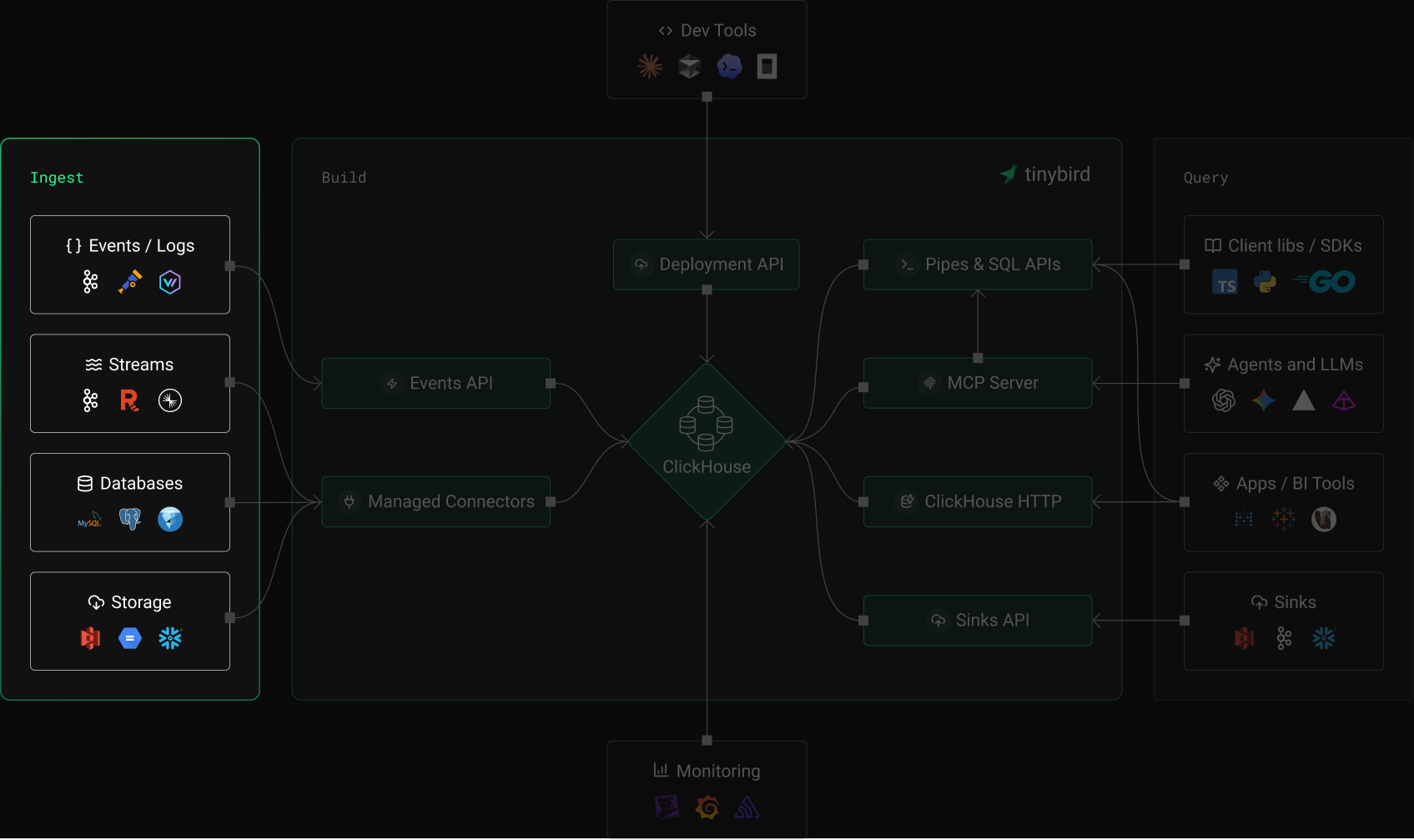
Built for scale
The ingestion layer
you don't have to build
Events API
- JSON/NDJSON over HTTP at any scale
- Sub-4 second query availability
- Gzip compression supported
Kafka connector
- Fully managed, auto-scaling consumers
- Schema Registry and Avro support
- Confluent, MSK, Redpanda, Azure Event Hubs
Object storage and databases
- S3 and GCS with CSV, NDJSON, Parquet
- PostgreSQL, MySQL, and Apache Iceberg via table functions
- Auto, on-demand, or scheduled ingestion modes
Reliability and correctness
- Idempotent ingestion with hash dedup
- Quarantine for malformed data
- Buffering, compaction, and backpressure
Developer experience
- CLI: tb datasource, tb connection, tb dev
- TypeScript SDK and Python SDK
- Local development, branches, CI/CD
Observability
- Ingestion metrics and error logs
- Quarantine inspection and replay
- Grafana and Prometheus integration
Get started
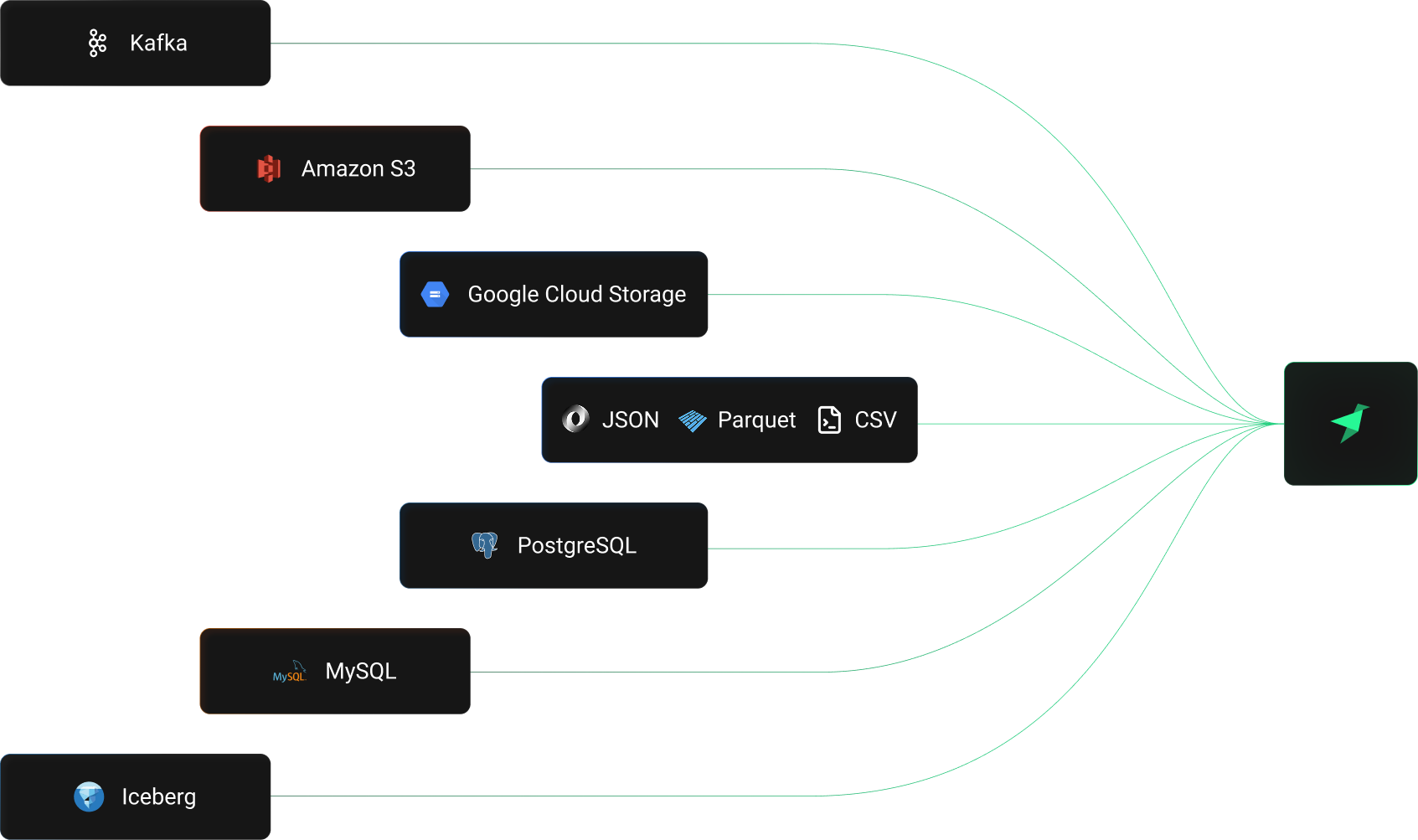
Connect anything
in minutes
FAQs
What ingestion methods does Tinybird support?
Tinybird supports multiple ingestion methods: the Events API for JSON/NDJSON over HTTP, a fully managed Kafka connector for streaming data, S3 and GCS connectors for batch imports, local or remote file uploads via the CLI, and table functions to read from PostgreSQL, MySQL, and Apache Iceberg. There are also step-by-step guides for 25+ sources including Snowflake, BigQuery, MongoDB, Stripe, Auth0, OpenTelemetry, Vercel, GitHub, and more.
How fast is data available for queries after ingestion?
Data ingested via the Events API is available for queries in under 4 seconds. Kafka connector latency depends on your topic throughput but typically achieves sub-second flushing. S3 and GCS connectors support automatic or on-demand ingestion modes.
Is ingestion fully managed or do I need to run infrastructure?
All ingestion is fully managed. You don't deploy, scale, or maintain anything. Tinybird handles consumer autoscaling for Kafka, buffering and compaction for the Events API, and polling for object storage connectors. You provide credentials and configuration; Tinybird handles everything else.
How does Tinybird handle ingestion failures and retries?
Tinybird provides multiple reliability mechanisms. The Events API supports idempotent ingestion with a 5-hour retry window using data hashes to prevent duplicates. The Kafka connector uses a quarantine system (dead letter queue) for messages that fail schema validation, preserving the original message plus error details. All connectors include built-in retries and ingestion protection mechanisms.
What data formats are supported?
The Events API accepts JSON and NDJSON with optional Gzip compression. The Kafka connector supports JSON and Avro (with Schema Registry). S3 and GCS connectors support CSV, NDJSON, and Parquet with multiple compression formats including Gzip, Snappy, LZ4, Zstd, and Brotli. Local and remote file uploads support CSV, NDJSON, and Parquet.
How do I handle schema changes in my data?
Use the FORWARD_QUERY instruction in your .datasource file to define how existing data transforms to your new schema. Tinybird applies schema changes with zero downtime during deployment. The Kafka connector supports Schema Registry for decoding evolving Avro schemas.
Can I also export data from Tinybird?
Yes. Tinybird Sinks let you export processed data to S3, GCS, and Kafka. This enables flexible data distribution: you can build complete data circulation loops where data flows in from one source, gets transformed with SQL, and flows out to another destination.
How is ingestion priced?
Tinybird offers plan-based pricing with Free, Developer, SaaS, and Enterprise tiers. Each plan includes vCPU and storage allocations. All ingestion methods — Events API, Kafka, S3, GCS, and file uploads — are included in every plan with no per-connector fees. The Developer plan starts at $25/month. Visit our pricing for full details.
Can I define my ingestion flows in TypeScript or Python?
Yes. The Tinybird TypeScript SDK and Python SDK let you define data sources, connections, pipes, and endpoints as code with full type inference. You can define your entire ingestion pipeline programmatically and deploy it with the CLI.
Do I need separate configuration for different environments?
No. Tinybird supports environment branching with isolated configuration for development, staging, and production. Secrets, connection credentials, and consumer group IDs are scoped per environment. Use tb dev for local development and deploy to production with CI/CD.
How does the Kafka connector compare to building my own?
Tinybird's Kafka connector is fully managed with automatic consumer autoscaling, offset management, failure recovery, and high availability. Building your own requires deploying consumers, handling backpressure, managing offsets, and monitoring everything. For a detailed comparison, see the dedicated Kafka Connector page.

Start ingesting data in minutes
- Start with a quickstart guide
- Explore: All connectors and integrations
- Read: The perfect data ingestion API design
- Learn: How to export data with Sinks