


Imagine you’re building banking software, and you’ve been asked to figure out one of the most fundamental tasks in fintech: determining the current balance of every customer in your system. Traditionally, you might store the balance in a transactional database, a single source of truth, such that the current balance for each user is just an SQL query away. But what happens if that value gets accidentally (or nefariously) changed, and there’s no transaction history to back it up?
There is another way, one that adds flexibility, traceability, repeatability, and scalability for large, distributed systems. This approach is called event sourcing, and it’s a powerful and reliable way to get an eventually consistent view of the current state of a system by analyzing and aggregating past events.
Event sourcing is a powerful and flexible way to arrive at an eventually consistent view of state while retaining event histories.
In this blog post, you’ll learn how to implement event sourcing with Kafka and Tinybird, using Kafka’s event logs to track and replay events and Tinybird to calculate and store state snapshots to arrive at an eventually consistent state for your system.
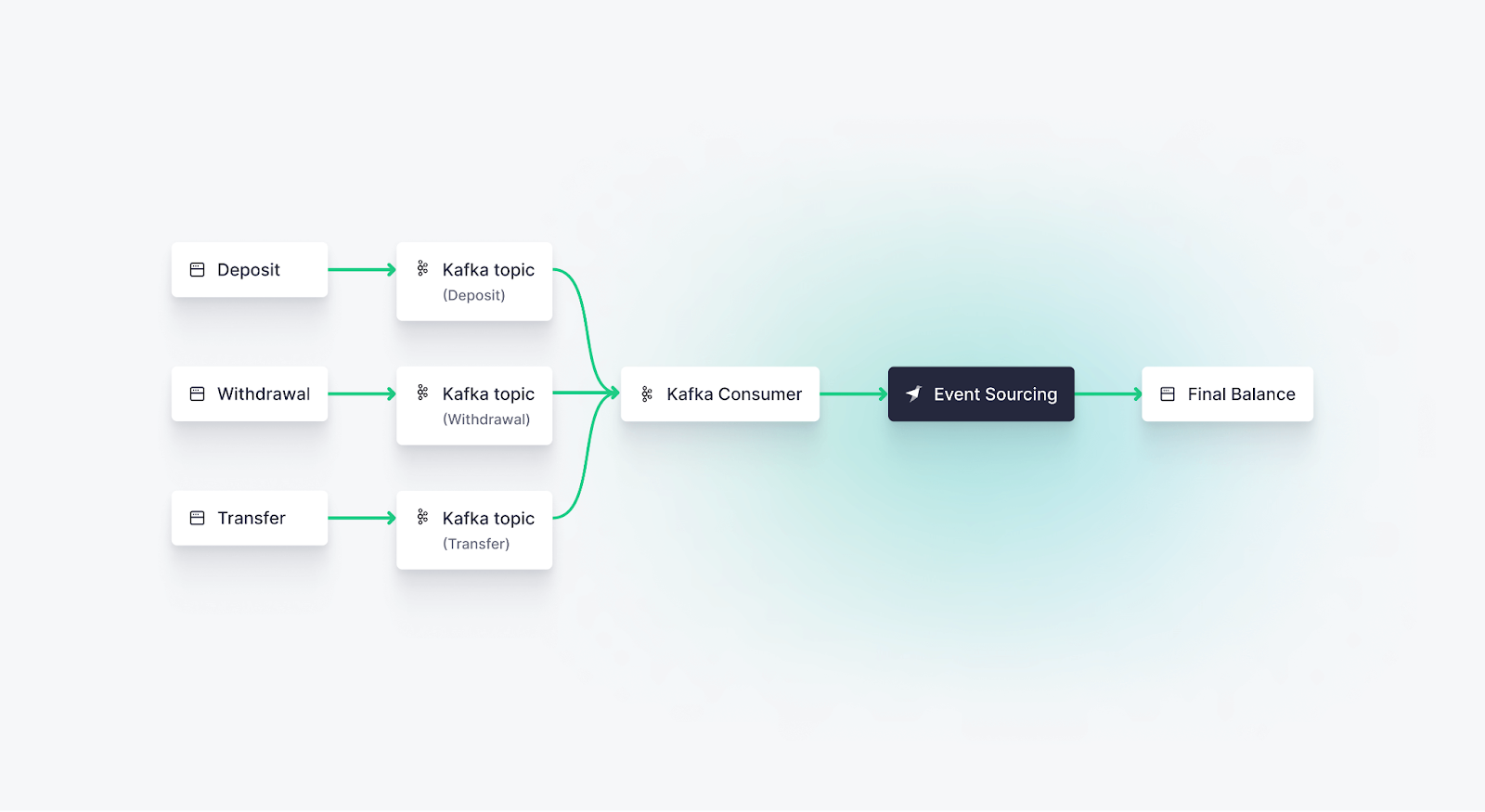
Along the way, you’ll get a better idea of what event sourcing is, why Kafka is so great for event sourcing, and how Tinybird supports snapshotting and real-time analytics over Kafka streams as a part of event-driven architectures. Let’s dig in.
What is event sourcing?
Event sourcing is a data design pattern in which the state of an application is determined by a sequence of events. Instead of explicitly storing the latest state of an entity, event sourcing reconstructs the current state by replaying a series of events.
Event sourcing changes the way you think about data
In a transactional world, you may think about entries in a database in terms of state. Columns like CurrentBalance and PendingTransactionAmount feel natural. In the world of event sourcing, that changes a bit.
Instead of data representing states, data represents state-changing events. These events are like dinosaur footprints forever fossilized in the sands of time; they're the unalterable objective facts that tell the story of our application or system, and how we got to the current state.
With event sourcing, we focus not on data that represents state, but data that represents state-changing events. We construct state from these events.
For instance, in our banking app, events like DepositAdded or WithdrawalMade don't just hold raw state - they capture actionable intent. This is immensely valuable for things like auditing, debugging, or understanding user behavior over time.
In event sourcing patterns, backtracking or adjusting state doesn’t involve erasing events. Instead, you simply add a new event to counteract the last. This is what we call a "compensation event”; it's a way to make amends without rewriting history, keeping the chronology intact.
Is event sourcing worth it?
As with all things, it depends. If you’re more comfortable with transactional databases and ACID properties, event sourcing might feel difficult. But, properly applied, event sourcing can be worth implementing when you’re dealing with large, distributed systems or microservices.
Specifically, event sourcing is beneficial for the following reasons
- Auditability and traceability: Since every change to the system is captured as a discrete event, it is much easier to trace how the system arrived at its current state, enabling in-depth auditing and analysis.
- Scalability and performance: By decoupling the write and read operations, event sourcing allows for better scalability and performance. This separation is often further optimized through Command Query Responsibility Segregation (CQRS), allowing read-heavy and write-heavy operations to be fine-tuned independently for maximum efficiency.
- Historical data analysis: With a complete history of events, it's possible to analyze past states and trends, enabling powerful analytics and insights.
- Replayability and debugging: The ability to replay events allows for debugging and reproducing issues, as well as testing new features or updates without affecting the live system.
- Event-driven architecture: Event sourcing naturally complements event-driven architectures, enabling applications to react to changes in real time and promoting loose coupling between components.
Event sourcing is valuable for its durability. If state gets corrupted, you can replay the event log to reconstruct it.
How does event sourcing scale?
You might be wondering how event sourcing scales when you want to calculate and retrieve state. Surely you wouldn’t fetch the entire event history from the beginning of time, as this would be highly computationally inefficient.
To scale with event sourcing, you use periodic snapshots that store state. Depending on the system and use case, these could be calculated every month or every minute. The important thing is that they reduce the amount of computation required when you want to fetch the up-to-the-millisecond current state.
Snapshots are critical for scaling event sourcing systems.
With snapshots, retrieving the current state becomes much simpler: You start with the snapshot and process all events since it was calculated, perfectly reconstructing state in a much more efficient manner.

Event sourcing with Kafka
Kafka is a perfect technology for event sourcing. Here's why:
- Distributed, durable, and scalable event log: Kafka's distributed architecture provides a highly scalable, fault-tolerant, and performant event log for storing and processing events. Kafka's topics and partitions enable horizontal scaling, ensuring that your system can handle the growing volume of events over time. Since event sourcing is quite useful for distributed systems, Kafka is a perfect fit.
- Real-time event streaming: Kafka excels at handling real-time data, making it an ideal choice for event-driven architectures. Producers can write events to Kafka as they occur, while consumers can react to these events in real time, facilitating seamless communication between components. Event sourcing relies on speedy and reliable event streaming to be able to produce a consistent state as quickly as possible.
- Data retention and durability: Kafka provides configurable data retention policies, allowing you to define how long events should be kept in an event store. This ensures that the event log remains accessible for historical analysis and debugging purposes. Additionally, Kafka's replication mechanisms ensure data durability and high availability.
- Strong consistency guarantees: Kafka guarantees that events are written in order and ensures that consumers read events in the order they were produced. This is crucial for maintaining the correct state with event sourcing, as the order of events determines the current state.
- Wide integration support: Kafka's popularity has created a large, vibrant ecosystem of integrations. Data platforms such as Tinybird have native support for consuming Kafka data, allowing you to perform complex event processing, aggregation, and transformation tasks, making it easier to derive insights and react to events in real time. For detailed examples of connecting Kafka to ClickHouse® for analytics, see our comprehensive integration guide.
Kafka is perfect for event sourcing thanks to its durable event log and strong consistency guarantees.
Best practices for implementing event sourcing with Kafka
Before diving into a practical example of implementing event sourcing with Kafka, it's crucial to set some ground rules. Best practices not only mitigate the complexities but also future-proof your architecture, ensuring seamless scalability and robustness. Whether you're a seasoned developer or just starting with event-driven architectures, the following guidelines offer valuable insights that could make the difference between a project’s success and failure.
- Schema Evolution: Always design your events with schema evolution in mind. Utilize schema registries and versioning to manage changes to your event schemas. This makes it possible to add or modify fields without breaking existing systems.
- Versioning: Implement event versioning from the start to ensure backward and forward compatibility as your application evolves. Utilize a schema registry or embed version numbers in event schemas to manage changes effectively. Always try to make backward-compatible changes. If not, use a different topic for non-backward compatible changes.
- Idempotence: Ensure that your system can handle the same or duplicated event multiple times without causing unwanted side effects. Kafka provides native support for idempotent producers, but you should also implement idempotence in your business logic.
- Event Ordering: Pay close attention to the order in which events are processed. Use Kafka partitions to ensure that events that affect the same entity are processed in the same partition and thus in order. When determining the order of events, try to use server-generated events whenever possible; client-generated timestamps are not often reliable.
- Compensation Events: Implement compensation events to undo the actions of a previous event. This can be valuable in failure scenarios or in handling business operations that are complex and conditional.
- Snapshots: For long event chains, utilize snapshots to reduce the overhead of replaying events. This is critical for maintaining system performance and ensuring real-time data analytics.
- Data Retention and Cleanup: Configure Kafka's data retention settings carefully to balance between data availability for replays and system performance. Too long retention periods can lead to unnecessary storage costs and reduced performance.
- Test, Test, Test: Before deploying, simulate different failure scenarios and verify that your system can recover and maintain data consistency. Automated tests, chaos engineering, and load testing are your friends here.
- Real-Time Analytics: Integrate your Kafka streams with real-time data platforms like Tinybird to gain immediate insights and act upon them. This is crucial for reactive, event-driven systems.
Challenges when using Kafka for event sourcing and real-time analytics
As with most things involving large-scale distributed systems, implementing event sourcing and real-time analytics on top of a streaming platform like Kafka can be difficult.
First, the sheer velocity and volume of event data can overwhelm systems not designed for real-time data processing. Arriving at eventual consistency when you’re streaming millions of events per second can be quite difficult.
Additionally, systems like ksqlDB (SQL) or Kafka Streams (Java/Python) that provide a layer of abstraction over the Kafka APIs offer stateful real-time transformation abilities, but they can struggle when state grows or when dealing with high-cardinality columns.
For teams working with fast-moving Kafka streams, it’s also essential to understand how event sourcing fits into the broader landscape of real-time data processing. This guide on [real-time data processing](https://www.tinybird.co/blog/real-time-data-processing) explores the core patterns and architectural choices that help systems reliably handle high-velocity event flows, transform them efficiently, and maintain correctness at scale.
For example, if you wanted to run real-time analytics over event streams, calculate state using a simple SQL interface, or run queries across multiple data sources, you’ll probably need to look beyond the native Kafka ecosystem. Apache Flink, an open source stream processing engine, can handle massive scale for stream processing but can also come with a steep learning curve.
Finally, we’re often talking about massive, distributed systems that need to support high-concurrency access at scale. Building these is always hard. Ensuring scalability and fault tolerance requires a careful orchestration of distributed systems, complicating the architecture further.
Tinybird is a real-time data platform that can simplify event sourcing with Kafka by providing a serverless, scalable infrastructure that keeps up with Kafka streaming. Tinybird leverages an online analytical processing (OLAP) real-time database, offering an intuitive, scalable SQL engine for both calculating state and running real-time analytics. Tinybird can consume events from Kafka in real-time, calculate and persist state into real-time materialized views, and serve real-time analytics as comfortable, interoperable APIs. For step-by-step examples of setting up Kafka-to-ClickHouse® pipelines, see our complete guide. In this way, it cuts back on the learning curve and reduces barriers to entry for implementing event sourcing with Kafka.
A practical example of event sourcing with Kafka and Tinybird
Below, I’ll walk you through a simple real-world example of event sourcing using Tinybird and Kafka, so that you can see how they work together to provide an eventually consistent representation of state.
Step 1: Kafka Topic Setup
First, set up a Kafka topic using a Kafka service. If you don’t want to self-host (and you probably don’t just for this tutorial), I would recommend Confluent Cloud, Redpanda, or Upstash.
For this example, we’re using a Kafka topic whose schema, which defines customer banking transactions, looks like this:
Step 2: Tinybird Kafka Connector
After setting up your Kafka topic, sign up for Tinybird (it’s free) and configure the Kafka Connector to consume the topic. We are saving our transaction data from Kafka into a table called transactions.
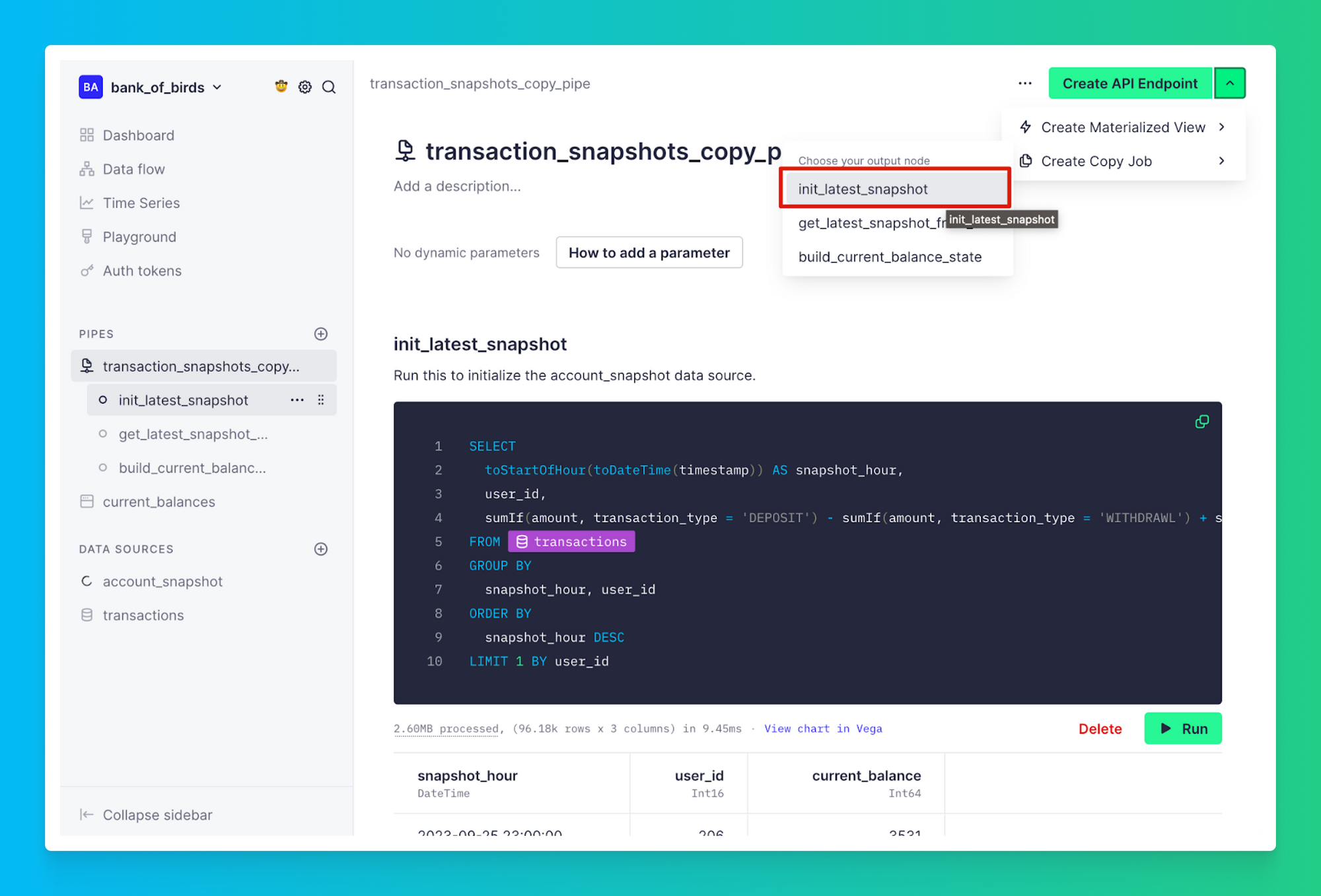
Step 3: Create a Copy Pipe to capture your first snapshot
Here you will use Copy Pipes to capture the result of an SQL transformation at a moment in time and write the result into a target Data Source. To create a Copy Pipe, you will first need to make a new Pipe in Tinybird called init_latest_snapshot and paste this SQL query.
This query:
- Calculates the current balance for each user based on deposits, withdrawals, and transfers up to the moment the snapshot was taken.
- Sorts the output by
snapshot_timestampin descending order and returns only one row peruser_idusingLIMIT 1 BY user_id.
After you run the query, confirm that you are happy with the data, and click the carot by the “Create API Endpoint” button, select the “Create Copy Job”, and choose the node we just created, init_latest_snapshot, to generate your first snapshot. For this demo, you can just select “On Demand”, but for future reference, you can also set up CRON jobs in Tinybird to manage copy jobs on a schedule.
Step 4: Create a Copy Pipe to calculate the user balance based on the last Account Snapshot
Now that you have the account_snapshot seeded with account balance data, you will create two more Pipe nodes to calculate the new account balance based on the previous account snapshot. This way, you won’t need to sum up all the events every time you create a new snapshot.
First, create a new node, get_latest_snapshot_from_account_snapshot that gets the latest snapshot from the account_snapshot Data Source:
Next, you can create another node, transactions_after_the_last_snapshot that finds all the transactions that occurred after the last snapshot was taken.
Next, you will write a final node that calculates the current balance for each user by starting with their last snapshot balance (or zero if not available) and adding deposits, subtracting withdrawals, and adding transfers from transactions that occurred after the last snapshot; it then groups and sorts the results by the timestamp and user ID, showing their latest balance. This new node is titled build_current_balance_state.
After you run the node, you can confirm that your final user balance is equal to the sum of all their balances with a quick check. You can then create a new Copy Pipe from this node. Click the caret by the “Create API Endpoint” button, select the “Create Copy Job”, and choose build_current_balance_state to generate the new snapshot.
Step 5: Publish your Pipe as an API
Now that you have all of your users' current balance state built up using event sourcing, you can publish an API Endpoint from this data so you can integrate it with other services, user applications, or admin dashboards.
In Tinybird, here's how to do that:
1. Duplicate your Copy Pipe: The logic you implemented in your Copy Pipe for building up the current balance of your users' accounts is sound, but in order to isolate services, you will need to duplicate it into a new Pipe. You can do this by clicking the ellipsis next to your Copy Pipe, selecting “Duplicate” and “Pipe".
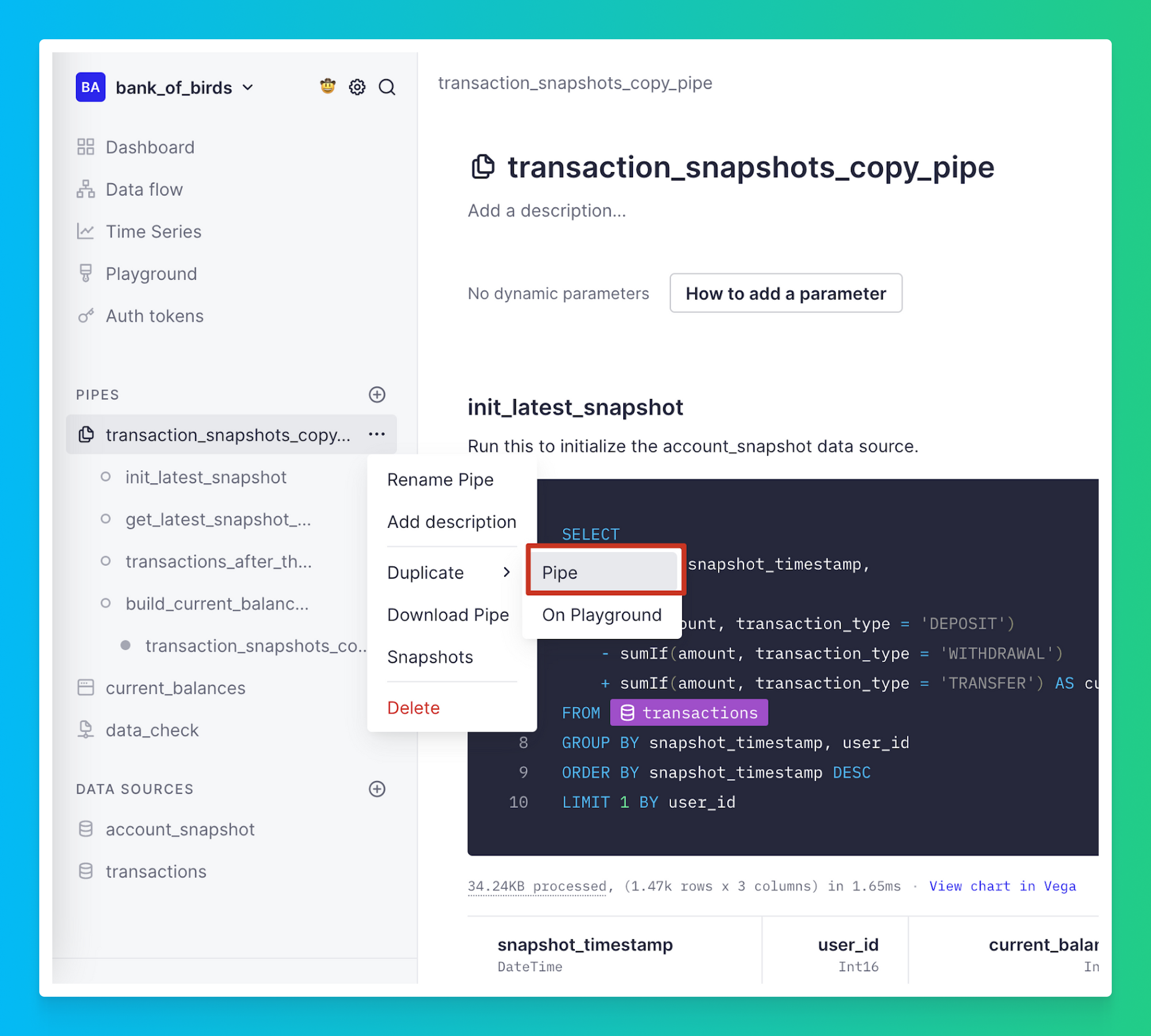
2. Rename: Rename the duplicated pipe to current_account_balance.
3. Create an API Endpoint: Click “Create API Endpoint,” and then select the node you want to publish. In this case, it’s build_current_balance_state.
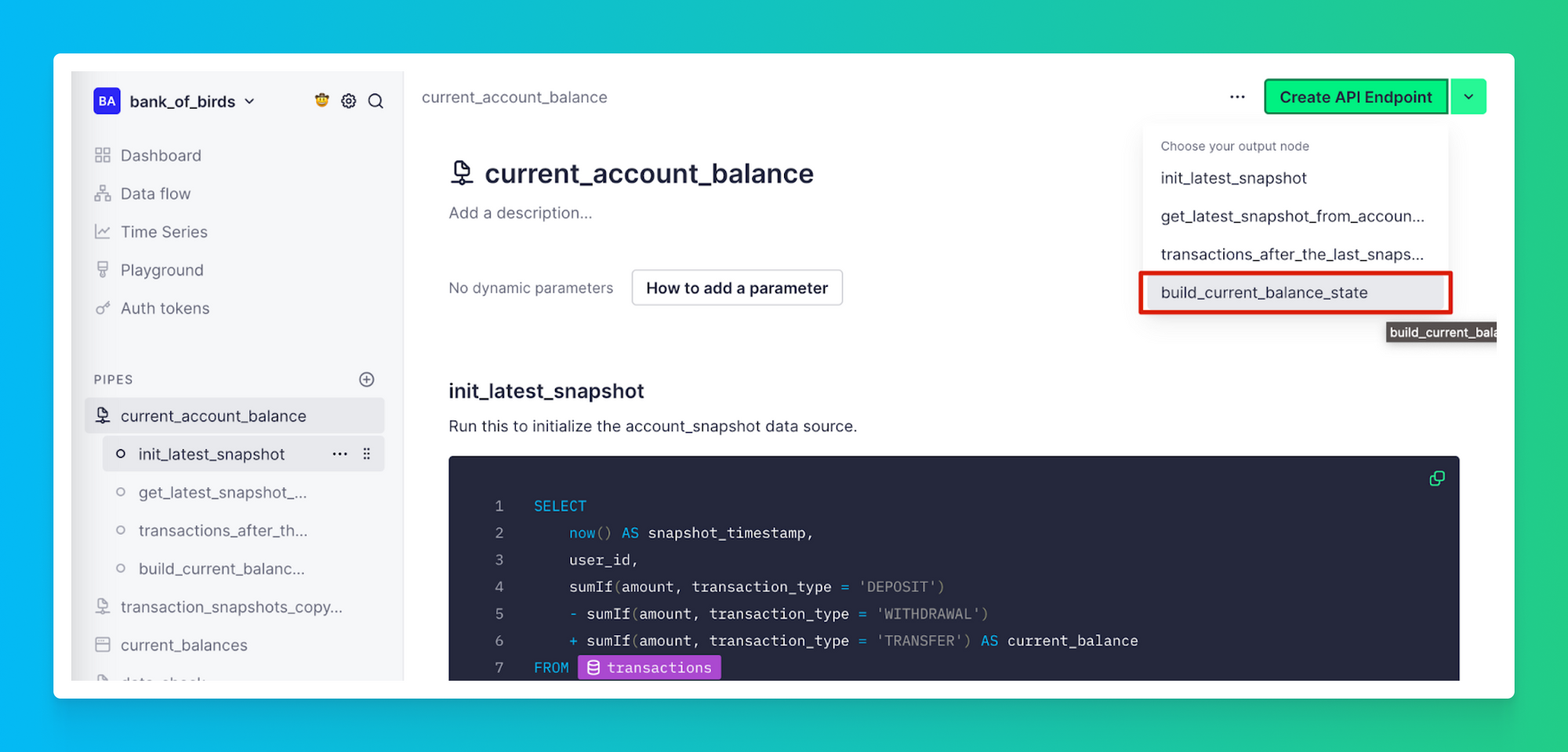
4. Test: Once your API Endpoint is published, you will be able to access your data with an HTTP GET request. Try pasting the sample API Endpoint (HTTP) into your browser, and you should be able to see all of your users' account balances as JSON. To learn more about building APIs in Tinybird, consult the docs.
Wrap up
Event sourcing with Kafka offers a robust and scalable solution for building real-time, event-driven architectures. Leveraging snapshotting and advanced analytics tools like Tinybird, you can handle large event logs efficiently while keeping system complexity in check. From enabling dynamic attribution models to ensuring data durability and eventual consistency, the techniques and best practices discussed in this post are key to mastering event sourcing in your applications.
If you’re new to Tinybird, give it a try. You can start for free on the Build Plan - which is more than enough for small projects and has no time limit - and use the Kafka Connector to quickly ingest data from your Kafka topics.
For more information about Tinybird and its integration with Kafka, use these resources:
- Tinybird Documentation
- Tinybird Kafka Connector
- Create REST APIs from Kafka streams in minutes
- Enriching Kafka streams for real-time analytics
FAQs
What is event sourcing?
Event sourcing is a design pattern that captures changes as events instead of storing the latest state, enabling advanced auditing, scalability, and system debugging.
Is Kafka a good tool for event sourcing?
Kafka serves as a highly scalable and reliable event log that can handle real-time event streaming, making it ideal for implementing event sourcing.
Why should I consider snapshotting?
Snapshotting provides a performance boost in event sourcing, minimizing the number of events that must be replayed and re-aggregated to arrive at a final current state. This reduces the computational load when the event log becomes large.
What is Tinybird and how does it relate to event sourcing?
Tinybird is a real-time data platform that simplifies the handling of event data, making it easier to implement event sourcing strategies.
How do I handle state-building in event sourcing?
You rebuild state by aggregating events from the log and applying business logic to them; Tinybird can simplify this by offering SQL-based Pipes for complex operations.
How complex is implementing event sourcing compared to a simple SQL query?
It's more complex due to the need to manage an event log and state rebuilding, but tools like Tinybird can significantly reduce this complexity. With Tinybird, you can use plain SQL to reconstruct state, which is often easier and more familiar than implementing use-case-specific event sourcing in Java with a tool like Kafka Streams, for example.
What is eventual consistency in the context of event sourcing?
Eventual consistency means that given no new events, all replicas of the state will eventually converge to the same value.
What are the best practices for versioning events?
Adopt a versioning strategy for your events to handle changes in schema or business logic, facilitating system evolution without breaking compatibility.
How can Tinybird help in attribution modeling?
Tinybird enables you to apply retroactive changes to your attribution model, thanks to its ability to replay and reprocess events easily.
Is data durability guaranteed with Kafka in an event sourcing system?
Yes, Kafka's built-in replication ensures high data durability and availability, crucial for long-term event storage.