Copy Pipes¶
Copy Pipes are an extension of Tinybird's Pipes. Copy Pipes allow you to capture the result of a Pipe at a moment in time, and write the result into a target Data Source. They can be run on a schedule, or executed on demand.
Copy Pipes are great for use cases like:
- Event-sourced snapshots, such as change data capture (CDC).
- Copy data from Tinybird to another location in Tinybird to experiment.
- De-duplicate with snapshots.
Copy Pipes should not be confused with Materialized Views. Materialized Views continuously re-evaluate a query as new events are inserted, while Copy Pipes create a single snapshot at a given point in time.
Best practices¶
A Copy Pipe executes the Pipe's query on each run to export the result. This means that the size of the copy operation is tied to the size of your data and the complexity of the Pipe's query. As Copy Pipes can run frequently, it's strongly recommended that you follow the best practices for faster SQL to optimize your queries, and understand the following best practices for optimizing your Copy Pipes.
1. Round datetime filters to your schedule¶
Queries in Copy Pipes should always have a time window filter that aligns with the execution schedule. For example, a Copy Pipe that runs once a day typically has a filter that filters for yesterday's data, and an hourly schedule usually means a filter to get results from the previous hour.
Remember that a Copy Pipe job is not guaranteed to run exactly at the scheduled time. If a Copy Pipe is scheduled to run at 16:00:00, the job could run at 16:00:01 or even 16:00:05. To account for a potential delay, round your time window filter to align with the schedule window.
For example, if your Copy Pipe is scheduled hourly, instead of writing:
SELECT *
FROM datasource
WHERE datetime >= now() - interval 1 hour
AND datetime < now()
You should use toStartOfHour() to round the time filter to the hour:
SELECT *
FROM datasource
WHERE datetime >= toStartOfHour(now()) - interval 1 hour
AND datetime < toStartOfHour(now())
Doing this means that, even if the Copy Pipe's execution is delayed (perhaps being triggered at 16:00:01, 17:00:30, and 18:0:002) you still maintain consistent copies of data regardless of the delay, with no gaps or overlaps.
2. Account for late data in your schedule¶
There are many reasons why you might have late-arriving data: system downtime in your message queues, network outages, or something else. These are largely unavoidable and will occur at some point in your streaming journey. You should account for potential delays ahead of time.
When using Copy Pipes, include some headroom in your schedule to allow for late data. How much headroom you give to your schedule is up to you, but some useful guidance is that you should consider the Service Level Agreements (SLAs) both up and downstream of Tinybird. For instance, if your streaming pipeline has 5 minute downtime SLAs, then most of your late data should be less than 5 minutes. Similarly, consider if you have any SLAs from data consumers who are expecting timely data in Tinybird.
If you schedule a Copy Pipe every 5 minutes (16:00, 16:05, 16:10...), there could be events with a timestamp of 15:59:59 that do not arrive in Tinybird until 16:00:01 (2 seconds late!). If the Copy Pipe executes at exactly 16:00:00, these events could be lost.
There are two ways to add headroom to your schedule:
Option 1: Delay the execution¶
The first option is to simply delay the schedule.
For example, if you want to create a Copy Pipe that creates 5 minute snapshots, you could delay the schedule by 1 minute, so that instead of running at 17:00, 17:05, 17:10, etc. it would instead run at 17:01, 17:06, 17:11.
To achieve this, you could use the cron expression 1-59/5 * * * *.
If you use this method, you must combine it with the advice from the first tip in this best practices guide to Round datetime filters to your schedule. For example:
SELECT *
FROM datasource
WHERE datetime >= toStartOfFiveMinutes(now()) - interval 5 minute
AND datetime < toStartOfFiveMinutes(now())
Option 2: Filter the result with headroom¶
Another strategy is to keep your schedule as desired (17:00, 17:05, 17:10, etc.) but apply a filter in the query to add some headroom.
For example, you can move the copy window by 15 seconds:
WITH (SELECT toStartOfFiveMinutes(now()) - interval 15 second) AS snapshot
SELECT snapshot, *
FROM datasource
WHERE timestamp >= snapshot - interval 5 minute
AND timestamp < snapshot
With this method, a Copy Pipe that executes at 17:00 will copy data from 16:54:45 to 16:59:45. At 17:05, it would copy data from 16:59:45 to 17:04:45, and so on.
It is worth noting that this can be confusing to data consumers who might notice that the data timestamps don't perfectly align with the schedule, so consider whether you'll need extra documentation.
3. Write a snapshot timestamp¶
There are many reasons why you might want to capture a snapshot timestamp, as it documents when a particular row was written. This helps you identify which execution of the Copy Pipe is responsible for which row, which is useful for debugging or auditing.
For example:
SELECT toStartOfHour(now()) as snapshot_id, *
FROM datasource
WHERE timestamp >= snapshot_id - interval 1 hour
AND timestamp < snapshot_id
In this example, you're adding a new column at the start of the result which contains the rounded timestamp of the execution time. By applying an alias to this column, you can re-use it in the query as your rounded datetime filter, saving you a bit of typing.
4. Use parameters in your Copy Pipe¶
Copy Pipes can be executed following a schedule or on-demand. All the previous best practices on this page are focused on scheduled executions.
But what happens if you want to use the same Copy Pipe to do a backfill? For example, you want to execute the Copy Pipe only on data from last year, to fill in a gap behind your fresh data.
To do this, you can parameterize the filters. When you run an on-demand Copy Pipe with parameters, you can modify the values of the parameters before execution. Scheduled Copy Pipes with parameters use the default value for any parameters. This means you can simply re-use the same Copy Pipe for your fresh, scheduled runs as well as any ad-hoc backfills.
The following example creates a Pipe with two Nodes that break up the Copy Pipe logic to be more readable.
The first Node is called date_params:
%
{% if defined(snapshot_id) %}
SELECT parseDateTimeBestEffort({{String(snapshot_id)}}) as snapshot_id,
snapshot_id - interval 5 minute as start
{% else %}
SELECT toStartOfFiveMinutes(now()) as snapshot_id,
snapshot_id - interval 5 minute as start
{% end %}
The date_params Node looks for a parameter called snapshot_id. If it encounters this parameter, it knows that this is an on-demand execution, because a scheduled Copy Pipe will not be passed any parameters by the scheduler. The scheduled execution of the Copy Pipe will create a time filter based on now(). An on-demand execution of the Copy Pipe will use this snapshot_id parameter to create a dynamic time filter. In both cases, the final result of this Node is a time filter called snapshot_id.
In the second Node:
SELECT (SELECT snapshot_id FROM date_params) as snapshot_id, *
FROM datasource
WHERE timestamp >= (SELECT start FROM date_params)
AND timestamp < snapshot_id
First, you select the result of the previous date_params Node, which is the snapshot_id time filter. You do not need to worry about whether this is a scheduled or on-demand execution at this point, as it has already been handled by the previous Node.
This also retrieves the other side of the time filter from the first Node with (SELECT start FROM date_params). This is not strictly needed but it's convenient so you don't have to write the - interval 5 minute in multiple places, making it easier to update in the future.
With this, the same Copy Pipe can perform both functions: being executed on a regular schedule to keep up with fresh data, and being executed on-demand when needed.
Configure a Copy Pipe (CLI)¶
To create a Copy Pipe from the CLI, you need to create a .pipe file. This file follows the same format as any other .pipe file, including defining Nodes that contain your SQL queries. In this file, define the queries that will filter and transform the data as needed. The final result of all queries should be the result that you want to write into a Data Source.
You must define which Node contains the final result. To do this, include the following parameters at the end of the Node:
TYPE COPY TARGET_DATASOURCE datasource_name COPY_SCHEDULE --(optional) a cron expression or @on-demand. If not defined, it would default to @on-demand. COPY_MODE append --(Optional) The strategy to ingest data for copy jobs. One of `append` or `replace`, if empty the default strategy is `append`.
There can be only one copy Node per Pipe, and no other outputs, such as Materialized Views or API Endpoints.
Copy Pipes can either be scheduled, or executed on-demand. This is configured using the COPY_SCHEDULE setting. To schedule a Copy Pipe, configure COPY_SCHEDULE with a cron expression. On-demand Copy Pipes are defined by configuring COPY_SCHEDULE with the value @on-demand.
Note that all schedules are executed in the UTC time zone. If you are configuring a schedule that runs at a specific time, be careful to consider that you will need to convert the desired time from your local time zone into UTC.
Here is an example of a Copy Pipe that is scheduled every hour and writes the results of a query into the sales_hour_copy Data Source:
NODE daily_sales
SQL >
%
SELECT toStartOfDay(starting_date) day, country, sum(sales) as total_sales
FROM teams
WHERE
day BETWEEN toStartOfDay(now()) - interval 1 day AND toStartOfDay(now())
and country = {{ String(country, ‘US’)}}
GROUP BY day, country
TYPE COPY
TARGET_DATASOURCE sales_hour_copy
COPY_SCHEDULE 0 * * * *
Before pushing the Copy Pipe to your Workspace, make sure that the target Data Source already exists and has a schema that matches the output of the query result. Data Sources will not be created automatically when a Copy Pipe runs.
If you push the target Data Source and the Copy Pipe at the same time, be sure to use the --push-deps option in the CLI.
Change Copy Pipe Token reference¶
Tinybird automatically creates a Token each time a scheduled copy is created, to read from the Pipe and copy the results. To change the Token strategy (for instance, to share the same one across each copy, rather than individual Tokens for each), update the Token reference in the .pipe datafile.
Execute Copy Pipes (CLI)¶
Copy Pipes can either be scheduled, or executed on-demand.
When a Copy Pipe is pushed with a schedule, it will automatically be executed as per the schedule you defined. If you need to pause the scheduler, you can run tb pipe copy pause [pipe_name], and use tb pipe copy resume [pipe_name] to resume.
Note that you cannot customize the values of dynamic parameters on a scheduled Copy Pipe. Any parameters will use their default values.
When a Copy Pipe is pushed without a schedule, using the @on-demand directive, you can run tb pipe copy run [pipe_name] to trigger the Copy Pipe as needed. You can pass parameter values to the Copy Pipe by using the param flag, e.g., --param key=value.
You can run tb job ls to see any running jobs, as well as any jobs that have finished during the last 48 hours.
If you remove a Copy Pipe from your Workspace, the schedule will automatically stop and no more copies will be executed.
Configure a Copy Pipe (UI)¶
To create a Copy Pipe from the UI, follow the process to create a standard Pipe. After writing your queries, select the Node that contains the final result, click the actions button to the left of the Node (see Mark 1 below). Then click Create Copy Job (see Mark 2 below).
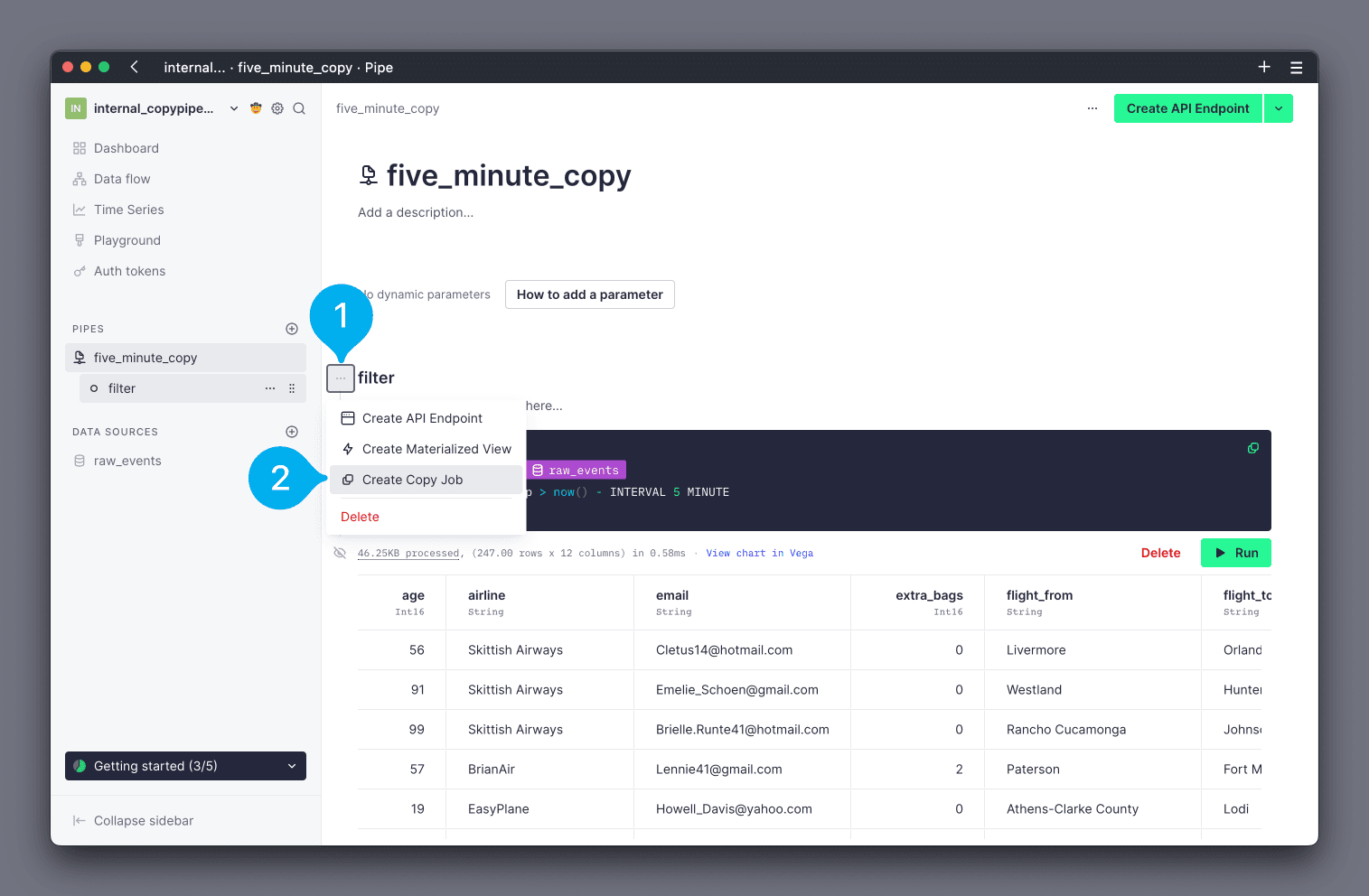
A dialogue window will open.
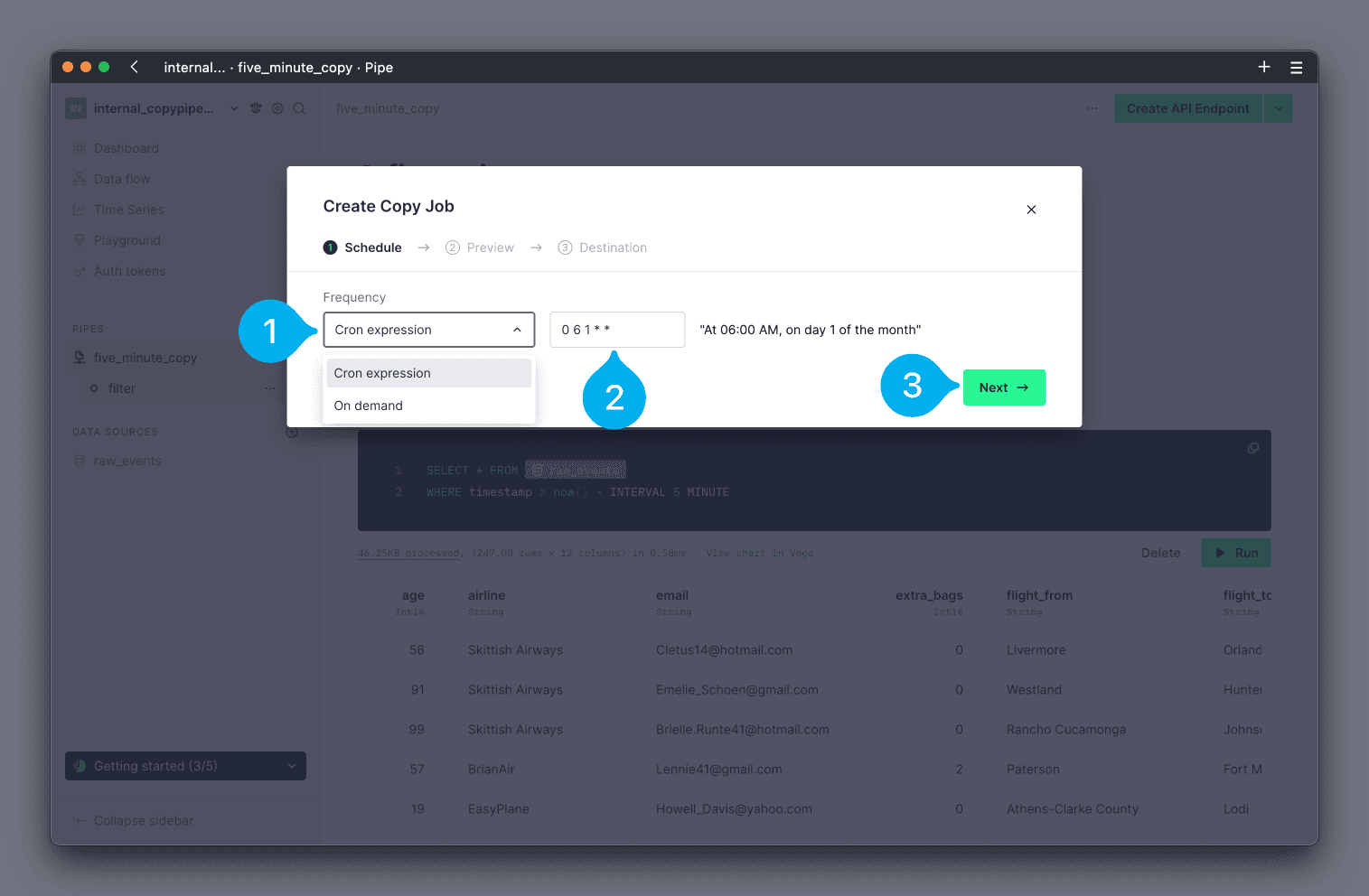
To configure the frequency, begin by selecting whether the Copy Pipe should be scheduled via a cron expression, or run on-demand, using the Frequency drop down menu (see Mark 1 below). If cron expression is selected, configure the cron expression in the text box (see Mark 2 below). If you are unfamiliar with cron expressions, tools like crontab guru can help. Click Next to continue (see Mark 3 below).
Note that all schedules are executed in the UTC time zone. If you are configuring a schedule that runs at a specific time, be careful to consider that you will need to convert the desired time from your local time zone into UTC.
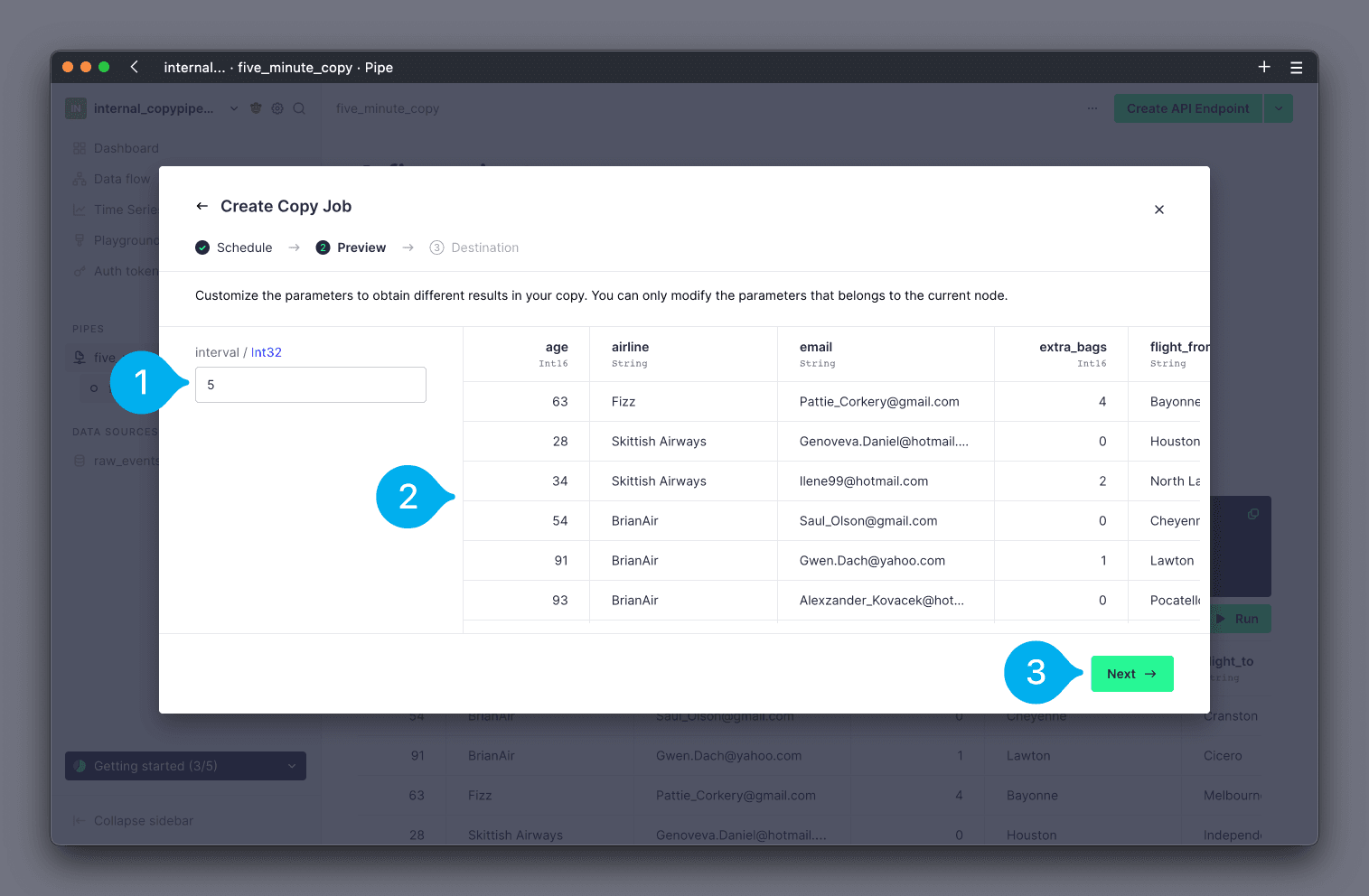
On-demand¶
If you selected on-demand as the frequency for the Copy Pipe, you can now customize the values for any parameters of the Pipe (if any). You can find any configurable parameters on the left hand side, with text boxes to configure their values (see Mark 1 below). On the right hand side, you will see a preview of the results (see Mark 2 below). Click Next to continue (see Mark 3 below).
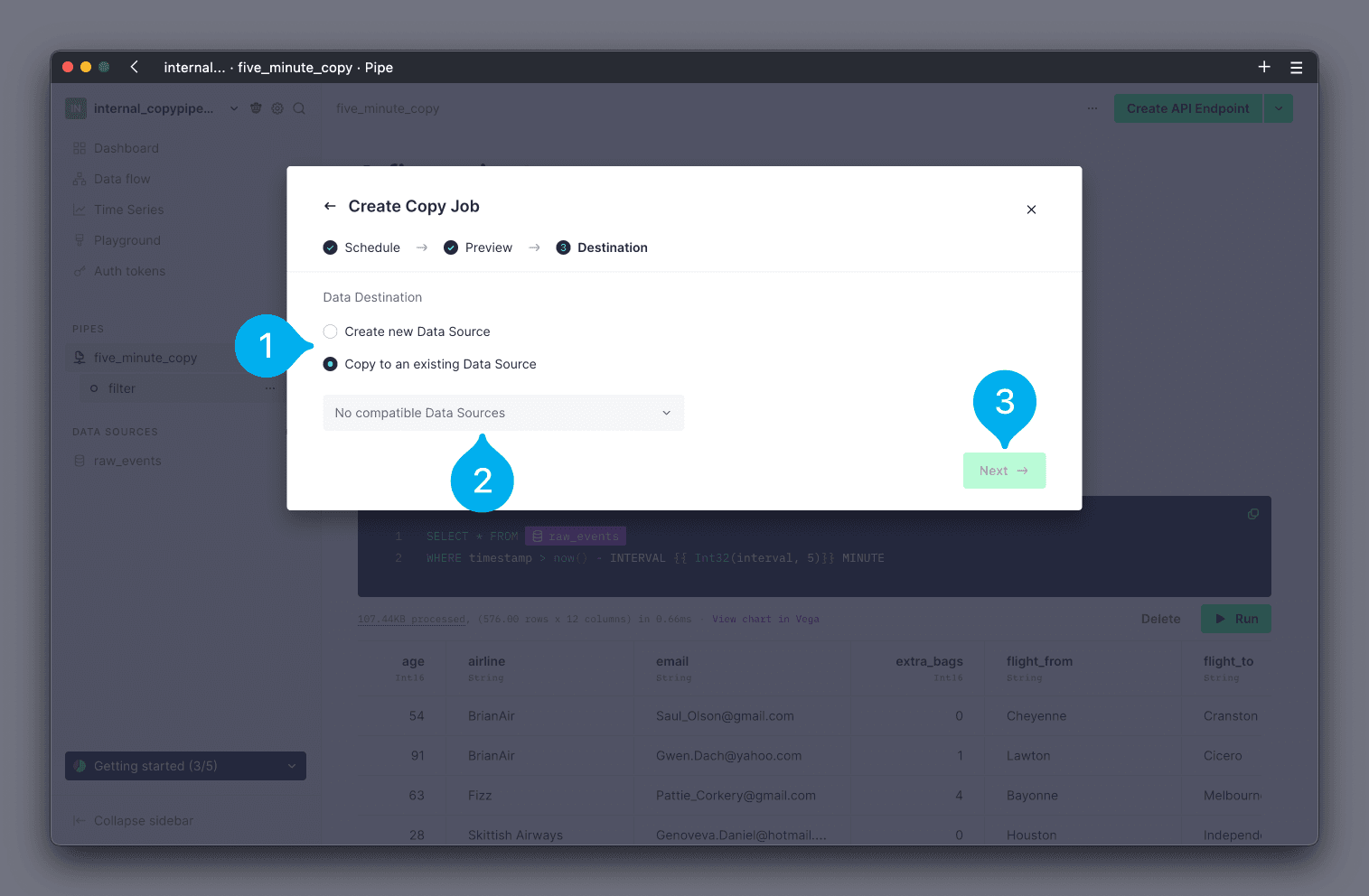
Finally, you can now configure whether the Copy Pipe should write results into a new, or existing, Data Source, using the radial buttons (see Mark 1 below). If you choose to use an existing Data Source, you can select which one to use from the drop down list of your Data Sources (see Mark 2 below). Note that only Data Sources with a compatible schema will be shown in the drop down. If you choose to create a new Data Source, you will be guided through creating the new Data Source. Click Next to continue (see Mark 3 below).
If you chose to create a new Data Source, you will now be taken through the standard Create Data Source wizard.
Scheduled¶
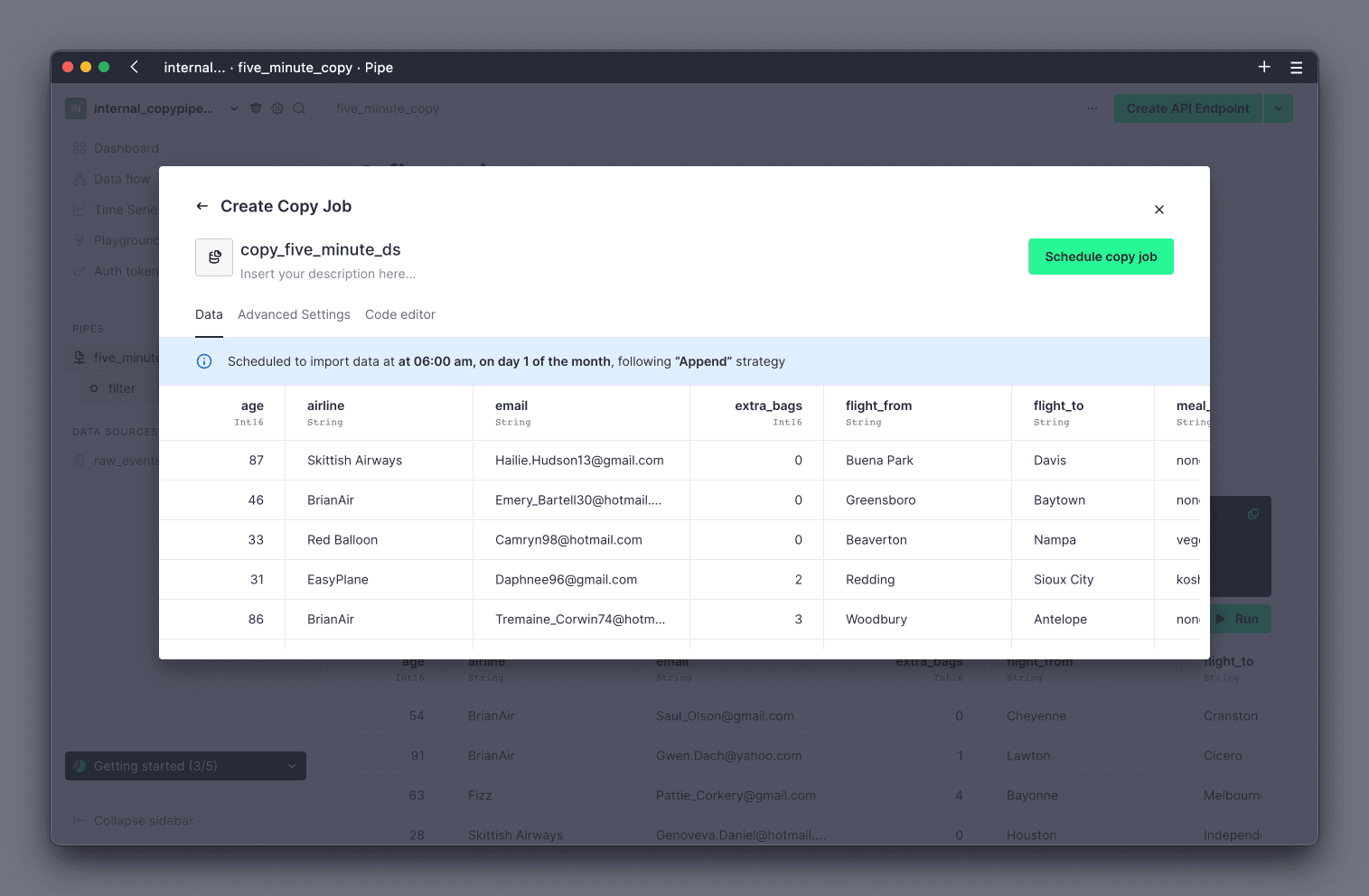
If you selected cron expression as the frequency for the Copy Pipe, you will be shown a preview of the result. You cannot configure parameter values for a scheduled Copy Pipe. Review the results and click Next to continue (see Mark 1 below).
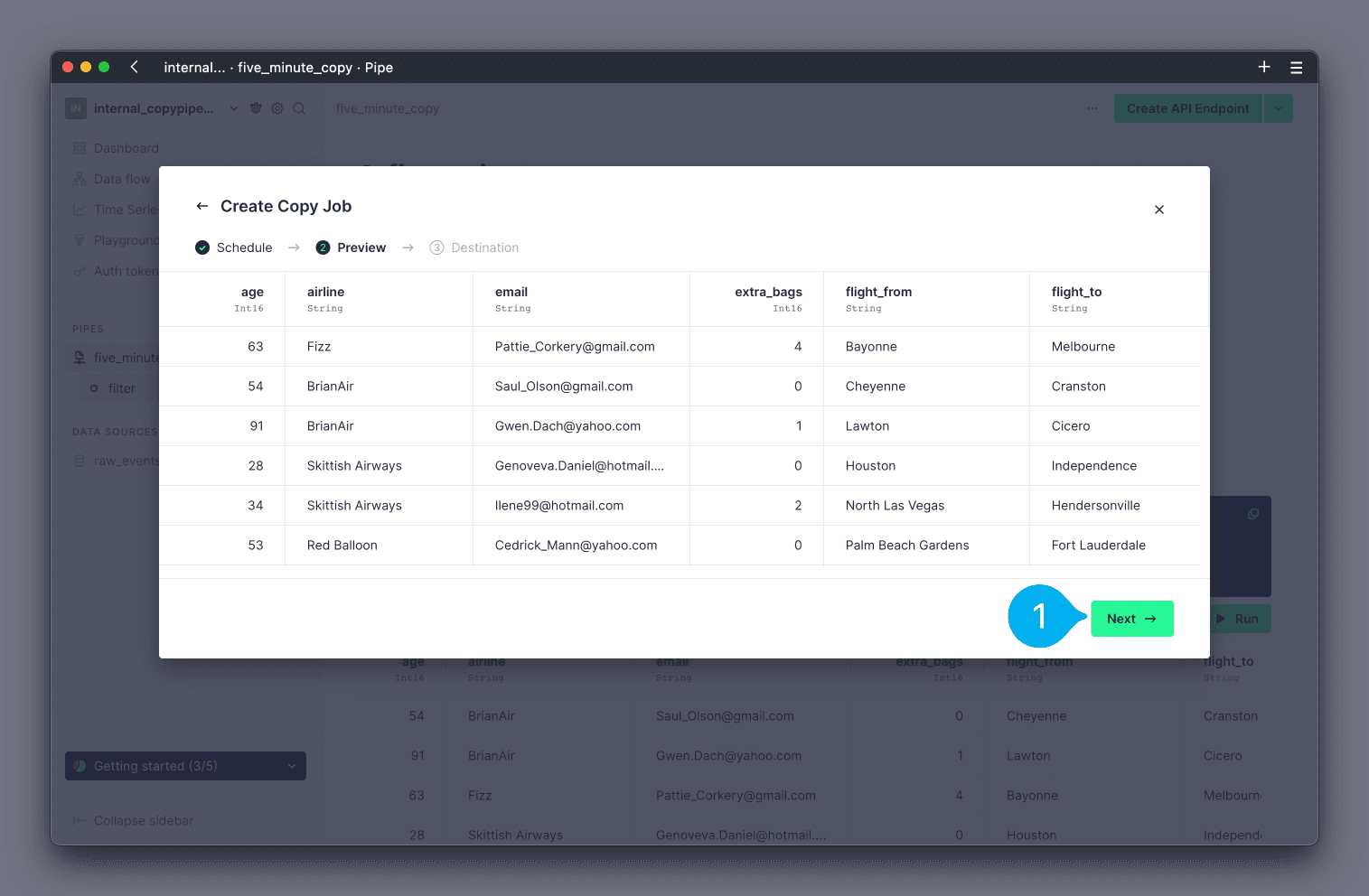
Finally, you can now configure whether the Copy Pipe should write results into a new, or existing, Data Source, using the radial buttons (see Mark 1 below). If you choose to use an existing Data Source, you can select which one to use from the drop down list of your Data Sources (see Mark 2 below). Note that only Data Sources with a compatible schema will be shown in the drop down. If you choose to create a new Data Source, you will be guided through creating the new Data Source. Click Next to continue (see Mark 3 below).
If you chose to create a new Data Source, you will now be taken through the standard Create Data Source wizard.
Execute Copy Pipes (UI)¶
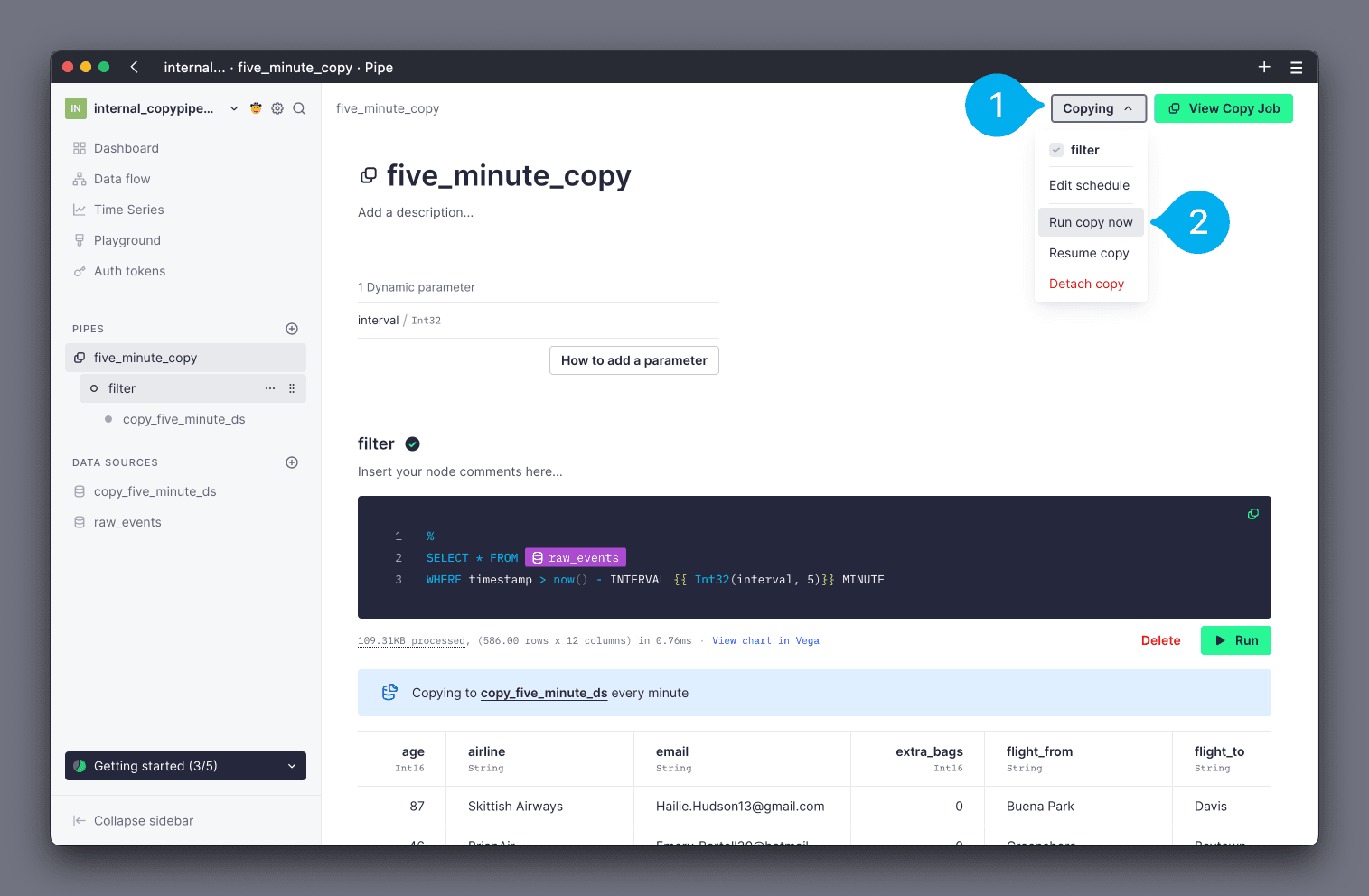
To execute a Copy Pipe in the UI, navigate to the Pipe, and click on the Copying button in the top right corner (see Mark 1 below). From the options, select Run copy now (see Mark 2 below).
Note that you cannot customize the values of dynamic parameters on a scheduled Copy Pipe. Any parameters will use their default values.
Iterating a Copy Pipe¶
Copy Pipes can be iterated using version control just like any other resource in your Data Project. However, you need to understand how connections work in Branches and deployments in order to select the appropriate strategy for your desired changes.
Branches don't execute on creation by default recurrent jobs, like the scheduled ones for Copy Pipes (they continue executing in your Workspace as usual).
To iterate a Copy Pipe, create a new one (or recreate the existing one) with the desired configuration. The new Copy Pipe will start executing from the Branch too (without affecting the unchanged production resource). This means you can test the changes without mixing the test resource with your production exports.
In this example, we explain how to change the Copy Pipe time granularity, adding an extra step for backfill the old data.
Monitoring¶
Tinybird provides a high level metrics page for each Copy Pipe in the UI, as well as exposing low level observability data via the Service Data Sources.
You can view high level status & statistics about your Copy Pipes in the TInybird UI from the Copy Pipe's details page. To access the details page, navigate to the Pipe, and click on the View Copy Job button in the top right corner (see Mark 1 below).
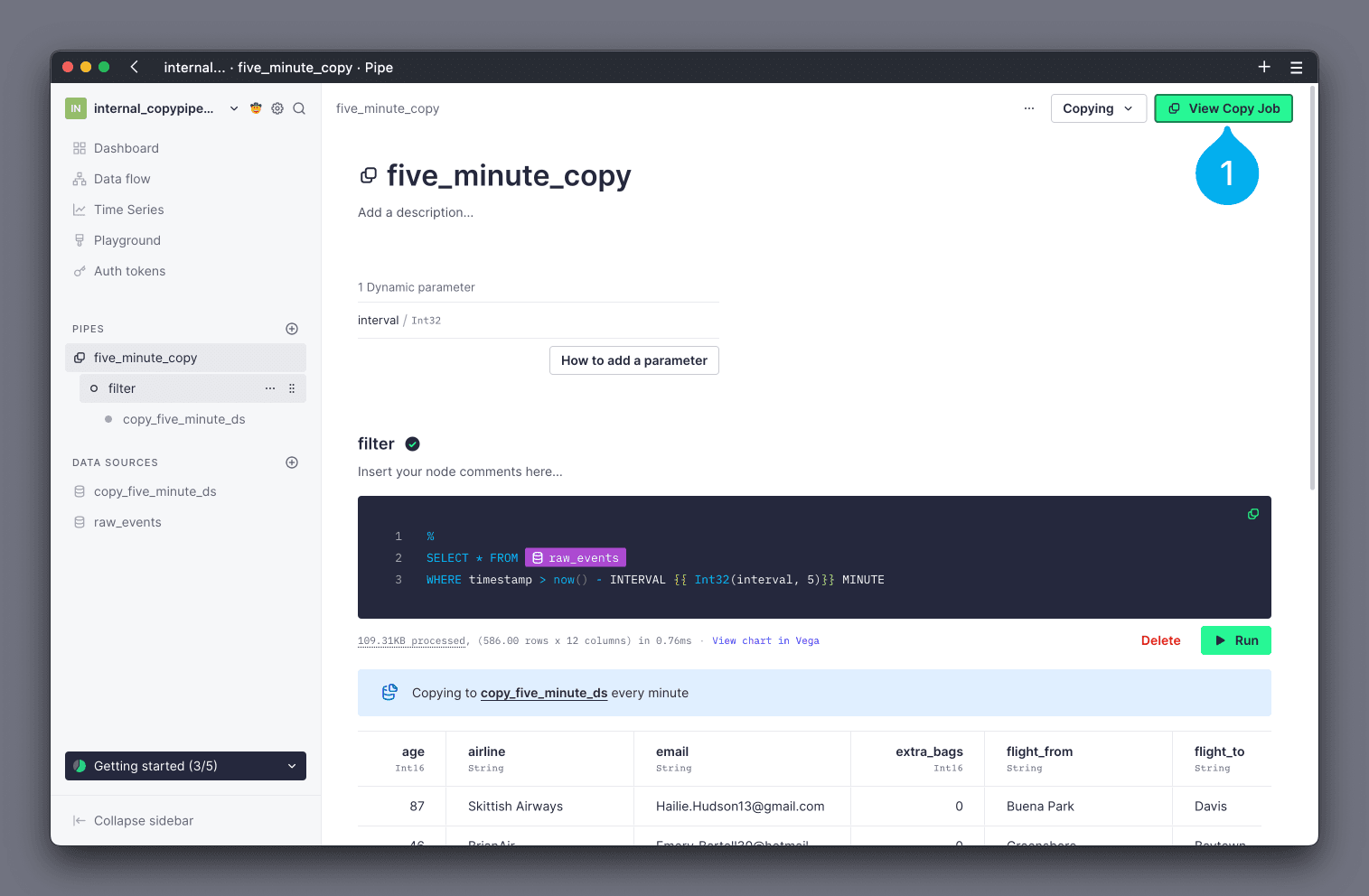
The details page shows summaries of the Copy Pipe's current status and configuration, as well charts showing the performance of previous executions.
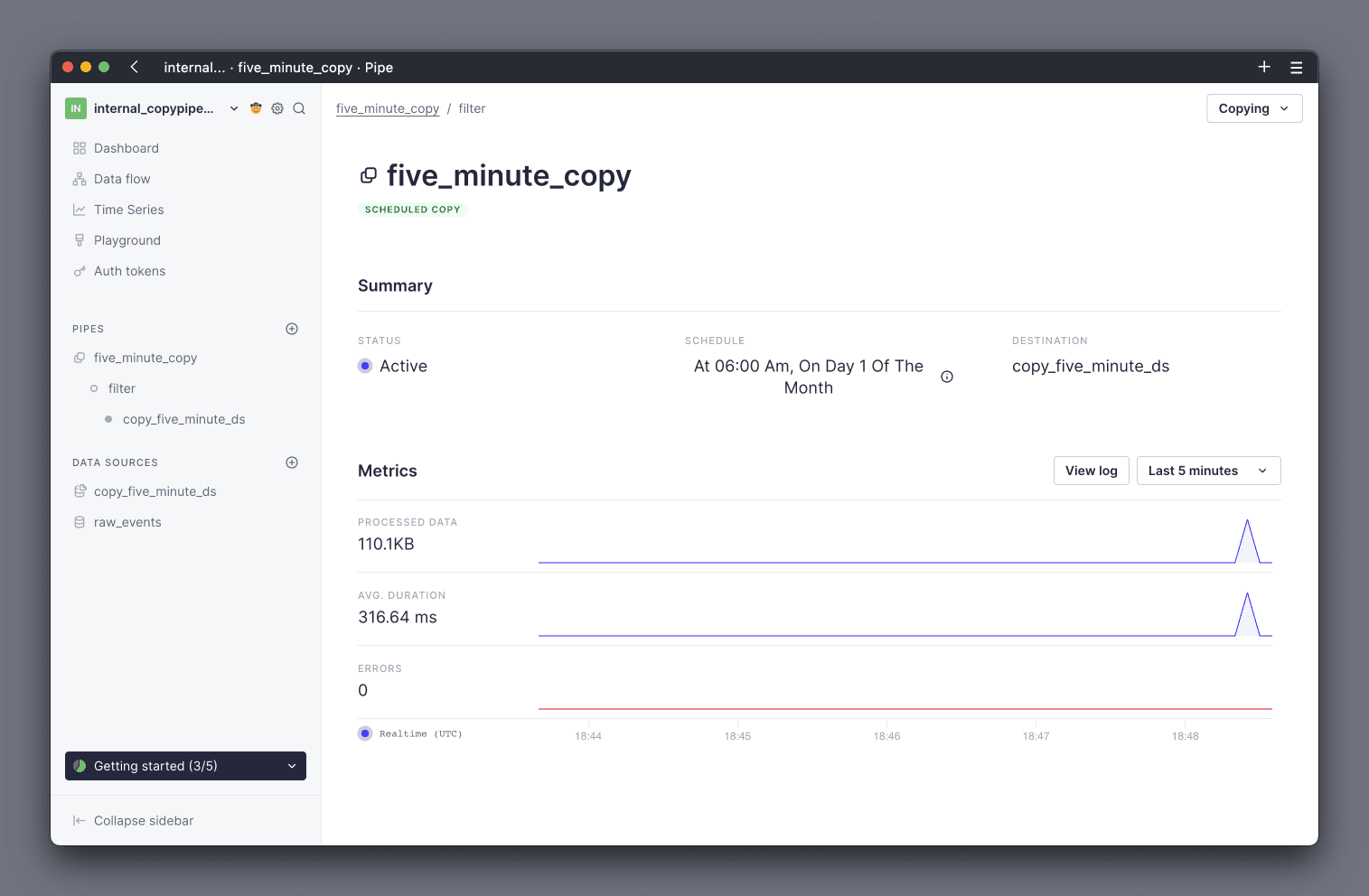
You can also monitor your Copy Pipes using the datasource_ops_log Service Data Source. This Data Source contains data about all of your operations in Tinybird. Logs that relate to Copy Pipes can be identified by a value of copy in the event_type column.
For example, the following query aggregates the Processed Data from Copy Pipes, for the current month, for a given Data Source name.
SELECT toStartOfMonth(timestamp) month, sum(read_bytes + written_bytes) processed_data
FROM tinybird.datasources_ops_log
WHERE datasource_name = '{YOUR_DATASOURCE_NAME}'
AND event_type = 'copy'
AND timestamp >= toStartOfMonth(now())
GROUP BY month
Using this Data Source, you can also write queries to determine average job duration, amount of errors, error messages, and more.
Billing¶
Processed Data and Storage are the two metrics that Tinybird uses for billing Copy Pipes. A Copy Pipe executes the Pipe's query (Processed Data) and writes the result into a Data Source (Storage).
Any processed data and storage incurred by a Copy Pipe is charged at the standard rate for your billing plan (see "Tinybird plans").
See the Monitoring section for guidance on monitoring your usage of Copy Pipes.
Limits¶
Check the limits page for limits on ingestion, queries, API Endpoints, and more.
Build and Professional¶
The schedule applied to a Copy Pipe does not guarantee that the underlying job executes immediately at the configured time. The job is placed into a job queue when the configured time elapses. It is possible that, if the queue is busy, the job could be delayed and executed some time after the scheduled time.
Enterprise¶
A maximum execution time of 50% of the scheduling period, 30 minutes max, means that if the Copy Pipe is scheduled to run every minute, the operation can take up to 30 seconds. If it is scheduled to run every 5 minutes, the job can last up to 2m30s, and so forth. This is to prevent overlapping jobs, which can impact results.
The schedule applied to a Copy Pipe does not guarantee that the job executes immediately at the configured time. When the configured time elapses, the job is placed into a job queue. It is possible that, if the queue is busy, the job could be delayed and executed some time after the scheduled time.
To reduce the chances of a busy queue affecting your Copy Pipe execution schedule, we recommend distributing the jobs over a wider period of time rather than grouped close together.
For Enterprise customers, these settings can be customized. Reach out to your Customer Success team directly, or email us at support@tinybird.co.
Next steps¶
- Understand how to use Tinybird's dynamic query parameters.
- Read up on configuring, executing, and iterating Materialized Views.